本文整理自美团技术沙龙第75期的主题分享《美团数据库攻防演练建设实践》,系超大规模数据库集群保稳系列(内含4个议题的PPT及视频)的第4篇文章。
本文作者在演讲后根据同学们的反馈,补充了很多技术细节,跟演讲(视频)相比,内容更加丰富。文章分成上、下两篇,上篇将介绍数据库的异常发现跟诊断方面的内容,下篇将介绍内核可观测性建设、全量SQL、异常处理以及索引优化建议与SQL治理方面的内容。希望能够对大家有所帮助或启发。
-
1 背景&目标
-
2 平台演进策略
-
3 异常发现
-
3.1 数据分布规律与算法选择
-
3.2 模型选择
-
-
4 异常诊断
-
4.1 主从延迟(内核代码路径分析)
-
4.2 大事务诊断分析(内核功能增强)
-
4.3 MySQL Crash分析(内核Core Dump分析)
-
1 背景&目标
MySQL的故障与SQL的性能,是DBA跟研发同学每天都需要关注的两个重要问题,它们直接影响着数据库跟业务应用程序的稳定性。而当故障或者SQL性能问题发生时,如何快速发现、分析以及处理这些问题,使得数据库或者业务系统快速恢复,是一项比较大的挑战。
针对此问题,美团数据库自治平台经过多轮的迭代建设,在多个场景下已经实现了异常的发现、分析以及处理的端到端能力。本文将跟大家分享一下我们平台建设的心路历程,同时提供一些经验、教训供同行参考,希望能够起到“抛砖引玉”的作用。本文主要介绍以下主题:
-
异常发现:基于数理统计方式的动态阀值策略,来发现数据库系统的指标异常。
-
故障分析:丰富完善数据库关键信息,来做精确的数据库异常根因分析;深入挖掘内核价值,来解决根因诊断方面的疑难杂症。
-
故障处理:依据异常根因分析的不同结果,通过自助化或自动化的方式来进行故障的恢复处理。
-
内核可观测性建设:如何跟数据库内核团队合作,从内核的角度来分析SQL性能问题,通过内核团队大量的内核代码改造,力求将数据库的可观测性跟诊断做到极致。
-
单SQL优化建议:通过改造MySQL存储引擎,同时结合查询优化来打造基于Cost模式的索引优化建议。
-
基于workload索引优化建议:基于整个DB或者实例的Workload策略的索引优化建议,为实现数据库的索引自维护提供前置条件。
-
基于SQL生命周期的治理:实现从SQL上线前、执行过程中、执行完毕后几个环节,以期实现端到端的慢SQL治理。
2 平台演进策略
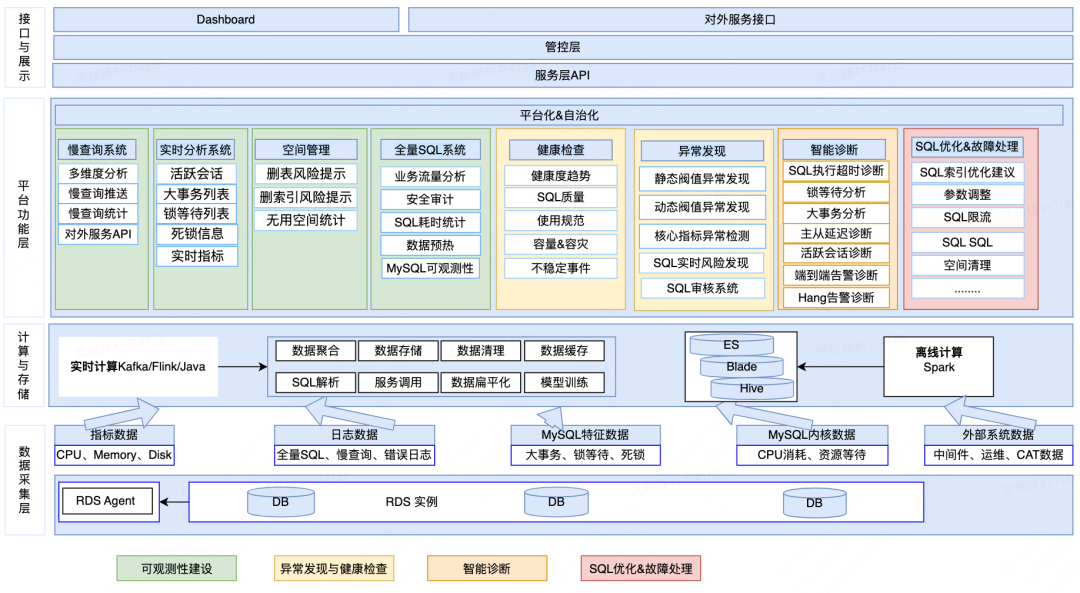
美团数据库自治平台从下到上总体分为四层,分别为接口与展示、平台功能层,计算与存储、数据采集层,平台的总体架构以及每一层的作用如下:
-
数据库采集层:要进行数据库的诊断与分析,需要依靠关键的指标以及SQL文本数据,当前在每个数据库实例上部署一个数据采集程序(rds-agent)统一负责采集、上报关键数值指标以及SQL文本数据。
-
数据计算与存储层:数据采集层上报上来的数据,依托Kafka、Flink&Spark作为数据缓冲,对关键组件进行相关的数据处理,如SQL解析、SQL模版化、数据聚合等操作,再把处理的结果存入ES、Blade(美团自研的分布式数据库)、Hive等分布式数据库或者大数据平台,提供给上层的平台功能层使用。
-
平台功能层:此层是整个系统最为重要的部分,由于平台同时服务于DBA运维团队及研发团队,所以平台的建设分成了两条路:1)主要面向DBA用户,按照可观测性建设、异常发现、故障根因分析、故障处理几个阶段来进行建设;2)主要面向研发同学,按照SQL优化建议、风险SQL的发现、分析与SQL治理等跟SQL相关的几个阶段来建设。当然,两者并没有严格界限,这些功能所有的用户都可以同时使用。
-
接口与展示:平台功能层提供的核心功能会通过Portal来展示,同时为了让平台提供的功能更好地集成在用户自己的系统中,我们也通过OpenAPI的方式对外提供服务。
3 异常发现
数据库产生异常时需要尽早地发现,才能防止异常一进步放大,避免造成真正的故障。异常发现的主要方式是对数据库或者OS的关键数值指标进行监控,相关指标包括seconds_behind_master、slow_queries、thread_running、system load、Threads_connected等等,也可以是业务端研发关注的关键指标,如“应用程序访问数据库的报错数量”、“SQL执行平均耗时”等指标来进行监控。如果这些指标短时间内发生比较大的波动,那么数据库很可能出现了一些异常,这就需要及时进行处理。
这些异常如何才能被发现呢?业界一般有基于静态阀值以及动态阀值的两种异常发现策略。前者很简单,如根据专家经验,人工设定seconds_behind_master或者Threads_connected的告警阀值,超过阀值就认为发生了异常。此方式虽然简单易用,但OLTP、OLAP等不同的业务场景,对于相同指标的敏感度是不一样的,如果所有场景都使用统一的静态阀值来做异常发现,难免会有很多误告。而如果每个场景都去手工去调整,既不灵活,成本又太高,解决方案是基于不同场景的历史时序数据,使用数理统计的方式来分别建模,通过拟合出各自场景的模型来作为异常发现的策略。
| 3.1 数据分布规律与算法选择
基于数理统计方法的异常发现,需要根据具体的场景使用特定的模型。一般来说,模型的选择跟时序数据的分布形态有很大的关系,时序数据的分布并不总是都像正态分布一样都是对称的,而是有些是左偏的,有些是右偏的,当然也有对称分布的。下图就展示典型的三种不同的时序数据分布形态。
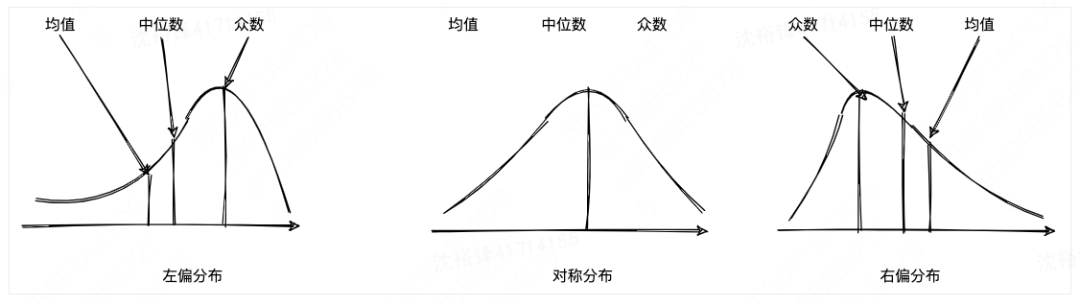
针对上面的三种不同时序数据的分布形态,以及每种异常检测算法自身的特性,我们分别采用不同的异常检测算法。
对于低偏态高对称分布选择“绝对中位差(MAD)”,中等偏态分布选择“箱形图(Boxplot)”,高偏态分布选择“极值理论(EVT)”。没有选择3Sigma的主要原因是:它对异常容忍度较低(建模的时候,如果有噪音等异常点也不会对模型的形态产生很大的影响,则说明异常容忍度很高),而绝对中位差(MAD)从理论上而言具有更好的异常容忍度,所以在数据呈现高对称分布时,通过绝对中位差替代3Sigma来进行检测。

| 3.2 模型选择
数据分布跟算法适用场景的分析之后,对内部的时序数据进行检查,发现数据的规律主要呈现漂移、周期和平稳三种状态,对样本先进行时序的漂移(如果检测存在漂移的场景,则需要根据检测获得的漂移点t来切割输入时序,使用漂移点后的时序样本作为后续建模流程的输入)。
之后同时进行平稳性分析(如果输入时序S满足平稳性检验,则直接通过箱形图或绝对中位差的方式来进行建模)以及周期分析(存在周期性的情况下,将周期跨度记为T,将输入时序S根据跨度T进行切割,针对各个时间索引j∈{0,1,⋯,T−1} 所组成的数据桶进行建模流程。不存在周期性的情况下,针对全部输入时序S作为数据桶进行建模流程),再对时序数据分布特性进行偏度的计算,最后再根据不同的偏度特性选择不同的算法模型,具体如下:
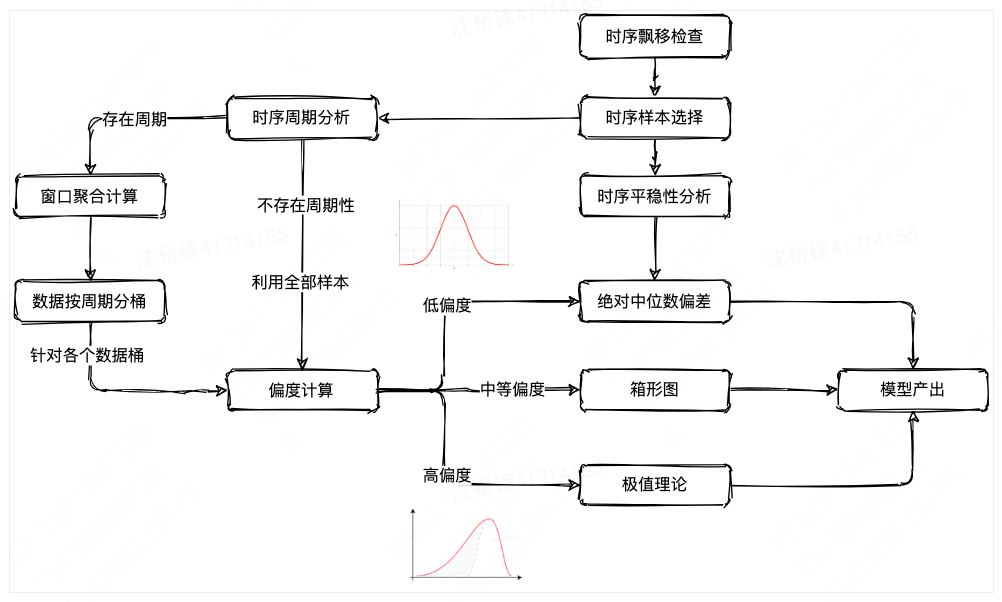
在算法确定之后,先在离线环境针对不同的场景使用历史指标来训练模型,模型训练完毕之后会存入数据库,在生产环境运行过程中,对于不同场景下的数值指标根据其特性来加载不同的模型,并且结合Flink实时计算框架来实时的发现指标的异常并进行告警。
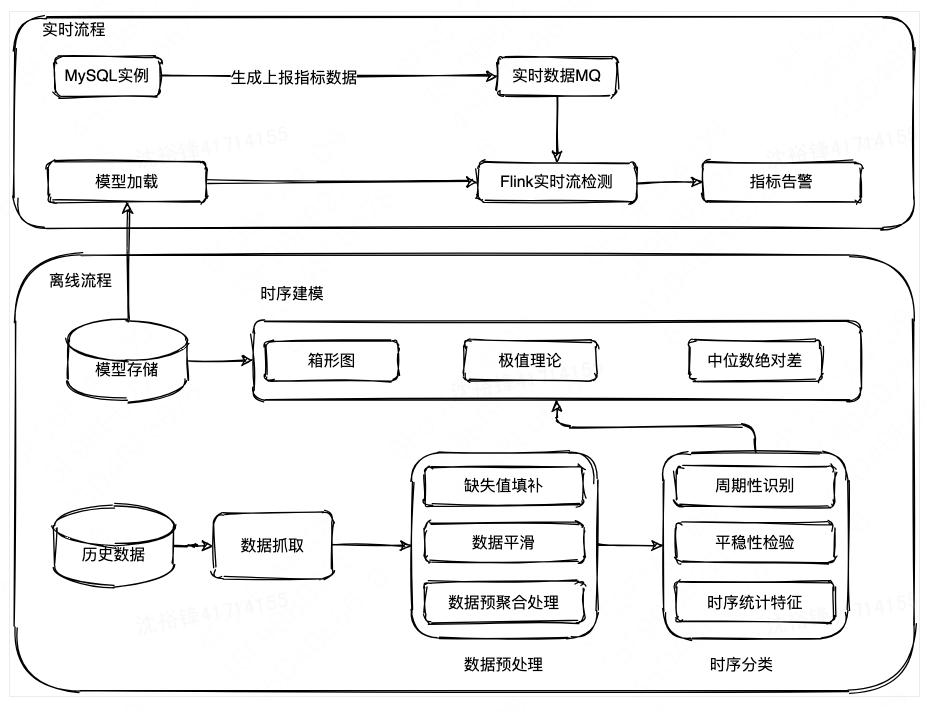
4 异常诊断
发现指标异常后,需要快速的给出异常的根因,我们可以根据具体的根因来选择不同的处理策略,然后进行自动或者手动的恢复工作。根因分析可以基于专家经验,也可以严格地按照内核代码的逻辑来进行分析。
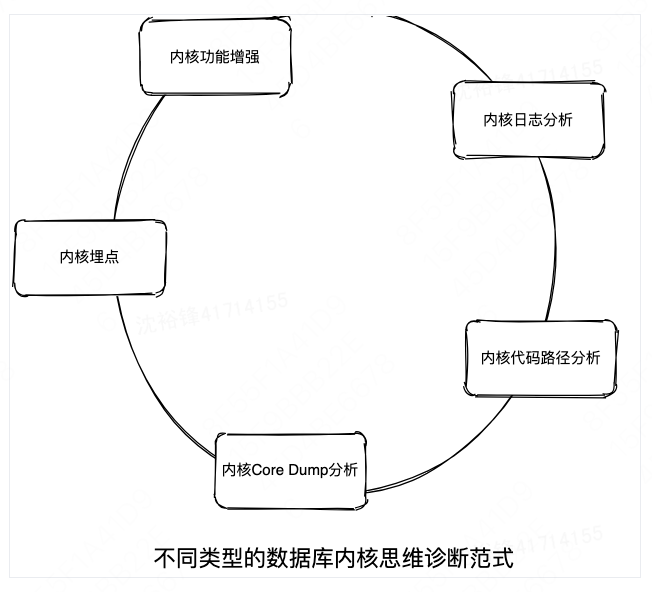
本文重点讲述后者,强调如何使用“内核思维”来解决专家经验很难或者无法解决的诊断问题。本文将列举“内核代码路径分析”、”内核日志分析”、“内核功能增强“、“内核Core Dump分析”以及“内核埋点”等几种不同的范式,来说明数据库根因诊断的思路。
| 4.1 主从延迟(内核代码路径分析)
这里先介绍“内核代码路径分析”这个方式来诊断根因。对于数据一致性要求比较高的应用程序,seconds_behind_master是一个十分重要的指标,如果其值过大就需要诊断其根因,防止应用程序读取到不一致的数据。根据专家经验,其值过大可能由“QPS突增”、“大事务”、“大表DDL”、“锁阻塞”、“表缺少主键或者唯一健”、“低效执行计划”、“硬件资源不足”等因数造成,把这些专家经验总结成规则列表,当异常产生时逐个迭代去验证是不是符合某个规则,据此来诊断根因,然而此方式存在如下两大问题:
-
无法枚举所有根因:经验由于其固有的局限性不可能考虑到所有的故障场景,如何完整的给出造成seconds_behind_master值异常的所有规则是一个挑战;另外,如果需要对一个全新的指标进行诊断,而在没有任何的专家经验情况下,如何能快速地整理出完整的规则列表?
-
缺乏对根因的深层次理解:“QPS突增”、“大事务”、“大表DDL”、“锁阻塞”、“低效执行计划”、“硬件资源不足”等因素会造成seconds_behind_master指标值的异常,但是为什么这些因数会造成指标值的异常呢?如果不从内核源码角度来了解这些因素跟seconds_behind_master之间的逻辑计算关系,那么是无法了解真正原因的。
4.1.1 内核代码路径分析
针对上面两个问题,具体策略是直接看seconds_behind_master这个变量在内核层面是如何计算的,只有这样才能完整的枚举出所有影响seconds_behind_master值计算的因数。
从源码角度看,seconds_behind_master的值由①time(0)、②mi->rli->last_master_timestamp和③mi->clock_diff_with_master这三个变量来决定(代码层面seconds_behind_master的计算逻辑是:seconds_behind_master=((long)(time(0) - mi->rli->last_master_timestamp)- mi->clock_diff_with_master),其中time(0)是系统当前时间(用秒表示),clock_diff_with_master这个值的计算很复杂、又很关键,会放到下一节详细进行说明。
而针对mi->clock_diff_with_master的计算,这个变量从源码层面看就是主、从实例之间的时间差;根据当前的信息就可以看出来,从库的当前时间以及主从库之间的时间差都会影响seconds_behind_master值的计算。seconds_behind_master的计算和事务在主从库执行的情况如下:
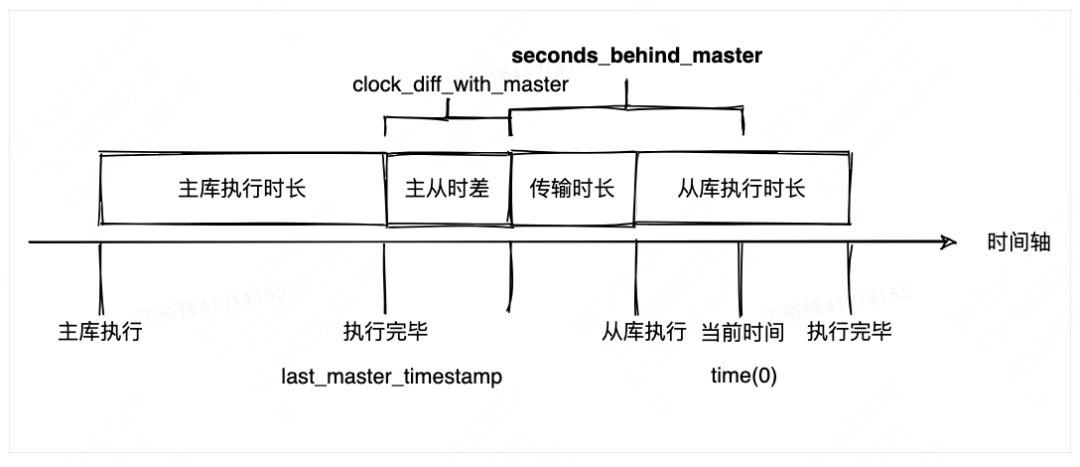
last_master_timestamp计算逻辑
从上面分析可以知道,last_master_timestamp值是影响seconds_behind_master值计算的关键变量,所以很有必要从源码角度分析影响last_master_timestamp值的因数有哪些(从而间接获取了影响seconds_behind_master值的因素)。
last_master_timestamp的值来自于一个叫rli->gaq->head_queue()的成员变量new_ts(此处的rli->gaq->head_queue()是指代某个最新的已经完成replay的事务对应的event group,event group是指一个事务在binlog文件里生成一组event来表示某个事务,这个event group里的event从主库传输到从库后进行replay操作来还原主库的事务)。new_ts值来源于rli->gaq->head_queue())->ts,而rli->gaq->head_queue())->ts的值是通过ptr_group->ts= common_header->when.tv_sec + (time_t) exec_time计算获取的。
再看一下when.tv_sec跟exec_time的含义,前者指代SQL在主库上的SQL执行的开始时间,后者指代SQL在主库上的“执行时长”,“执行时长”又跟“锁阻塞”、“低效执行计划”、“硬件资源不足”等因素息息相关。
值得注意的是,前面提到的rli->gaq->head_queue())->ts的计算跟slave_checkpoint_period以及sql_delay两个变量也有关系,按照这个思路层层迭代下去找出所有影响seconds_behind_master值的因素,这些因素都是潜在的主从延迟异常的根源,这样也解决了前面说的“无法枚举所有根因”跟“缺乏对根因的深层次理解”两大问题。
为了便于理解上诉的逻辑,放出关键的源代码:获取last_master_timestamp值的来源rli->gaq->head_queue()的成员变量new_ts。
bool mts_checkpoint_routine(Relay_log_info *rli, ulonglong period,bool force, bool need_data_lock)
{do{ cnt= rli->gaq->move_queue_head(&rli->workers);} .......................ts= rli->gaq->empty()? 0: reinterpret_cast<Slave_job_group*>(rli->gaq->head_queue())->ts; //其中的ts来自下面的get_slave_worker函数;rli->reset_notified_checkpoint(cnt, ts, need_data_lock, true);// 社区版本的代码 rli->reset_notified_checkpoint(cnt, rli->gaq->lwm.ts, need_data_lock);/* end-of "Coordinator::"commit_positions" */......................
}获取Master实例上执行的SQL的开始跟执行时长信息tv_sec跟exec_time。
Slave_worker *Log_event::get_slave_worker(Relay_log_info *rli)
{
if (ends_group() || (!rli->curr_group_seen_begin && (get_type_code() == binary_log::QUERY_EVENT || !rli->curr_group_seen_gtid))){..............ptr_group->checkpoint_seqno= rli->checkpoint_seqno;ptr_group->ts= common_header->when.tv_sec + (time_t) exec_time; // Seconds_behind_master relatedrli->checkpoint_seqno++;}
}根因层叠图
如果进一步分析内核代码,可以发现影响seconds_behind_master变量计算的因素还有很多,但是找出这些因素的思路是相同的。这个思路的好处是:无论之前有没有相关专家经验,理论上这种分析方式都能尽可能地枚举出所有的根因。
除了seconds_behind_master,其他的像thread_running、Threads_connected,slow_queries等指标异常的分析也都可以套用这种思路。下面为按照上述思路整理出来的影响seconds_behind_master值的部分因素的层次结构图:
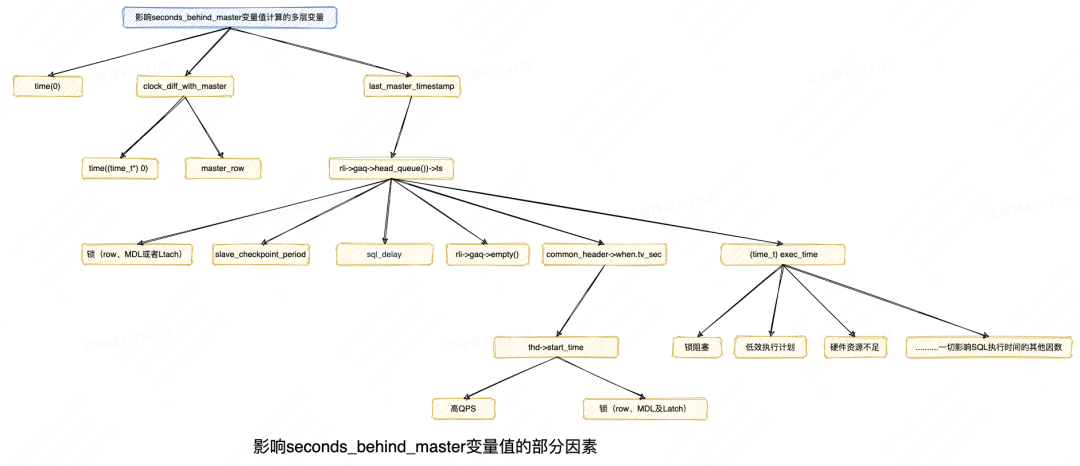
4.1.2 流程分析
把影响seconds_behind_master值的相关因素确认后,可以画一个流程图把这些因素都体现在流程图中的具体位置。这样既能比较形象地理解影响seconds_behind_master的因素在整个主从复制流程中的所处的位置,又便于对整体规则进行查漏补缺。
下面我们使用一个具体的例子,来说明一下上面分析的因素是如何影响seconds_behind_master的。从下图可以看出在执行SQL的过程中影响seconds_behind_master计算的两个变量thd->start_time跟exec_time的计算在master实例。假设start_time的值为2023-07-03 00:00:00,SQL执行了60秒,所以exec_time为60,2023-07-03 00:01:00,SQL在主库上执行完毕,在从库上replay这个SQL,可以看到seconds_behind_master值会从0开始并且逐渐增加60秒,然后再返回0。
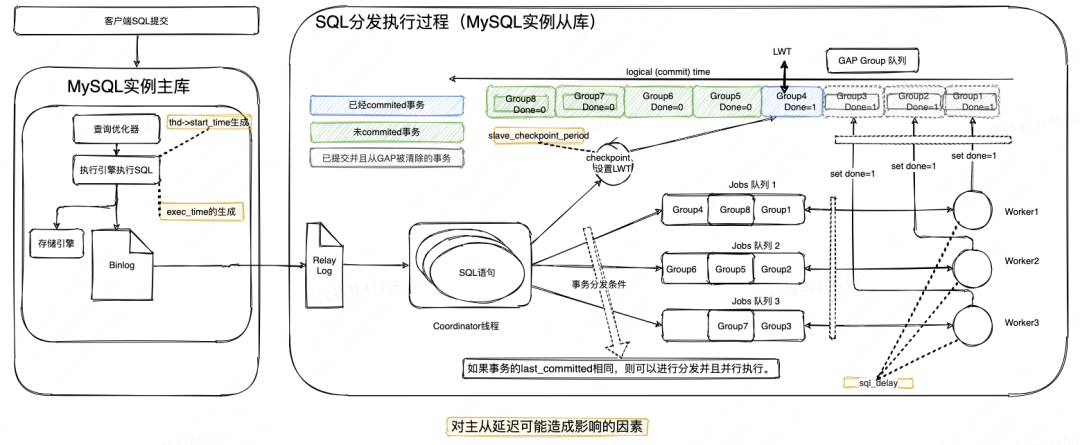
具体原因是:假设我们忽略binlog日志的传输时间,那么从库开始执行replay这个SQL的开始时间也是2023-07-03 00:01:00,所以根据seconds_behind_master=((long)(time(0) - mi->rli->last_master_timestamp)- mi->clock_diff_with_master)=2023-07-03 00:01:00 - 2023-07-03 00:00:00-60s,结果就是0,然后SQL的执行时间是60秒,并且(long)(time(0)(当前时间)的时间一秒一秒的在增加,所以seconds_behind_master值会从0开始逐渐增加至60秒。
再看一下其他的因数,协调器(Coordinator)会把Group放入一个叫做GAP Group的队列中,Coordinator会以slave_checkpoint_period值为周期来扫描GAP Group中的元素并且更新rli->gaq->head_queue())->ts值,所以果slave_checkpoint_period的值被设置的很大,那么rli->gaq->head_queue())->ts的值因为没有及时更新而变得比较旧,从而引起seconds_behind_master值变大。
另外,每个Worker读取自己队列的Group元素,进行repaly操作,需要注意的是sql_delay这个变量,如果当前时间还没有达到sql_delay规定的时间(假设sql_delay被设置为100秒,那么SQL对应的binlog日志到达从库后需要等待100秒再执行),那么worker就不会进行repaly工作,这间接导致影响计算seconds_behind_master变量thd->start_time值比正常情况下小了100秒,所以当worker进行replay的时候,seconds_behind_master的值就会相应的增加100秒。
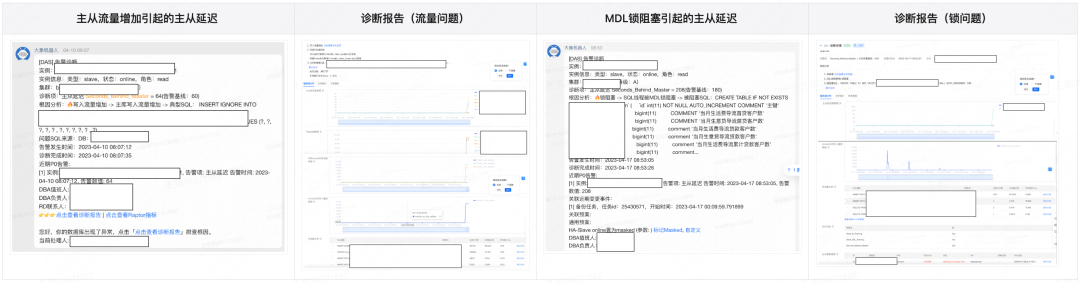
4.1.3 产品展示
下面的产品展示了因为流量突增跟MDL锁造成的主从延迟的诊断分析报告的产品页面。我们可以看到,流量突增的具体SQL以及MDL锁的持有者,方便用户进行限流或者Kill掉阻塞者SQL。
| 4.2 大事务诊断分析(内核功能增强)
大事务的存在,对整个数据库系统的稳定性与总体SQL的性能都会产生很大的挑战,如大事务长时间持有某个锁会造成大面积阻塞,或者更改过多的行数造成整个实例硬件资源的不足。我们需要及时发现这些场景,并且将其信息发送给用户治理,但在实践过程中,往往面临如下的两大挑战:
第一个挑战:无法得到大事务所包含的完整的SQL列表,造成用户不清楚大事务的全貌是什么,用户也就无法识别需要优化的大事务。
-
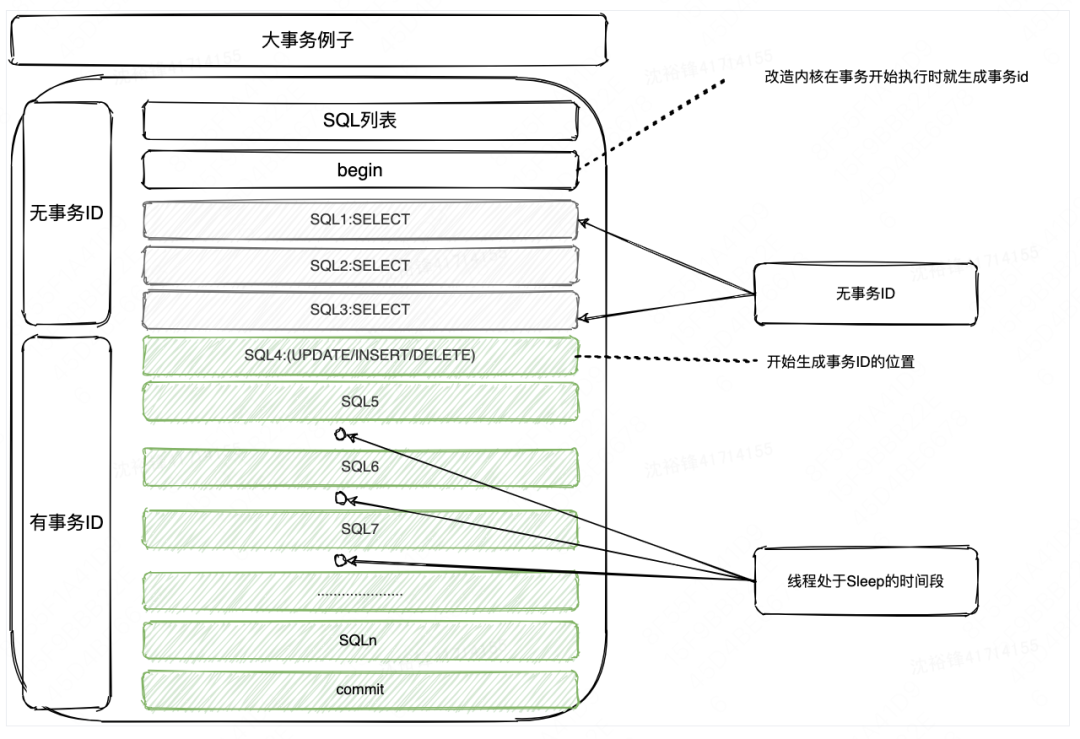
解决方案:每个事务来MySQL会在内核层面生成一个唯一的事务ID:trx_id,如果事务包含的每条SQL,都给其附加一个事务ID trx_id字段,并且把这些SQL连同trx_id一起输出(通过全量SQL输出),问题就可以解决;不过这里还有一个挑战,这个事务ID到底是何时产生的呢?如何大家熟悉内核内部事务的执行过程,就会知道事务ID的只有在事务修改数据的时候才会通过trx_assign_id_for_rw这个方法被获取,这意味着就下面这个图上展示的事务而言,是无法获取SQL4之前执行的读SQL语句列表,所以获取到的事务的SQL列表还是残缺的,那么如何获取到完整的SQL列表呢?解决方案也很简单,可以把事务ID的生成逻辑提前到在事务刚开始执行的时候生成就可以了。
第二个挑战:大事务的耗时组成不明确。数据库规定执行时长大于某个阀值的事务被定义为大事务,但是不清楚耗时到底是SQL本身的执行时间还是SQL执行之外的耗时,SQL执行之外的耗时可能是在执行上下两个SQL之间,业务端在处理一些跟数据库无关的业务逻辑,也可能是网络延迟造成的。
-
解决方案:上述问题可以通过在数据库内核内对SQL执行开始时、结束时分别埋点时间戳来解决,这样整个大事务执行总时间中有多少时间是在执行SQL,有多少时间是在Sleep就一目了然;当然,这一块还可以做的更加的细致,比如两条SQL之间的Sleep时间到底是网络延迟还是应用程序端的延迟等,可以进一步细分大事务造成的原因到底是在MySQL端、网络端还是用户自己的应用程序造成的等待;关于计算网络端的延迟计算,可以参考MySQL内部的mysql_socket_send_time跟vio_socket_io_wait_time这2个关键指标的实现思路,下图是一个大事务的SQL列表以及耗时组成列表。
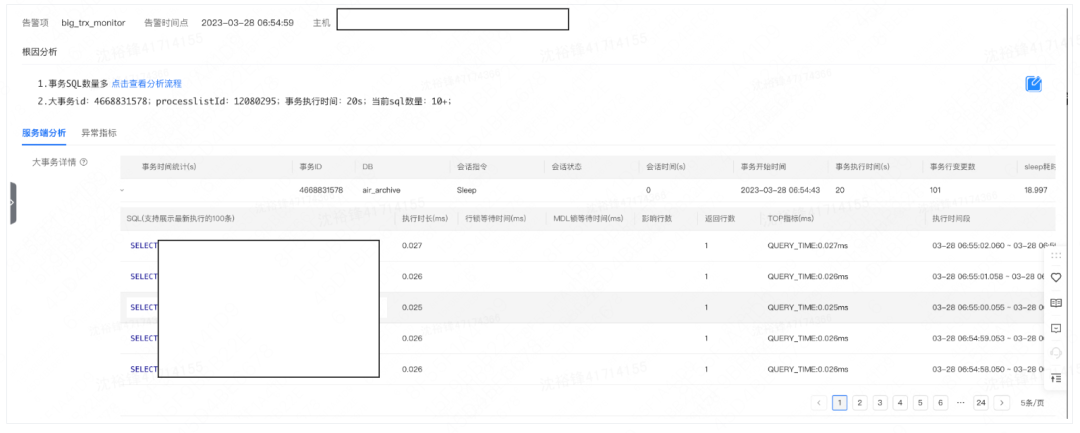
4.2.1 产品展示
内核团队通过内核改造,对事务中所包含的SQL都提供了trx_id后就可以根据trx_id把整个事务所有的SQL串起来。根据SQL执行的开始跟结束时间,我们也提供了所有SQL之间的Sleep时间,成功解决了上面的两个挑战,产品效果图如下:
| 4.3 MySQL Crash分析(内核Core Dump分析)
MySQL实例突然Crash了怎么进行根因诊断?进程Crash的根因分析,也是数据库故障中最难分析的问题之一。本节提供一些思路尝试去分析各种场景下的MySQL Crash的根因。
4.3.1 Crash的触发方式
在分析Crash的根因之前,我们可以先了解一下MySQL进程是如何被Crash的整个过程十分有必要。一般来说,触发Crash的原因分成两类:①MySQL进程自己触发了Crash(这里称之为MySQL自杀);②MySQL进程被OS杀死。
针对前者,比如MySQL发现某个关键数据发生了Data Corruption、磁盘空间不足、硬件错误、等待内核锁时间过长、MySQL 内核Bug等场景,都可能导致MySQL自杀。尤其是检查到MySQL内核里有些数据的状态不符合预期时,是必要要让那个实例Crash也不能继续执行,否则可能会产生更加严重的数据不一致性问题;而后者,OS如果发现系统内存严重不足或者空指针引用等情况,就会把包括MySQL在内相关的进程杀掉。
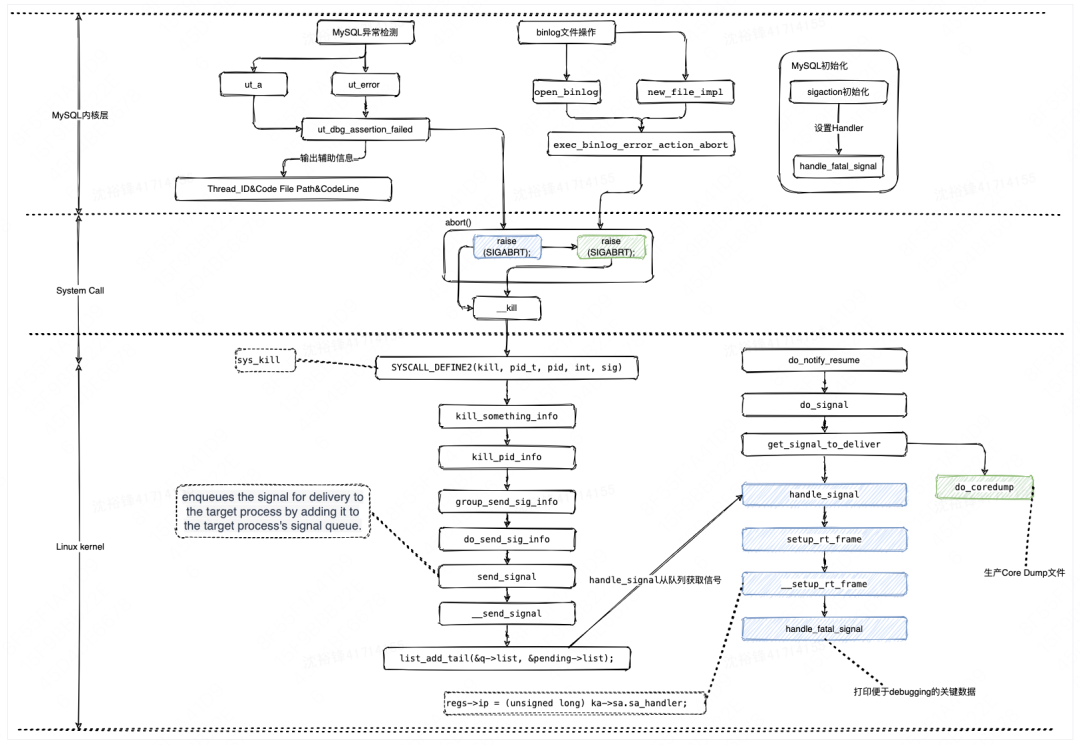
分析一下MySQL自身触发Crash这个场景,在MySQL内部有很多地方通过ut_a(如果是ut_error的话,则直接触发Crash)断言对程序的内部数据状态进行异常检查,如果发现数据状态不符合预期,那么势必发生了Data Corruption,这个时候程序会调用ut_dbg_assertion_failed在进程Crash之前做一些关键信息(如thread id、发生Crash的文件名字跟code line等)的记录后,会继续调用abort()向进程发送SIGABRT信号量让进程Crash掉。
需要注意的是,从abort()的源码可知,这里调用了两次raise (SIGABRT),第一次调用raise (SIGABRT)触发处理函数handle_fatal_signal(此函数在MySQL实例初始化时通过sigaction的sa_handler注册)被调用,这个函数主要是打印一些重要的调试信息,便于做Core Dump分析;第二次调用raise (SIGABRT)的目的,是为了让OS生成Core Dump文件(core Dump文件非常重要,因为所有引起MySQL Crash的现场信息都包含在Core Dump里面);如果是在MySQL自杀的情况下发生了Crash ,一般会在errorlog里会产生如下的一段跟Crash相关的现场信息,其中的“signal”、“触发Crash的线程堆栈”、“正在执行的SQL”等信息都是分析Crash根因的关键信息。
下图为MySQL通过ut_a断言检查异常问题后再到OS触发进程Crash的整体流程图。总体来说,MySQL通过raise来发送SIGABRT信号到一个队列,OS内核处理这个队列的信号并调用MySQL的处理程序handle_fatal_signal来保留一些关键的现场信息。这里需要注意到的是,OS内核在__setup_rt_frame中执行“regs->ip = (unsigned long) ka->sa.sa_handler;”,这个步骤正是让MySQL的handle_fatal_signal方法被顺利的调用的原因。
4.3.2 根据Signal类型做根因分析
分析Crash根因的第一步就是看触发了什么类型的signal,常见类型有“signal 6”、“signal 7”、“signal 11”几种类型,当知道了Signal类型后就有一个根因分析的大方向。根据经验,我们将常见的signal类型以及可能引起的原因大致如下图所示,下面对于常见的signal类型以及引起的根因做一个简单的分析。
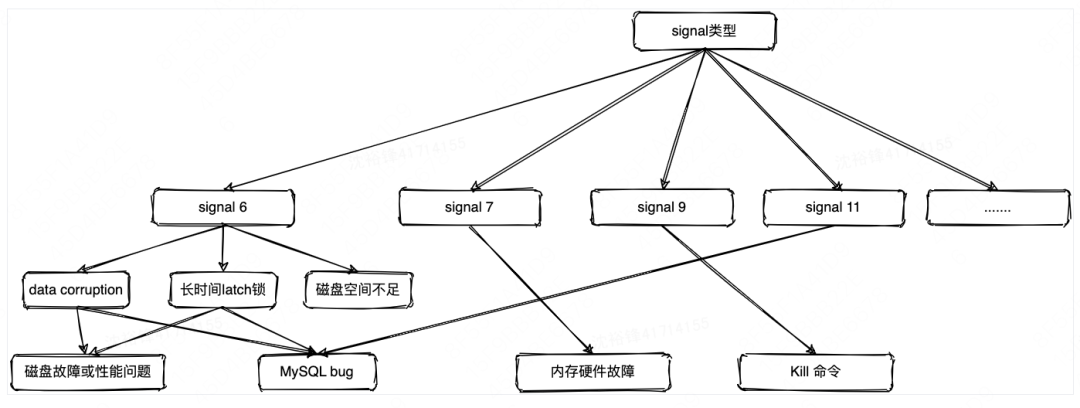
1) 如果是signal 6,一般是实例的磁盘空间不足或者磁盘只读,MySQL的数据发生了data corruption,内核层面latch锁的长时间的锁等待造成。不过这里的data corruption、长时间的锁等待可能是硬盘损坏或者MySQL的Bug造成的,判断逻辑如下:
-
磁盘空间不足或者磁盘只读
-
磁盘写数据时,如果磁盘没有剩余空间或者数据库被设置为read only就会造成实例的Crash,日志中有“Either disk is full or file system is read only while opening the binlog”的字样。
-
data corruption
-
MySQL在运行过程中如果断言(比如这里ut_a(table != NULL)返回false,很可能是数据发生了corruption并且MySQL就会自行Crash掉;发生data corruption时一般在MySQL的error log中有“Database page corruption on disk or a failed file read of tablespace”的字样,所以查看日志来判断否有硬盘故障问题,如果没有硬件故障信息,则可能是MySQL Bug造成的data corruption,具体分析看下面 “MySQL Bug”那部分。
-
长时间无法获取Latch锁
-
如果MySQL长时间没有办法获取到Latch锁,那么MySQL认为系统可能是Hang住了也会引起实例的Crash,并且日志中打印“We intentionally crash the server because it appears to be hung”字样,一般是硬件故障造成的性能问题或者MySQL自身的设计缺陷形成的性能问题造成的,这次场景根因分析比较有挑战。
-
MySQL Bug
-
如果不属于上面任何一种情况,那么有可能是MySQL自身的Bug造成的Crash,比如MySQL对一些SQL解析或者执行时会发生Crash;这种场景一般先看一下Crash发生时正在执行的SQL是什么,这个SQL可能存在于Crash日志中(这个Crash日志中有个例子),可以先把SQL提取出来再次执行查看能否复现问题;如果在Crash日志中看不到SQL语句,就需要从core dump文件中提取SQL了,提取方式是MySQL每个链接对应的THD的成员变量m_query_string就包含了SQL文本,只需要打开Core Dump文件切换到某个包含THD实例的方法内,通过命令“p this->thd->m_query_string.str ”来打印,这里有个例子。
-
再举个MySQL的Bug造成data corruption的例子,从Crash日志里“InnoDB: Assertion failure in thread 139605476095744 in file rem0rec.cc line 578”看出,从rec_get_offsets_func函数中触发ut_error而导致的Crash,之所以触发这个Crash是因为rec_get_offsets_func中的rec_get_status(rec)获取到的MySQL的记录类型不符合预期(因为记录类型只有固定的REC_STATUS_ORDINARY、REC_STATUS_NODE_PTR,REC_STATUS_INFIMUM,REC_STATUS_SUPREMUM这4种类型),如果内核发现一个记录类型不属于这4种类型的任何一种,那么就是发生了data corruption,所以必须要把自己Crash掉。为了验证刚才的结论,看一下Crash发生时的rec的类型是什么,从源码可知rec的类型是通过rec_get_status获取,并且其通过调用的rec_get_bit_field_1跟mach_read_from_1两个函数可以知道rec的类型其实就是rec这个指针往前三个byte(通过#define REC_NEW_STATUS_MASK 0x7UL可知)代表的值。
-
通过gdb加载core dump文件后,切换到抛出exception的线程,因为异常是在rec_get_offsets_func里抛出的,切换到rec_get_offsets_func对应的frame 7来验证rec的类型,看到rec的指针地址为0x7f14b7f5685d(相关分析数据可以看此链接)。前面说过,rec的类型值在rec指针往前三个byte里,也就是指针0x7f14b7f5685a(0x7f14b7f5685d-3)那个位置的值,发现是0x1f,执行与计算(11111(1f)&00111(0x7UL)=00111=7 )得到的类型是7,而记录类型的范围是(0~3),很明显这个指针指向的记录类型值信息发生了data corruption(分析过程查看此链接),这里做了一个rec的类型在正常情况下跟本例异常情况下的类型值计算的对比表,发现正常情况下,rec的类型值就应该是3。
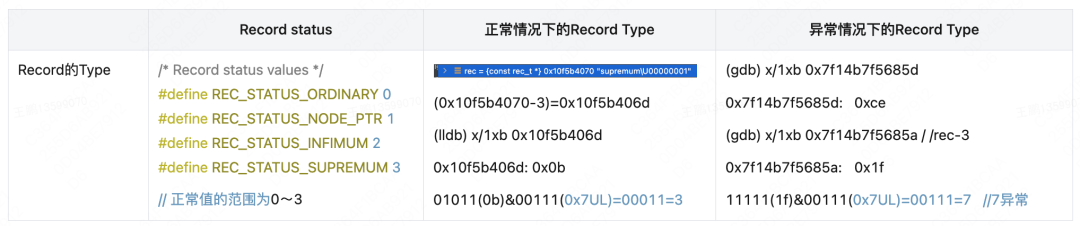
-
这里有个重要问题是,为什么rec的类型是无效的呢?很可能是MySQL搜索满足条件的记录的时候,rec指向的记录很可能被page_cleaner在后台被清理掉了,所以rec指针指向的记录就是无效了。官方有个bugfix,解决方案就是把prev_rec设置为NULL(这里的prev_rec是persistent cursor指向的记录,这里说一下persistent cursor,它是MySQL从InnoDB 层获得记录后进入SQL层前在B-tree上的cursor会被暂时存储到row_prebuilt_t::pcur中,当再次从InnoDB层拿数据时,如果对应的buf_block_t没有发生修改,则可以继续沿用之前存储的cursor,否则需要重新定位,如果没有persistent cursor则每次都需要重新定位则对性能有影响),这样prev_rec != NULL这个条件不满足,也就没有机会进入rec_get_offsets_g_func里去检查rec的类型值而引发Crash了。
2) 如果为signal 7,那么大概率是内存硬件错误,并且日志里一般有“mce: [Hardware Error]: Machine check events logged , mce: Uncorrected hardware memory error in user-access at xxx MCE xxx: Killing mysqld:xxx due to hardware memory corruption”等字样。
3) 如果为signal 9,表示这个进程被Kill命令杀掉了。
4) 如果为signal 11,表示是由MySQL的Bug造成的,这类问题较难分析特别是MySQL Crash现场(通过core dump打印出来的堆栈信息)往往还不是第一现场,由于篇幅关系具体的例子分析不在本文中给出,但是分析的思路跟上面的“MySQL Bug”是类似的。
5 本文作者
裕锋,来自美团基础研发平台-基础技术部,负责美团数据库自治平台的相关工作。
6 参考
-
https://github.com/shenyufengdb/sql
-
https://github.com/percona/percona-server/blob/release-5.7.41-44
-
An Efficient, Cost-Driven Index Selection Tool for Microsoft SQL Server
-
plan-stitch-harnessing-the-best-of-many-plans-2
-
Random Sampling for Histogram Construction: How Much is Enough?
-
AutoAdmin “what-if” index analysis utility
-
What is a Self-Driving Database Management System?
-
Self-Tuning Database Systems: A Decade of Progress - Microsoft Research
-
Automatic Database Management System Tuning Through Large-scale Machine Learning
-
Query-based Workload Forecasting for Self-Driving Database Management Systems
-
The TSA Method
-
LangChain Chat
-
https://github.com/hwchase17/langchain
-
REAC T: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
-
Evaluating the Text-to-SQL Capabilities of Large Language Models
-
SQL-PALM: IMPROVED LARGE LANGUAGE MODEL ADAPTATION FOR TEXT-TO-SQL
---------- END ----------
推荐阅读
| 超大规模数据库集群保稳系列之一:高可用系统
| 超大规模数据库集群保稳系列之二:数据库攻防演练建设实践
| 超大规模数据库集群保稳系列之三:美团数据库容灾体系建设实践