CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,与XGBoost、LightGBM并称为GBDT三大主流神器库。LightGBM和XGBoost已经在各领域得到了广泛的应用,而Yandex的CatBoost作为后起之秀则是号称比XGBoost和LightGBM在算法准确率等方面表现更为优秀的算法。
CatBoost的名称来源于”Category”和”Boosting”两个词。”Boosting”表明CatBoost和XGBoost、LightGBM一样,都是在梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法框架下的一种改进实现;而”Category”则体现了CatBoost最显著的一个特点,即它可以很好的处理类别型特征(Categorical Features)数据。在我们风控领域的建模中,类别型特征是十分常见的,比如用户的性别、职业、教育程度等等。
相较于XGBoost和LightGBM,CatBoost可以使我们在模型训练之前不再需要通过特征工程去处理分类型特征;同时CatBoost使用对称树作为基模型,并提出了新的方法来处理梯度偏差和预测偏移问题,减少了模型过拟合的可能,提升了模型预测的效果。可以预见,在风控建模中引入CatBoost算法会有着非常优异的表现。
下面我们针对CatBoost算法的主要特点逐一展开介绍:
一、类别型特征
1.Ordered TS编码
像XGBoost这样的算法是不接受类别型特征的输入的,因此在模型训练之前就需要对类别型特征进行特征工程处理。而特征工程中又有许多处理方法,比如分箱处理、one-hot编码、TS(target statistics)编码、label编码等。具体的方式选择取决于我们的主观经验以及调试结果。
CatBoost则设计了一直类似均值编码的,基于预测目标统计值的方法将类别特征转化为数值特征,这种方法称之为Ordered Target Statistics数值编码方法,可以有效解决梯度偏差和预测偏移的问题,降低模型过拟合的可能。它的流程如下:
对数据集多次随机排序,产生多组随机排列的情况。
将浮点型或属性值标记转化为整数。
对于每个样本的该类别特征中的某个取值,基于该样本之前的类别编码值取均值,同时加入先验的权重系数,转换为数值型结果。
由于CatBoost算法对样本进行了多次随机排序,在不同轮次的迭代中,会得到不同排序状态的样本集,综合起来使得模型方差更小,这种随机性可以减少过拟合。
2.特征交叉
特征交叉是指将样本集中的类别型特征进行组合,形成新的类别型特征。这是特征工程中的一种方式,可以丰富特征的维度。当然这些新的特征不一定都是有用的,需要结合实际业务场景和意义进一步筛选。
CatBoost在将类别特征转换为数值编码的同时,会自动产生交叉特征。但当样本集中的类别型特征较多的时候,如果让所有类别特征都两两,甚至三三及以上相互组合,产生的新特征又太多了。
CatBoost使用一种贪心的策略来进行特征交叉。在生成树选择第一个节点时,不使用交叉特征,而只考虑选择一个特征,如A;在生成第二个节点时,考虑A和任意一个类别型特征的组合,选择其中最优的,就这样使用贪心算法生成新的特征。
3.克服梯度偏差和预测偏移
在使用XGBoost和LightGBM的时候,经常会发生模型在训练集拟合的特别好,但是在测试集上却差强人意,这很有可能是由于模型太复杂了,造成了过拟合。
构建一棵树有两个阶段:一是选择树结构,二是计算叶节点的值。我们知道梯度提升算法都是通过构建新树来拟合当前模型的梯度。在训练下一棵树的时候,需要计算前面树构成的加法模型在所有样本上的一阶梯度和二阶梯度,然后用这些梯度来决定下一棵树的结构和叶子节点取值。但这是有偏的,前面的树是在这些样本上训练的,现在我们又在相同的样本上估计模型预测结果的梯度,应该换新的样本才合理。
而CatBoost和之前说的一样,先将样本随机打乱,每个样本只用排序在他前面的样本来训练模型,来估计预测结果的梯度,然后构建下一棵树的结构,最终树的每个叶子节点的取值则是用全体样本进行计算。这种方法可以有效减少梯度偏差,缓解预测偏移,缺点是增加了计算量,影响训练速度。
二、完全对称二叉树
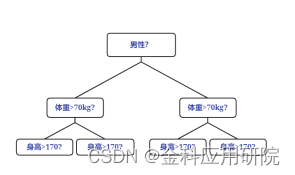
XGBoost一层层建立节点(level-wise),LightGBM一个个地建立节点(leaf-wise),而CatBoost则采用完全对称二叉树作为基树模型,这种树的特点是每一层使用相同的分割特征。叶子节点可以被转化为二进制编码,结点的值被存储在一个长度为2的d次方(d为树的深度)的浮点向量中。这种树的一个优点是预测性能更好、速度更快,同时这种结构也能一定程度弱化决策树容易过拟合的缺点。
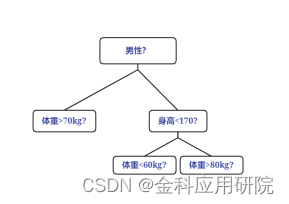
非对称树:
对称树:
三、优缺点
在实际的应用中,相比于XGBoost和LightGBM而言,CatBoost在类别型特征较多的时候更能发挥自身的优势,总结而言主要有以下几大优点:
性能优异:
足以匹敌任何先进的机器学习算法,在某些情况下能比XGBoost和LightGBM有更高的精准性和泛用性;
稳健性:
它减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性;
实用:
可以处理类别型、数值型特征,支持自定义损失函数;
易用:
提供scikit集成的Python接口,支持自动调参。
当然,CatBoost也有一些缺点:
对于类别型特征的处理需要大量的内存和时间;
不同随机数的设定对于模型预测结果有一定的影响。
四、总结
在信贷风控场景中,LightGBM和XGBoost已经得到了充分的应用,而CatBoost算法的使用还相对较少。这是因为这个算法比较新,国内对它的研究也比较少。当实际业务中的数据包含较多的类别型特征的时候,我们不妨可以试试这个简单而又强力的后起之秀,说不定能得到意外的效果。