文章目录
- 前言
- 一、MIG IP 核的配置
- 二、MIG 交互的接口
- 三、常用IP例化值
- 四、小实验传图
前言
本节主要是介绍 Xilinx DDR 控制器 IP 的创建流程、IP 用户使用接口 native 协议介绍和IP 对应的 Example Design 的仿真和上板验证。。
提示:以下是本篇文章正文内容,下面案例可供参考
一、MIG IP 核的配置
首先在 Vivado 环境里新建一个工程,取名为 ddr3_rw_top。再点击 Project Manager 界面下的 IP Catalog,打开 IP Catalog 界面。本次实验是以 35t 芯片为例,芯片的配置如下图所示。
在搜索栏中输入 MIG,此时出现 MIG IP 核,直接双击打开。如下图所示。
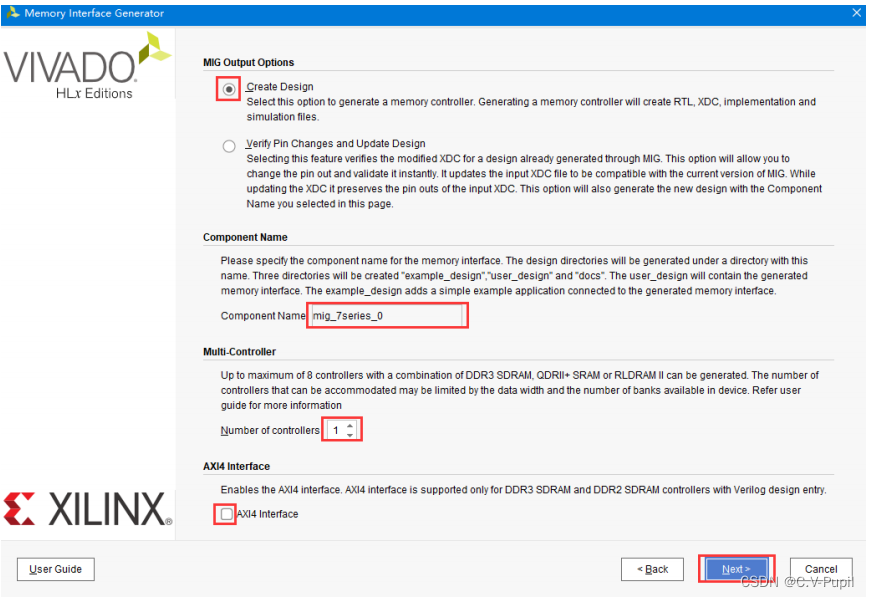
下面让确认工程的信息,主要是芯片信息和编译环境的信息,如果没什么问题,直接点击“Next”。如下图所示。

如下图所示,这一页选择“Create Design”,在“Component Name”一栏设置该 IP 元件的名称,这里取默认软件的名称,再往下选择控制器数量,默认为“1”即可。最后关于 AXI4 接口,因为本工程不去使用,所以不勾选。配置完成点击“Next”。(AXI4接口可参考AXI4接口)
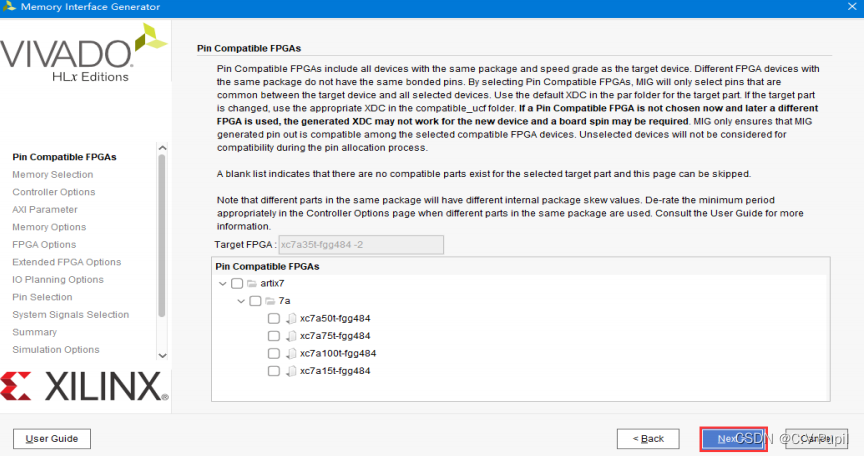
如下图所示,这一页主要是让用户选择可以兼容的芯片,本工程默认不勾选,即不需要兼容其他的 FPGA芯片。配置完成点击“Next”。
如下图所示,这一页选择第一个选项“DDR3 SDRAM”,因为本实验用的就是 DDR3 芯片。配置完成点击“Next”。

如下图所示,从这页开始,下面来讲解如何配置 MIG IP 核,大家可以对照图片和文字来详细了解各个选项和本次实验的配置参数。
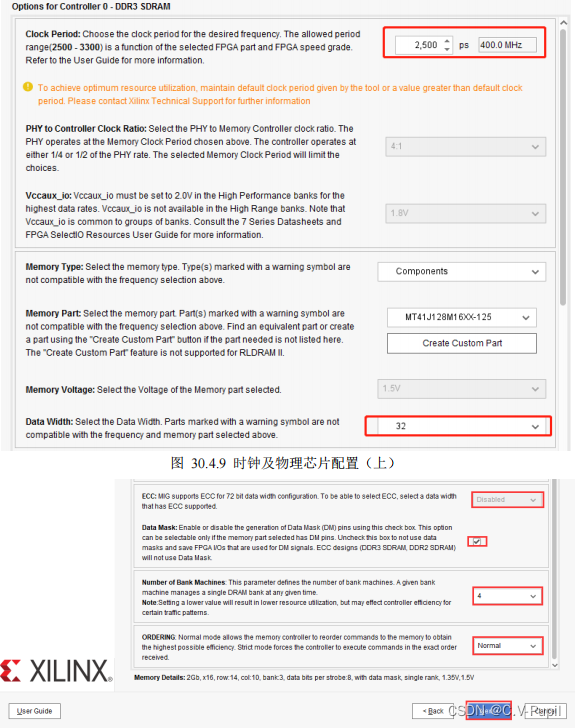 Clock Period:DDR3 芯片运行时钟周期,这个参数的范围和 FPGA 的芯片类型以及具体类型的速度等级有关。本实验选择 2500ps,对应 400M,这是本次实验所采用芯片可选的最大频率。注意这个时钟是 MIG IP 核产生,并输出给 DDR3 物理芯片使用的,它关系到 DDR3 芯片具体的运行带宽。比如本次实验的开发板板载了 1颗 DDR3 芯片,数据位宽总共 16 位,因为是双沿触发,这里带宽达到了 800M*16bit。
Clock Period:DDR3 芯片运行时钟周期,这个参数的范围和 FPGA 的芯片类型以及具体类型的速度等级有关。本实验选择 2500ps,对应 400M,这是本次实验所采用芯片可选的最大频率。注意这个时钟是 MIG IP 核产生,并输出给 DDR3 物理芯片使用的,它关系到 DDR3 芯片具体的运行带宽。比如本次实验的开发板板载了 1颗 DDR3 芯片,数据位宽总共 16 位,因为是双沿触发,这里带宽达到了 800M*16bit。
PHY to Controller Clock Ratio:DDR3 物理芯片运行时钟和 MIG IP 核的用户端(FPGA)的时钟之比,一般有 4:1 和 2:1 两个选项,本次实验选 4:1。由于 DDR 芯片的运行时钟是 400Mhz,因此 MIG IP 核的用户时钟(ui_clk)就是 100Mhz。一般来说高速传输的场合选择 4:1,要求低延时的场合选择 2:1。这里还要指出,当 DDR3 时钟选择选择了 350M 到最高的 400M,比例默认只为 4:1,低于 350M 才有 4:1 和 2:1 两个选项。
VCCAUX_IO:这是 FPGA 高性能 bank(High Performance bank)的供电电压。它的设置取决于 MIG控制器运行的周期/频率。当用户让控制器工作在最快频率的时候,系统会默认为 1.8V,当然在 1.8V 下用户可以运行低一点的频率。本实验默认 1.8V。
Memory Type:DDR3 储存器类型选择。本实验选择 Component。
Memory Part:DDR3 芯片的具体型号。本实验选择 MT41J128M16XX-125,这个型号其实和实际硬件原理图上的型号 NT5CC128M16IP-DI 是不同的,这个没关系,只要用户的 DDR3 芯片容量和位宽一致大部分是可以兼容的,其他的型号也是可以的,大家有兴趣可以去尝试。
Memory Voltage:是 DDR3 芯片的电压选择,本实验选 1.5v。
Data Width:数据位宽选择,这里选择 32,因为是 2 块 ddr 拼接而成的。
ECC:ECC 校验使能,数据位宽为 72 位的时候才能使用。本实验不使用它。
Data Mask:数据屏蔽管脚使能。勾选它才会产生屏蔽信号,本实验没用到数据屏蔽,但是在这里还是把它勾选上。
Number of Bank Machines:Bank Machine 的数量是用来对具体的每个或某几个来单独控制的,选择多了控制效率就会高,相应的占用的资源也多,本实验选择 4 个,平均一个 Bank Machine 控制两个 BANK(本次实验的 DDR3 芯片是八个 bank)。
ORDERING:该信号用来决定 MIG 控制器是否可以对它收到的指令进行重新排序,选择 Normal 则允许,Strict 则禁止。本实验选择 Normal,从而获得更高效率。
点击“NEXT”按钮,界面如下图所示。
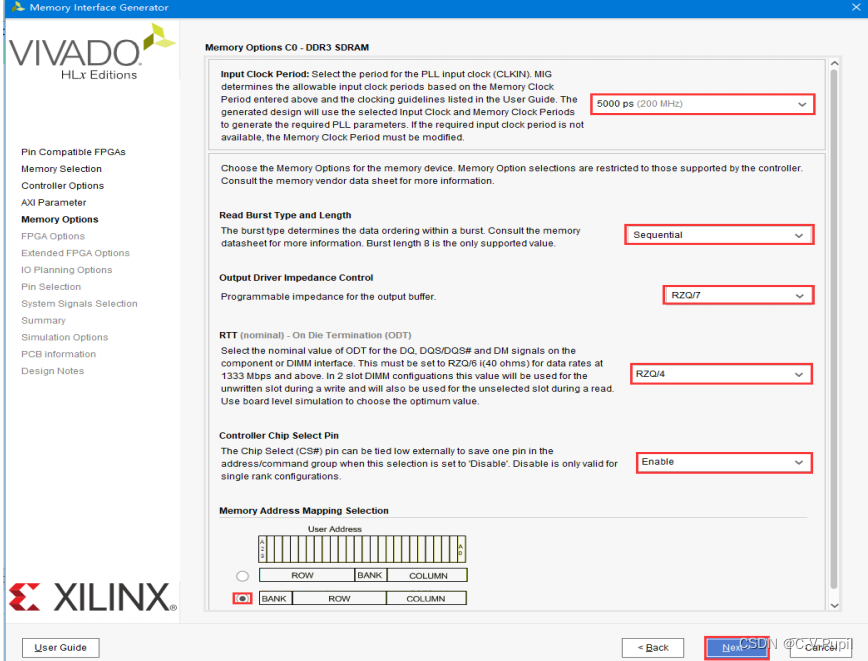
Input Clock Period:MIG IP 核的系统输入时钟周期,该输入时钟是由 FPGA 内部产生的,本次实验选择的时钟频率为 200MHz(5000ps)。
Read Burst Type and Length:突发类型选择,突发类型有顺序突发和交叉突发两种,本实验选择顺序突发(Sequential),其突发长度固定为 8。
【注:】此处Native接口是与硬件直接交互,其位宽上面选择为16位,此处突发长度位8,于是一次写入数据位8*16=128,与AXI接口不同,此处无法随意改变突发长度。
Output Driver Impdance Control:输出阻抗控制。本实验选择 RZQ/7。
RTT:终结电阻,可进行动态控制。本次实验选择 RZQ/4。
Controller Chip Select Pin:片选管脚引出使能。本实验选择 enable,表示把片选信号 cs#引出来,由外部控制。
BANK_ROW_COLUMN:寻址方式选择。本实验选择第二种,即 BANK-ROW-COLUMN 的形式,这是一种最常规的 DDR3 寻址方式,即要指定某个地址,先指定 bank,再指定行,最后指定列,这样就确定了一个具体地址。一般来说这样寻址方式有利于降低功耗,但是读写性能(效率)上不如“ROW_BANK_COLUMN”。配置完成点击“Next”。
如下图所示这是对 MIG IP 系统时钟的属性设置。
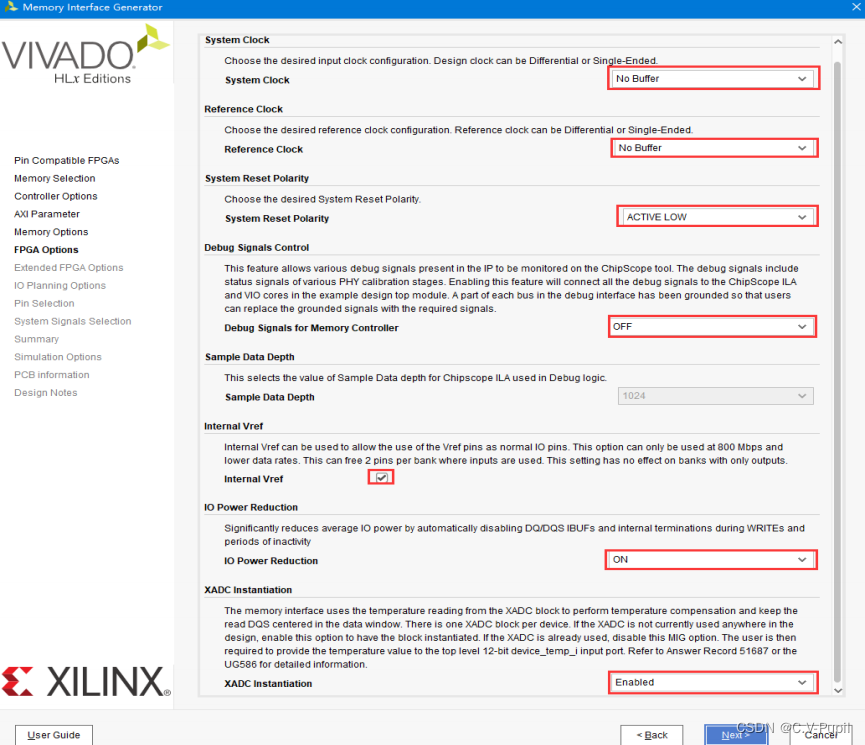
System Clock:MIG IP核输入时钟。本实验选择“No Buffer”, 因为IP核的输入系统时钟是单端时钟,是由内部的MMCM产生的,MMCM所产生的时钟默认添加了buffer。
Reference Clock:MIG IP 核参考时钟。同样选择“No Buffer”,将由时钟模块生成。感兴趣的用户也可以选择“Use System Clock”这个选项,这时候的 MIG IP 系统时钟同时作为了参考时钟,IP 核参考时钟要求是 200Mhz,而 MIG IP 核的系统时钟刚好也使用了 200Mhz 的系统时钟。
System Reset Polarity:复位有效电平选择。本实验选择“ACTIVE LOW”低电平有效。
Debug Signals Control:该选项用于控制 MIG IP 核是否把一些调试信号引出来,它会自动添加到 ILA,这些信号包括一些 DDR3 芯片的校准状态信息。本实验选择选择“OFF”,不需要让 IP 核生产各种调试信号。
Sample Data Depth:采样深度选择。当“Debug Signals Control”选择“OFF”时,所有采样深度是不可选的。
Internal Vref:内部参考管脚,表示将某些参考管脚当成普通的输入管脚来用。由于开发板的 IO 资源较为紧张,因此这里需要选择“ON”,把参考管脚当做普通的输入管脚来用。
IO Power Reduction:IO 管脚节省功耗设置。本实验选择“ON”,即开启。
XADC Instantiation:XADC 模块例化。使用 MIG IP 核运行的时候需要进行温度补偿,可以直接选择XADC 模块的温度数据引到 MIG IP 核来使用,否则需要额外提供温度数据,所以本实验选择“Enable”。
继续点击“NEXT”按钮,界面如下图所示。
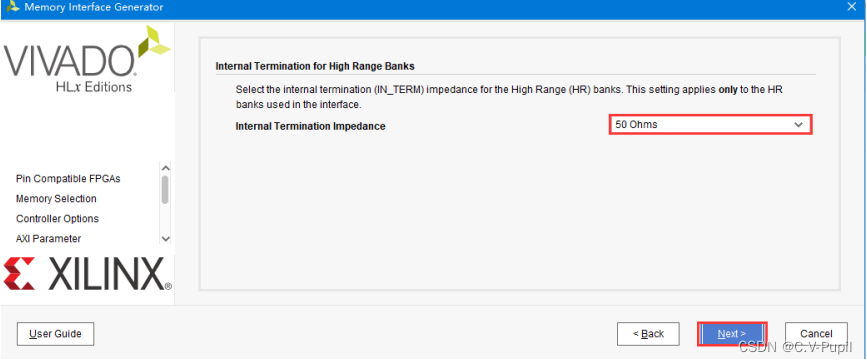 上图界面是内部高性能 bank 端接匹配阻抗的设置,这里不去改它,默认 50 欧姆即可。接下来点击“NEXT”按钮,界面如下图所示。
上图界面是内部高性能 bank 端接匹配阻抗的设置,这里不去改它,默认 50 欧姆即可。接下来点击“NEXT”按钮,界面如下图所示。
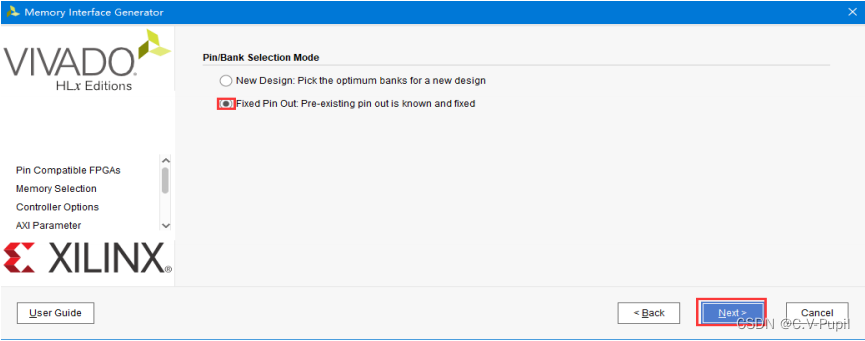
Pin/Bank Selection Mode:管脚模式选择。本次实验选择第二种。
继续点击“Next”按钮,界面如下图所示。
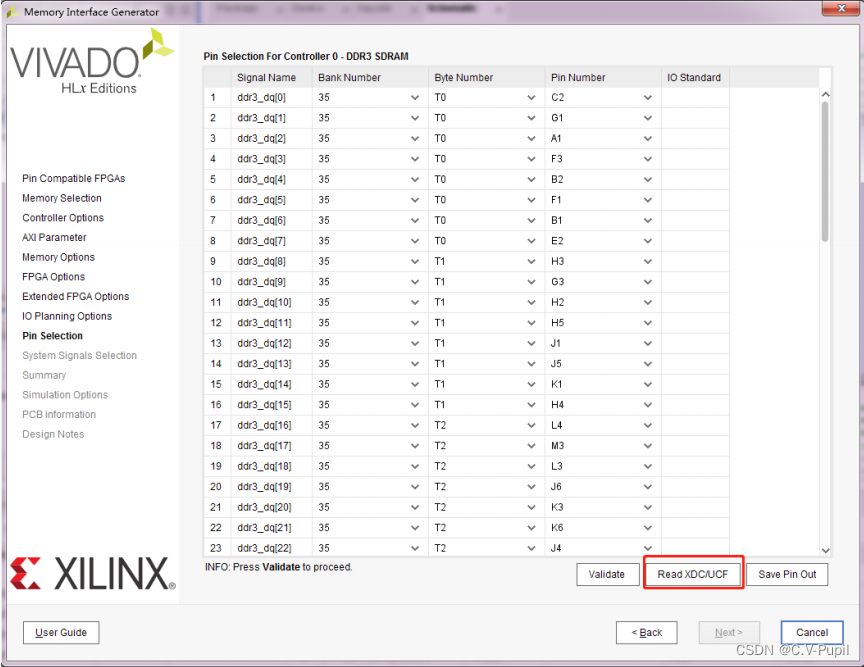
选择“Read XDC/UCF”,直接导入管脚分配文件,紧接着弹出如下图所示界面。

在工程目录下,已经为大家准备好了一个 ddr3_xdc 文件,大家可以直接从例程中拷贝。用户只要直接导入这个 ucf 文件,就可以完成 DDR3 的管脚分配。
如下图,导入后点击“Validate” ,此时会跳出对话框,表明已经验证通过,点击“OK”,此时“Next”变成可选,点击“Next”完成管脚分配。

其他的一路点击next,直到完成创建。
二、MIG 交互的接口
MIG IP 核是 Xilinx 公司针对 DDR 存储器开发的 IP,里面集成存储器控制模块,实现DDR 读写操作的控制流程,下图是 7 系列的 MIG IP 核结构框图。MIG IP 核对外分出了两组接口。左侧是用户接口,就是用户(FPGA)同 MIG 交互的接口,用户只有充分掌握了这些接口才能操作 MIG。右侧为 DDR 物理芯片接口,负责产生具体的操作时序,并直接操作芯片管脚。这一侧用户只负责分配正确的管脚,其他不用关心。
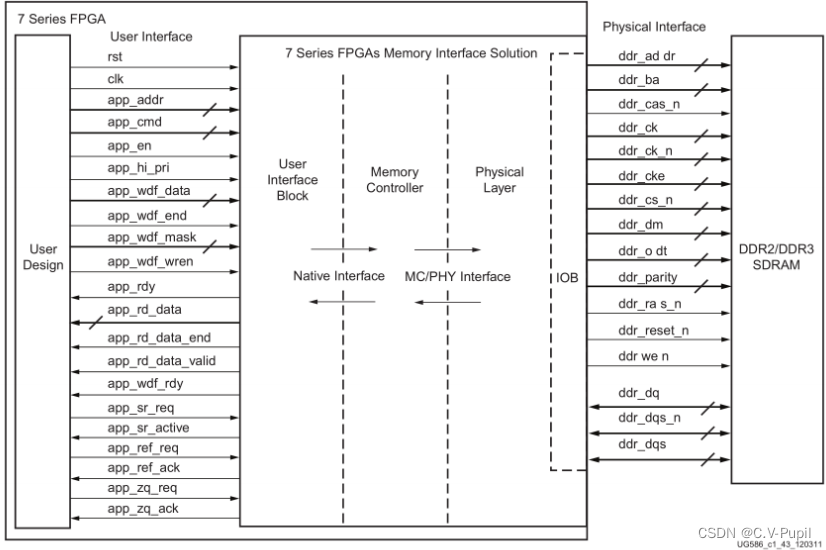
使用这个 IP 核,用户将可以进行 DDR3 的读写操作而不必熟悉 DDR3 具体的读写控制时序,当然用户必须掌握用户接口侧的操作时序,并严格遵照时序来编写代码,这样才能正确实现对 DDR3 的读写操作。在了解具体时序之前,大家有必要先了解相关的信号定义。下图给出了MIG IP 核用户接口的信号及其说明。


MIG IP 核用户侧端口数量共 26 个,当然用户并不用去关心所有的信号,只需要了解本实验要用到几组重要信号。下面将对这些信号逐一讲解并以表格的形式呈现给大家。为了与官方的文档保持一致,表中标明的信号的方向是以MIG IP核作为参照的,例如表格中的信号方向定义为输出,那么相对于用户端(FPGA)来说实际上是输入。
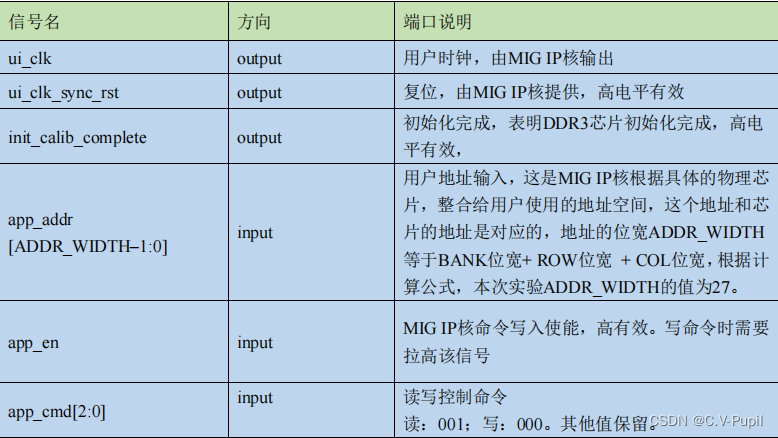
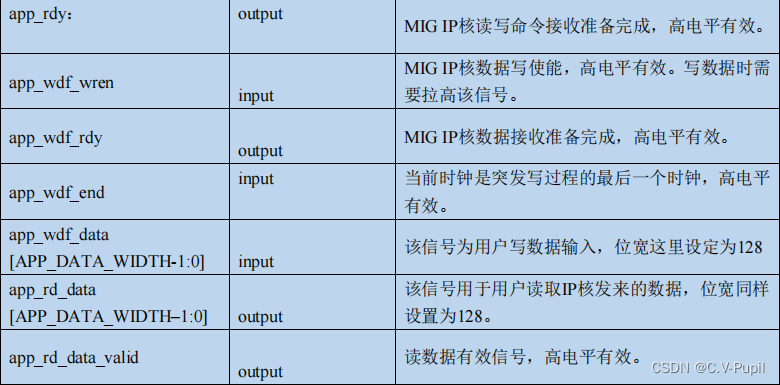
以上是用户需要用到的信号,其他信号请大家自行了解。
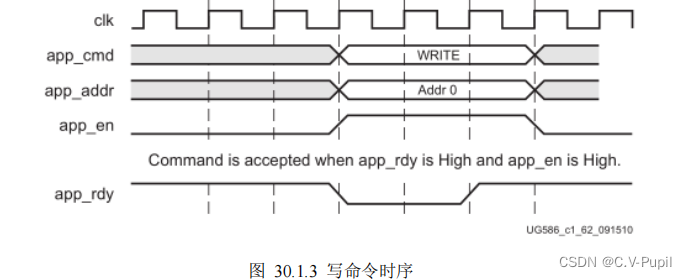
DDR3 的读或者写都包含写命令操作,其中写操作命令(app_cmd)的值等于 0,读操作 app_cmd 的值等于 1。首先来看写命令时序,如下图所示。首先检查 app_rdy,为高则表明此时 IP 核命令接收处于准备好状态,可以接收用户命令,在当前时钟拉高 app_en,同时发送命令(app_cmd)和地址(app_addr),此时命令和地址被写入。
下面来看写数据的时序,如下图所示。

如上图所示,写数据有三种情形均可以正确写入:
(1)写数据时序和写命令时序发生在同一拍;
(2)写数据时序比写命令时序提前一拍;
(3)写数据时序比写命令时序至多延迟晚两拍;
结合上图,写时序总结如下:首先需要检查 app_wdf_rdy,该信号为高表明此时 IP 核数据接收处于准备完成状态,可以接收用户发过来的数据,在当前时钟拉高写使能(app_wdf_wren),给出写数据(app_wdf_data)。这样加上发起的写命令操作就可以成功向 IP 核写数据。这里有一个信号 app_wdf_mask,它是用来屏蔽写入数据的,该信号为高则屏蔽相应的字节,该信号为 0 默认不屏蔽任何字节。
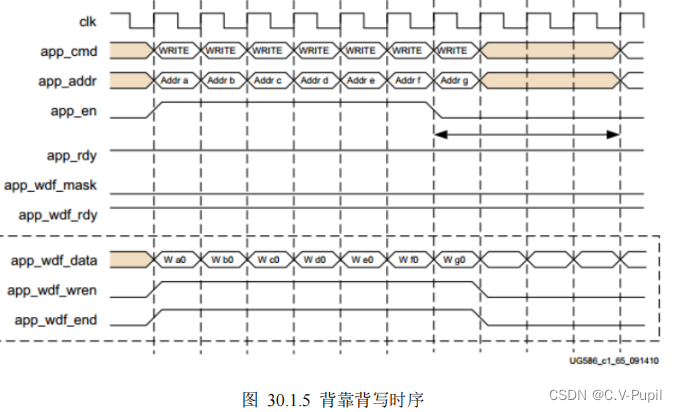
这里需要指出的是 DDR3 的读或者写操作都可以分为背靠背和非背靠背两种情形。背靠背,即读或者写每个时钟都连续进行,中间没有间隙。非背靠背写则是非连续的读写。对于背靠背写,其实也有三种情形,唯一点不同的是,它没有最大延迟限制,如下图所示。
接着来看读数据,如下图所示:
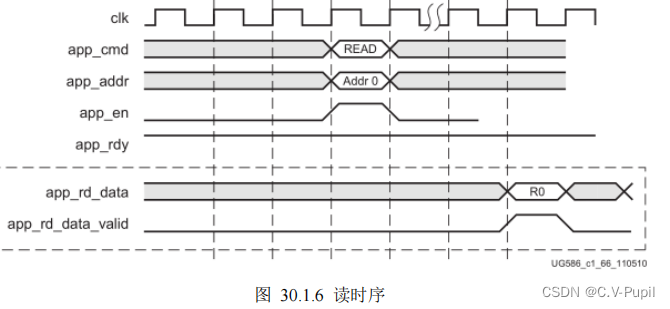
读时序比较简单,发出读命令后,用户只需等待数据有效信号(app_rd_data_valid)拉高,为高表明此时数据总线上的数据是有效的返回数据。需要注意的是,在发出读命令后,有效读数据要晚若干周期才出现在数据总线上。下面是背靠背读的情况,如下图所示。

这里还需要注意一点,在连续读的时候,读到的数据顺序跟请求的命令/地址是相对应的。通常使用DDR3 的时候,为了最大限度地提高 DDR3 效能,充分利用突发写的特点,非背靠背很少用,而更多地采用背靠背操作。本章实验的读写操作就是基于背靠背模式进行的。
三、常用IP例化值
mig_7series_native u_mig_7series_native (// Memory interface ports.ddr3_addr (ddr3_addr ), // output [13:0] ddr3_addr.ddr3_ba (ddr3_ba ), // output [2:0] ddr3_ba.ddr3_cas_n (ddr3_cas_n ), // output ddr3_cas_n.ddr3_ck_n (ddr3_ck_n ), // output [0:0] ddr3_ck_n.ddr3_ck_p (ddr3_ck_p ), // output [0:0] ddr3_ck_p.ddr3_cke (ddr3_cke ), // output [0:0] ddr3_cke.ddr3_ras_n (ddr3_ras_n ), // output ddr3_ras_n.ddr3_reset_n (ddr3_reset_n ), // output ddr3_reset_n.ddr3_we_n (ddr3_we_n ), // output ddr3_we_n.ddr3_dq (ddr3_dq ), // inout [15:0] ddr3_dq.ddr3_dqs_n (ddr3_dqs_n ), // inout [1:0] ddr3_dqs_n.ddr3_dqs_p (ddr3_dqs_p ), // inout [1:0] ddr3_dqs_p.init_calib_complete (init_calib_complete), // output init_calib_complete.ddr3_cs_n (ddr3_cs_n ), // output [0:0] ddr3_cs_n.ddr3_dm (ddr3_dm ), // output [1:0] ddr3_dm.ddr3_odt (ddr3_odt ), // output [0:0] ddr3_odt// Application interface ports.app_addr (app_addr ), // input [27:0] app_addr.app_cmd (app_cmd ), // input [2:0] app_cmd.app_en (app_en ), // input app_en.app_wdf_data (app_wdf_data ), // input [127:0] app_wdf_data.app_wdf_end (app_wdf_end ), // input app_wdf_end.app_wdf_wren (app_wdf_wren ), // input app_wdf_wren.app_rd_data (app_rd_data ), // output [127:0] app_rd_data.app_rd_data_end (app_rd_data_end ), // output app_rd_data_end.app_rd_data_valid (app_rd_data_valid), // output app_rd_data_valid.app_rdy (app_rdy ), // output app_rdy.app_wdf_rdy (app_wdf_rdy ), // output app_wdf_rdy.app_sr_req (1'b0 ), // input app_sr_req.app_ref_req (1'b0 ), // input app_ref_req.app_zq_req (1'b0 ), // input app_zq_req.app_sr_active (app_sr_active ), // output app_sr_active.app_ref_ack (app_ref_ack ), // output app_ref_ack.app_zq_ack (app_zq_ack ), // output app_zq_ack.ui_clk (ui_clk ), // output ui_clk.ui_clk_sync_rst (ui_clk_sync_rst ), // output ui_clk_sync_rst.app_wdf_mask (16'h0000 ), // input [15:0] app_wdf_mask// System Clock Ports.sys_clk_i (loc_clk200M ),.sys_rst (xx_sys_rst ) // input sys_rst);
四、小实验传图
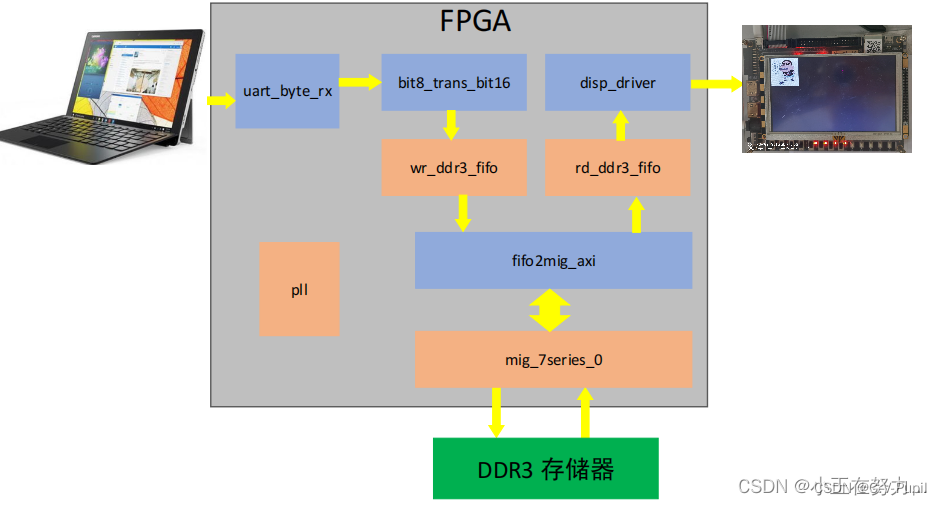
本次传图小实验见【基于 DDR3 的native接口串口传图帧缓存系统设计实现】。