目录
一、概述
二、小样本学习的数据集
1、Omniglot
2、MiniimageNet
三、孪生网络
四、三元组损失函数
一、概述
小样本学习用于处理训练数据集中样本数量少的情况,一般来说,小样本学习流程是这样的,从一个多种类少量样本的巨大数据集中训练一个Pretrained网络模型(这一步不需要做),之后可以基于预训练模型根据微调、元学习或度量方法进行fine-tune,做到对查询集的一个分类和识别。
小样本学习的LibFewShot库:https://github.com/RL-VIG/LibFewShot
小样本学习与传统神经网络的区别:
假设训练猫狗分类问题,传统神经网络会从大量带标签的猫狗训练集中进行充分训练,得到较好的模型,然后测试集也是猫狗数据集,只不过是训练集中没有的图片,模型将对测试集进行分类。
小样本学习首先在一个较大的较多类别,每个类别较少数据的数据集(即辅助集,不包含猫狗类别)中进行预训练,通过迁移学习对预训练模型进行微调,微调时会利用一个Support set(支持集),支持集包含猫狗的图片和标签,根据支持集的类别共K类和每个类别的图片数量n张,又叫做K-way n-shot小样本问题,通常K取5或10,n取1或5。通过在支持集进行微调,达到少量样本完成对查询集(测试集,猫狗测试集)的分类。
小样本学习,不需要传统神经网络的过高层数,过多的融合来寻找分类的特征从而知道如何分类,而是通过有限的支持集进行相似度匹配,来达到分类的效果。
小样本学习例子:
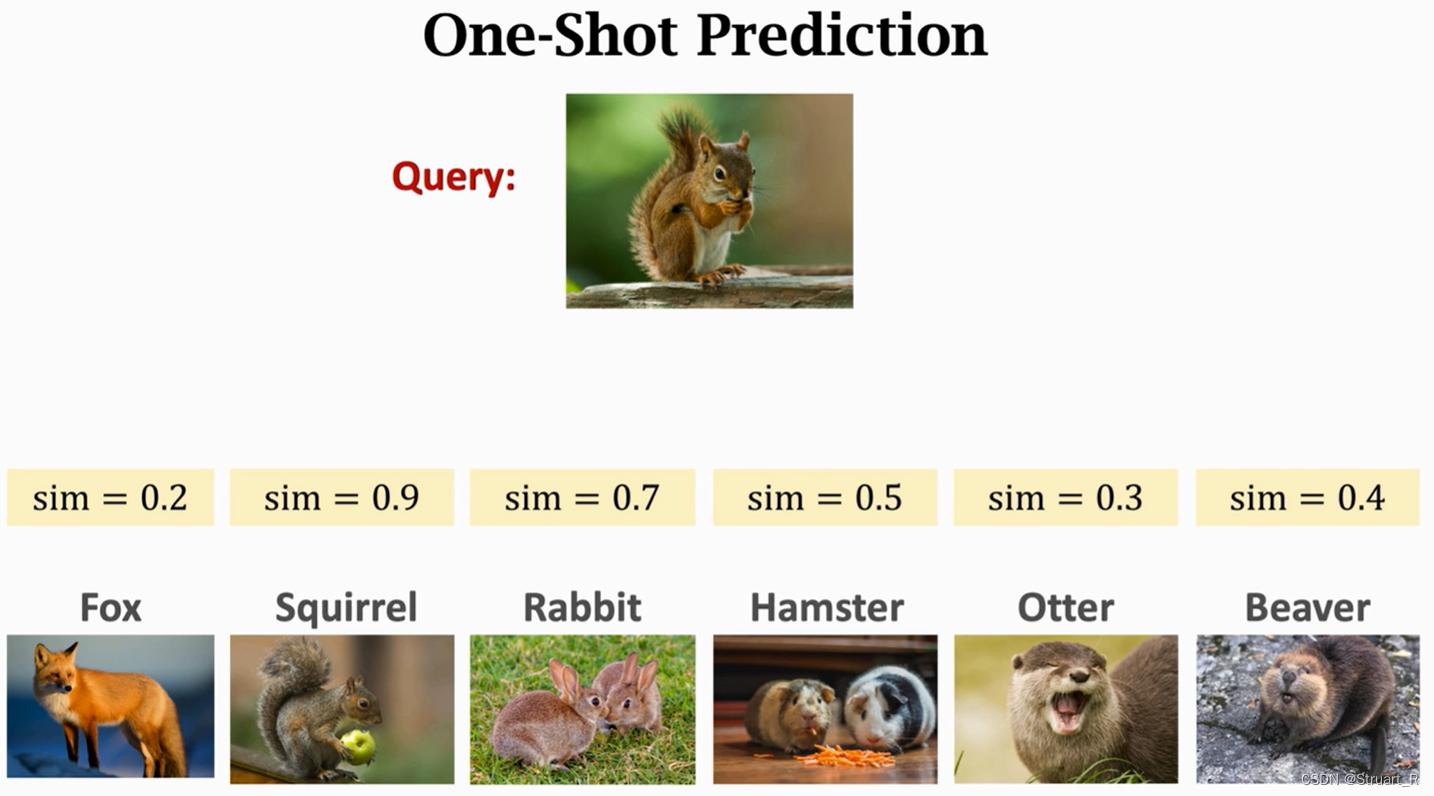
下图的Query:兔子就是测试集,而辅助集在训练时没有见过兔子类,那么他是如何分类的呢?
通过依赖支持集Support Set对于预训练模型进行微调,来获得水獭与测试图片相似度最高的标签。

另外 K-way n-shot的举例如下:
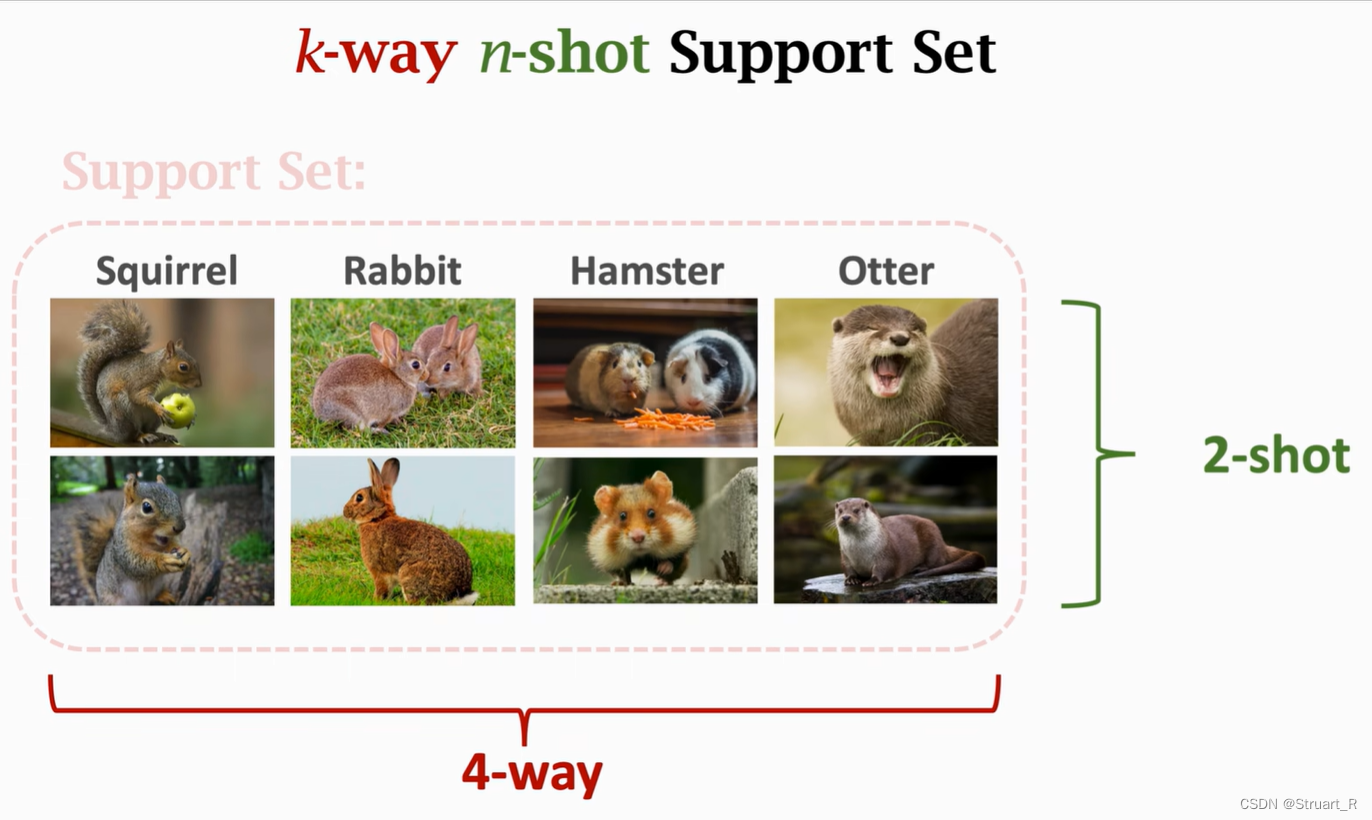
K-way n-shot与测试集的Accuracy的关系:
(1)支持集类别数越多,测试集Accuracy越低,因为测试图片占测试种类的比例下降了。
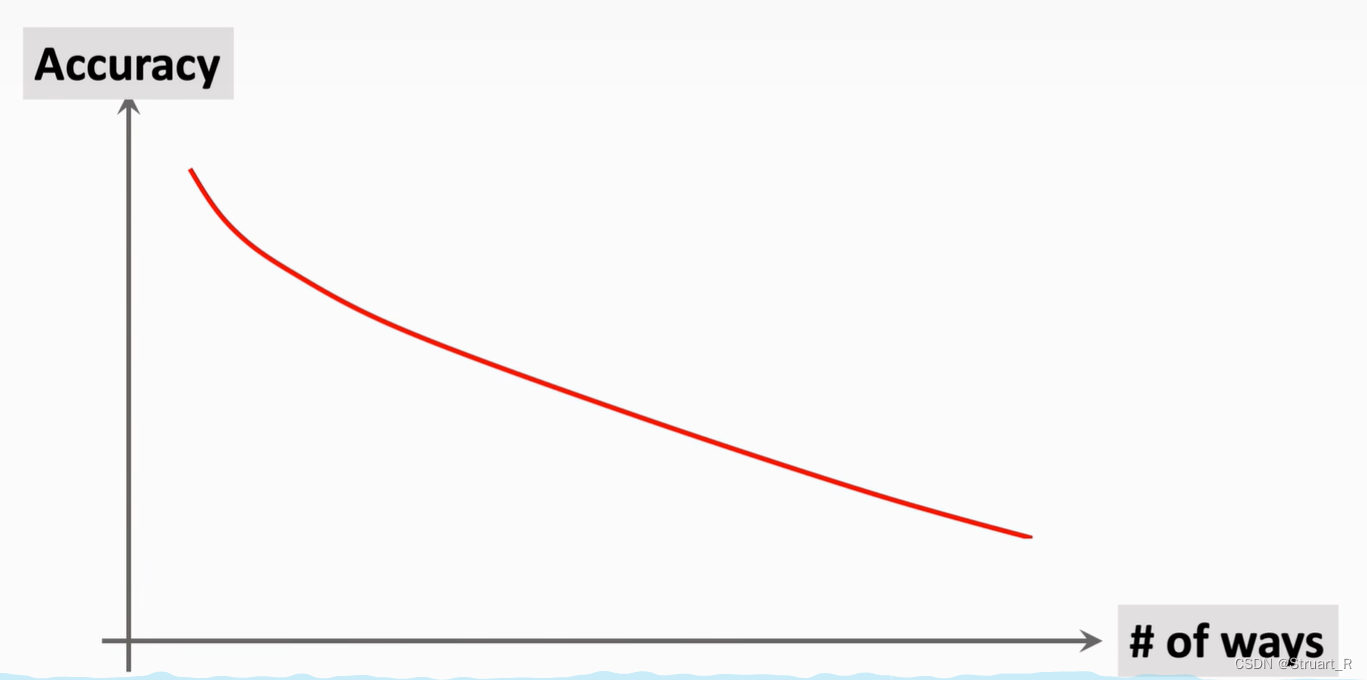
(2)支持集图片越多,测试集Accuracy越高,这个很好理解,图片越多学的越好。
二、小样本学习的数据集
1、Omniglot
Omniglot是全语言文字数据集,包含50种语言的字母表,共计1623个类,每个字母由20个不同的人书写,也就是每个字母仅有20张图片,每个图片的像素为105*105。Omniglot数据集分为训练集和测试集,训练集有30个字母表,964个字符,测试集有20个字母表,659个字符,训练集和测试集类别不同,也就是说预训练也是进行的小样本学习,Omniglot数据集一般用作小样本训练。

2、MiniimageNet
MiniimageNet是一个从ImageNet数据集中抽取的数据集,一共100个类别,每个类别600张图片,共计6万张图片。MiniimageNet数据集的训练集64个类别,验证集16个类别,测试集20个类别。Miniimagenet用于针对各种生物、物品的小样本学习数据集。

三、孪生网络
孪生网络,利用相同样本和不同样本之间的区别,训练出一个能够分类的神经网络。
首先将训练集分成正负样本,且样本数量相等的三元组形式,类别相同的图片为正样本,类别不同的图片(首先选取一张图片a,再找从不属于a的图片中随机取样b图片)为负样本。

孪生网络前向传播输入两张图片,经过映射得到两个列向量,向量作差得到z层,经过全连接网络和激活函数,与所给target计算损失函数,并进行反向传播修改权重。
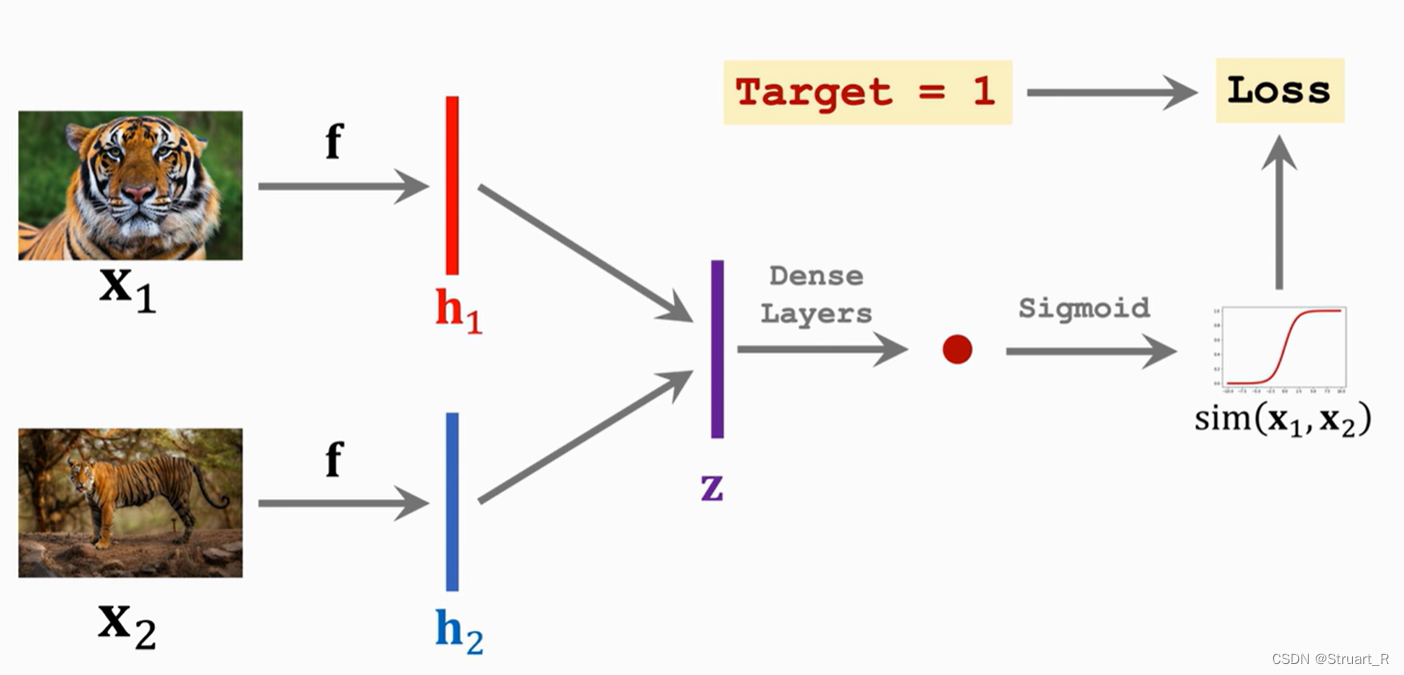
注意这个网络只是简单的一个解释,内部的网络已经更新换代,但大体依旧是输入两张图片与一个Target训练该模型。如下图这种就是图片映射的列向量进入网络层,而没有直接做差。
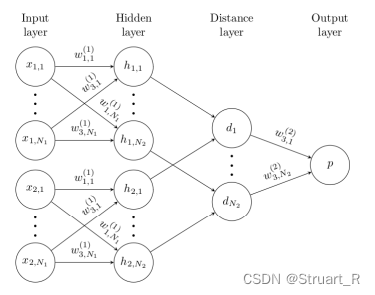
测试模型时,根据测试集与支持集的不同类别计算相似度,相似度最大的记为本次测试的类别。
四、三元组损失函数
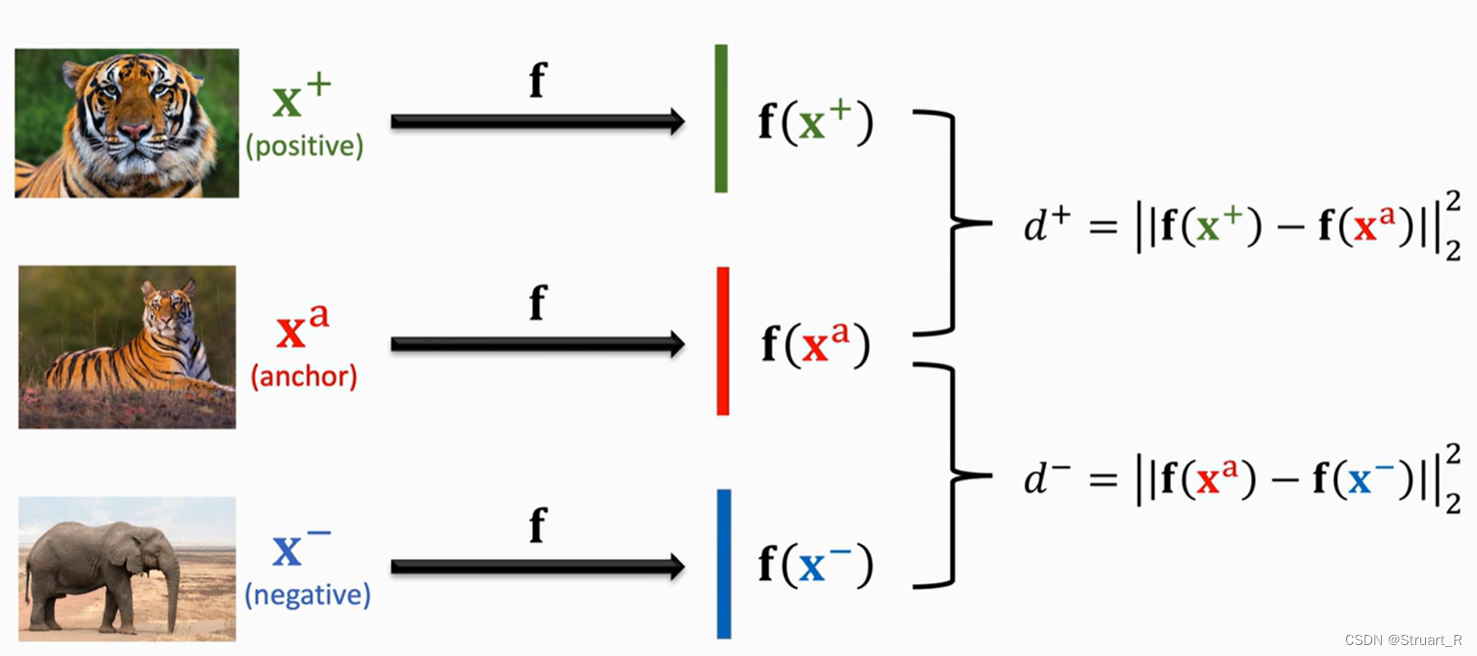
三元组损失(Triplet Loss),是基于度量的小样本学习中的损失函数方法。首先从训练集中随机选择一张图片作为anchor,如下图中第一张老虎图片,再根据anchor的类别寻找该类的随机一张图片作为Positive,最后从trainset除去老虎类,随机抽取一张图片记为Negative。

根据三张图片,正样本和负样本去计算与anchor的2-范数,也就是几何距离,记作d+和d-,d+越小越好,正样本越接近anchor,d-越大越好,负样本越远离anchor。
如果d+=d-那么相当于随机模型,所以训练好的模型必须满足,我们定义三元组损失为
根据三元组损失计算预测图片与支持集中图片的距离dist,通过比较距离中最短的一个,就可以确定预测图片所属的类别。

相关视频:Siamese Network (孪生网络) (2/3)_哔哩哔哩_bilibili




![[uni-app] canvas绘制圆环进度条](https://img-blog.csdnimg.cn/1d2e9493e93246018115ae6dd13dd41a.png)
