线程
为什么有了进程还需要线程
进程切换的时候会花费很大的代价
(1)上下文切换,CPU寄存器需要切换
(2)虚拟地址和物理地址的映射需要切换
进程间通信麻烦
线程是轻量级的进程
(1)线程是一个正在执行的程序,但是它不在是资源分配的最小单位
(2)同一个进程存在多个线程,多个线程共享内存资源
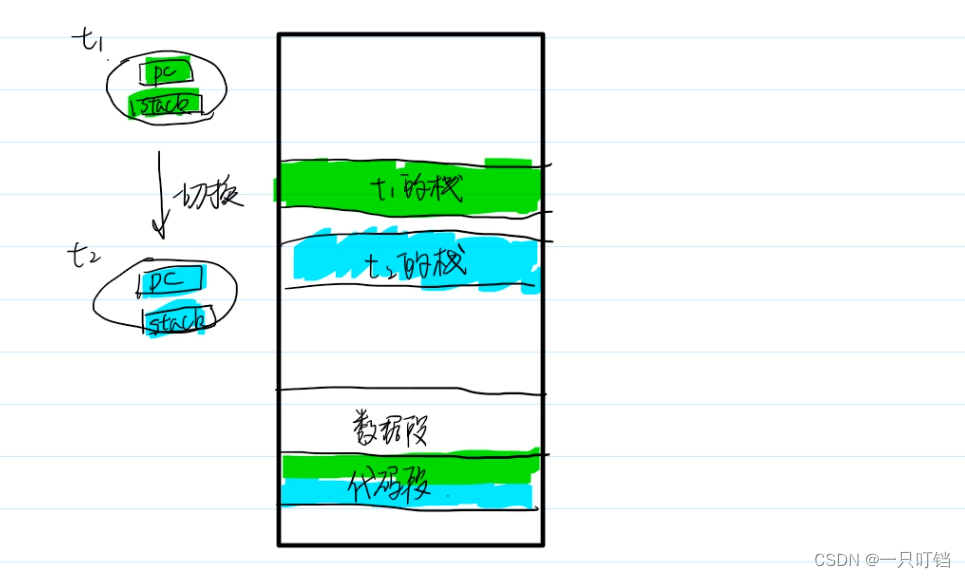
(3)线程也有上下文状态(主要的是PC指针和stack(栈)指针)
用户级线程:不能够被CPU感知到的CPU不能根据用户使用线程的多少来进行调度,用户自己分配这个进程内部各个CPU使用情况,线程调度由进程处理
内核级线程:线程调用是由操作系统处理
CPU调度以线程为单位
原来的进程都是当线程进程
在Linux操作系统中,进程控制块和线程控制块合二为一了,每个进程和线程都有task_struct的描述
引入线程的好处
(1)减少了上下文切换的代价
(2)消灭了页表切换
(3)线程是共享内存的可以无痛通信
创建线程
当我们启动进程就会自动创建一个主线程,主线程栈区从main函数开始压栈
在主线程中可以使用pthread_create函数创建一个子线程
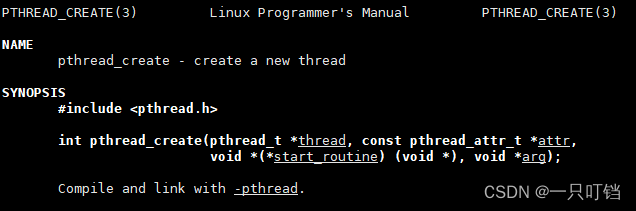
pthread_t *thread:线程ID,不同操作系统中pthread的实现是不一样的
pthread_attr *attr:线程的属性,填NULL表示我们使用默认属性
void *(*start routine) (void *):线程启动函数,参数和返回值都是void*类型-----void *func(void*) 子线程的main函数
void *arg:传递给start_routine的参数
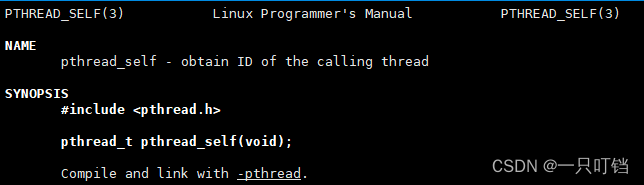
获取自己线程的线程ID

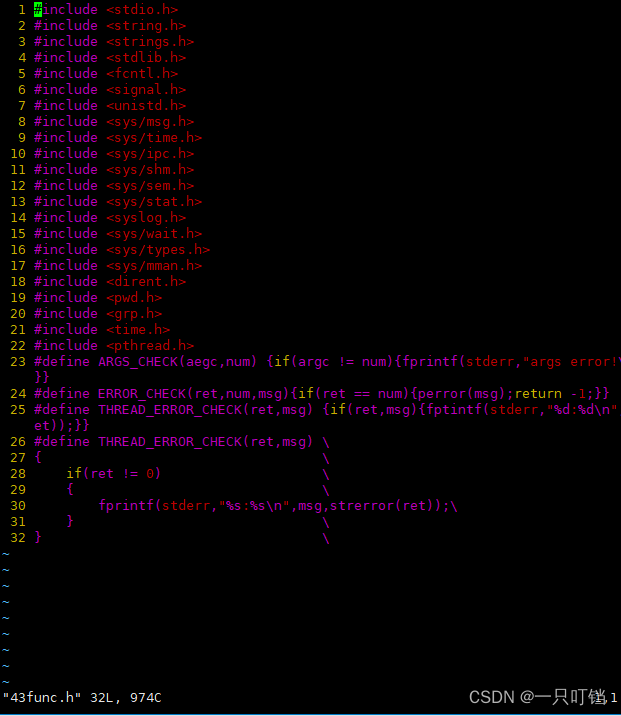
Makefile文件后面添加-pthread

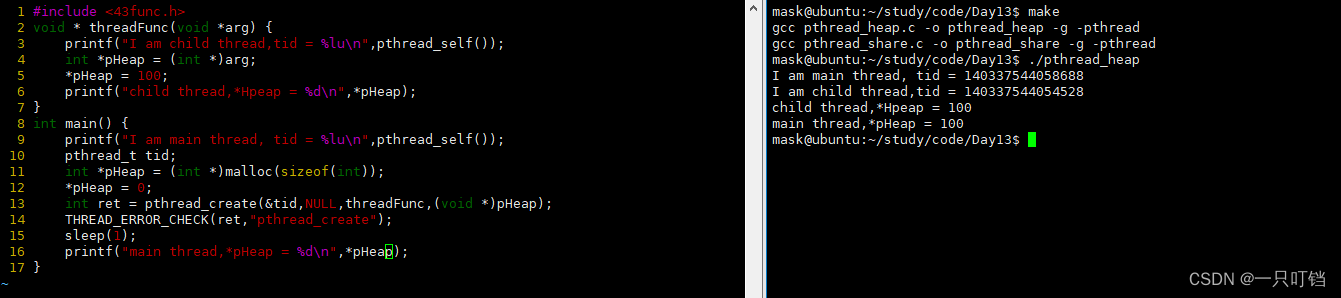
让main主线程创建一个子线程,让主线程和子线程输出自己的线程ID
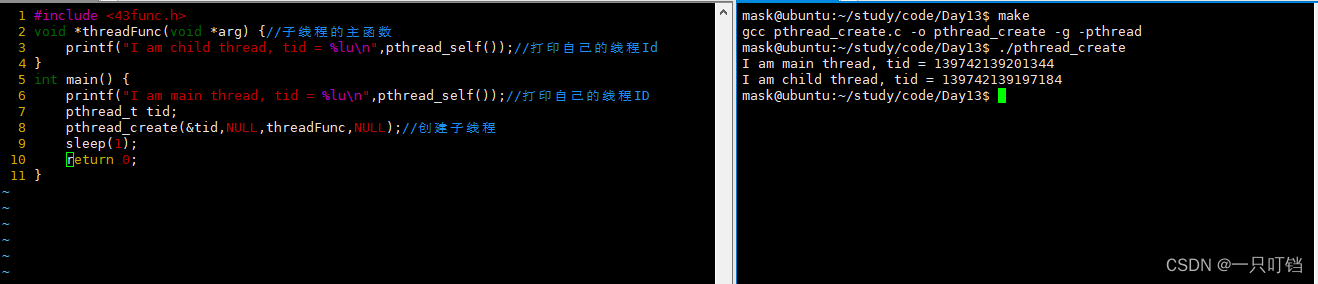
如果我们让父线程sleep(1),最终只会打印main主线程的线程ID,因为当主线程main,也就是进程终止了,那么这个进程里面的线程也就无法运行了
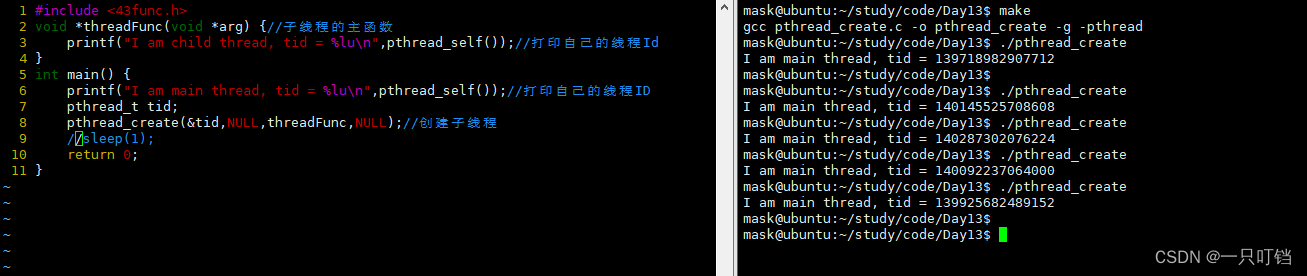
如果我们让主线程只睡20微秒,那么我们打印输出的记录有可能由三条记录,也有可能只有两条记录,因为数据从输入到展示在命令框要经过三个步骤,首先是printf将数据拷贝到stdout,stdout将数据拷贝(原子操作)到内核的文件对象,然后再清空我们的stdout,因此主线程有可能在清空stdout之前就终止,这时,命令框已经输出一次数据,然后发现stdout的数据还存在,就会把stdout的数据在刷新一遍在显示框,这就出现打印三次结果
多线程下不能使用perror
一个典型的报错会做两件事
(1)return -1
(2)修改全局变量errno
然后perror会根据errno生成错误提示字符串,所以perror依赖的数据就会存储在数据段里面,但是多个和线程都可以同时共同访问一个数据段,但是此时如果由多个进程报错,其他线程报错信息会覆盖本线程的包i错信息,因此就不能获取到正确的错误信息
在多线程中报错不会返回-1,而是返回数值,通过返回值数值来确定报错的类型strerror可以通过传入的数值返回给我们一个错误提示字符串
唯一的坏处是它不能打印这个字符串,因此我们需要通过fprintf(stderr)来将错误信息输出
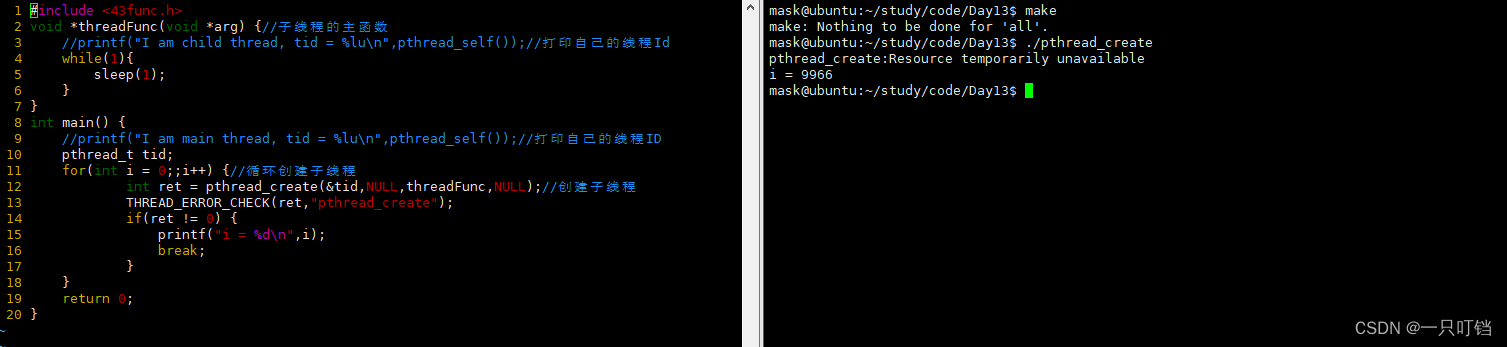
检测我们的进程能够创建多少线程
多线程共享内存空间
多线程可以共享同一个数据段

多线程共享堆空间,主线程和子线程使用同一个数值的地址使用pthread_create传递地址参数,其实我们是直接把第四个参数拷贝到另外一个线程的栈帧里面
多线程之间传递一个整数,直接传递一个long类型的数据,因为void *是8个字节,long类型也是8个字节,不会有信息丢失,如果我们希望主线程和子线程之间共享内存那么就传递指针,如果不希望共享内存你那么久传递long类型。void *既可以当指针用也可以当long来用

多线程的栈区是相对独立的,一个线程可以通过地址区访问另一个线程的栈区
线程的终止
一个进程中的任意一个线程只要触发其中任意一个信号,那么整个进程就会终止,其中所有的线程也都会终止
(1)
main线程的return函数、(2)exit命令、(3)_exit/_Exit、(4)abort、(5)收到导致进程终止的信号
子线程终止自己
(1)从threadFunc中return(尽量不要用)
(2)pthread_exit(主线程不要调用)
void *retval子线程的返回值
pthread_join回收线程的资源
join等待任何一个线程的终止
pthread_t thread目标线程的tid(不是一个指针)
void **retval是拷贝子线程的终止状态,主调函数中申请void * 的内存join试图修改主调函数中的void *
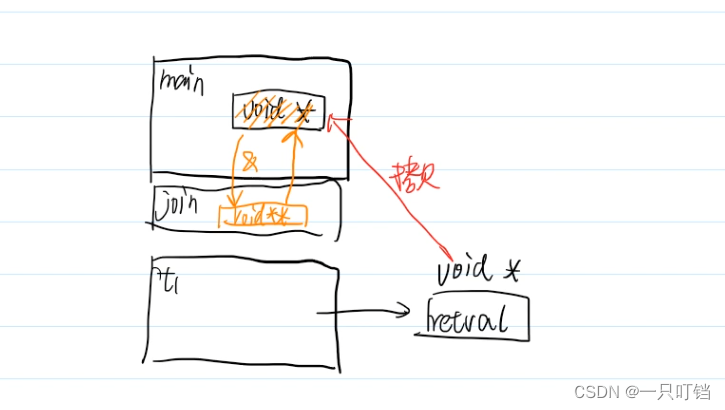
join和exit的例子
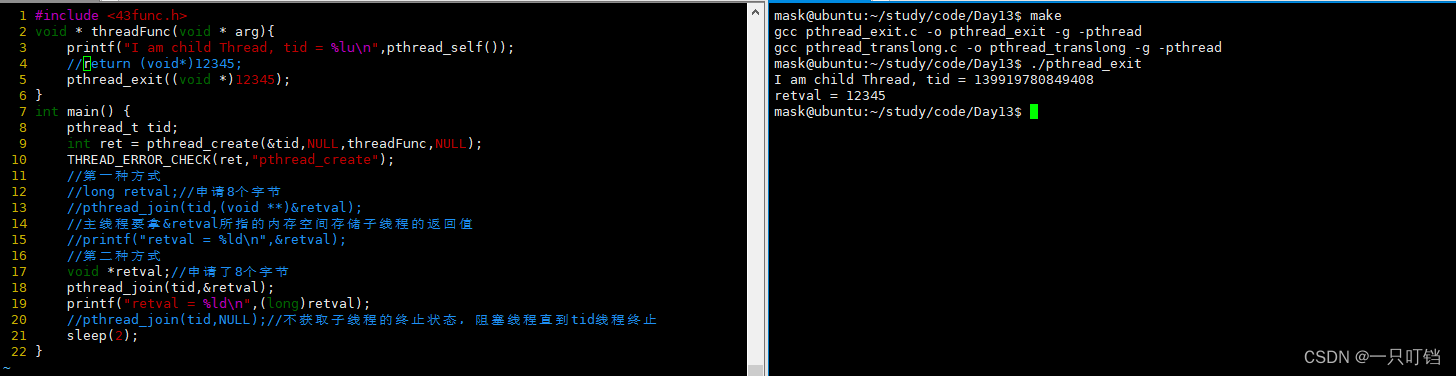
pthread_join的的错误用法

多线程和信号不能同时使用
多线程会共享注册信号的信息,用户无法得知是哪个线程递送信号
线程的取消类似于信号:线程可以在运行过程中给别的线程发送一个取消请求,另一个线程收到取消请求之后,他不会立刻终止,他会将自己的取消标志置为1,运行到一些特殊函数的时候就会取消,在一些特殊函数之前或者调用之后就会取消进程,这些特殊的函数称之为取消点
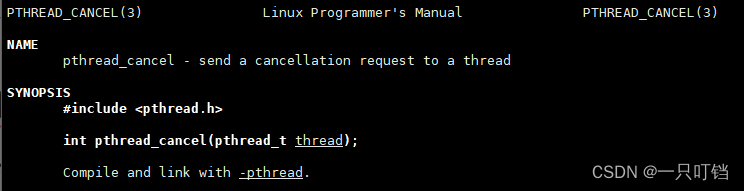
取消点函数
(1)操作文件的系统调用、(2)可能引发阻塞的系统调用;库函数和系统调用都是取消点函数
pthread_mutex_lock加锁不是取消点
如果线程是被pthread_cacel终止的并且取消成功,那么终止的线程返回值为-1
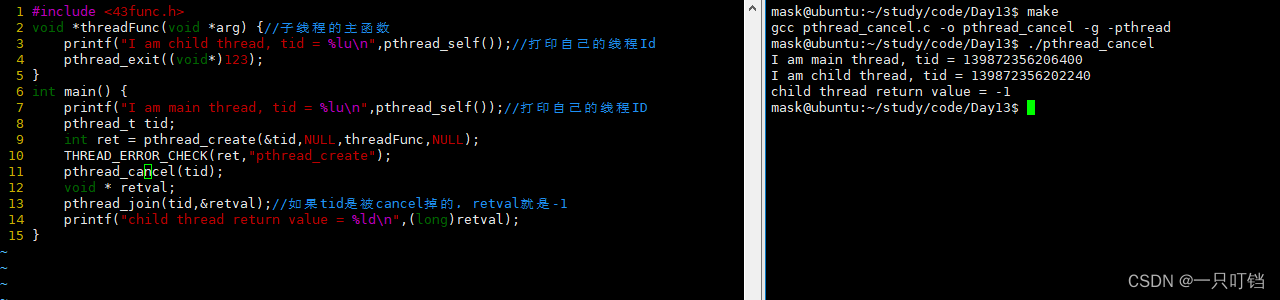
但是如果线程没有碰到取消点函数那么也就不会执行终止指令,会继续执行下去
ps -elLf|grep pthread_cancel查看线程运行状态

手动增加取消点
pthread_testcancel如果取消标志位为真,就终止本线程
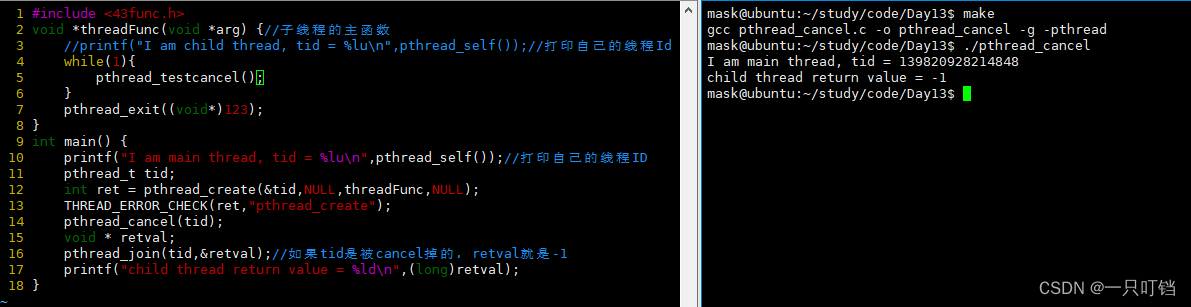
异步终止可能会导致资源泄漏,因为malloc和free函数都是取消点,我们不知道pthrread_cancel函数实在malloc之前还是free之后或者是在malloc和free之间,这就很容易造成资源泄漏。
因此在目标线程运行到取消点函数和取消点函数调用完前终止线程之间会调用线程中终止清理函数
资源清理栈(自动根据申请了多少资源,就释放多少资源)
当我们申请资源malloc ; open/fopen/opendir ; semop/mutex_lok对应的释放行为 free ; close/fclose/closedir ; semop/mutex_unlock,
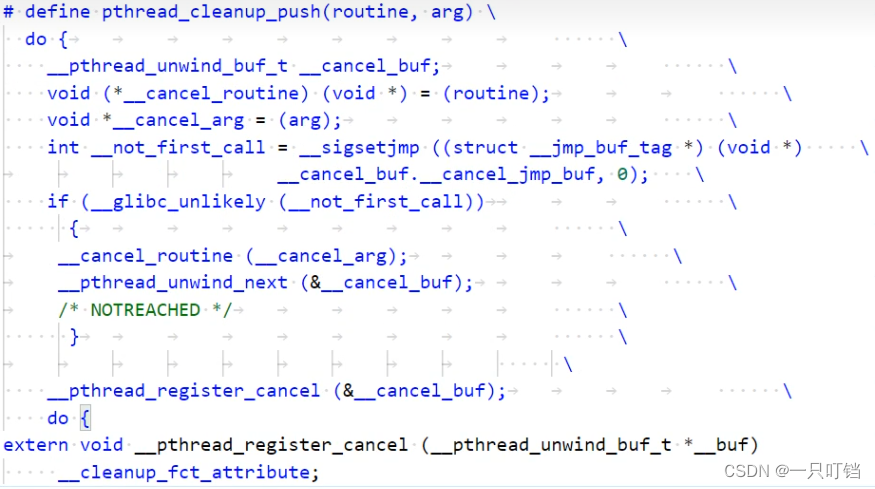
我们会去维护一个特殊的结构,资源清理栈,里面存储了资源释放的行为,当我们申请资源之后就会把对应的释放行为压栈(pthread_cleanup_push)
当线程因为(1)pthread_exit(不包括在启动函数中return)、(2)被cancel终止时;将栈清空
线程可以主动调用pthread_cleanup_pop释放资源
只有pthread_exit(主动)和pthread_cancel(被动)才能调用清理函数,如果使用return语句是不会调用清理函数的
并且pthread_cleanup_pop()的参数如果为0则不会调用清理函数,其参数要大于零才会主动调用清理函数
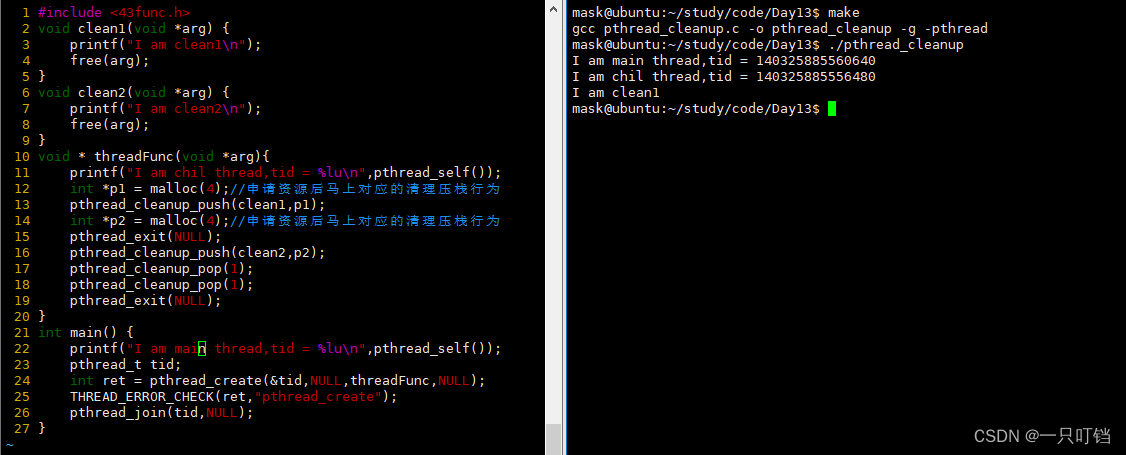
Linux规定push和pop必须在同一个作用域中成对出现
因为在linux中clean和pop的宏定义是利用do while循环写的,push的宏定义包含了do{而pop的宏定义包含了}while(0),因此就可以保证push和pop必须要在作用域里面成对出现,并且在push和pop中间定义的变量不能在这两个语句之外进行使用
mutex互斥锁
一个线程可以做加锁操作
(1)若有任何线程持有锁,加锁的线程会阻塞(P)
(2)若未加锁,加锁操作会将锁加锁,线程继续运行(V)

pthread_mutex_t fastmutex初始化一个锁,静态初始化
pthread_mutex_t recmutex初始化一个锁,静态初始化
pthread_mutex_t errchkmutex初始化一个锁,静态初始化
int pthread_mutex_init初始化一个锁,动态初始化
int pthread_mutex_lock加锁
int pthread_mutex_unlock解锁
int pthread_mutex_destroy销毁锁
使用mutex互斥锁实现两个线程堆同一个地址区域的相加操作
其实现相加所用的时间页也很短相比起使用信号量的每次相加600多微妙而言,互斥锁每次执行时间1.5微秒更显的效率高
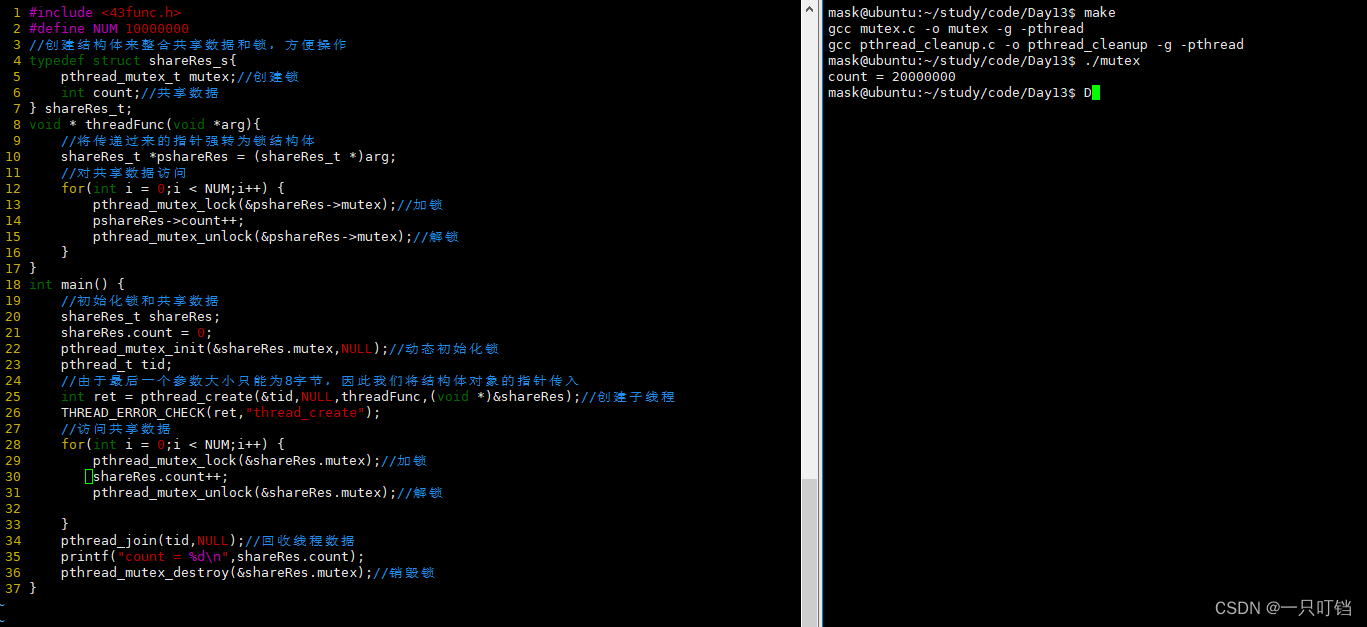
pthread_mutex_lock和pthread_mutex_unlock之间被称为临界区,所有共享资源的访问都要放在临界区内
死锁
线程因为一直在等待永远不可能为真的条件而阻塞就是死锁。
pthread_mutex_lock不是取消点
出现死锁的几种情况
(1)之前说过两个管道的建立就会产生死锁,这是因为我们申请资源的顺序有问题而导致的死锁,我们可任意通过修申请的顺序就可以避免死锁
(2)一个进程在持有锁的期间终止了,也会导致死锁;在线程终止的任何分支都要解锁,我们可以使用资源清理函数pthread_clean_push和pthread_clean_pop来释放锁
(3)一个线程对同一把锁加锁两次也会导致死锁,这个线程就会在等待这把锁解锁,但是这个进程又需要解锁来给其他线程使用锁吗,但是本线程已经因为在等待锁的过程中发生了阻塞
死锁之后进程阻塞到futex里面,是底层使用的锁
mutex底层实现原理
mutex互斥锁,加锁不满足条件会睡眠
rwlock读写锁,在少量写大量读的情况用的比较多
phread_spin_lock自旋锁,加锁时如果不满足条件就会执行while(1),如果条件马上就会就绪,优先使用自旋锁
while(1)占用CPU资源,睡眠不占用CPU资源,睡眠线程属于阻塞态,while(1)线程属于运行态
mutex依赖futex,futex底层使用的就是自旋锁
锁和二元你信号量几乎无差别
差别在用法上,限制哪个线程加的锁,就由哪个线程解锁,但是P,V是可以一个线程P,另一个线程V
解决上面第三种死锁
(1)不写这种代码
(2)使用pthread_mutex_trylock非阻塞加锁,如果为加锁状态,trylock会加锁,如果已加锁,trylock会立刻返回。while循环加上trylock可以实现自旋锁

trylock可能导致活锁,避免活锁,让一个进程执行完操作之后,sleep随机时间
(3)修改锁的属性,对于方法intpthread_mutex_init(pthread_mutex_t *mutex,const pthread_mutexattr_t)函数的第二个参数,我们之前一直使用的都是NULL,但是它可以有多种选项,这个参数就是锁的属性,他会影响重复加锁的行为。此属性将锁分为检错锁和递归锁/可重入锁,

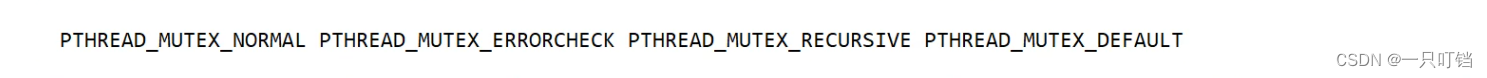
PTHREAD_MUTEX_NORMAL普通锁和默认时一样的
PTHREAD_MUTEX_ERRORCHECK检错锁,二次加锁会报错
PTHREAD_MUTEX_RECURSIVE递归锁/可重入锁,第二次加锁可以成功加锁,会增加锁的层数,不会报错,其他线程只有在锁的引用计数为0的情况下才能加锁,自己可以加多次
PTHREAD_MUTEX_DEFAULT默认锁

同步
同步:事件的执行顺序式固定的
利用mutex实现同步,完成后一个事件的线程有极大可能CPU空转一段时间,等待另一个线程完成前一个事件
条件变量
条件变量:实现事件的同步(无竞争同步),后一个事件在等待前一个线程执行事件的过程中,第二个线程不是使用while循环来等待,而是进入睡眠状态等待前一个线程事件执行完毕,当第一个线程执行完毕之后,会向第二个线程发送一个signal唤醒第二个线程运行
(1)设计一个条件,这个条件决定了本线程是否要等待
(2)如果不满足,调用wait会使本线程陷入等待
(3)此时,另外的线程会运行,直到将条件改成满足,通知`siginal阻塞的线程恢复就绪
条件变量接口

pthread_cond_t cond = PHREAD_COND_INITALIZER创建
pthread_cond_init初始化
pthread_cond_signal唤醒处于等待的线程
pthread_cond_wait
pthread_cond_timewait让线程处于等待状态,条件变量需要配合锁一起使用
pthread_cond_destory销毁一个线程
使用条件变量的一般流程
弄清楚事件的发生顺序,先事件的线程使用signal,后执行事件的线程使用wait
为什么条件变量需要配合锁一起使用,因为希望检查状态和陷入等待是一个原子操作,不希望在一个线程在检查状态符合某个if条件之后去执行某些指令之前这中间线程被抢占4然后哦改变的状态条件导致线程出现结果错误等情况
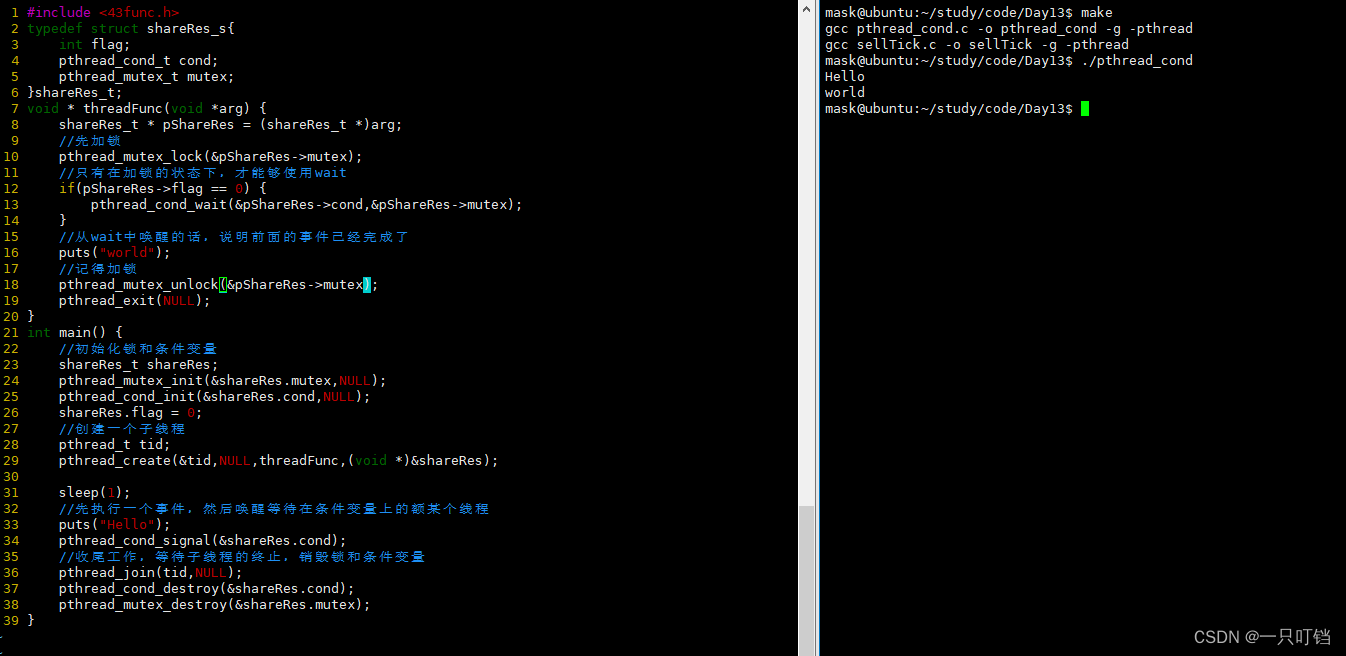
pthread_cond_wait的内部实现(很重要)
前一半的内容,描述直接运行的时候会出席那什么情况
(1)判断有没有加锁
(2)把自己加入唤醒队列
(3)解锁并陷入阻塞(原子操作)
后一半的内容,收到了signal之后
(1)是自己处于就绪状态
(2)加锁,加锁操作会一直阻塞,直到其他线程其他线程释放锁
(3)持有锁之后再继续运行
再signal之时,应该有线程已调用wait而阻塞,否则这个signal就丢了




![P1494 [国家集训队] 小 Z 的袜子](https://img-blog.csdnimg.cn/ffca3ec7b46e4fc9ba95099a6c31dce5.png)