首先,在ChatGPT中输入提示词:
写一段Python代码:
F盘文件夹“新三板 2023年日常性关联交易20230704”中很多个PDF文件,用 Tabula提取这些PDF文件中第1页中的第2个表格,然后保存到表格文件中,文件标题名和原PDF文件保持一致;
注意:表格中的元素,如果为None,则替换为空字符串,避免出现TypeError错误;
注意:每一步骤都要输出信息
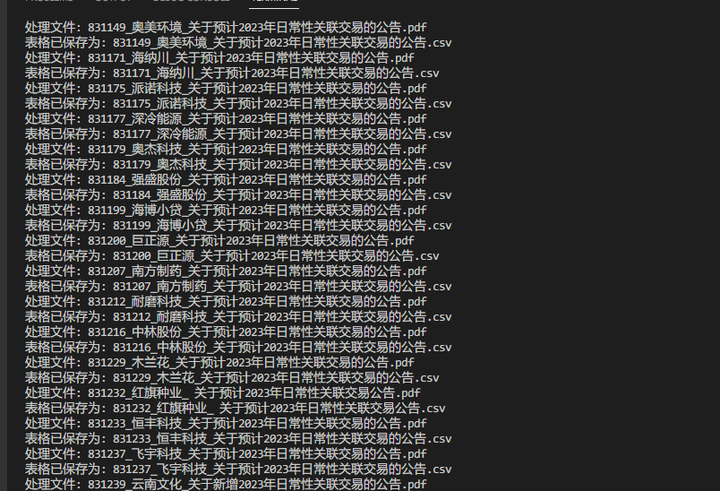
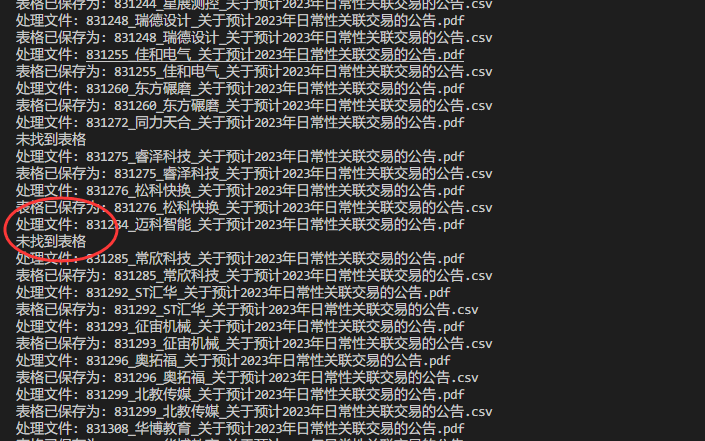
个别未找到表格;
然后让ChatGPT合并所有这些表格到一张表里面,输入提示词如下:
写一段Python程序:
在F盘“新三板2023年日常性关联交易20230704”中新建一个文件,文件标题为:newexcel.xlsx
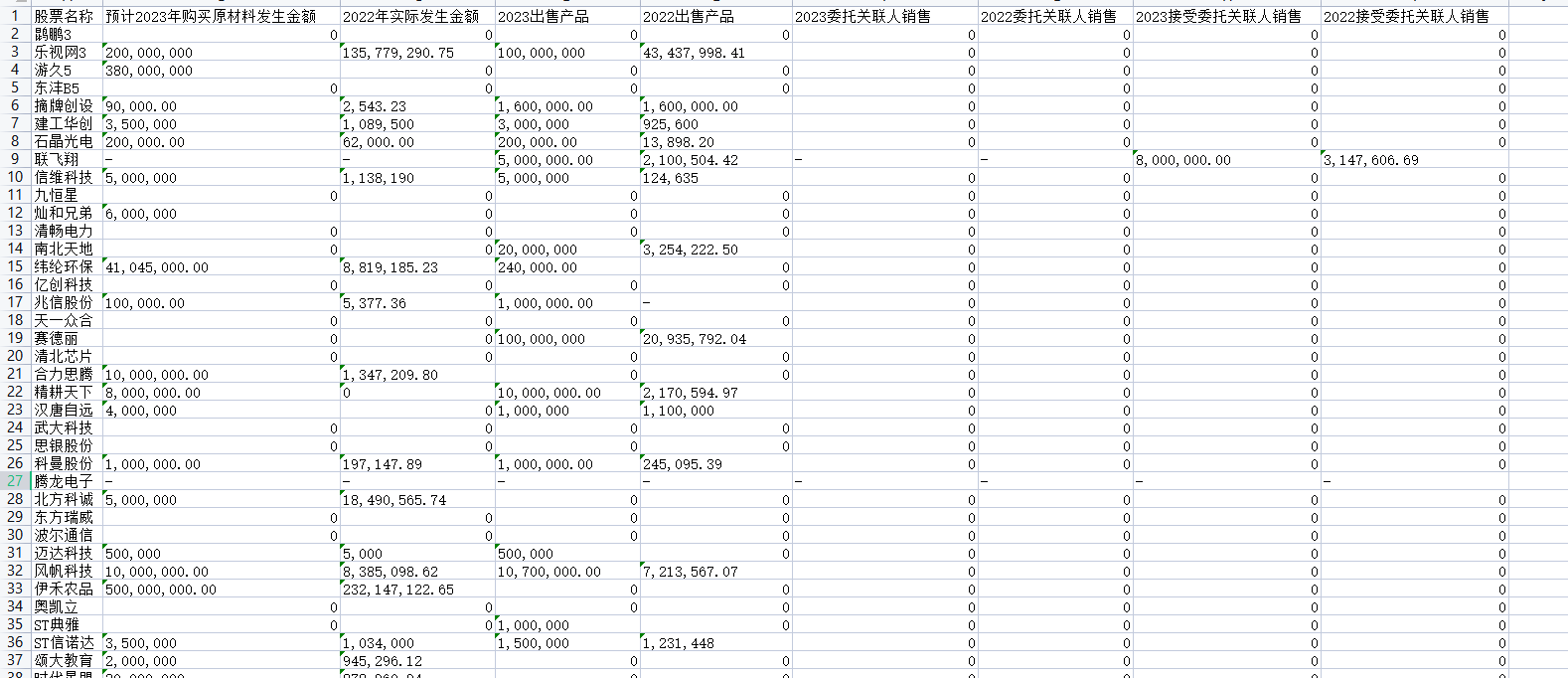
表格的表头为:股票名称、 预计2023年购买原材料发生金额、2022年实际发生金额、2023出售产品、2022出售产品、2023委托关联人销售、2022委托关联人销售、2023接受委托关联人销售、2022接受委托关联人销售;
打开F盘“新三板2023年日常性关联交易20230704”文件夹中所有的CSV文件;
获取CSV文件的文件名,截取两个“_”中间的股票名称,写入newexcel表格中的A{2}单元格(2为变量,从2开始,间隔+1),比如“430105_合力思腾_关于预计2023年日常性关联交易的公告”截取“合力思腾”;
获取CSV文件中的“C2”、“D2”、“C3”、“D3”、“C4”、“D4”、“C5”、“D5”单元格内容,构成一个数组,如果单元格内容为空,就赋值为0;
打印出这个数组内容;
然后按顺序写入newexcel表格中的B{2}到I{2}单元格(2为变量,从2开始,间隔+1);
打印出写入newexcel表格的内容;
注意:
每一步都要输出信息;
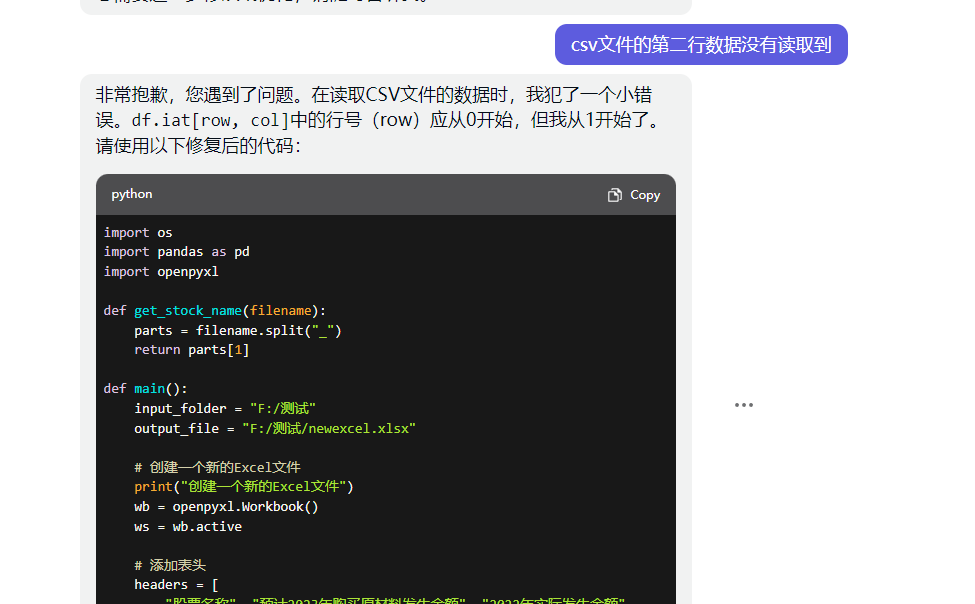
运行后,虽然合并了表格,但是数据是不对的,第二行数据没有。ChatGPT的回复是:读取CSV文件的数据时,df.iat[row, col]中的行号(row)应从0开始;
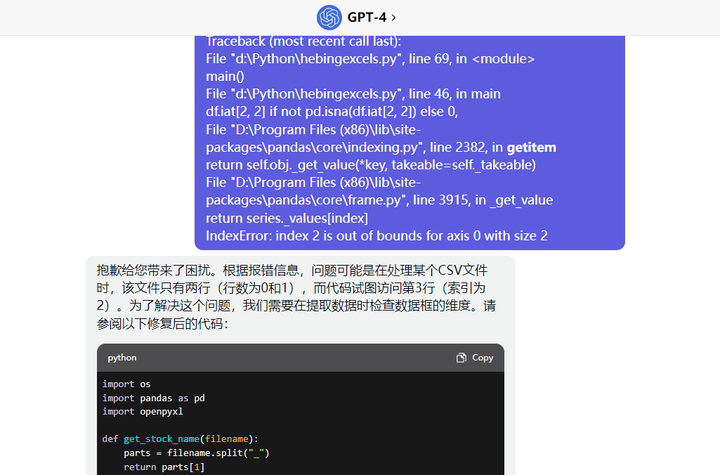
修正后,又出现问题。ChatGPT的回复是:需要在提取数据时检查数据框的维度。请参阅以下修复后的代码:
再次运行,成功。
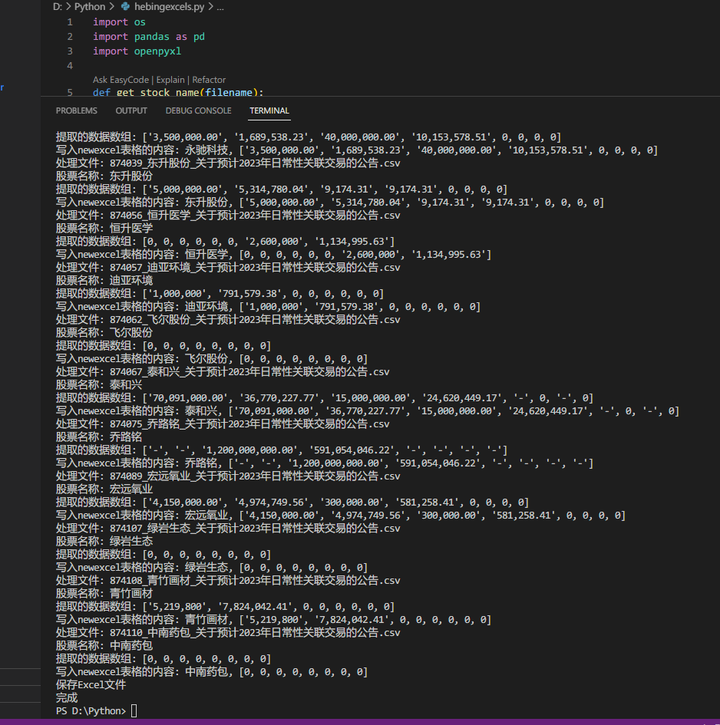
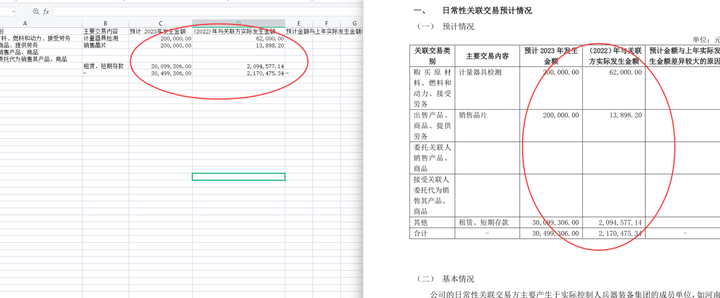
上千个excel表格合并到一张表中了: