目录
1.采样和分割数据
1.1 抽样简介
1.2 过滤 PII(个人身份信息)
2.数据不平衡
2.1 下采样和增加权重
3.数据分割示例
3.1 随机分割可能不是最好的方法
4.分割数据
5.随机化
5.1 实际考虑
5.2 散列的注意事项
6.参考文献
1.采样和分割数据-Sampling and Splitting Data
1.1 采样简介
为机器学习项目收集足够的数据通常很困难。然而,有时数据太多,我们必须选择示例子集进行训练。那么,如何选择子集?以 Google 搜索为例,以什么粒度对大量数据进行采样?你会使用随机查询吗?随机会话?随机用户?
最终,答案取决于问题:我们想要预测什么,我们想要什么特征?
- 要使用上一个查询的特征,需要在会话级别进行采样,因为会话包含一系列查询。
- 要使用前几天的用户行为特征,则需要在用户级别进行采样。
1.2 过滤 PII(个人身份信息)
如果数据包含 PII(个人身份信息),可能需要将其从数据中过滤掉。例如,策略可能要求你删除不常见的特征。 这种过滤通常会改变数据分布,丢失尾部的信息(分布中值非常低的部分,远离平均值)。这种过滤很有用,因为非常罕见的特征很难学习。但重要的是要认识到你的数据集将偏向头部查询。在服务时,你可以预期从尾部提供示例会做得更糟,因为这些示例是从训练数据中过滤掉的。尽管这种偏差无法避免,但在分析过程中请注意这一点。
2.数据不平衡-Imbalanced Data
构成数据集大部分的类称为 多数类。所占比例较小的是 少数群体。那么,什么算不平衡?答案可能从温和到极端,如下表所示。
| 不平衡程度 | 少数群体比例 |
|---|---|
| 温和的 | 数据集的 20-40% |
| 缓和 | 数据集的 1-20% |
| 极端 | <数据集的1% |
为什么要注意不平衡的数据?如果你的分类任务包含不平衡的数据集,则可能需要应用特定的采样技术。举个例子,一个检测欺诈的模型,相关数据集如下图所示:数据集中每 200 笔交易就会发生一次欺诈实例,因此在真实分布中,大约 0.5% 的数据是正的。
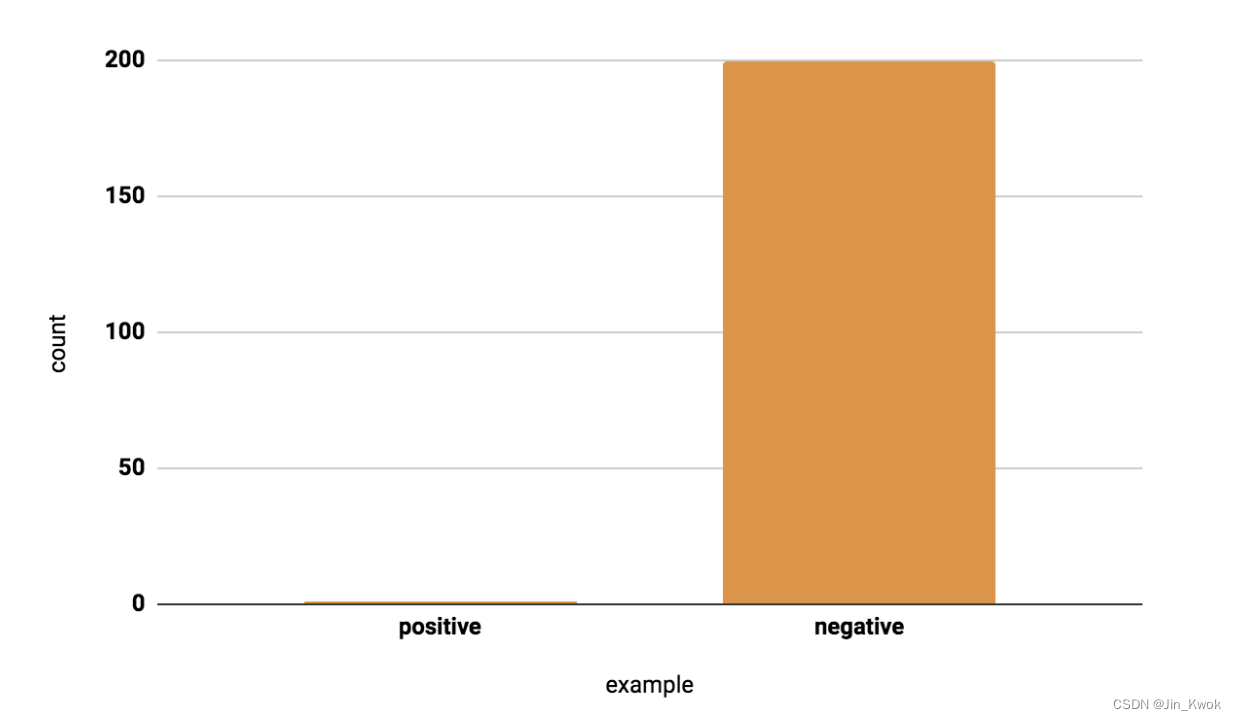
由于相对于负面例子来说,正面例子很少,因此训练模型将把大部分时间花在负面例子上,而不能从正面例子中学到足够的东西。例如,如果你的批次大小为 128,则许多批次将没有正例,因此梯度的信息量会较少。
在实践中,如果数据集不平衡,需要首先尝试对真实分布进行训练。如果模型运行良好并且具有概括性,那么自然是最好的结果!反之,则需尝试以下下采样和上加权技术。
2.1 下采样和增加权重
处理不平衡数据的有效方法是对多数类进行下采样和增加权重。让我们首先定义这两个新术语:
- 下采样:意味着对大多数类示例中不成比例的低子集进行训练。
- 增加权重:意味着向下采样的类添加一个示例权重,该权重等于下采样的因子。
步骤 1:对多数类别进行下采样。还是以上面介绍的欺诈数据集为例,其中 1 个正例到 200 个负例。下采样 10 倍可将平衡性提高到 1 个正例到 20 个负例 (5%)。虽然得到的训练集仍然是不平衡的,但正例与负例的比例比原来极度不平衡的 比例(0.5%)要好得多。
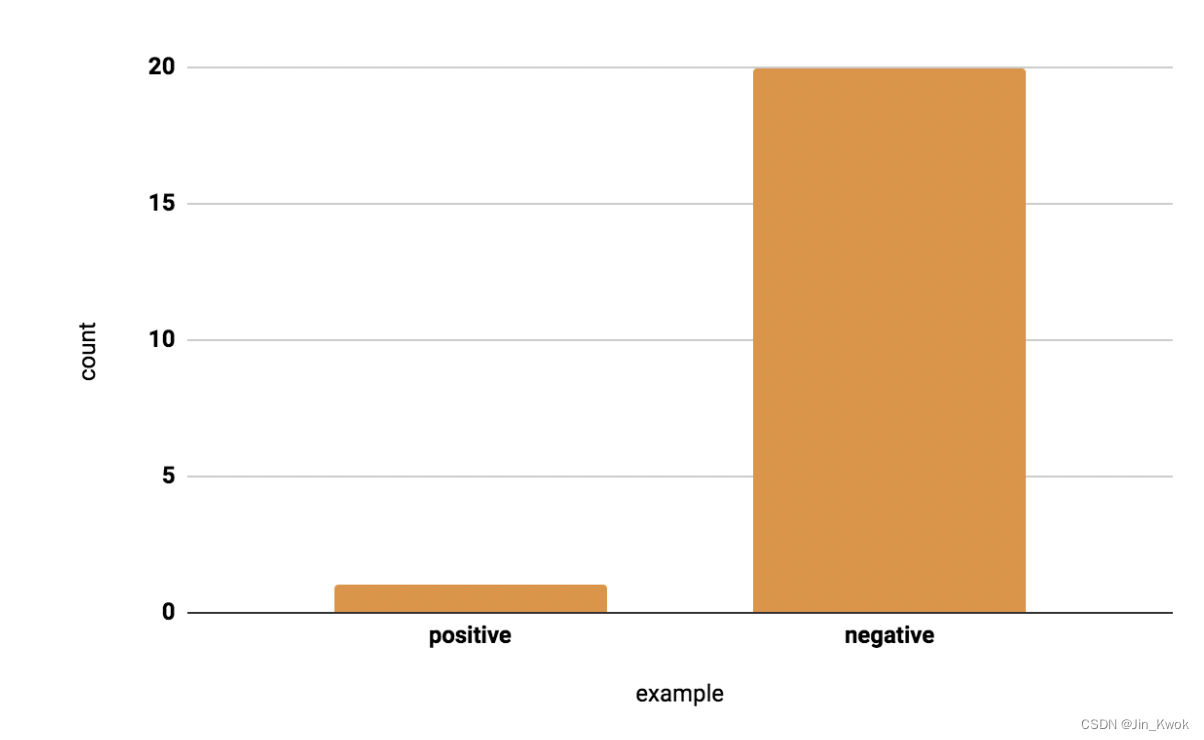
步骤 2:增加下采样类的权重:将示例权重添加到下采样类。由于我们按 10 倍下采样,因此示例权重应为 10。
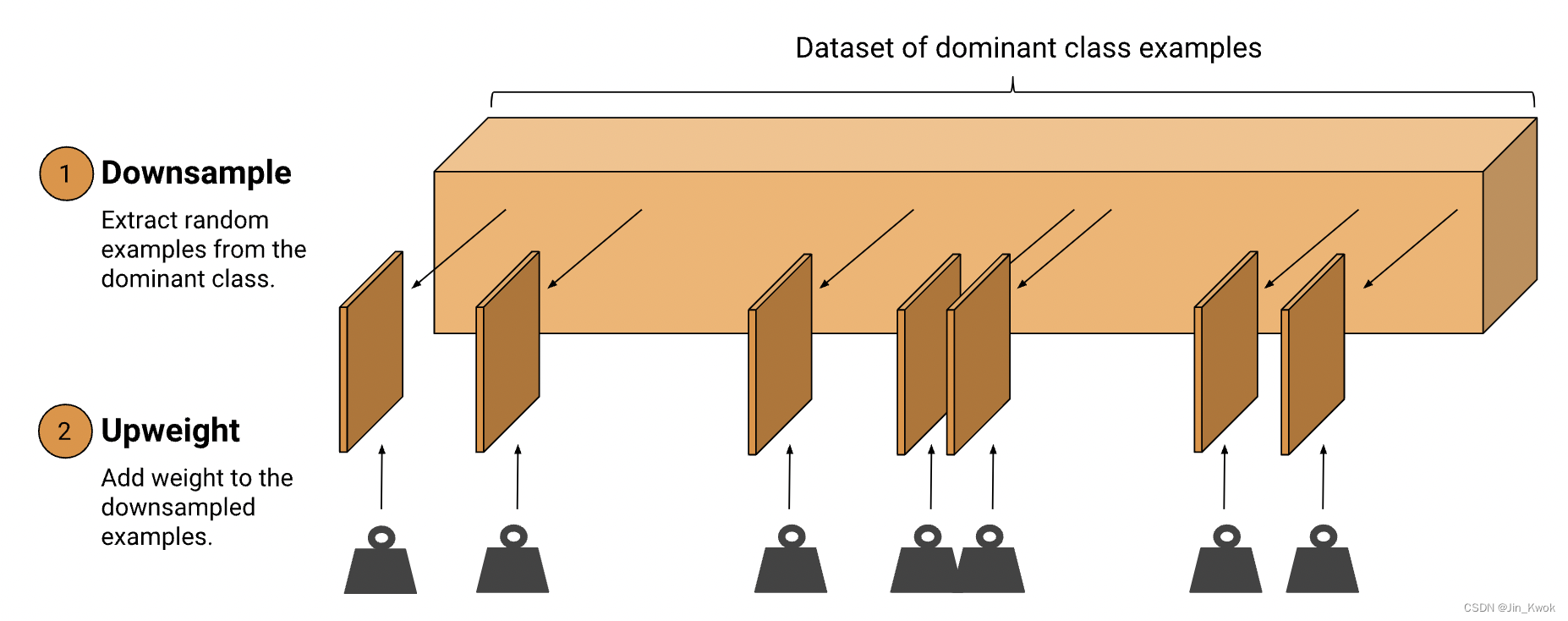
在之前的文章中,权重一词指代模型参数(例如神经网络中的连接)。在这里,我们讨论的是 示例权重,这意味着在训练过程中更重要的是计算单个示例。示例权重为 10 意味着模型将该示例视为权重为 1 的示例的 10 倍(计算损失时)。
权重应等于您用于下采样的因子:
3.数据分割示例
收集数据并根据需要进行采样后,下一步是将数据分为 训练集、 验证集和测试集。
3.1 随机分割可能不是最好的方法
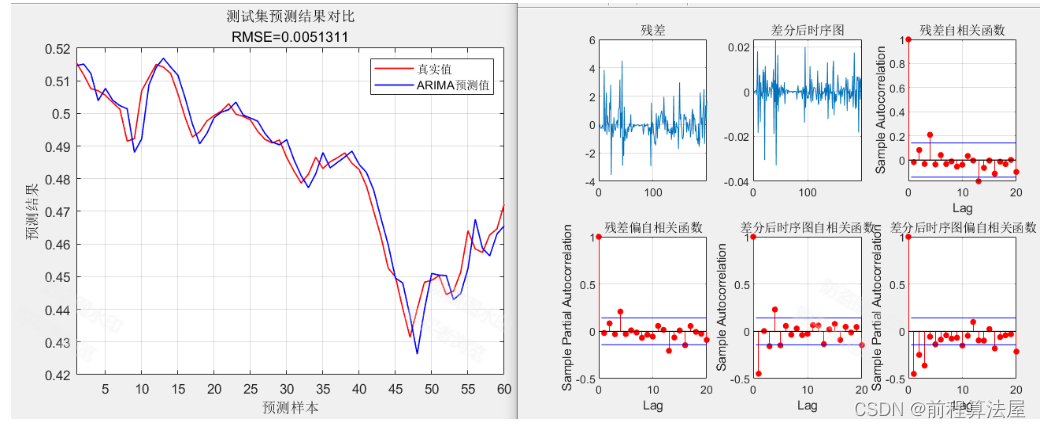
虽然随机分割是解决许多机器学习问题的最佳方法,但它并不总是正确的解决方案。例如,考虑其中示例自然聚集成相似示例的数据集。如图 1 所示,假设用模型对新闻的主题进行分类,采用随机分割就可能会出现问题。

图 1. 新闻报道是聚集的
原因在于新闻故事一般是成群出现的:关于同一主题的多个故事在同一时间发布。因此,如果我们随机分割数据,测试集和训练集可能会包含相同的故事。实际上,这种方式是行不通的,因为所有故事都会同时进入,所以像这样进行分割会导致倾斜。
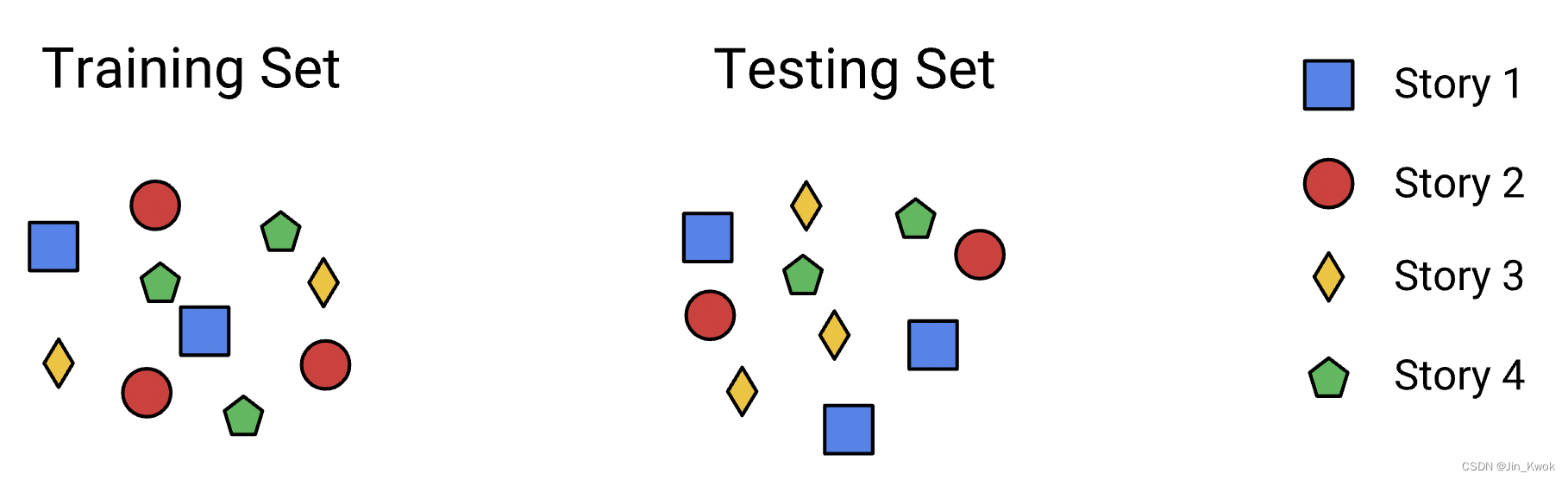
图 2. 随机拆分会将集群拆分为多个集合,从而导致倾斜
解决这个问题的一个简单方法是根据故事发布的时间(也许是故事发布的日期)来分割我们的数据。这会导致同一天的故事被放置在同一个分组中。
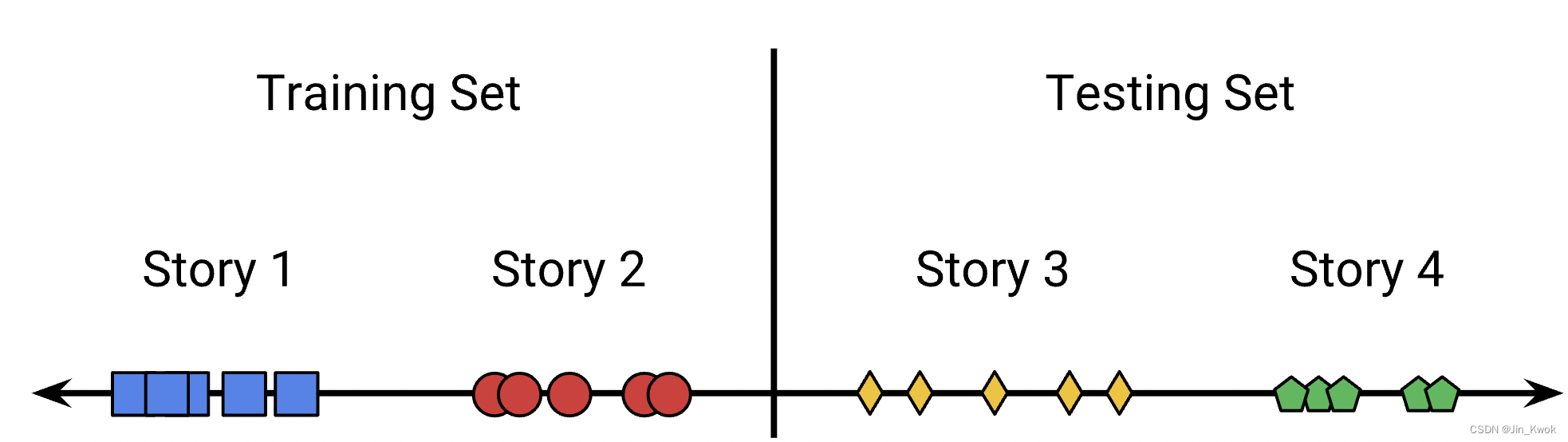
图 3. 按时间分割可以使集群大部分最终位于同一组中
对于数以万计或更多的新闻报道,一定比例的新闻报道可能会在几天内分配。不过问题不大,事实上,这些故事分布在两天的新闻周期中,或者,我们可以丢弃距离截止点一定范围内的数据,以确保没有任何重叠。例如,可以训练四月份的故事,然后使用五月的第二周作为测试集,周间隙防止重叠。
4.分割数据-Splitting Data
正如上面的 “新闻报道主题分类” 所示,纯粹的随机分割并不总是正确的方法。在线系统的一种常见技术是按时间分割数据,这样就可以:
- 收集 30 天的数据。
- 使用第 1-29 天的数据进行训练。
- 评估第 30 天的数据。
对于在线系统,训练数据比服务数据更旧,因此该技术可确保验证集反映训练和服务之间的滞后。然而,基于时间的分割最适合非常大的数据集,例如具有数千万个示例的数据集。在数据较少的项目中,训练、验证和测试之间的分布最终会有很大不同。
想要为数据设计一种合适的分隔方式,首先需要明确数据代表什么(数据的内涵),只有充分了解数据,才能设计出合适的分隔策略。
5.随机化-Randomization
5.1 实际考虑
假设想要添加一个特征来查看它如何影响模型质量。为了公平的实验,除了这个新特征之外,数据集应该是相同的。如果数据不可重现,则无法制作这些数据集。鉴于此,确保数据生成中的任何随机化都可以是确定性的:
- 为随机数生成器(RNG) 播种。播种可确保 RNG 在每次运行时以相同的顺序输出相同的值,从而重新创建数据集。
- 使用不变的哈希键。 散列是分割或采样数据的常用方法。我们可以对每个示例进行散列,并使用生成的整数来决定将示例放置在哪个分割中。每次运行数据生成程序时,哈希函数的输入不应更改。例如,如果想按需重新创建哈希值,请勿在哈希值中使用当前时间或随机数。
5.2 散列的注意事项
想象一下,你正在收集搜索查询并使用散列来包含或排除查询。如果哈希键仅使用查询,则在多天的数据中,将始终包含该查询或始终排除它,而总是包含或总是排除查询是不好的,因为:
- 训练集将看到一组不太多样化的查询。
- 评估集与训练集没有重叠。
针对上述问题,可以对查询+日期进行散列,如此一来,每天都有不同的散列。
小结一下,即保证散列独一无二,以确保系统不会与其他系统发生冲突。
6.参考文献
链接-https://developers.google.cn/machine-learning/data-prep/construct/sampling-splitting/sampling