文章目录
- 1 InnoDB 行记录格式(实验)
- 1.1 Compact 行格式实验
- 1.1.1 实验步骤
- 1.1.2 分析捞出来的数据
- 1.1.3 疑问
- 1.2 Redundant 行格式实验
- 1.2.1 实验步骤
- 1.2.2 分析捞出来的数据
- 1.3 CHAR 列类型的存储
- 1.3.1 实验步骤
- 1.3.2 分析捞出来的数据
- 2 参考资料
1 InnoDB 行记录格式(实验)
前言:
1、本文是对 InnoDB 行格式的实验,请先通读 InnoDB 行格式的理论后再来实验。理论参考我的文章:《InnoDB 行记录格式》
2、实验环境是 mysql 的
5.7.41,建议读者也采用 5.7 版本,如果是 8.0 版本可能会有些不同之处3、mysql 中一般一页是 16KB 大小,所以有如下的页地址列表
第几页 页起始地址 1 00000000 2 00004000 3 00008000 4 0000c000 5 00010000 6 00014000 4、从
0000c000页开始为数据页(当然也不一定但本实验是这样的)5、Linux 平台提供了
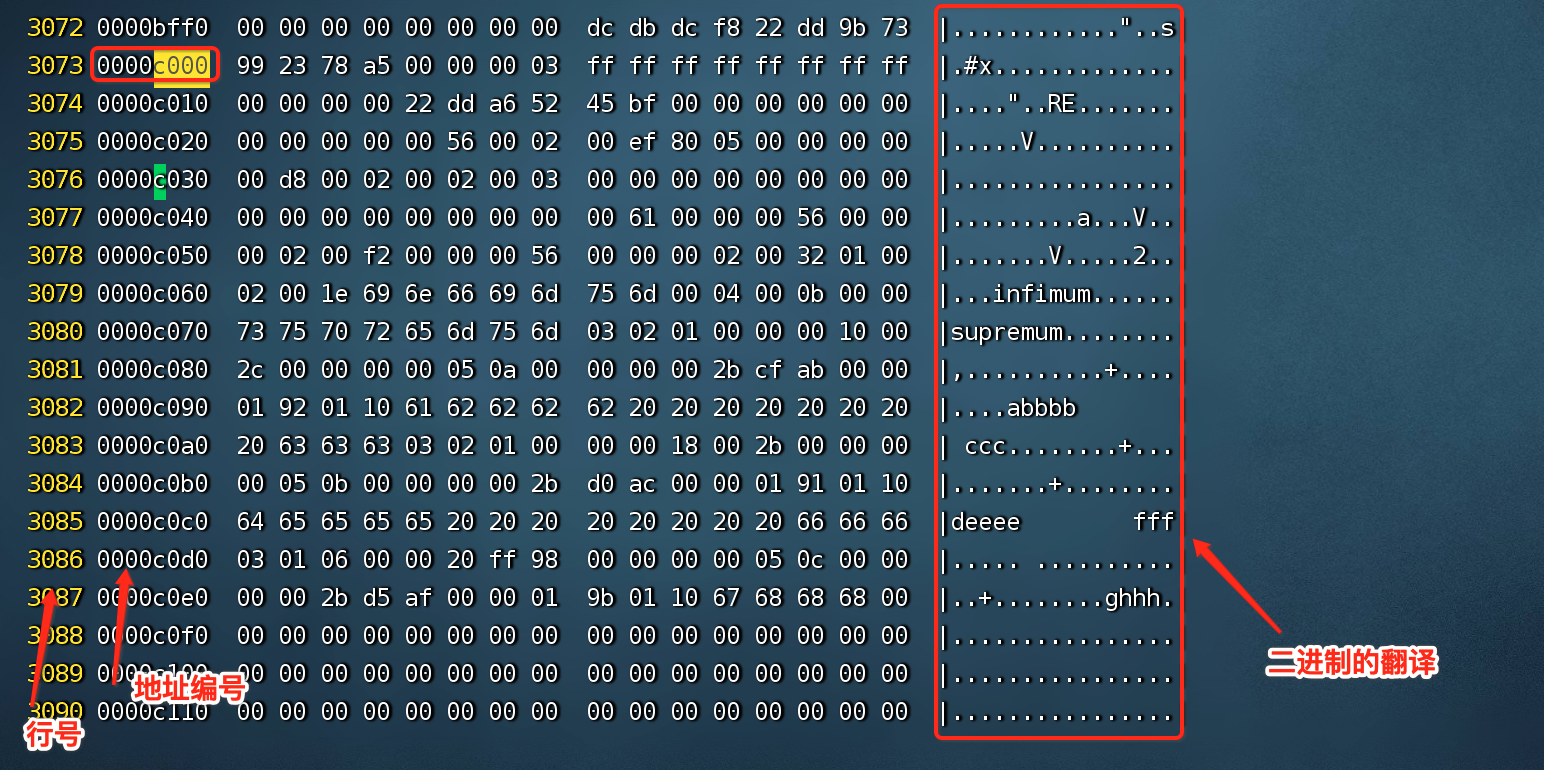
hexdump命令把二进制文件打印成标准的文本形式hexdump -C -v t1.ibd > t1.txt
如上图所示,显示的是每行的地址,所以如果某详细地址找不到那就取前缀地址在 txt 文件中搜索。当然刚开始非常建议用户直接通过特殊数据(如特殊的插入数据 fff )直接在 txt 文件中搜索
1.1 Compact 行格式实验
1.1.1 实验步骤
-
准备数据
CREATE TABLE `t1` (
a varchar(10),
b varchar(10) DEFAULT NULL,
c char(10) DEFAULT NULL,
d varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=COMPACT;
– 2、插入一些特殊数据
INSERT INTO t1 VALUES (‘a’, ‘bb’, ‘bb’, ‘ccc’);
INSERT INTO t1 VALUES (‘d’, ‘ee’, ‘ee’, ‘fff’);
INSERT INTO t1 VALUES (‘g’, NULL, NULL, ‘hhh’);
2. 进入 mysql 存放数据的目录,找到 t1.ibd 文件```shell
# 找到表 t1 的存储文件
cd /var/lib/mysql/innodb_learn
# 把二进制文件 t1.ibd 文件输出为 t1.txt
hexdump -C -v t1.ibd > t1.txt
-
从 t1.txt 文件把我们感兴趣的数据捞出来
3073 0000c000 99 23 78 a5 00 00 00 03 ff ff ff ff ff ff ff ff |.#x.............| 3074 0000c010 00 00 00 00 22 dd a6 52 45 bf 00 00 00 00 00 00 |...."..RE.......| 3075 0000c020 00 00 00 00 00 56 00 02 00 ef 80 05 00 00 00 00 |.....V..........| 3076 0000c030 00 d8 00 02 00 02 00 03 00 00 00 00 00 00 00 00 |................| 3077 0000c040 00 00 00 00 00 00 00 00 00 61 00 00 00 56 00 00 |.........a...V..| 3078 0000c050 00 02 00 f2 00 00 00 56 00 00 00 02 00 32 01 00 |.......V.....2..| 3079 0000c060 02 00 1e 69 6e 66 69 6d 75 6d 00 04 00 0b 00 00 |...infimum......| 3080 0000c070 73 75 70 72 65 6d 75 6d 03 02 01 00 00 00 10 00 |supremum........| 3081 0000c080 2c 00 00 00 00 05 0a 00 00 00 00 2b cf ab 00 00 |,..........+....| 3082 0000c090 01 92 01 10 61 62 62 62 62 20 20 20 20 20 20 20 |....abbbb | 3083 0000c0a0 20 63 63 63 03 02 01 00 00 00 18 00 2b 00 00 00 | ccc........+...| 3084 0000c0b0 00 05 0b 00 00 00 00 2b d0 ac 00 00 01 91 01 10 |.......+........| 3085 0000c0c0 64 65 65 65 65 20 20 20 20 20 20 20 20 66 66 66 |deeee fff| 3086 0000c0d0 03 01 06 00 00 20 ff 98 00 00 00 00 05 0c 00 00 |..... ..........| 3087 0000c0e0 00 00 2b d5 af 00 00 01 9b 01 10 67 68 68 68 00 |..+........ghhh.| 3088 0000c0f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
1.1.2 分析捞出来的数据
我们从捞出来的数据中其实已经看到我们刚刚插入的数据了,一共插入了 3 条数据
在一行数据的格式中,最重要最重要的就是 Record Header 和 RowID 2 项了!
第一行:
按照前面理论介绍,从具体数据如第一条数据 abbbb 按字节反推的到第一行数据整理后的格式如下:
03 02 01 /*变长字段长度列表(倒序的)*/
00 /* NULL 标志位列表 */
00 00 10 00 2c /* record header */
00 00 00 00 05 0a /* RowID【我们没有指定主键,是由系统自动生成的】 */
00 00 00 00 2b cf /* TranactionID */
ab 00 00 01 92 01 10 /* Roll Pointer */
61 /* 第1列数据 */
62 62 /* 第2列数据 */
62 62 20 20 20 20 20 20 20 20 /* 第3列数据 */
63 63 63 /* 第4列数据 */
1、变长字段列表是[03, 02, 01],跟我们插入的数据[ccc, bb, a]的长度是符合的。备注:char 列类型没参与长度的计算
2、NULL 标志位列表为 00 ,表明没有表不超过 8 个字段,且没有字段是 NULL
3、record header 最后 2 个字节 2c 指明了下一条记录的相对本条记录的偏移量,那我们来计算下下一条记录 rowid 的位置
1、本条记录的地址是:找到 RowID 的地址为:0000c081
2、偏移量是 2c,相加得到地址为:0000c0ad
3、查看 0000c0ad 的位置的数据为:00 00 00 00 05 0b
4、验证完全正确
4、第一列的数据为十六进制的 61,查表对应我们插入的数据:a
5、第二列第三列第四列也完全对应我们插入的数据:bb、bb、ccc
第二行:
请读者按第一行数据同样方式自行分析
第三行:
第三行跟前面 2 行略有不同,因为包含了字段为 NULL 的数据,重点观察一下 NULL 标志位列表的变化
在第 2 行地址的基础上加上偏移量直接得到第 3 行的地址为:0000c0ad + 2b = 0000c0d8,则有下面的结果
03 01 /*变长字段长度列表(倒序的)*/
06 /* NULL 标志位列表 */
00 00 20 ff 98 /* record header */
00 00 00 00 05 0c /*【 RowID 重点】*/
00 00 00 00 2b d5 /* TranactionID */
af 00 00 01 9b 01 10 /* Roll Pointer */
67 /* 第1列数据 */
68 68 68 /* 第4列数据 */
后面就是未使用的了,都是 00 00
1、变长字段为[03,01],第三行只有 2 个变长字段了其他字段为 NULL,跟我们插入的数据[hhh,g]吻合
2、NULL 标志位列表为 06,转化为二进制为 00000110,从右边往左边数,第 2、3 位是1 表示该记录的第 2、3 个字段是 NULL
3、在最后的数据列部分只有 2 列数据,因为为字段为 NULL 前面已经找到了也就不必在这里了
1.1.3 疑问
问题 1:为什么偏移量要根据 RowID 来偏移
因为没有比 RowID 更加合适的了
1、向前推理可以知道 NULL 标志位列表的长度、变长字段长度列表(刚好也解释了为什么变长字段的长度要倒序)
2、往后推理根据各项占用的字节数,也可以方便的知道 TranactionID、Roll Pointer、各列的数据
那还是谁的地址合适呢?(其实还真有,就是页的地址,Redundant 就是使用这个地址作为偏移的参考标准)
1.2 Redundant 行格式实验
1.2.1 实验步骤
-
准备数据
数据是复制的实验 Compact 行记录格式时的数据
-- 注意行格式已经改成了REDUNDANT create table t2ENGINE = Innodb DEFAULT CHARSET=latin1 ROW_FORMAT =REDUNDANT select * from t1; -- 数据还是原来的数据 select * from t2; +------+------+------+------+ | a | b | c | d | +------+------+------+------+ | a | bb | bb | ccc | | d | ee | ee | fff | | g | NULL | NULL | hhh | +------+------+------+------+ 3 rows in set (0.00 sec) -
通过 hexdump 工具转换表空间 t2.ibd 文件为 t2.txt 文件
hexdump -C -v t2.ibd > t2.txt3073 0000c000 ec bd 4c 64 00 00 00 03 ff ff ff ff ff ff ff ff |..Ld............| 3074 0000c010 00 00 00 00 22 dd fb 99 45 bf 00 00 00 00 00 00 |...."...E.......| 3075 0000c020 00 00 00 00 00 59 00 02 01 0b 00 05 00 00 00 00 |.....Y..........| 3076 0000c030 00 ea 00 02 00 02 00 03 00 00 00 00 00 00 00 00 |................| 3077 0000c040 00 00 00 00 00 00 00 00 00 64 00 00 00 59 00 00 |.........d...Y..| 3078 0000c050 00 02 00 f2 00 00 00 59 00 00 00 02 00 32 08 01 |.......Y.....2..| 3079 0000c060 00 00 03 00 8a 69 6e 66 69 6d 75 6d 00 09 04 00 |.....infimum....| 3080 0000c070 08 03 00 00 73 75 70 72 65 6d 75 6d 00 23 20 16 |....supremum.# .| 3081 0000c080 14 13 0c 06 00 00 10 0f 00 ba 00 00 00 00 05 13 |................| 3082 0000c090 00 00 00 00 2b fc ac 00 00 01 91 01 10 61 62 62 |....+........abb| 3083 0000c0a0 62 62 20 20 20 20 20 20 20 20 63 63 63 23 20 16 |bb ccc# .| 3084 0000c0b0 14 13 0c 06 00 00 18 0f 00 ea 00 00 00 00 05 14 |................| 3085 0000c0c0 00 00 00 00 2b fc ac 00 00 01 91 01 1e 64 65 65 |....+........dee| 3086 0000c0d0 65 65 20 20 20 20 20 20 20 20 66 66 66 21 9e 94 |ee fff!..| 3087 0000c0e0 14 13 0c 06 00 00 20 0f 00 74 00 00 00 00 05 15 |...... ..t......| 3088 0000c0f0 00 00 00 00 2b fc ac 00 00 01 91 01 2c 67 00 00 |....+.......,g..| 3089 0000c100 00 00 00 00 00 00 00 00 68 68 68 00 00 00 00 00 |........hhh.....| 3090 0000c110 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
1.2.2 分析捞出来的数据
在理论部分已经明确了 Redundant 的格式为:字段长度偏移列表、记录头(6个字节)
第一行:
23 20 16 14 13 0c 06 /* 字段长度列表,为什么有7个啊,明明我们只有4个字段*/
00 00 10 0f 00 ba /* record header 记录头。不同于Compact格式记录头占用5个字节,Redundant记录头占用6个字节*/
00 00 00 00 05 13 /* RowID */
00 00 00 00 2b fc /* TranactionID */
ac 00 00 01 91 01 10 /* roll pointer */
61 /* 第1列数据,字符'a' */
62 62 /* 第2列数据,字符'bb' */
62 62 20 20 20 20 20 20 20 20 /* 第3列数据,字符'bb',其余用空白字符填充 */
63 63 63 /* 第3列数据,字符'ccc' */
第一行的字段长度偏移列表为[23 20 16 14 13 0c 06],调整顺序为[06 0c 13 14 16 20 23],表示的含义是第1个字段的长度是6,第2个字段的长度是6(06 + 06 = 0c),第3个字段的长度是7(0c + 07 = 13),第4个字段的长度是1(13 + 01 = 14),第5个字段的长度是2(14 + 02 = 16),第6个字段的长度是10(16 + 0a = 20),第7个字段的长度是3(20 + 03 = 23)。为什么会多出3个字段我们只定义了4个字段现有有7个,这3个字段是隐藏字段
第1个字段:即 rowid,确实是占用6个字节
第2个字段:即 TranactionID,确实是占用6个字节
第3个字段:即 roll pointer,确实是占用7个字节
第4个字段:即字符’a’,确实是占用1个字节
第5个字段:即字符’bb’,确实是占用2个字节
第6个字段:即字符’bb’,但是是 char(10) 类型,确实是占用10个字节
第7个字段:即字符’ccc’,确实是占用3个字节
第二行:
第二行的数据请读者按第一行同样的自行整理
第一行记录的 rowid 地址是:0xc08a,偏移量是:ba,算出来第二行的地址是:0xC144,但是不对,因为在 Redundant 格式下偏移量相对的是页地址(0xc000)的偏移量,所以第二行的实际地址是:0xc000 + ba = 0xc0ba。根据地址把数据捞出来如下:
23 20 16 14 13 0c 06 /* 字段长度列表,为什么有7个啊,明明我们只有4个字段*/
00 00 18 0f 00 ea /* record header 记录头 */
00 00 00 00 05 14 /* RowID */
00 00 00 00 2b fc /* TranactionID */
ac 00 00 01 91 01 1e /* roll pointer */
64 /* 第1列数据,字符'd' */
65 65 /* 第2列数据,字符'ee' */
65 65 20 20 20 20 20 20 20 20 /* 第3列数据,字符'ee',其余用空白字符填充 */
66 66 66 /* 第3列数据,字符'fff' */
第三行:
重点看一下第三行,因为第三行包括了 NULL 字段,重点关注下字段长度列表中是如何体现出 NULL 含义的
直接计算第三行的 rowid 地址为:0xc0ea,再整理后如下:
21 9e 94 14 13 0c 06 /* 字段长度列表,为什么有7个啊,明明我们只有4个字段*/
00 00 20 0f 00 74 /* record header 记录头 */
00 00 00 00 05 15 /* RowID */
00 00 00 00 2b fc /* TranactionID */
ac 00 00 01 91 01 2c /* roll pointer */
67 /* 第1列数据,字符'g' */
00 00 00 00 00 00 00 00 00 00 /* 第3列数据,全部是00 */
68 68 68 /* 第3列数据,字符'hhh' */
长度列表为[21 9e 94 14 13 0c 06],倒序后为[06 0c 13 14 94 9e 21],表示的含义如下:
第1个字段:第1个字段的长度是6,即 rowid,确实是占用6个字节
第2个字段:第2个字段的长度是6(06 + 06 = 0c),即 TranactionID,确实是占用6个字节
第3个字段:第3个字段的长度是7(0c + 07 = 13),即 roll pointer,确实是占用7个字节
第4个字段:第4个字段的长度是1,即字符’g’,确实是占用1个字节
第5个字段:
第6个字段:
第7个字段:即字符’hhh’,确实是占用3个字节
第5个字段的长度是:94 - 14 = 80,但是 80 表示的是符号位根本表示不了长度,那太好了很适合 NULL 这个特殊的类型
第6个字段的长度是:9e - 94 = 0a,表示的长度是 10,任然占用空间
可以看到对于 varchar 类型的 NULL 值,Redundant 同样不占用空间,而 CHAR 类型的 NULL 值需要占用空间
1.3 CHAR 列类型的存储
实验目的:
1、验证CHR(N)中的N指的是字符的长度,而不是字节长度
2、验证在不同的字符集下,CHAR类型列内部存储的可能不是定长的数据
通过 CHAR(N) 理论部分的介绍我们可以知道,
1.3.1 实验步骤
-
准备数据
CREATE TABLE t1 (a char(2) ) CHARSET=GBK engine=InnoDB; -
插入数据(含多字节的)
INSERT INTO t1 SELECT 'ab'; INSERT INTO t1 SELECT '我们'; INSERT INTO t1 SELECT 'a'; -
查看每行数据的字符个数和字节个数
mysql> SELECT a,CHAR_LENGTH(a),LENGTH(a) from t1; +--------+----------------+-----------+ | a | CHAR_LENGTH(a) | LENGTH(a) | +--------+----------------+-----------+ | ab | 2 | 2 | | 我们 | 2 | 4 | | a | 1 | 1 | +--------+----------------+-----------+ 3 rows in set (0.00 sec)通过不同的CHAR_LENGTH和LENGTH函数可以观察到:前两个记录’ab’和’我们’字符串的长度都是2。但是内部存储上’ab’占用2字节,而’我们’占用4字节。如果通过HEX函数查看内部十六进制的存储,可以看到
mysql> SELECT a,HEX(a) from t1; +--------+----------+ | a | HEX(a) | +--------+----------+ | ab | 6162 | | 我们 | CED2C3C7 | | a | 61 | +--------+----------+ 3 rows in set (0.00 sec)可以看到对于字符串’ab’,其内部存储为0x6162。而字符串’我们’为0xCED2C3C7。因此对于多字节的字符编码,CHAR类型不再代表固定长度的字符串了
1.3.2 分析捞出来的数据
通过 hexdump 工具查看表空间 t1.ibd 文件
对于UTF-8下CHAR (10)类型的列,其最小可以存储10字节的字符,而最大可以存储30字节的字符。因此,对于多字节字符编码的CHAR数据类型的存储,InnoDB存储引擎在内部将其视为变长字符类型。这也就意味着在变长长度列表中会记录CHAR数据类型的长度,下面查看下表 t1 的表空间文件:
hexdump -C -v t1.ibd > t1.txt
3073 0000c000 41 57 55 5a 00 00 00 03 ff ff ff ff ff ff ff ff |AWUZ............|
3074 0000c010 00 00 00 00 22 dd cc 90 45 bf 00 00 00 00 00 00 |...."...E.......|
3075 0000c020 00 00 00 00 00 57 00 02 00 ce 80 05 00 00 00 00 |.....W..........|
3076 0000c030 00 b9 00 02 00 02 00 03 00 00 00 00 00 00 00 00 |................|
3077 0000c040 00 00 00 00 00 00 00 00 00 62 00 00 00 57 00 00 |.........b...W..|
3078 0000c050 00 02 00 f2 00 00 00 57 00 00 00 02 00 32 01 00 |.......W.....2..|
3079 0000c060 02 00 1c 69 6e 66 69 6d 75 6d 00 04 00 0b 00 00 |...infimum......|
3080 0000c070 73 75 70 72 65 6d 75 6d 02 00 00 00 10 00 1c 00 |supremum........|
3081 0000c080 00 00 00 05 0d 00 00 00 00 2b e0 b7 00 00 01 9c |.........+......|
3082 0000c090 01 10 61 62 04 00 00 00 18 00 1e 00 00 00 00 05 |..ab............|
3083 0000c0a0 0e 00 00 00 00 2b e1 b8 00 00 01 a5 01 10 ce d2 |.....+..........|
3084 0000c0b0 c3 c7 02 00 00 00 20 ff b7 00 00 00 00 05 0f 00 |...... .........|
3085 0000c0c0 00 00 00 2b e6 bb 00 00 01 a8 01 10 61 20 00 00 |...+........a ..|
3086 0000c0d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
3087 0000c0e0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
3088 0000c0f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
整理后可以得到如下结果:
第一行:
02 /* 变长字段长度2,将CHAR视作变长类型 */
00 /* null 标志位列表 */
00 00 10 00 1c /* record header */
00 00 00 00 05 0d /* rowid */
00 00 00 00 2b e0 /* TranactionID */
b7 00 00 01 9c 01 10 /* roll pointer */
61 62 /* 字符,'ab' */
第二行:
04 /* 变长字段长度4,将CHAR视作变长类 */
00 /* null 标志位列表 */
00 00 18 00 1e /* record header */
00 00 00 00 05 0e /* rowid */
00 00 00 00 2b e1 /* TranactionID */
b8 00 00 01 a5 01 10 /* roll pointer */
ce d2 c3 c7 /* 字符,'我们' */
第三行:
02 /* 变长字段长度2,将CHAR视作变长类 */
00 /* null 标志位列表 */
00 00 20 ff b7 /* record header */
00 00 00 00 05 0f /* rowid */
00 00 00 00 2b e6 /* TranactionID */
bb 00 00 01 a8 01 10 /* roll pointer */
61 /* 字符,'我们' */
本实验清楚地显示了 InnoDB 存储引擎内部对 CHAR 类型在多字节字符字符集的存储。CHAR类型被明确视为了变长字符类型,对于未能占满长度的字符还是填充0x20。InnoDB存储引擎内部对字符的存储和我们用HEX函数看到的也是一致的。因此可以认为在多字节字符集的情况下,CHAR和VARCHAR的实际行存储基本是没有区别的
2 参考资料
官网:https://dev.mysql.com/doc/refman/8.0/en/innodb-row-format.html
InnoDB 行记录格式(理论):我的另外文章:《15.10 InnoDB 行记录格式(理论,重要)》
书籍:《InnoDB 存储引擎》,该书电子版练习作者无套路免费下载
传送门: 保姆式Spring5源码解析
欢迎与作者一起交流技术和工作生活
联系作者