目录
- Padding: 填充
- 步幅(stride)
- Pooling Layer:池化层
- Batch Normalization
- Separable Convolutions
- REFERENCE
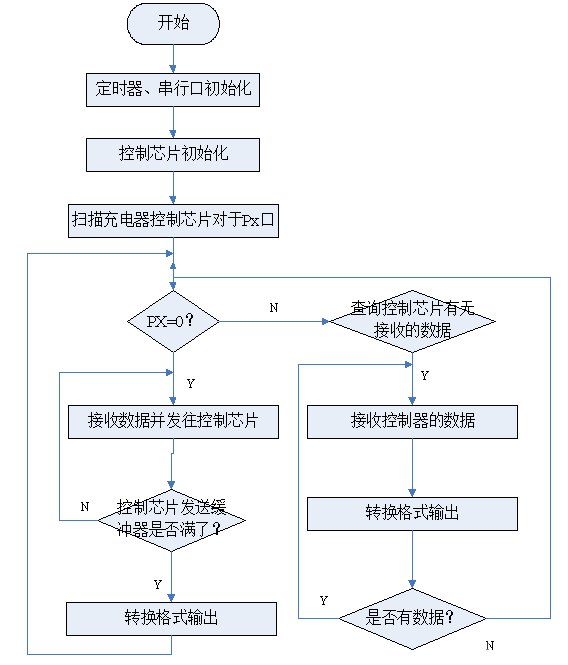
Padding: 填充
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比
如0等),这称为填充(padding),是卷积运算中经常会用到的处理。比如,
在图7-6的例子中,对大小为(4, 4)的输入数据应用了幅度为1的填充。“幅
度为1的填充”是指用幅度为1像素的0填充周围

使用填充主要是为了调整输出的大小。比如,对大小为(4, 4)的输入
数据应用(3, 3)的滤波器时,输出大小变为(2, 2),相当于输出大小
比输入大小缩小了 2个元素。这在反复进行多次卷积运算的深度网
络中会成为问题。为什么呢?因为如果每次进行卷积运算都会缩小
空间,那么在某个时刻输出大小就有可能变为 1,导致无法再应用
卷积运算。为了避免出现这样的情况,就要使用填充。在刚才的例
子中,将填充的幅度设为 1,那么相对于输入大小(4, 4),输出大小
也保持为原来的(4, 4)。因此,卷积运算就可以在保持空间大小不变
的情况下将数据传给下一层。
步幅(stride)
应用滤波器的位置间隔称为步幅(stride)。之前的例子中步幅都是1,如
果将步幅设为2,则如图7-7所示,应用滤波器的窗口的间隔变为2个元素

Pooling Layer:池化层
池化是缩小高、长方向上的空间的运算。比如,如图7-14所示,进行将
2 × 2的区域集约成1个元素的处理,缩小空间大小。

图7-14的例子是按步幅2进行2 × 2的Max池化时的处理顺序。“Max
池化”是获取最大值的运算,“2 × 2”表示目标区域的大小。如图所示,从
2 × 2的区域中取出最大的元素。此外,这个例子中将步幅设为了2,所以
2 × 2的窗口的移动间隔为2个元素。另外,一般来说,池化的窗口大小会
和步幅设定成相同的值。比如,3 × 3的窗口的步幅会设为3,4 × 4的窗口
的步幅会设为4等。
特征
- 没有要学习的参数:池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。
- 通道数不发生变化:经过池化运算,输入数据和输出数据的通道数不会发生变化。如图7-15所示,计算是按通道独立进行的
- 对微小的位置变化具有鲁棒性(健壮)
输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对
输入数据的微小偏差具有鲁棒性。比如,3 × 3的池化的情况下,如图
7-16所示,池化会吸收输入数据的偏差(根据数据的不同,结果有可
能不一致)
Batch Normalization
Batch Norm,顾名思义,以进行学习时的mini-batch为单位,按minibatch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的
正规化。
优点:
- 可以使学习快速进行(可以增大学习率)
- 不那么依赖初始值(对于初始值不用那么神经质)。
- 抑制过拟合(降低Dropout等的必要性)
Separable Convolutions
- Spatial Separable Convolutions
- Depthwise Separable Convolutions
Learn more at link
REFERENCE
深度学习入门:基于python的理论与实现