文章目录
- 问题现象:
- 排查思路
- 查看task运行概况
- 查看map和reduce container的日志
- 初步结论
- 继续排查
- container数量差异大
- 分片计算异常
- 结论
问题现象:
每天调度的一个任务在某天突然运行时长多了好几倍,平时30m左右,那天运行了4个小时多

排查思路
-
1.查看hiveserver侧
检查query提交、编译及执行的时间,是否有卡点:如由于锁导致的等待导致的执行等待长 -
2.查看yarn侧及作业日志
查看hiveserver2侧提交tez session一切正常,此时需获取applicationId来查看作业日志
作业日志首先查看am日志,检查container的分配情况是否正常,有没有因资源堵塞导致的延迟、以及container的运行失败重调度情况等
上述查看正常
查看task运行概况
搜索关键字TASK_FINISHED
发现某个map task的运行时间是其他map task的三倍(这里00是map task、01是reduce task)

查看map和reduce container的日志
接着查看这个task_1676535507899_2801404_1_00_000013的日志
这里task会变为attempt,后面添加0代表这个第一次运行

通过map container的日志发现问题:
1.通过Processing split查看这个map task要读取的文件(业务原因,小文件)特别多
同时查看reduce container的日志:
很明显 是上面map task长尾了 导致reduce task一直等待拉取map的输出导致的

初步结论
后面对比了map task的输入文件,这个container接收的明显要多,导致map task长尾,拖慢整个作业的运行时长。(这两次作业的输入文件数和数据量是差不多的)
从现在看tez的分片机制有问题?
继续排查
container数量差异大
对比这个作业两天运行的app日志,发现以下情况:分配的container数量,有问题的作业明显要少几十倍
获知这个情况后,查看am日志发现:
分片计算异常
-
问题作业
在tez计算map task的数量时,available slots的数量为0,这里YarnTaskSchedulerService日志一直打印获取的集群可用资源为0
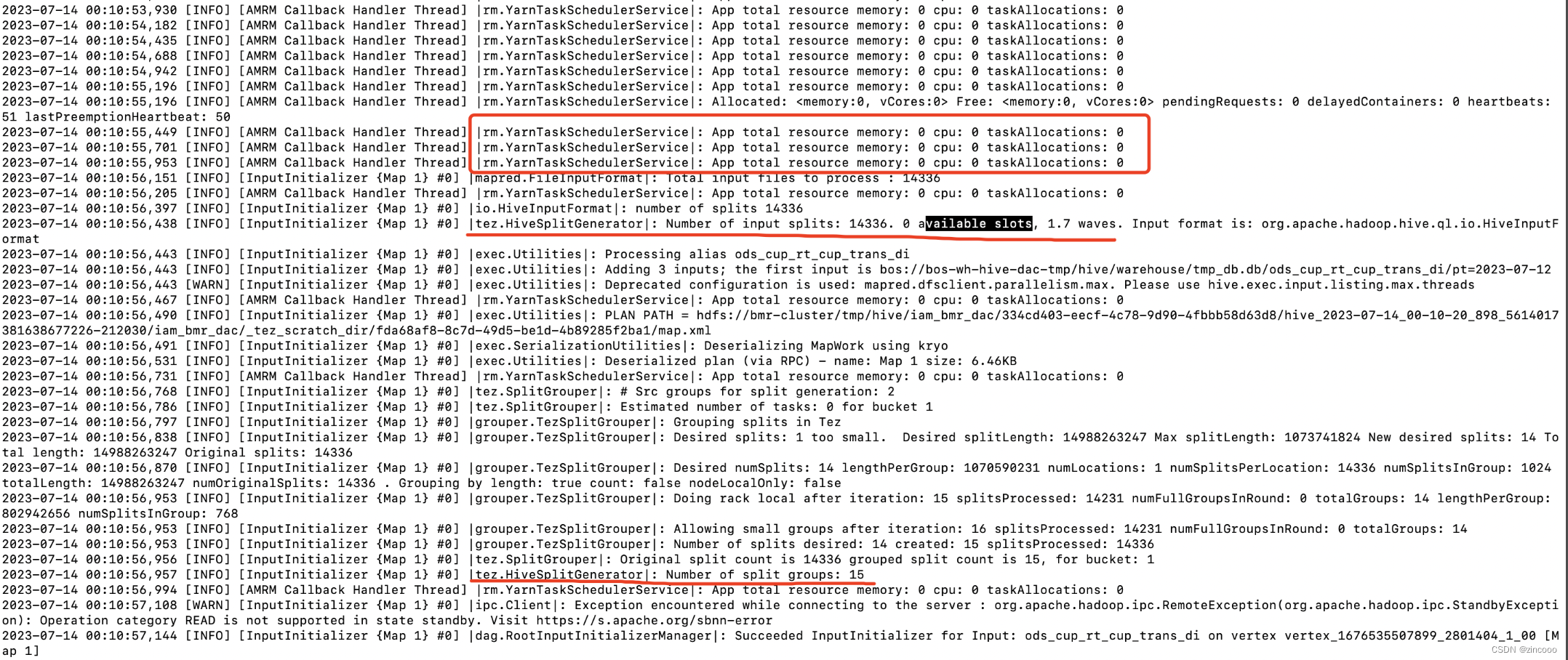
但是通过监控查看当时集群仍有很多的可用资源,从后续的日志看,1分多钟后也获取到了正常的资源情况,但此时task数量已经计算完了并提交请求了
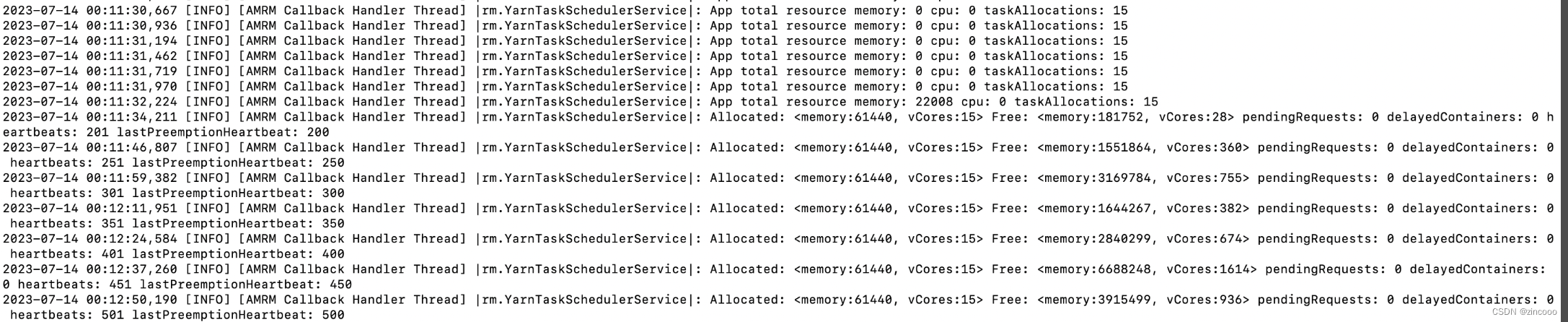
-
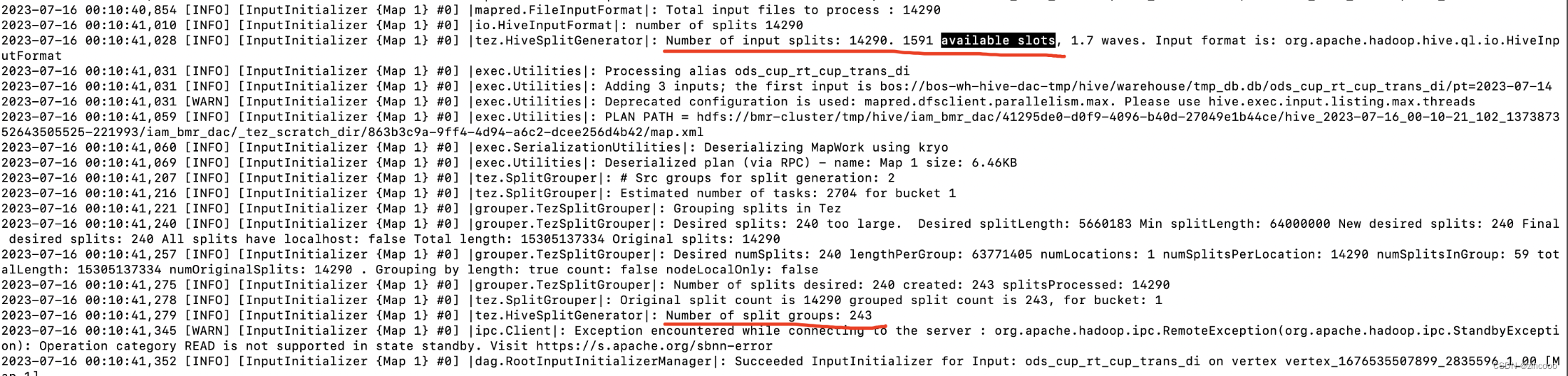
正常作业
计算map task的数量时,获取的集群资源是正常的(6516736/1591 正正好是4096M

结论
是由于一直获取不到集群资源导致,计算的container过少,某个map task处理的数据过多而长尾拖慢整个作业的运行时长。这里tez与RM通信,有以下几点怀疑:
1.网络层面:am运行的节点与RM之间网络波动
2.服务层面:RM当时无法正常响应、可能是由于gc pause等原因
3.资源层面:可能是队列资源满了或队列的父队列资源满了
![uni-app开发微信小程序的报错[渲染层错误]排查及解决](https://img-blog.csdnimg.cn/e25d1be8ff3f45fe933fca768fa4a963.png#pic_center)