文章目录
- 附近商铺、用户签到、UV统计
- 一、附近商铺
- 1.1 GEO数据结构
- 1.2 导入店铺数据到GEO
- 1.3 实现附近商户功能
- 二、用户签到
- 2.1 BitMap
- 2.2 签到功能
- 2.3 统计连续签到
- 2.3.1 分析
- 2.3.2 代码实现
- 三、UV统计
- 3.1 HyperLogLog用法
- 3.2 测试百万数据的统计
附近商铺、用户签到、UV统计
一、附近商铺
底层都是基于地理坐标进行搜索,支持地理坐标的技术有很多,Redis就是其中之一
1.1 GEO数据结构
GEO就是Geolocation的简写形式,代表地理坐标。
Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
-
GEOADD:添加一个地理空间信息,包含: 经度 (longitude)、纬度latitude)、值(member)
这个值可以使任何一个东西,比如店名、数据库中的某个字段的

-
GEODIST:计算指定的两个点之间的距离并返回
可以选择返回的单位,m,km等

- GEOHASH:将指定member的坐标转为hash字符串形式并返回

- GEOPOS:返回指定member的坐标

- GEORADIUS:指定圆心(radius)、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.2以后已废弃

- GEOSEARCH:在指定范用内搜索member,并按照与指定点之间的距离排席后返回。范用可以是圆形或矩形。6.2.新功能
可以指定我们这个key中的某个成员作为圆心,也可以直接指定经纬度作为圆心
BYRADIUS就是按照圆半径来搜索
BYBOX按照矩形来搜(指定长宽之类的)
COUNT表示查询多少条
WITHDIST表示携带距离

- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。6.2.新功能
需求
1.添加下面几条数据
—北京南站(116.378248 39.865275)
—北京站 (116.42803 39.903738 )
—北京西站(116.322287 39.893729)
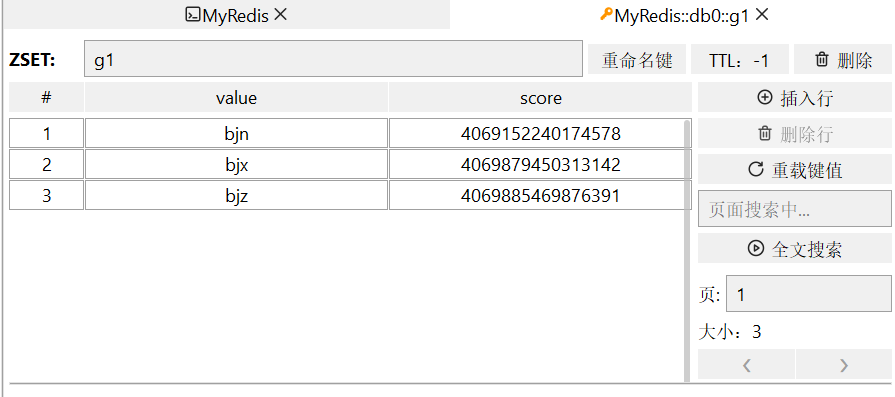
GEOADD g1 116.378248 39.865275 bjn 116.42803 39.903738 bjz 116.322287 39.893729 bjx
添加进去后发现底层的数据结构是ZSET,也就是SortedSet
下图中的value就是我们填进去的member,我们存进去的地理左边转换成了下面的一串数字,作为score传进去了
2.计算北京南站到北京西的距离
GEODIST g1 bjn bjx

若指定单位
GEODIST g1 bjn bjx km

3.搜索天安门(116.397904 39.909005 )附近10km内的所有火车站,并按照距离升序排序
GEOSEARCH g1 FROMLONLAT 116.397904 39.909005 BYRADIUS 10 km WITHDIST

1.2 导入店铺数据到GEO
看一下店铺表tb_shop
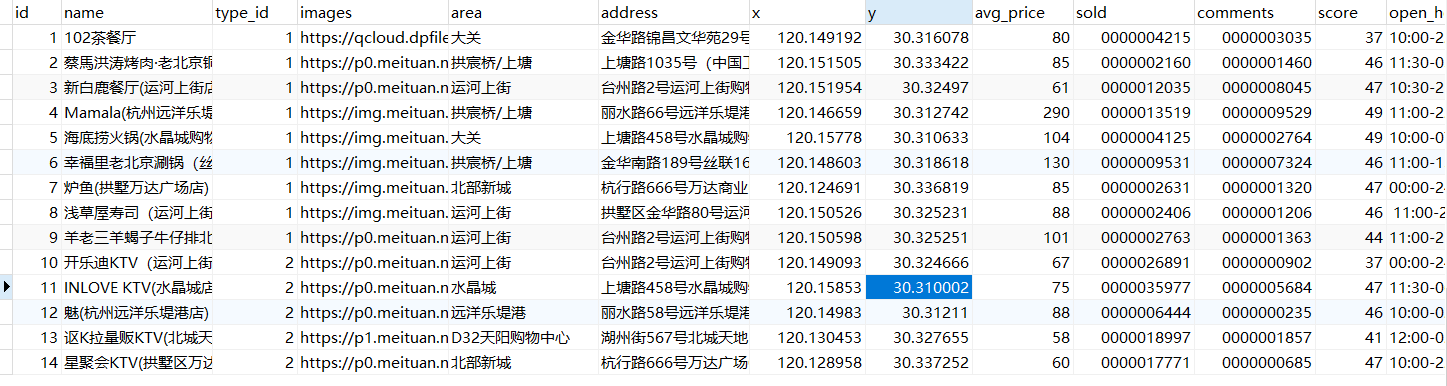
导入数据到GEO的时候并不是将所有的信息都导入,我们只需要导入经纬度坐标以及店铺id即可,店铺id充当GEO命令中的member
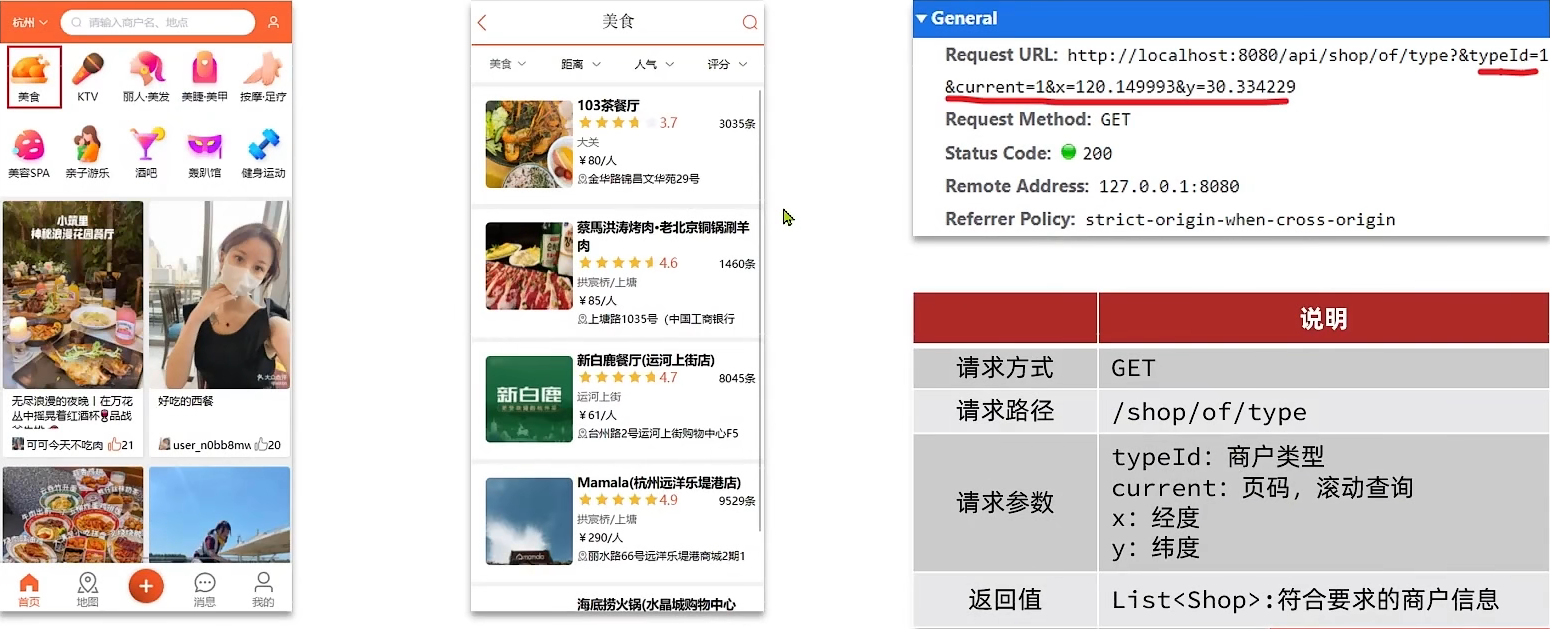
我们搜索的时候有一个限制条件,根据商户的类型做过滤,但是我们并没有把商铺的类型放入到GEO里面,所以过滤不了
为了解决这个问题,我们可以采取下面的措施:
按照商户类型做分组,类型相同的商户作为同一组,以typeId为Key存入同一个GEO集合中即可
@Resourceprivate StringRedisTemplate stringRedisTemplate;@Testvoid loadShopData() {
// TODO 1. 查询所有店铺信息List<Shop> list = shopService.list();
// TODO 2. 把店铺分组,按照typeId分组,id一致的放到一个集合Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(shop -> shop.getTypeId()));
// TODO 3. 分批完成存储写入Redisfor (Map.Entry<Long, List<Shop>> entry : map.entrySet()) {
// TODO 3.1 获取类型idLong typeId = entry.getKey();String key = "shop:geo:" + typeId;
// TODO 3.2 获取同类型的店铺集合List<Shop> value = entry.getValue();
// TODO 3.3 写入Redis GEOADD key 经度 纬度 member
// 方法1:效率比较低,不采用
// for (Shop shop : value) {
// 坐标我们可以一个个指定,也可以直接new一个Point对象
// stringRedisTemplate.opsForGeo().add(key,new Point(shop.getX(),shop.getY()),shop.getId().toString());
// 方法2:
// }
// 方法2List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>();for (Shop shop : value) {
// 下面泛型的类型是member的类型locations.add(new RedisGeoCommands.GeoLocation<>(shop.getId().toString(),new Point(shop.getX(), shop.getY())));}
// 批量操作stringRedisTemplate.opsForGeo().add(key,locations);}}
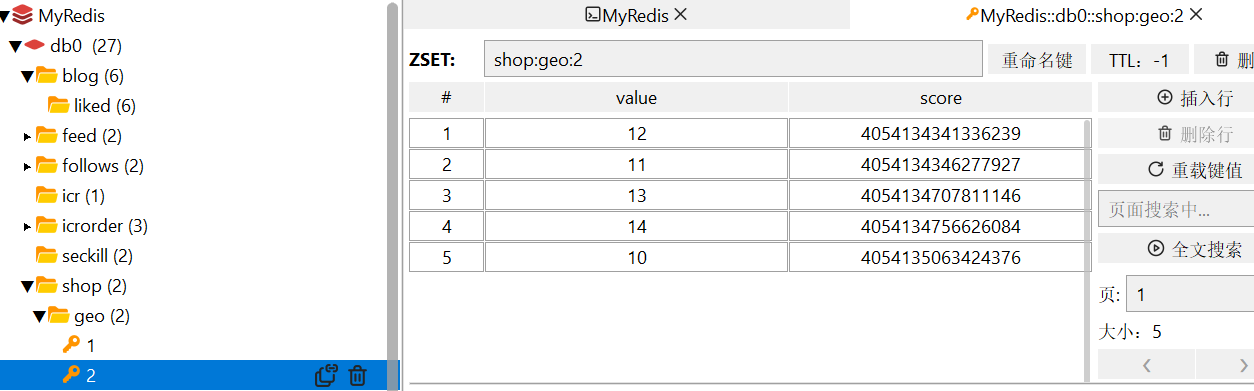
结果图:

1.3 实现附近商户功能
我们使用的Springboot版本不是最新的,那对应的SpringDataRedis的版本也不是最新的
SpringDataRedis的2.3.9版本并不支持Redis 6.2提供的GEOSEARCH命令,因此我们需要提示其版本,修改Pom文件
可以下载一个插件:Dependency Analyzer
<!--修改其中的版本--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId></exclusion><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId><!--使用2.6.2也可以--><version>2.7.11</version></dependency><dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>6.1.10.RELEASE</version></dependency>
接口分析图
Controller层
/*** 根据商铺类型分页查询商铺信息* @param typeId 商铺类型* @param current 页码* @return 商铺列表*/@GetMapping("/of/type")public Result queryShopByType(@RequestParam("typeId") Integer typeId,@RequestParam(value = "current", defaultValue = "1") Integer current,@RequestParam(value = "x",required = false) Double x,@RequestParam(value = "y",required = false) Double y) {return shopService.queryShopByType(typeId,current,x,y);}
Service层
@Overridepublic Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// TODO 1.判断是否需要根据坐标查询if (x == null || y == null) {//不需要坐标查询,按数据库查询Page<Shop> page = query().eq("type_id", typeId)
// SystemConstants.DEFAULT_PAGE_SIZE)==5.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));// 返回数据return Result.ok(page.getRecords());}// TODO 2.计算分页参数
// 从哪开始int from = (current-1)*SystemConstants.DEFAULT_PAGE_SIZE;
// 从哪结束int end = current*SystemConstants.DEFAULT_PAGE_SIZE;// TODO 3.查询redis,按照距离排序、分页。结果:shopId和distanceString key = "shop:geo:"+typeId;GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo()
// GEOSEARCH key FROMLONLAT x y BYRADIUS 10 km WITHDIST
// 第一个参数是key,第二个参数是圆心,第三个参数是半径,我们选择半径5000米以内的.search(key, GeoReference.fromCoordinate(x, y), new Distance(5000),RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs()
// 这个参数代表WITHDIST.includeDistance()
// 表示第一条数据到第end条数据.limit(end));
// TODO 4.解析出ShopIDif(results==null){return Result.ok();}List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();if (list.size()<from){
// 因为我们下面要执行skip操作,如果list集合中元素小于from的话,会出现sql异常return Result.ok(Collections.emptyList());}
// TODO 4.1 截取从from到end的数据List<Long> ids = new ArrayList<>(list.size());Map<String,Distance> distanceMap = new HashMap<>(list.size());list.stream().skip(from).forEach(result->{
// TODO 4.2 获取店铺idString shopIdStr = result.getContent().getName();ids.add(Long.valueOf(shopIdStr));
// TODO 4.3 获取距离Distance distance = result.getDistance();distanceMap.put(shopIdStr,distance);});
// TODO 5.根据id查询Shop
// 依然要保证有序String idStr = StrUtil.join(",", ids);List<Shop> shops = query().in("id", ids).last("order by FIELD(id," + idStr + ")").list();for (Shop shop : shops) {shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());}
// TODO 6.返回return Result.ok(shops);}
根据距离排名的效果图
二、用户签到
2.1 BitMap
假如我们用一张表来存储用户签到信息,其结构如下所示
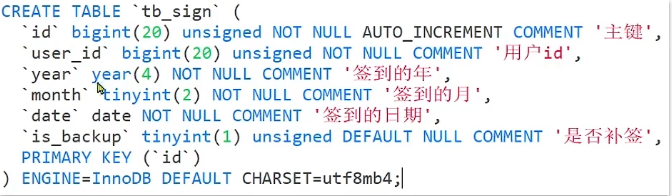
假如1000万用户,平均每人没你那签到次数为10次,则这张表一年的数据量为1亿条,记录量非常大。
我们可以按月来统计用户签到信息,签到记录为1,未签到则记录为0。然后从第一天开始,依次的把0或1记录下来,一个月的签到状况就用一个二进制的数字串给表现出来了
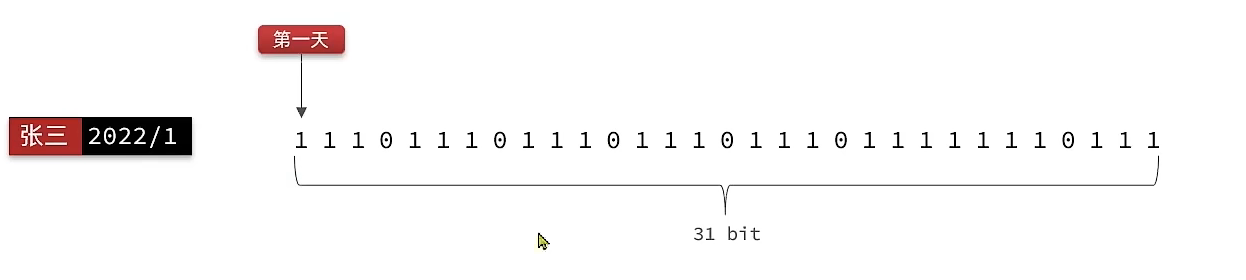
把每一个bit位对应当月的每一天,形成了映射关系。
用0和1表示业务状态,这种思路称为位图(BitMap)
Redis中是利用String类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是2^32个bit位
BitMap的操作命令有:
SETBIT:向指定位置 (offset,角标从0开始)存入一个0或1
如果我们不设置值的话,默认就是零,所以签到的时候存入1,不签到的时候不存也行
GETBIT:获取指定位置 (offset)的bit值

BITCOUNT: 统计BitMap中值为1的bit位的数量
BITFIELD:操作(查询、修改、自增)BitMap中bit数组中的指定位置 (offset)的值
GET type offset 中的type表示读取多少位,几个bit位,其还需要指定返回的结果是有符号的还是无符号的,因为最终的返回结果是以十进制返回
带符号的话,第一个“1”或者“0”就代表着符号位
带符号: GET i
不带符号: GET u
假如说不带符号获取两个bit,并且从0开始获取:GET u2 0
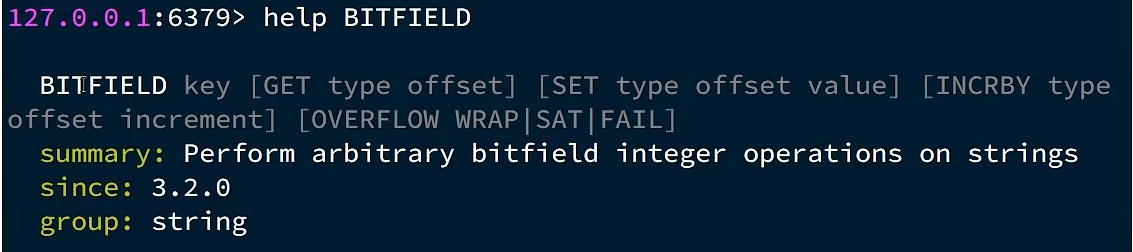
BITFIELD_RO:获取BitMap中bit数组,并以十进制形式返回
BITOP: 将多个BitMap的结果做位运算(与、或、异或)
BITPOS:查找bit数组中指定范围内第一个0或1出现的位置
2.2 签到功能
需求:实现签到接口,将当前用户当天签到信息保存到Redis中
提示:因为BitMap底层是基于String数据结构,因此其操作也都封装在字符串相关操作中了
Controller层
@PostMapping("/sign")
public Result sign(){return userService.sign();
}
Service层
// 用户签到功能@Overridepublic Result sign() {
// TODO 1.获取当前登录用户Long userId = UserHolder.getUser().getId();// TODO 2.获取日期LocalDateTime now = LocalDateTime.now();// TODO 3.拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = "sign:"+userId+keySuffix;
// TODO 4.今天是本月第几天,就向那个bit位存值int dayOfMonth = now.getDayOfMonth();
// TODO 5.写入Redis SETBIT key offset 0/1stringRedisTemplate.opsForValue().setBit(key,dayOfMonth-1,true);return Result.ok();}
从左往右数,今天是9号

2.3 统计连续签到
2.3.1 分析
统计总的签到次数不复杂,但是统计截止到今天为止的连续签到次数较为复杂
连续签到天数:从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。

怎么获取到本月到今天为止的所有签到数据?
BITFIELD key GET u[dataOfMonth] 0
命令可以帮助我们获取到指定范围内的所有数据
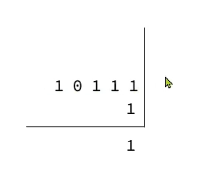
如何逐个bit位从后向前遍历?
与1做与运算,就能得到最后一个bit位
与1做与运算,只有两个都是1,最终结果才是1
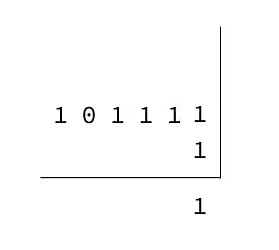
随后右移动一位,下一个bit位就成为了最后一个bit位,继续运算
2.3.2 代码实现
需求:实现下面接口,统计当前用户截止当前时间在本月的连续签到天数

Controller层
@GetMapping("/sign/count")
public Result signCount(){return userService.signCount();
}
Service层
// 获取连续签到天数@Overridepublic Result signCount() {// 1.获取当前登录用户Long userId = UserHolder.getUser().getId();
// 2.获取日期LocalDateTime now = LocalDateTime.now();
// 3.拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = "sign:" + userId + keySuffix;
// 4.今天是本月第几天,就向那个bit位存值int dayOfMonth = now.getDayOfMonth();
// TODO 5.获取本月截止今天为止的所有签到记录(返回的是一个十进制的数字)
// 因为可以同时执行查询、修改、自增功能,那这样的话返回值也会有多个,所以最终是一个list集合List<Long> result = stringRedisTemplate.opsForValue().bitField(key,
// BitFieldSubCommands.create() 创建子命令BitFieldSubCommands.create()
// unsigned无符号, dayOfMonth表示截取多少bit位.get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth))
// 表示从0开始查.valueAt(0));if (result == null || result.isEmpty()) {return Result.ok(0);}
// 我们这只执行了查询,所以集合中只有一个元素Long num = result.get(0);if (num == null || num == 0) {return Result.ok(0);}
// TODO 6.循环遍历int count =0;while (true) {
// TODO 6.1 数字与1做与运算,得到数字的最后一个bit位
// TODO 6.2 判断这个bit位是否为0if ((num & 1) == 0) {
// TODO 6.3如果为0,说明未签到,结束break;} else {
// TODO 6.4如果不为0,说明已签到,计数器+1count++;}// TODO 6.5把数字右移动一位,抛弃最后一个bit位,继续下一个bit位
// 先右移一位,在赋值给numnum >>>=1;}return Result.ok(count);}
三、UV统计
首先我们搞懂两个概念:
UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
PV往往比UV大很多
PV/UV可以看出网站的用户粘度如何
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖
理想的方案就是使用HyperLogLog
3.1 HyperLogLog用法
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。
相关算法原理大家可以参考: https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!
作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
三个命令
-
**PFADD key element [element …]**插入元素
插入五个元素.
不管加入多少重复元素,他只记录一次。天生适合做UV统计
PFADD hl1 e1 e2 e3 e4 e5

- **PFCOUNT key [key …]**统计总量
FCOUNT hl1

- PFMERGE destkey sourcekey [sourcekey …]

3.2 测试百万数据的统计
直接利用单元测试,向HyperLogLog中天际100万条数据,看看内存占用和统计效果如何:
@Test
void testHyperLogLog() {String[] values = new String[1000];int j = 0;for (int i = 0; i < 1000000; i++) {j = i % 1000;values[j] = "user_" + i;if(j == 999){// 发送到RedisstringRedisTemplate.opsForHyperLogLog().add("hl2", values);}}// 统计数量Long count = stringRedisTemplate.opsForHyperLogLog().size("hl2");System.out.println("count = " + count);
}
但是最终返回结果是997593,误差还是可以的