前言
熟悉Redis缓存应用的伙伴们都知道,Redis缓存存在缓存击穿、雪崩和穿透的问题,通常在解决缓存穿透问题时,除了缓存异常请求外,还有一个叫做布隆过滤器的方案。下面,我们认识下布隆过滤器。
结构&原理
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。根据上述百度百科的描述,我们可以大致画出布隆过滤器的结构,如下
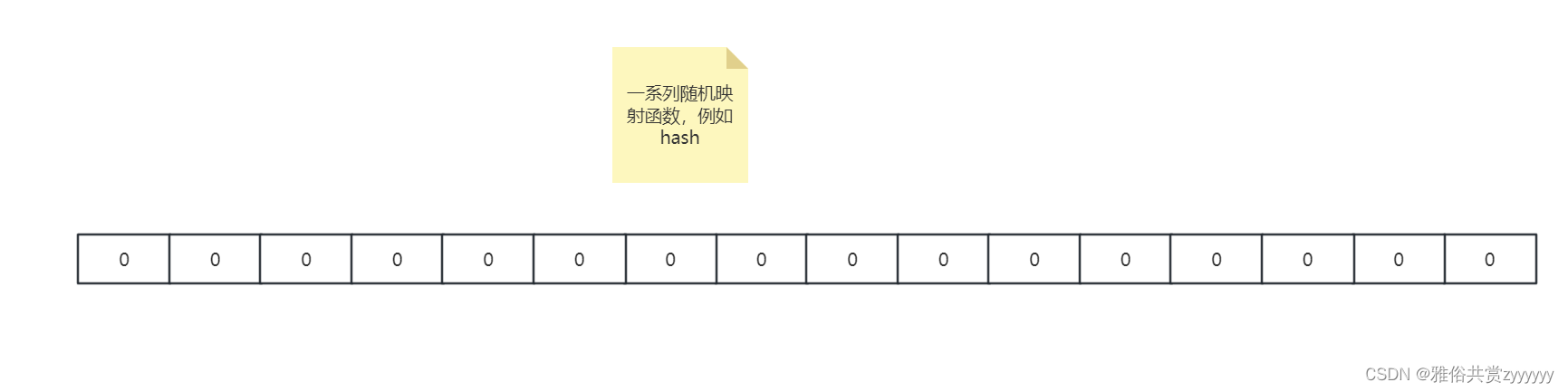
在初始情况下,我们可以将其看作一个很长的二进制数组,默认每个位置为0,当新增元素的时候,通过一系列Hash函数计算出这个元素的向量下标,然后填入二进制数组中,如下
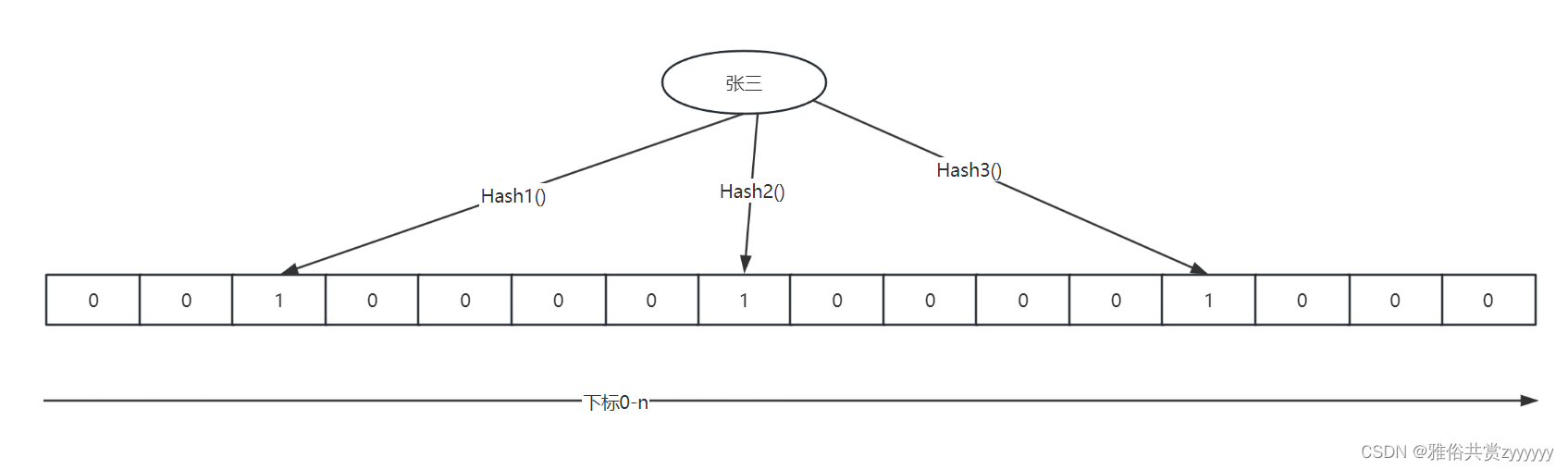
这样,“张三”通过n个Hash函数映射到n个数组下标的位置上标记,同理,这时如果再来“李四”、“王五”等元素,也是通过n个Hash函数映射,这样,就有可能会导致有些值通过不通的Hash函数映射到同一个下标的位置,如下所示
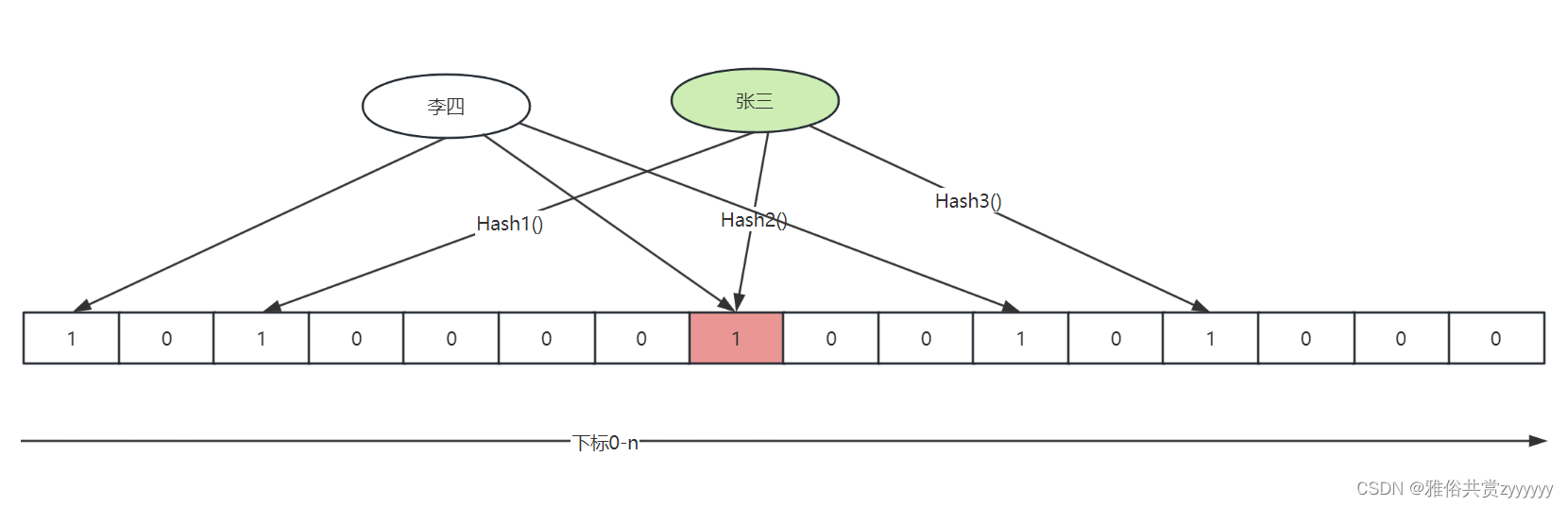
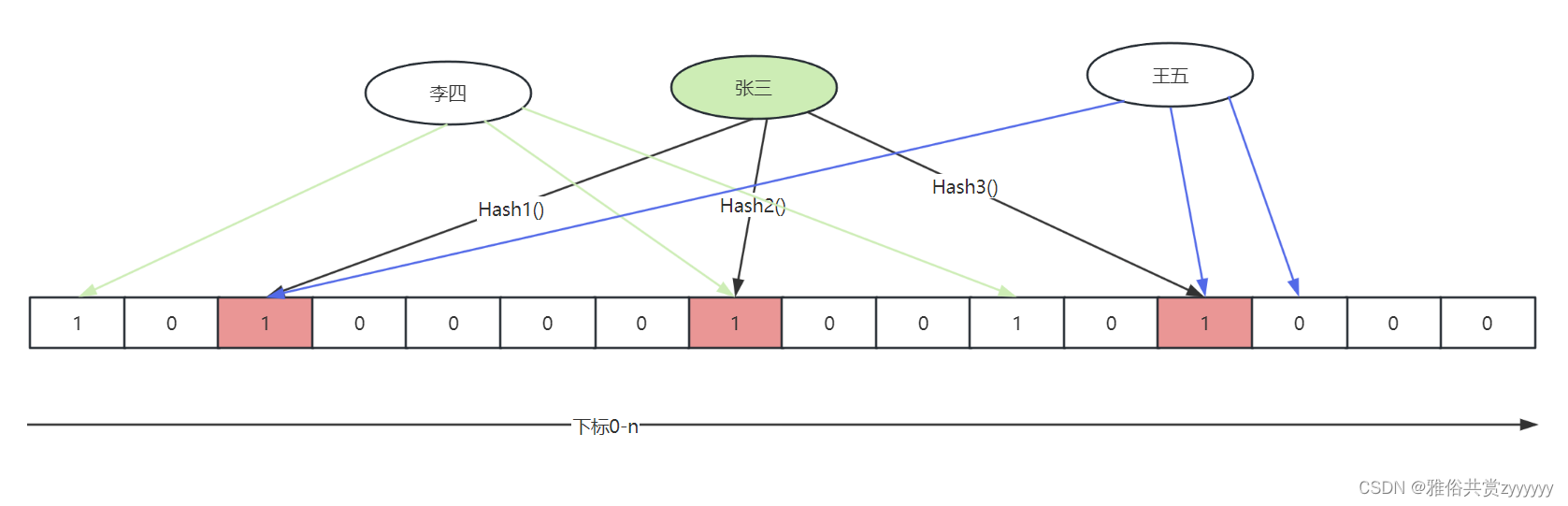
那么,如何查询元素呢?在查询元素时,也是通过n个不同hash函数将元素映射到n个点,然后判断这n个位置的值是否为1,这样,就会有两个结论:
- n个位置全是1,元素可能存在
- 有至少一个位置是0,元素不存在
从上图我们可以看出,张三这个元素查询时,可能是由李四和王五两个元素的位置覆盖得出的1,因此,即使所有位置都为1,也不能完全确认张三存在。基于此问题,我们可以调整布隆过滤器的长度和随机映射函数,来减少元素碰撞。同样基于上述情况,我们可以很清晰的知道,布隆过滤器万万不能删除元素,因为你不知道同一下标对应多少元素。
SpringBoot简单测试
谷歌开源的Guava自带布隆过滤器,首先引入依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version></dependency>
然后,我们设置好布隆过滤器的长度和误判率,插入对应的数据,例如插入1-1000000作为100万个测试数据,然后,查询1000001-2000000数据在布隆过滤器是否存在,查看它的误判数,从而计算真实的误判率,如下
package com.example.test.redis;import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;import java.text.NumberFormat;public class BloomFilterTest {/*** 预计要插入多少数据*/private static int size = 1000000;/*** 期望的误判率*/private static double fpp = 0.001;/*** 布隆过滤器*/private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(),size,fpp);public static void main(String[] args) {//插入样本数据for(int i=0; i<size; i++){bloomFilter.put(i);}//另外十万测试数据,预测误判率int count = 0;for(int i=size; i<size+1000000; i++){if(bloomFilter.mightContain(i)){count++;System.out.println(i+"误判了");}}NumberFormat nf = NumberFormat.getInstance();//关闭科学计数法nf.setGroupingUsed(false);//定义保留几位小数nf.setMaximumFractionDigits(8);System.out.println("总共误判数:"+count+",真实误判率为:"+nf.format((double)count/1000000.00));}
}运行结果如下
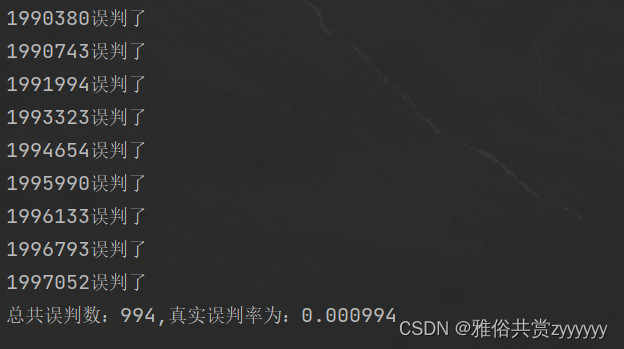
如果我们调整判断数据量,会发现误判率超过了我们的期望值,这也说明随着数据量增大,误判率也会增加,这就要我们调整布隆过滤器的长度和随机映射函数了。