1.Ranger简介
Apache Ranger提供一个集中式安全管理框架, 并解决授权和审计。它可以对Hadoop生态的组件如HDFS、Yarn、Hive、Hbase等进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问权限。
说白了就是管理大多数框架的授权问题。
2.安装部署
2.1.环境准备
2.2.下载Ranger源码包
wget https://repo.huaweicloud.com/apache/ranger/2.0.0/apache-ranger-2.0.0.tar.gz2.3.下载Maven并配置国内源
wget https://repo.huaweicloud.com/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz2.3.1解压并配置环境变量
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module/#配置环境变量
vi /etc/profileexport MAVEN_HOME=/opt/module/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin2.3.2 配置国内源
华为
<mirror><id>huaweicloud</id><mirrorOf>*</mirrorOf><url>https://repo.huaweicloud.com/repository/maven/</url>
</mirror>
或者 阿里
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror>
2.3.3安装git
yum -y install git
2.4Ranger编译
#进入安装目录
[root@hadoop102 apache-ranger-2.0.0]# pwd
/opt/module/apache-ranger-2.0.0编译命令
mvn clean compile package assembly:assembly install -DskipTests -Drat.skip=true编译时间需要好久。
中间有报错的情况下,请仔细看日志具体原因。
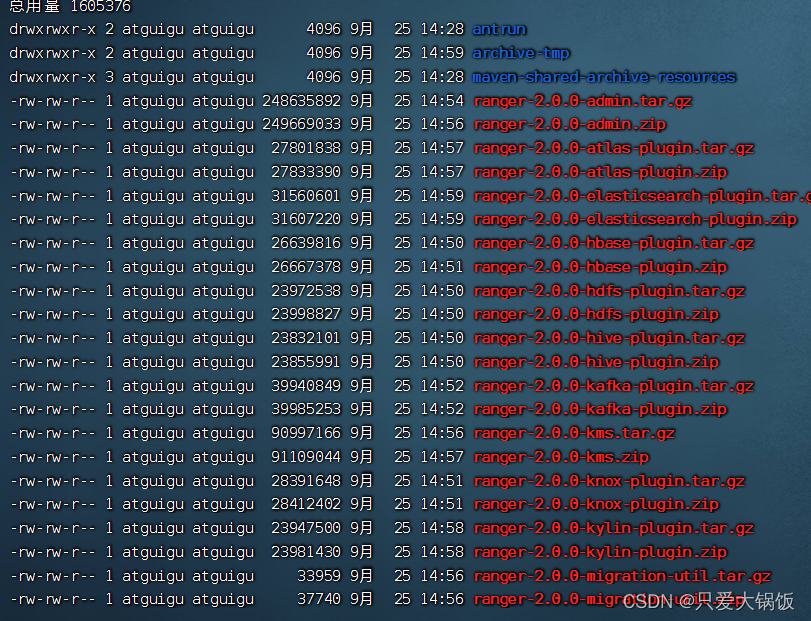
编译完成后,会在Ranger安装目录下生成target目录,里面会生成许多相对应的 tar 包
3.Ranger Admin使用
3.1数据库环境准备
#创建元数据库
create database ranger;#创建用户和密码
grant all privileges on ranger.* to ranger@'%' identified by 'ranger';
在创建用户和密码过程中 可能会出现异常:ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
解决方式:
set global validate_password_policy=LOW;
set global validate_password_length=6;#再次使用以下命令创建用户和密码 就正常了
grant all privileges on ranger.* to ranger@'%' identified by 'ranger';3.2解压ranger-admin
ranger-admin 就是上述编译后的包,存储在Ranger安装目录下的target目录下
本次路径为:
cd /opt/module/apache-ranger-2.0.0/target解压命令:
tar -zxvf /opt/module/apache-ranger-2.0.0/target -C /opt/module/3.3修改配置文件
进入ranger-admin 解压目录:
cd /opt/module/ranger-2.0.0-admin/修改install.properties文件,这里使用的数据库是mysql,不安装solar服务
1) 数据库配置
DB_FLAVOR=MYSQL #指定使用的数据库类型
SQL_CONNECTOR_JAR=/opt/mysql-connector-java-8.0.21.jar #数据库链接jar包所在位置
db_root_user=[mysql用户] #数据库t用户
db_root_password=[mysql密码] #用户密码
db_host=[数据库ip] #数据库主机名# 以下是设置ranger数据库的
# DB UserId used for the Ranger schema
#
db_name=ranger
db_user=ranger
db_password=ranger# 不需要保存,为空,否则生成的数据库密码为'_'
cred_keystore_filename=2)审计日志,如果没有安装solar,对应属性值为空#Source for Audit Store. Currently only solr is supported.
# * audit_store is solr
audit_store=3)策略管理配置,配置ip和端口。默认即可policymgr_external_url=http://[本机ip]:60804)配置hadoop conf文件目录hadoop_conf=[hadoop目录下的etc/hadoop]5)rangerAdmin、rangerTagSync、keyadmin密码配置。默认为空,可以不配置。rangerAdmin_password= #密码强度为 字母加数字
rangerTagsync_password=
rangerUsersync_password=
keyadmin_password=6) 是否需要ranger用户# 启动ranger是否需要创建ranger用户
# ------- UNIX User CONFIG ----------------
#
unix_user=ranger
unix_user_pwd=ranger
unix_group=ranger
3.4初始化ranger-admin 用户
cd /opt/module/ranger-2.0.0-admin# 以root用户指定该脚本, 需要写入一些配置
./setup.sh
3.5启动ranger-admin
ranger-admin start
# 或者
./ews/ranger-admin-services.sh start
查看进程 jps,有 EmbeddedServer 进程就说明启动成功!
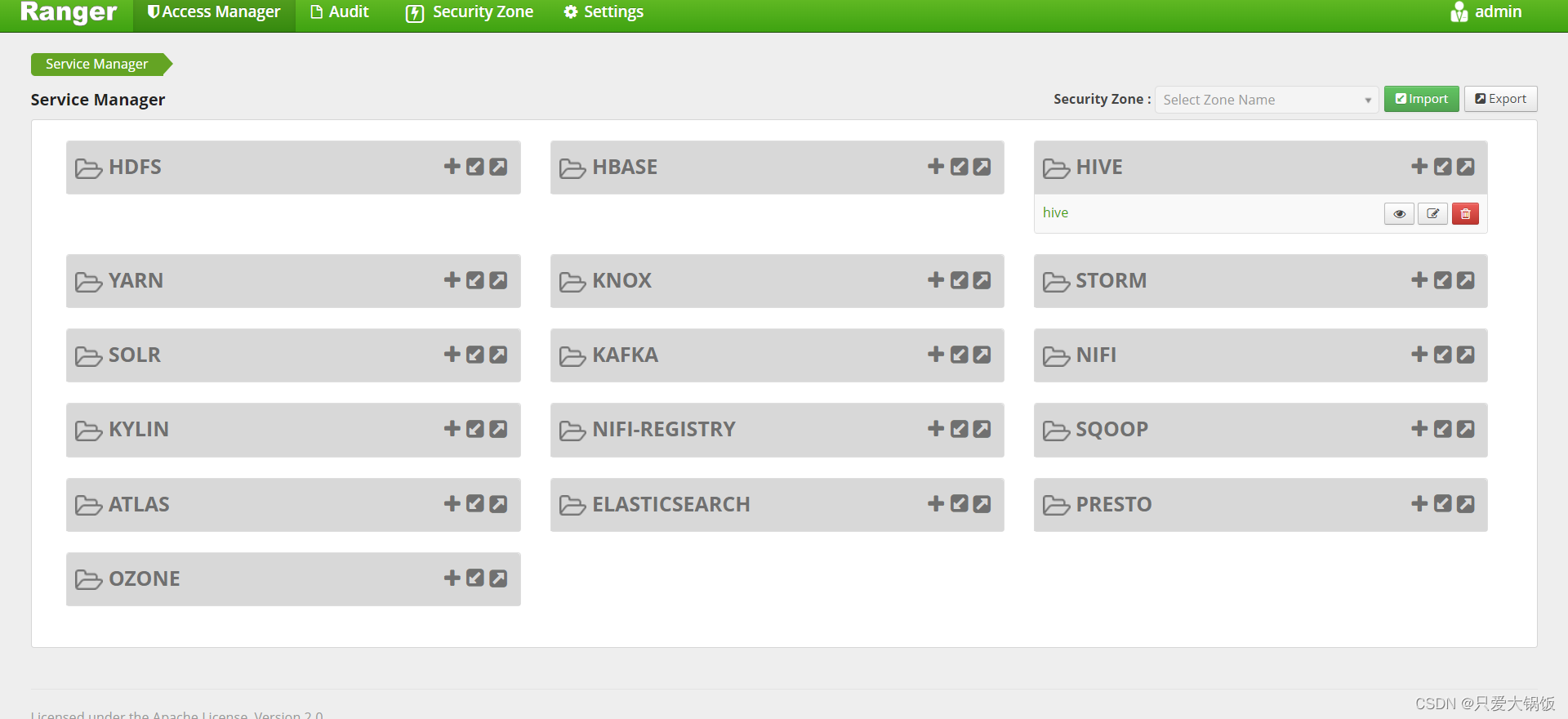
打开浏览器访问 http://ip:6080 ,登录界面密码为上文配置文件中配置rangerAdmin_password 的值,无配置默认为 admin。所以账号和密码 都为 admin
 4.Ranger-usersync安装部署
4.Ranger-usersync安装部署
4.1解压Ranger-usersync安装包
和解压ranger-admin一样,切换到 target目录
cd /opt/module/apache-ranger-2.0.0/target解压 Ranger-usersync 安装包
tar -zxvf ranger-2.0.0-usersync.tar.gz -C /opt/module/4.2修改配置文件
修改install.properties 文件
# 配置ranger_admin地址
POLICY_MGR_URL = http://[IP]:6080# 同步源系统类型
SYNC_SOURCE = unix# 同步时间间隔设置(单位:分钟)
SYNC_INTERVAL = 1# usersync程序运行的用户和用户组
#User and group for the usersync process
unix_user=ranger
unix_group=ranger# 修改rangerusersync用户的密码。注意,此密码应与Ranger admin中install.properties的rangerusersync_password相同。此处可以为空,同样Ranger admin的也要为空#change password of rangerusersync user. Please note that this password should be as per rangerusersync user in ranger
rangerUsersync_password=admin123456# 配置hadoop 配置路径
hadoop_conf=[hadoop_home下etc/hadoop]# 配置usersync的log路径
#user sync log path
logdir=logs
4.3初始化Ranger-usersync
./setup.sh
4.4启动ranger-usersync
ranger-usersync start
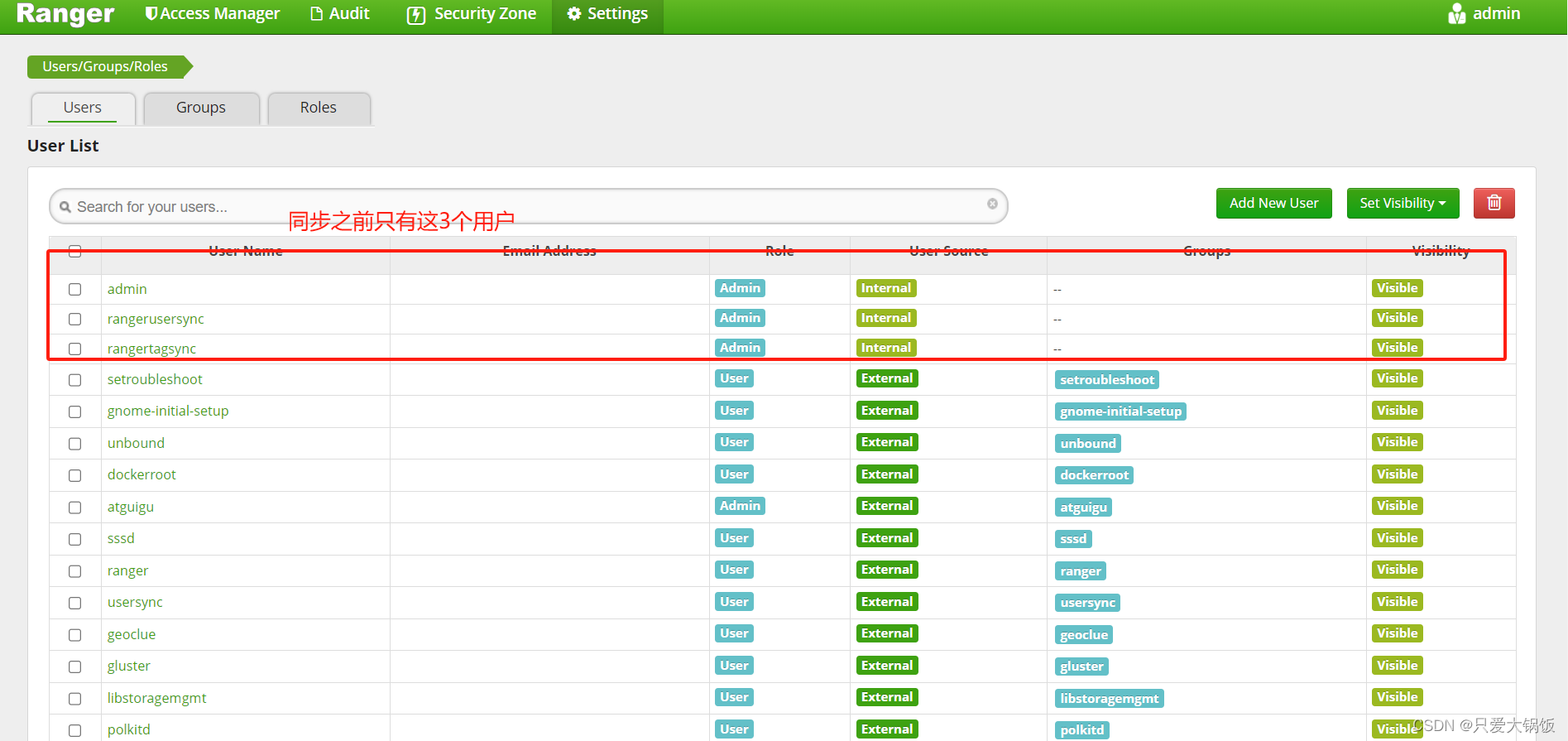
验证是否安装成功,可以查看是否同步到unix上的用户信息,同步之后有以下所有用户(每个人机器上用户不同)