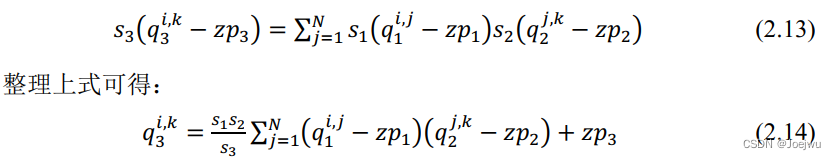Openpose是一种开源的实时多人姿态估计库,由卡耐基梅隆大学开发。它通过分析图像或视频中的人体关键点来估计人体的姿态,识别身体的各个部分,并推断出人体的姿势信息。
Openpose能够同时检测和跟踪多个人的姿态,可以用于人机交互、运动分析、动作捕捉、虚拟现实等各种应用领域。
它的工作原理是利用卷积神经网络对输入图像进行特征提取,并使用卷积层、池化层、上采样等操作进行特征融合和输出。Openpose在计算机视觉领域具有重要的应用价值,并且被广泛使用。
openpose是一种实时检测图像中多人的二维姿势的方法 。面临下面三项挑战:
第一,每张图像可能包含未知数量的人,他们可能出现在任何位置或规模。
第二,由于接触、遮挡或肢体衔接,人与人之间的互动会引起复杂的空间干扰,使得身体部分的关联变得困难。
第三,运行时的复杂性往往随着图像中人的数量而增加,使实时性能成为一个挑战 。

整体流程如下:
- 将整个图像作为网络输入,预测出一组身体部位位置的二维置信度图S(如图b)和一组部位亲和域(PAF)的二维矢量场L(如图c,它编码了部位之间的关联程度)。
- 通过贪婪推理对置信图和PAF进行解析(如图d),输出图像中所有人物的二维关键点。
其中身体部位的二维置信度图S={S_1, S_2, S_3, …, S_j},每个部位一个S_j∈R^(w×h)。部位亲和域的二维矢量场L={L_1, L_2,…, L_c},每个肢体一个,L_c∈R^(w×h×2)。
网络架构
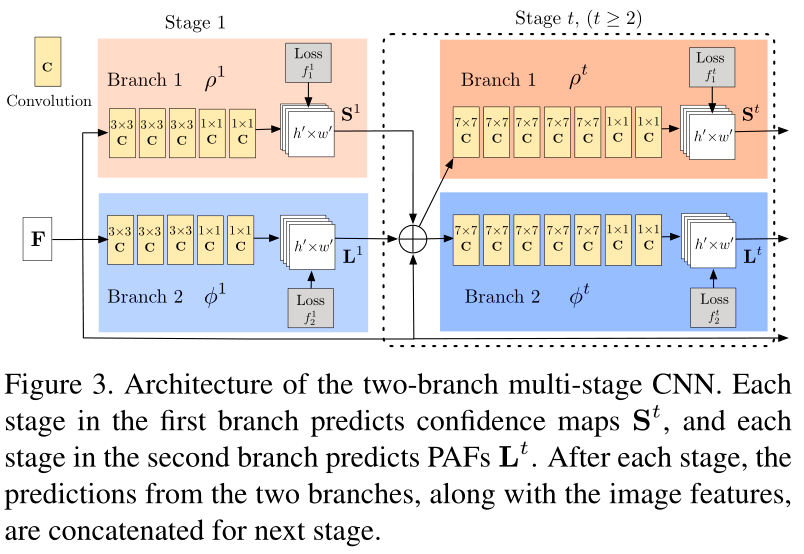
总体结构如图3所示,首先通过特征提取网络F(论文用的VGG-19)进行特征提取,将得到的特征层输入接下来的网络。后续网络被分成两个分支:顶部分支(以米黄色显示)预测置信图,底部分支(以蓝色显示)预测亲和场。
每个阶段都有中间监管,用于补充梯度,解决梯度消失的问题,确保结果不会向着错误的方向发展 。
stage t
在Stage 1,网络接收特征提取网络的输出,产生一组检测置信度映射S1=ρ1(F)和一组部分亲和域L1=φ1(F),其中ρ1和φ1是用于在阶段1进行推理的网络结构。
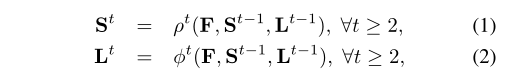
在Stage t (t>1),我们将特征提取网络输出的特征层和前一个Stage阶段生成的S_(t-1)和L_(t-1)连接输入,用来精细化预测。其中ρt和φt是用于在阶段1进行推理的网络结构。
Loss
网络结尾,应用了两个损失函数,分别用于优化身体部位的二维置信度图和部位亲和域的二维矢量场
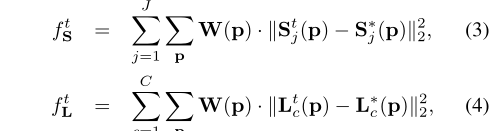
如上图所示,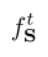 优化身体部位的二维置信度图,其中
优化身体部位的二维置信度图,其中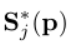 是真实的置信度图。
是真实的置信度图。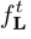 优化部分亲和域,其中
优化部分亲和域,其中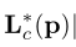 为真实的部位亲和域的二维矢量场。W§是一个掩码,当注释在图像位置P中消失时该掩码使该位置数据失效。
为真实的部位亲和域的二维矢量场。W§是一个掩码,当注释在图像位置P中消失时该掩码使该位置数据失效。
总体的损失函数是:
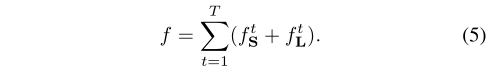
了解了上面的网络结构,出现了几个疑问:
1.训练时,基于真实标签的置信度图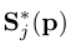 是如何生成的?
是如何生成的?
部分检测的置信度图 (PCM)
参考文章:https://zhuanlan.zhihu.com/p/360541947
该节解决了上面的第一个问题:训练时,基于真实标签 的置信度图[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kQGLFXuM-1688896277814)(./imgs/4.2.png)]是如何生成的?
当图像只出现一个人时,每个置信度图中有一个峰值,代表一个部位。
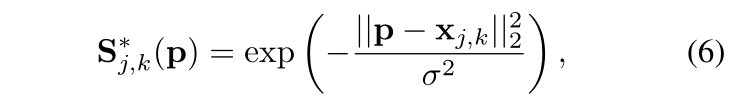
当图像出现多个人时,为每个人每个部位生成单独的置信度图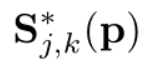 ,其中j代表部位 j,k代表人k,
,其中j代表部位 j,k代表人k,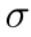 用来控制峰值的扩散。
用来控制峰值的扩散。
为什么采用公式(6)呢?
该公式代表着在关节点上的像素的置信度为1,其周围像素点根据距离呈高斯分布扩散,距离越远,置信度越低;距离越
近,置信度越高。 参考文章博主进行了更形象的解释!!!
之后,网络真实输出的置信度图是通过最大运算符对单个可信度图进行的聚合 :
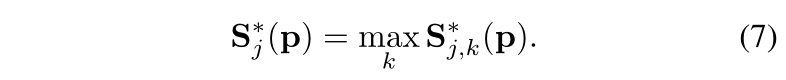
这里第一次看的时候比较疑惑为什么每个节点取k个人中最大的,这样相当于只有一个人的信息了,如何预测呢?
后来明白了,该小结上面的内容是在训练的时候做的事情,确实是每个部位只生成一个置信度图,一共19个(18个节点加背景图)
在测试时,我们预测置信图,并通过进行非最大限度的抑制来获得身体部位的候选位置 ,如图4第一行所示

比如通过预测置信度图,并通过非最大限度的抑制获得左眼(e1, e2, e3),左耳(r1, r2, r3, r4),之后通过PAF将节点正确连接起来。
部分关联的部分亲和域 (PAF)

该部分的输入是一组检测到的身体部位(训练时是标注好的,测试时是通过置信图预测的),如图5(a)中蓝色点和红色点所示。
部分亲和场是一个二维矢量场,保留了肢体支撑区域的位置和方向信息(如图5©所示),那么是如何定义的呢?
利用下面的公式:
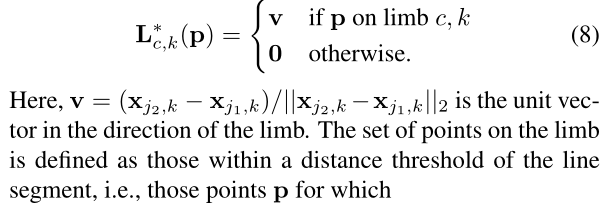
这里面,一些定义如下图所示:
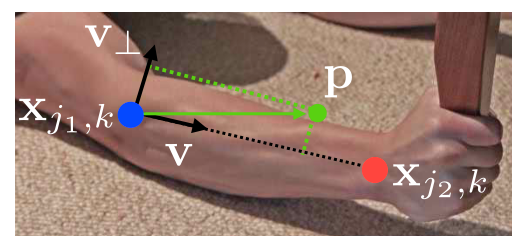
p是第k个人,部位c上的一点。v是p所在的肢体骨骼方向上的单位向量,x_jk是第k个人部位j的位置。那么p点在该肢体上的范围如下:
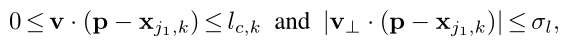
到这里我们便得到了部分亲和场,训练时到这里也就可以去计算损失了。
接下来是测试的时候做的事情:
**我们有了检测到的一组身体部位,结合上面求的部分亲和场,接下来可以计算两个节点之间的肢体关联置信度:**公式如下
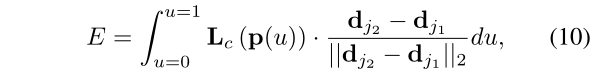
其中,d_j2和d_j1是两个关节的坐标。**p(u)**是通过均匀采样u的方式插值两个候选身体部位和的位置得到的位置 ,如下公式
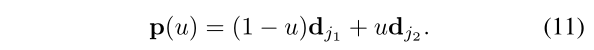
节点有了,关系大小可以用置信度表示了,这很像图的特性,下面也是用二分图进行的节点分配:具体如何做的呢?
首先,我们计算出两个部位的所有连接的权重,即E,生成矩阵。
下面举一个例子:假设有左耳={r_1, r_2, r_3, r_4},左眼={e_1, e_2, e_3},通过计算每个耳到眼的E值可以得到下列矩阵(值乱写的,正常应该是通过公式10生成的):
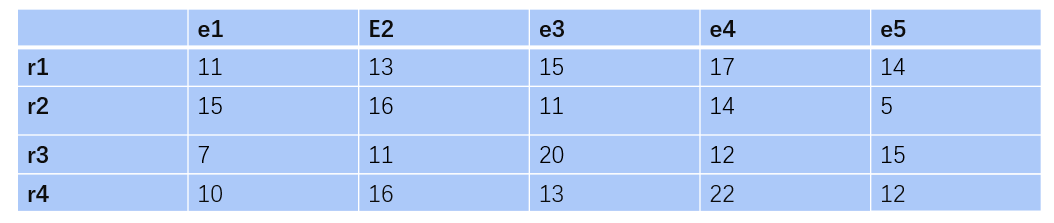
该二维矩阵代表了一个二分图,类似下面:
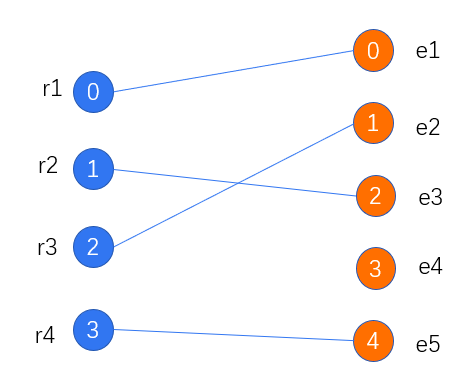
接下来找到权重最大组合:
首先明确约束,二分图中所有边不能公用一个顶点,这也很好理解,假设我们r3和e3连接了,即一个人的骨骼配对了,怎么可能再将另外一个人的骨骼节点和这个配对了的人的骨骼节点进行相连呢。
我们就是再上面提到的约束基础上寻找最大的权重组合,如下:

从该图能看出,与r1置信度最大的是e4,但是却不能被分配到一起,因为e4和r4的置信度更大。为了得到最大的权重总和,必须让r4和e4相连,r1与其余的节点相连。到这里就是所有的思想步骤了!!!
知道了权重最大组合的思想,再看数学表达就容易了很多:
假设我们有多人的身体部位候选集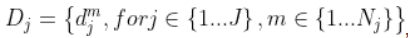
其中J代表身体部位j,N_j代表身体部位j有多少个候选位置,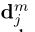 代表部位j的第m个侯选位置。
代表部位j的第m个侯选位置。
我们定义了下面的公式用来判断关节是否连接:
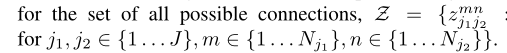
其中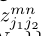 属于(0, 1),代表着关节
属于(0, 1),代表着关节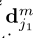 和
和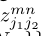 是否连接。同时为了达到上面二分图所有边不能公用一个顶点的效果,对该公式中的m和n做出约束。
是否连接。同时为了达到上面二分图所有边不能公用一个顶点的效果,对该公式中的m和n做出约束。
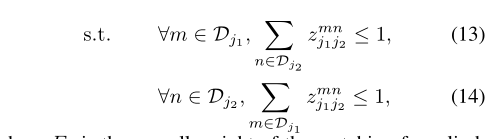
最后,就是权重最大组合的公式:
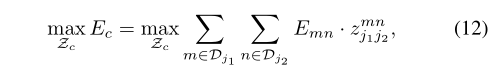
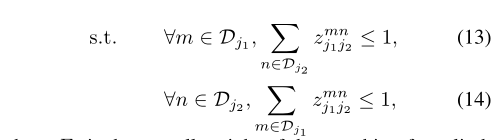
![[NSSRound#13 Basic]flask?jwt?解题思路过程](https://img-blog.csdnimg.cn/48e628999efb4a9181f681e4857e5204.png)