文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者公众号【AIShareLab】回复 pytorch教程 也可获取。
文章目录
- 数据增强 Data Augmentation
- 裁剪Crop
- transforms.CenterCrop
- transforms.RandomCrop
- transforms.RandomResizedCrop
- transforms.FiveCrop(TenCrop)
- 翻转Flip
- transforms.RandomHorizontalFlip(RandomVerticalFlip)
- transforms.RandomVerticalFlip(p=1)
- 旋转Rotation
- transforms.RandomRotation
数据增强 Data Augmentation
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。
技巧:
debug console:命令输入窗的环境与当前代码调试的环境完全一致,可以对变量进行更改或者查看。
例如这里对于输入变量的shape进行了查看。
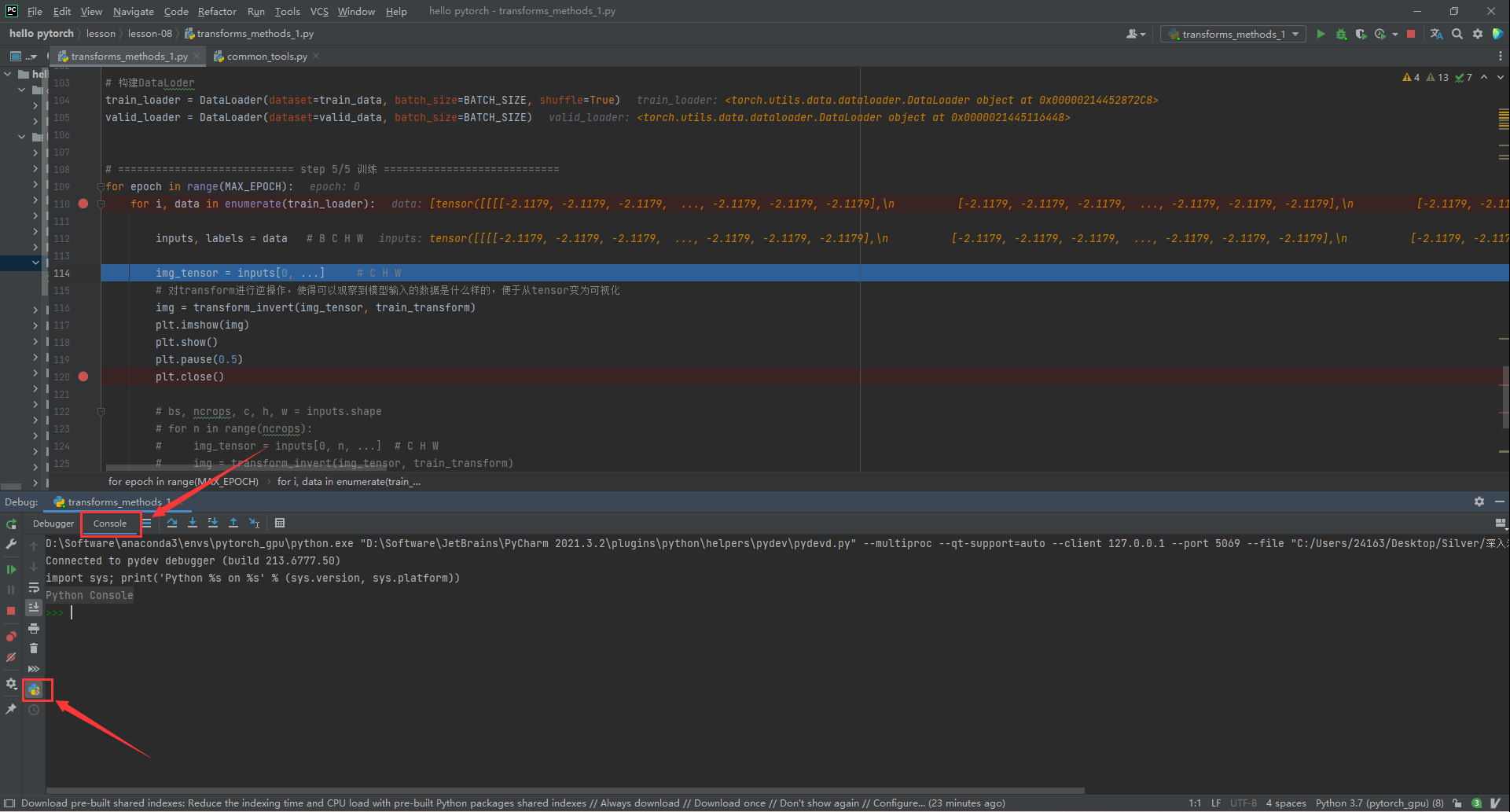

由于图片经过 transform 操作之后是 tensor,像素值在 0~1 之间,并且标准差和方差不是正常图片的。所以定义了transform_invert()方法。功能是对 tensor 进行反标准化操作,并且把 tensor 转换为 image,方便可视化。
主要修改的是transforms.Compose代码块中的内容,其中transforms.Resize((224, 224))是把图片缩放到 (224, 224) 大小,然后再进行其他 transform 操作。
裁剪Crop
transforms.CenterCrop
torchvision.transforms.CenterCrop(size)
功能:从图像中心裁剪图片
- size :所需裁剪图片尺寸
CenterCrop:以中心裁剪,如果裁剪尺寸小于原尺寸,则显示裁剪后的部分,否则对于多出的部分填充为0的像素(即黑色)。
transforms.RandomCrop
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
功能:从图片中随机裁剪出尺寸为size 的图片,若有 padding,那么先进行 padding,再随机裁剪 size 大小的图片。
-
size: 裁剪大小
-
padding: 设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
- 当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
-
pad_if_need: 当图片小于设置的 size,是否填充
-
padding_mode:
-
constant: 像素值由 fill 设定
-
edge: 用图像边缘的像素值进行填充
-
reflect: 镜像填充,最后一个像素不镜像。([1,2,3,4] -> [3,2,1,2,3,4,3,2])
可见,1和4均没有镜像。
-
symmetric: 镜像填充,最后一个像素也镜像。([1,2,3,4] -> [2,1,1,2,3,4,4,4,3])
-
-
fill: 当 padding_mode 为 constant 时,设置填充的像素值,如果不设置,则默认填充为0。
transforms.RandomResizedCrop
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(3 / 4, 4 / 3), interpolation=2)
功能:随机大小、随机宽高比裁剪图片。首先根据 scale 的比例裁剪原图,然后根据 ratio 的长宽比再裁剪,最后使用插值法把图片变换为 size 大小。
- size: 裁剪的图片尺寸
- scale: 随机缩放面积比例,默认随机选取 (0.08, 1) 之间的一个数,可以自行修改范围。
- ratio: 随机长宽比,默认随机选取 ( 3 4 \displaystyle\frac{3}{4} 43, 4 3 \displaystyle\frac{4}{3} 34 ) 之间的数。在这个范围内失真不明显,可以自行修改范围。
- interpolation: 当裁剪出来的图片小于 size 时,就要使用插值方法 resize,主要有三种插值方法,如下:
- PIL.Image.NEAREST
- PIL.Image.BILINEAR
- PIL.Image.BICUBIC
transforms.FiveCrop(TenCrop)
torchvision.transforms.FiveCrop(size)
torchvision.transforms.TenCrop(size, vertical_flip=False)
功能:FiveCrop在图像的上下左右以及中心裁剪出尺寸为 size 的 5 张图片。Tencrop对这 5 张图片进行水平(默认)或者垂直镜像获得 10 张图片。
- size: 裁剪的图片尺寸
- vertical_flip: 是否垂直翻转
由于这两个方法返回的是 tuple,每个元素表示一个图片,我们还需要把这个 tuple 转换为一张图片的tensor。代码如下:
transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stac k([(transforms.ToTensor()(crop)) for crop in crops]))
这里采用Lambda匿名函数,:前crops为函数的输入,之后的为函数的返回值。其中stack是在张量的某一个维度上进行拼接,默认的为第0维度,[(transforms.ToTensor()(crop)) for crop in crops]) 中对crops进行for循环,然后取出的crop进行totensor的操作转换为张量的形式,得到长度为5的list,然后stack将长度为5的list拼接为一个张量。
并且把transforms.Compose中最后两行注释:
# transforms.ToTensor(), # toTensor()接收的参数是 Image,由于上面已经进行了 toTensor()
# transforms.Normalize(norm_mean, norm_std), # 由于是 4 维的 Tensor,因此不能执行 Normalize() 方法
transforms.Normalize()方法接收的是 3 维的 tensor (在_is_tensor_image()方法 里检查是否满足这一条件,不满足则报错),而经过transforms.FiveCrop返回的是 4 维张量,因此注释这一行。
最后的 tensor 形状是 [ncrops, c, h, w],图片可视化的代码也需要做修改:
## 展示 FiveCrop 和 TenCrop 的图片
ncrops, c, h, w = img_tensor.shape
columns=2 # 两列
rows= math.ceil(ncrops/2) # 计算多少行
# 把每个 tensor ([c,h,w]) 转换为 image
for i in range(ncrops):img = transform_invert(img_tensor[i], train_transform)plt.subplot(rows, columns, i+1)plt.imshow(img)
plt.show()
5 张图片分别是左上角,右上角,左下角,右下角,中心。
翻转Flip
transforms.RandomHorizontalFlip(RandomVerticalFlip)
transforms.RandomVerticalFlip(p=1)
功能:根据概率,在水平或者垂直方向翻转图片。
- p: 翻转概率
transforms.RandomHorizontalFlip(p=0.5),那么一半的图片会被水平翻转。
transforms.RandomVerticalFlip(p=1),那么所有图片会被垂直翻转。
旋转Rotation
transforms.RandomRotation
torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None)
功能:随机旋转图片
-
degree: 旋转角度
- 当为 a 时,在 (-a, a) 之间随机选择旋转角度
- 当为 (a, b) 时,在 (a, b) 之间随机选择旋转角度
-
resample: 重采样方法,通常默认就好
-
expand: 是否扩大矩形框,以保持原图信息。根据中心旋转点计算扩大后的图片。如果旋转点不是中心,即使设置 expand = True,还是会有部分信息丢失。因为expand主要是针对center旋转设计的,如果更换了旋转点,会丢失旋转信息。
如果设置 expand=True, batch size 大于 1,那么在一个 Batch 中,每张图片的 shape 都不一样了,会报错
Sizes of tensors must match except in dimension 0。所以如果 expand=True,那么还需要进行 resize 操作。 -
center: 旋转点设置,是坐标,默认中心旋转。如设置左上角为:(0, 0)