编者按:2023年是微软亚洲研究院建院25周年。25年来,微软亚洲研究院探索并实践了一种独特且有效的企业研究院的新模式,并以此为基础产出了诸多对微软公司和全球社会都有积极影响的创新成果。一直以来,微软亚洲研究院致力于创造具有突破性的技术。在人工智能时代,微软亚洲研究院将为计算新范式奠定基础,并为人工智能和人类发展创造更美好的未来。
借此机会,我们特别策划了“智启未来”系列文章,邀请到微软亚洲研究院不同研究领域的领军人物,以署名文章的形式分享他们对人工智能、计算机及其交叉学科领域的观点洞察及前沿展望。希望此举能为关注相关研究的同仁提供有价值的启发,激发新的智慧与灵感,推动行业发展。

我们希望人工智能能够像人类一样,从现实世界的视频、音频等媒介中获得知识和智能。为了实现这一目标,我们需要将复杂而含有噪音的现实世界,转化为能够捕获世界本质信息和动态变化的抽象表示。微软亚洲研究院正在探索多媒体与人工智能的协同发展,从对媒体基础(Media Foundation)的创新研究中找到新的突破口,这一探索将为多模态大模型的研究带来新的思路。
——吕岩,微软亚洲研究院全球研究合伙人
自1956年达特茅斯会议提出“人工智能”一词,人类足足用了近70年的时间,才积累了足够的技术和资源促成人工智能的爆发。而当我们跨过“临界点”,大语言模型(LLMs)在自然语言理解、语音识别、图像生成等方面展现出的一系列巨大进步令人目不暇接。随着 ChatGPT、DALL-E 等应用的出现,我们看到人工智能开始展现出更复杂的能力,比如观察、学习和理解真实世界,并进一步实现推理和创造。
如今我们对人工智能有了更高的期待。我们不仅希望人工智能能够进行创作,也希望它能如同人类一样,通过各种渠道从真实世界中获取知识、实现成长。然而人工智能与人类的认知能力还有很大的差距:人脑能够接收和解析物理世界的绝大多数现象,如视频、声音、语言、文字等,并将其抽象为可保存和积累的信息、知识或技能。而能完成通用任务的多模态人工智能模型,却还处在蹒跚学步的早期阶段。
我们希望人工智能能够从现实世界的数据中进行学习和迭代。然而如何在复杂且充满噪声的真实世界和人工智能所处在的抽象语义世界之间架起桥梁呢?是否可以为不同类型媒体信息构建与自然语言平行的,另一种可被人工智能学习理解的语言?我认为这是非常值得探索的方向。我和微软亚洲研究院的同事们正致力于从神经编解码器(Neural Codec)入手,构建一个全面的媒体基础(Media Foundation)框架,通过提取真实世界中不同媒体内容的表征,形成可被人工智能理解的语义,从而弥合真实世界与抽象语义之间的鸿沟,为多模态人工智能研究开启一扇新的大门。
打破复杂真实世界与抽象语义之间的壁垒
人类之所以能成为无出其右的卓越“学习者”,是因为人类能通过视觉、听觉、触觉和语言等多种方式来观察物理世界并与之互动,从中汲取广泛的技能和知识,从而不断提高我们的智能水平。我们希望能将人类的这一特征“复制”到人工智能身上,使其能够从丰富的真实世界数据中进行学习和迭代。
目前绝大多数人工智能大模型的基座模型都建立在大语言模型之上,通过抽象、紧凑的文本表达来获得对世界的认知。虽然人们陆续研发出针对不同媒体形式的预训练模型,但它们并不能充分反映真实世界的动态变化。来自物理世界的视频和音频信号是复杂且充满噪声的,我们需要找到一种有效方法,将其转换为能够捕获真实世界本质信息和动态变化的抽象表示。
过去一段时间,我和微软亚洲研究院的同事们一直在探索与大语言模型平行的人工智能发展之路。多媒体研究立足于捕捉、压缩、解释、重构和生成各种模态的媒体中的丰富信息,如图像、视频、音频和文本等,并自然而然地将复杂而嘈杂的真实世界转化为一种抽象表示。我们希望这种抽象表示具有三方面的特性:富有语义、紧凑的大小和信息的完整保留。如果能在该领域有所突破,是否就可以为视频、音频等多媒体信号和抽象且语义化的人工智能模型之间搭建桥梁?
于是我们产生了这样的想法:建立一个全面的媒体基础框架,通过神经编解码器,将不同模态的媒体信号转换为紧凑且语义化的表征标记,从而构建真实世界及其动态变化的抽象表示。
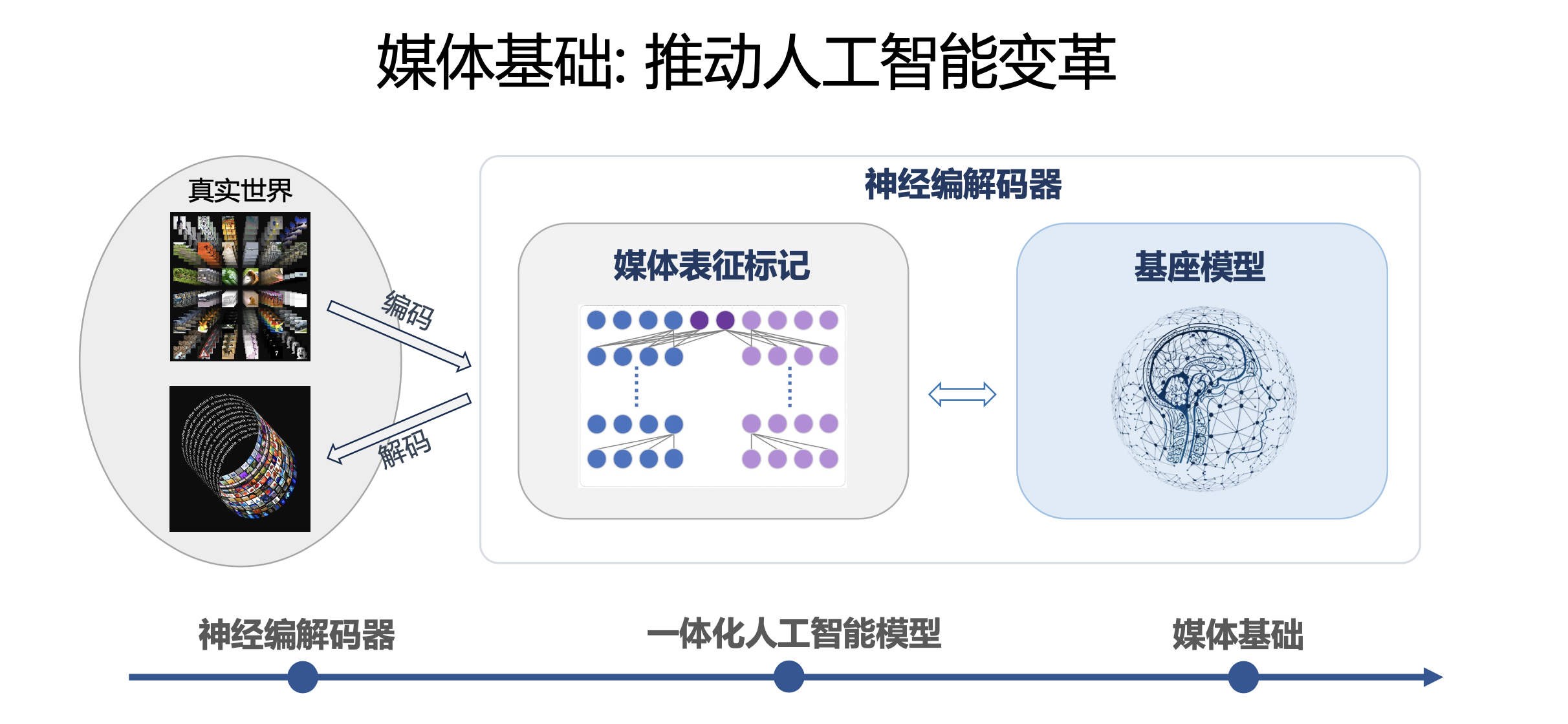
神经编解码器构建多媒体的抽象表示
我们构想的媒体基础由两个组件组成:在线媒体表征标记和离线基座模型。其中,在线媒体表征标记模型可以动态地将多媒体信息转换为紧凑抽象的语义表示,以供人工智能观察现实世界并与之交互。而离线基座模型可以由现实世界中提取的媒体表征标记来离线构建,并通过离线学习的知识预测动态变化。无论人工智能用来学习的是语言文本,还是音频或视频,尽可能实现无损的压缩都是其智能的源泉。
从本质上讲,整个媒体基础框架可被视为一种更广泛意义上的神经编解码器。对此我们设计了三个阶段的发展计划:首先,训练初始的编码器和解码器模型,学习每种模态的媒体表征;其次,为每种模态构建基座模型,并进一步优化编码器和解码器;第三,学习包括自然语言在内的跨模态关联,并构建最终的多模态基座模型。媒体的动态表征标记与多模态基座模型一起构成了我们的媒体基础,并为我们迈向多模态人工智能之路提供一种新的思路。
如前所述,抽象的语义表达更加紧凑和简洁,而视频和音频信号却复杂且含有噪声,我们的媒体基础框架是否能够将真实世界的动态变化进行高效且尽可能无损的压缩?至少此前我们所看到的多媒体编解码器都难以胜任这项工作。因此,我们认为当务之急是开发一个新的神经编解码器框架,用于高效构建视频、音频及其动态变化的抽象表示。
在过去的几年里,我和同事们一直致力于开发高效的神经音频/视频编解码器,并取得了令人兴奋的进展。在利用深度学习颠覆传统编解码器架构的同时,我们也实现了更低的计算成本及更优的性能。我们开发的神经编解码器的性能不仅超越了传统的编解码器,也显著优于现有的其它神经编解码器。
在神经音频编解码器方面,我们首次实现了 256bps 的高质量语音信号压缩,并在 256bps 的极低比特率下,通过信息瓶颈实现了解耦的抽象语义表征学习。其意义不仅在于多媒体技术层面——通过这一创新,我们能够利用捕捉到的音频表征来实现各种音频和语音任务,例如语音转换或语音到语音的翻译。
此外,我们还开发了 DCVC-DC(Deep Contextual Video Compression-Diverse Contexts) 神经视频编解码器。它可以将传统编解码中通过规则组合的不同模块和算法转换为深度学习的自动学习方式,有效利用不同的上下文来大幅提高视频压缩率,这使得它在性能上超越了此前所有的视频编解码器。由于构建全面、协同的媒体基础对神经视频编解码器带来了全新的挑战,我们正在对 DCVC-DC 进行深度改造。
探索隐文本语言之外的另一种可能性
我们开发的神经编解码器,本质上是通过从根本上改变对隐空间中的对象、动作、情绪或概念等不同类型信息的建模方式,让模型达到更高的压缩比。这对多模态大模型的意义在于,通过神经编解码器可以将视觉、语言和声音等信息转换为隐空间的神经表达——类似于自然语言处理中的抽象而紧凑的语义表征,但这些多媒体表征更符合自然规律,而且不局限于自然语言顺序的简单描述,能够支持更广泛的应用。
我们的探索验证了通过视频和音频构建全新的媒体基础的可行性,这为开发人工智能带来了全新的视角。虽然自然语言已被证明是构建人工智能的有效方法,但如果我们总是试图将复杂的多媒体信号转化成文本语言或与之相关联,不仅过于繁琐,还会限制人工智能的全面发展。相比之下,构建基于神经编解码器的媒体基础的思路可能更加有效。
当然,通过媒体基础和自然语言模型实现多模态大模型的方式虽然不同,但对于人工智能发展来说都有不可替代的价值。我们不妨将人工智能学习的多媒体表征看作是与自然语言并行的另一种“语言”。这样,大型多模态模型也可以被视为“大型多媒体语言模型”。我相信,神经编解码器的发展将成为媒体基础演进的巨大推动力,其包含的媒体基座模型与大语言模型将共同构建未来的多模态大模型,真正实现我们所期待的全方位、协同的多模态媒体基础与融合,从而更好地释放人工智能的潜力。
目前,我们仍在努力探索神经编解码器在隐空间中对多媒体信息的更多建模方法,全面、协同、融合的媒体基础作为我们的设想和判断,任何一个切入点都充满了无穷的可能。如果我们的这一设想能够为人工智能的进步带来一些激发灵感的星星之火,那对我们来说已经足以感到欣慰和自豪了!
相关论文
Disentangled Feature Learning for Real-Time Neural Speech Coding
论文链接:https://ieeexplore.ieee.org/abstract/document/10094723
Neural Video Compression with Diverse Contexts
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Li_Neural_Video_Compression_With_Diverse_Contexts_CVPR_2023_paper.pdf
本文作者
吕岩,微软亚洲研究院全球研究合伙人、多媒体计算方向负责人,领导团队从事多媒体通信、计算机视觉、语音增强、多模态信息融合、用户界面虚拟化及云计算等方向的关键技术研究。
自2004年加入微软亚洲研究院以来,吕岩和团队的多项科研成果和原型系统已转化至 Windows、Office、Teams、Xbox 等关键产品中。近年来,吕岩致力于推动基于神经网络的端到端多媒体处理与通信框架和多模态智能交互系统的研究突破。吕岩在多媒体领域发表学术论文100余篇,获得美国专利授权30余项,有多项技术被 MPEG-4、H.264、H.265 和 AOM AV-1 等国际标准和工业标准所采用,曾获国家技术发明二等奖。