学习RLAIF论文前,可以先学习一下基于人类反馈的强化学习RLHF,相关的微调方法(比如强化学习系列RLHF、RRHF、RLTF、RRTF)的论文、数据集、代码等汇总都可以参考GitHub项目:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, and more.,这个项目收集了Text2SQL+LLM领域的相关简介、综述、经典Text2SQL方法、基础大模型、微调方法、数据集、实践项目等等,持续更新中!
(如果觉得对您有帮助的话,可以star、fork,有问题、建议也可以提issue、pr,欢迎围观)
论文概述
基本信息
- 英文标题:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- 中文标题:RLAIF:利用人工智能反馈扩展基于人类反馈的强化学习
- 发表时间:2023年9月
- 作者单位:Google Research
- 论文链接:https://arxiv.org/pdf/2309.00267.pdf
- 代码链接:无
摘要
摘要生成任务有效,其他任务比如Text2SQL任务是否有效呢?
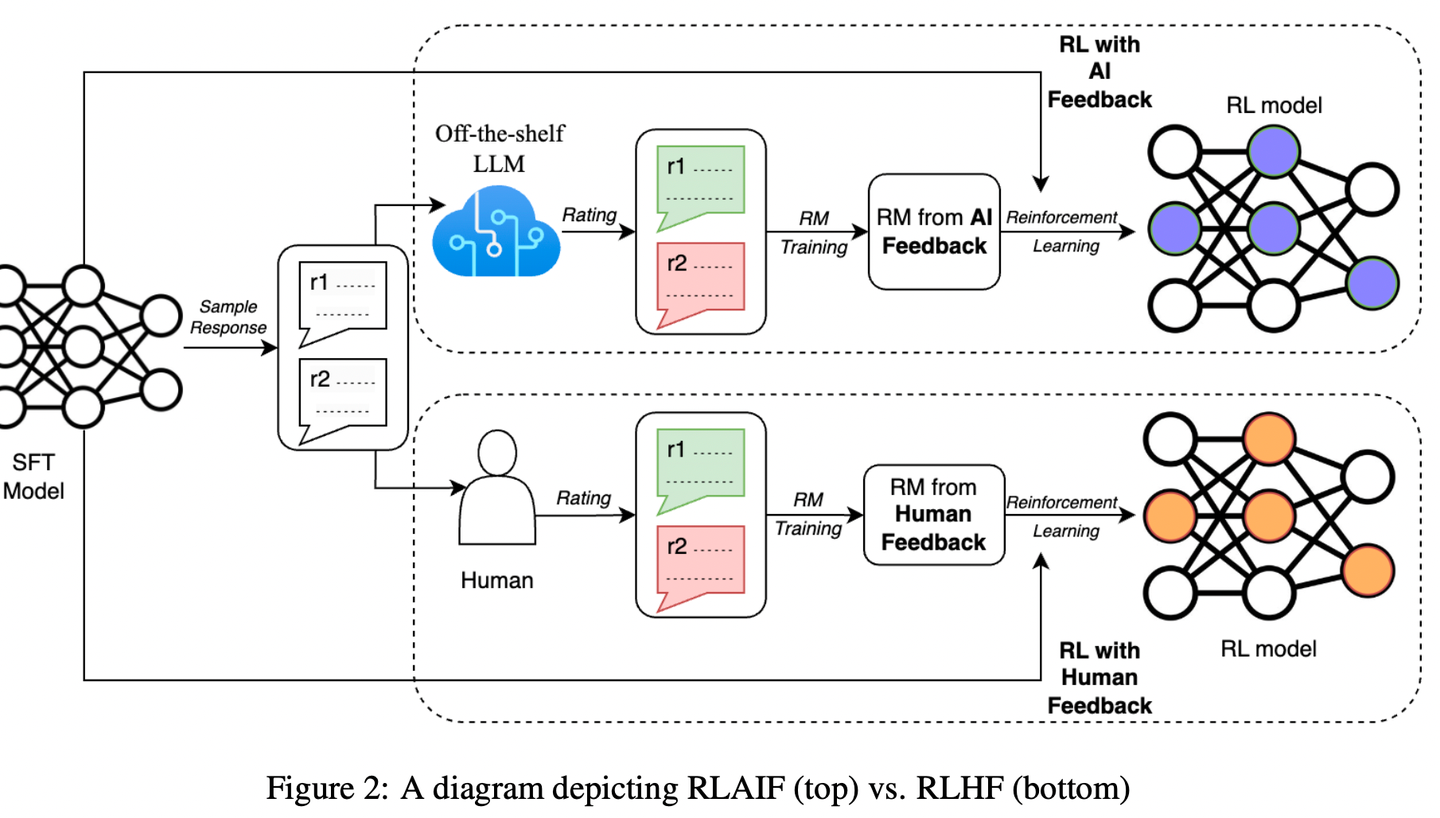
- 基于人类反馈的强化学习(RLHF)在将大型语言模型(llm)与人类偏好对齐方面是有效的,但收集高质量的人类偏好标签是一个关键瓶颈。
- 作者提出了RLAIF(利用AI反馈代替人类反馈),并且和RLHF进行对比,结果如下:
- 在摘要生成任务(summarization task)中,在约70%的情况下,人类评估者更喜欢来自RLAIF和RLHF的结果,而不是SFT模型。
- 此外,当被要求对RLAIF和RLHF摘要进行评分时,人类对两者的偏好率相同。
- 这些结果表明,RLAIF可以产生人类水平的性能,为RLHF的可扩展性限制提供了一个潜在的解决方案。
数据可以让AI生成,评估也可以让AI评估,AI for anything
结果
上结果,有图有真相

结果表明,RLAIF达到了与RLHF相似的性能。(人类打分,人类评估谁更好)
- RLHF 和 SFT 相比,RLHF有73%的情况更优秀
- RLAIF 和 SFT 相比,RLAIF有71%的情况更优秀
- RLHF 和 RLAIF 相比,RLHF有50%的情况下更优秀,也就是两者五五开。
碰巧还发现了一个论文的笔误,结果应该是论文中的图1,论文写的是表1。

论文还比较了RLHF和RLAIF分别和人类撰写的参考摘要。
- RLAIF摘要在79%的情况下优于参考摘要。
- RLHF摘要在80%的情况下优于参考摘要。
结果表明,RLAIF和RLHF策略倾向于生成比SFT策略更长的摘要,这可以解释一些质量改进。
但在控制长度后,两者的表现仍然优于SFT策略。
结论
证明了AI反馈的潜力
在这项工作中,论文证明了RLAIF可以在不依赖于人类注释者的情况下产生与RLHF相当的改进。
论文的实验表明,RLAIF在SFT基线上有很大的改进,改进幅度与RLHF相当。
在头对头比较中(head-to-head comparision,两者单挑的意思),人类对RLAIF和RLHF的偏好率相似。
还是有一些局限性。
比如任务是否可以推广到其他任务(和前面的摘要想法一样)
AI反馈 和 人工反馈的成本
RLHF+RAIF 结合是不是更好
等等
核心方法
贡献点
- 摘要任务上:RLAIF达到了和RLHF相当的性能
- 比较了各种AI 标签的技术,确定了最佳设置
RLHF
RLHF三部曲
SFT
RM
RL
SFT——提取专家知识
Supervised Fine-tuning有监督微调,简称为SFT。
SFT的数据通常是高质量的标注数据,比如基于LLM完成Text2SQL任务的话,数据集可以构造为如下形式:
以spider数据集示例:使用DB-GPT-Hub项目中预处理得到下面类似的数据:
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}我们可以做个测试,把prompt输入到ChatGPT-3.5中,如下:可以发现这个和标准的SQL一致,这个SQL属于比较简单的那种。

RM——类似于loss function
Reward Modeling 奖励模型,简称RM训练,最终目标就是训练一个模型,这个模型可以对LLM生成的response进行打分,得分高,代表response回答比较好。
RM的训练数据通常来说比SFT训练数据少,之前看见个例子说SFT数据占60%, RM数据占20%, RL数据占20%.
同样的,我们还是以Text2SQL任务举例子,RM数据可以构造为(prompt,chosen,rejected}的三元组,如下所示:
- chosen数据就是SFT的标准输出,groundtruth
- rejected数据通常来源于SFT 模型的错误输出,也就是bad case
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","chosen": "SELECT count(*) FROM head WHERE age > 56","rejected":"SELECT COUNT(head_name) FROM head WHERE age > 56;"}损失函数如下形式:
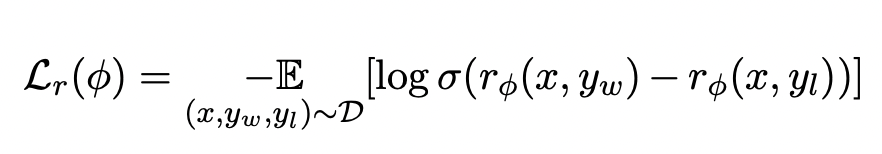
- 这里的x就是输入prompt
- y_w就是chosen data
- y_l就是rejected data
RL——引入强化学习方法
Reinforcement Learning 强化学习,简称为RL,就是利用强化学习的方法训练一个模型,使得奖励分数最高。
如下所示:
- 优化分数最大使用的是max
- 使用了KL散度,让训练的RL模型和原始模型差距不能过大
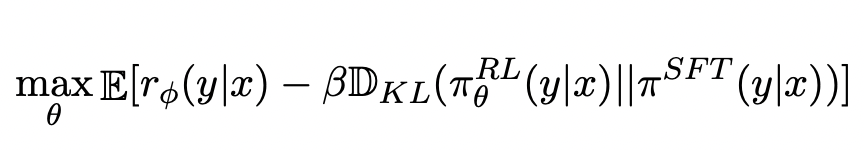
同样的,我们还是以Text2SQL任务举例子,RL数据可以构造为(prompt,output}的三元组,如下所示:
- 数据形式和SFT阶段保持一致
- SFT阶段训练的数据,不应和RL数据重叠。
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}RLAIF
进入主题RLAIF
LLM偏好标注
- 前言介绍和说明任务
- 1个例子说明:
-
- 需要输入一段文本Text、一对摘要(摘要1和摘要2)
- 模型输出偏好 Preferred Summary=1
- 给出文本和等待标注的摘要1、摘要2
- 结束:给出偏好 Preferred Summary=

在给出输入信息后,得到LLM的输出偏好1 或者 2之后,计算对数概率和softmax,得到偏好分布。
论文提到计算偏好分布也有其他的替代方法:
- 比如直接让模型输出output = "The first summary is better"
- 或者直接让偏好分布是one-hot编码
那么论文为什么不这么做呢?因为论文说就用上面的方法(输出1 或者 2),准确率已经足够高了。
论文做了一个实验,就是对比不同的任务前沿介绍,看看LLM标注的差距。
- Base:代表任务介绍比较简单,比如是“which summary is bet- ter?”(这个是论证任务介绍应该简单点还是详细点?)
- OpenAI:代表任务介绍比较详细,密切模仿了OpenAI,生成的任务介绍包含了哪些构成好的摘要信息
- COT:代表chain-of-thought思维链。(这个是论证思维链是否有效)
- 1-shot:代表给出1个例子,其他shot类似。(这个是论证上下文学习是否有效)
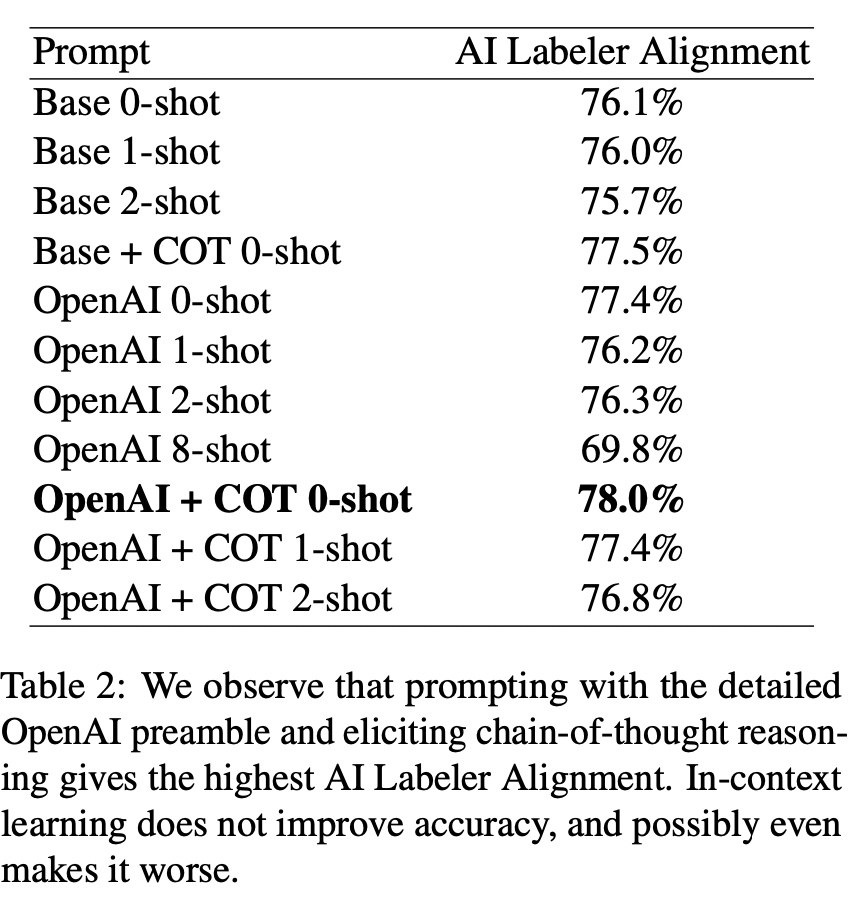
这个实验证明了:效果最好是OpenAI + COT + 0-shot
- 任务说明应该详细点好,OpenAI变现更好
- 思维链是有效的
- 上下文学习无效,甚至会降低效果,因为shot越多,效果越差。
Position Bias位置偏差
注意例子不要都是第一个更好,或者都是第二个更好
这样可能让模型有记忆以为都是第一个更好/第二个更好
所以输入要有随机性。
论文如何减少这个偏差的?
实验两次,取平均值。
- 正常顺序来一次,比如输入「摘要1-摘要2」
- 反方向顺序来一次,比如输入「摘要2-摘要1」
Chain-of-thought Reasoning思维链推理
思维链就是让模型模仿人类思考问题的方式。
回答问题的时候,不仅要有答案,更要有思考的过程。
比如摘要任务,选取第一个摘要更好,是因为第一个摘要的准确性,覆盖性更好。
Self-Consistency自洽性/前后一致性
采用多个推理路径,得到答案。
取平均值。
RLAIF步骤
LLM标记偏好后,训练奖励模型RM模型来预测偏好。
- 论文的方法产生的是软标签比如(preferencesi =[0.6, 0.4]),使用softmax交叉熵损失,而不是前面提到的RLHF中RM的损失函数。
蒸馏方法:用小模型去逼近大模型,让小模型的输出尽量和大模型保持一致。(模型轻量化的方法之一)
- 小模型:学生模型
- 大模型:教师模型
使用AI标注的数据进行训练RM模型,可以理解为模型蒸馏的一部分,因为AI打标签的大模型LLM通常比RM更大、更强。
RL训练不使用PPO算法。
RL训练采用 Advantage Actor Critic (A2C)方法,因为更简单,更有效,在摘要任务上。