之前是写在[Instruction-tuning(指令微调)]里的,抽出来单独讲一下。
基本原理
在做下游的任务时,我们发现GPT-3有很强大的能力,但是只要人类说的话不属于GPT-3的范式,他几乎无法理解。例如,我们说把句子A变成句子B,这种到底是机器翻译呢,还是同语言的转述,都需要让GPT-3学习到才是可以的。
InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。
InstructGPT采用基于人类反馈的强化学习(RLHF)来不断微调预训练语言模型,旨在让模型能够更好地理解人类的命令和指令含义,如生成小作文、回答知识问题和进行头脑风暴等。该方法不仅让模型学会判断哪些答案是优质的,而且可以确保生成的答案富含信息、内容丰富、对用户有帮助、无害和不包含歧视信息等多种标准。
新训练范式:RLHF
大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
RLHF是旨在人类对语言模型的指令与人类意图对齐并生成无负面影响结果的技术。该算法在强化学习框架下实现,分为奖励模型训练和生成策略优化两个阶段。[Training an agent manually via evaluative reinforcement]
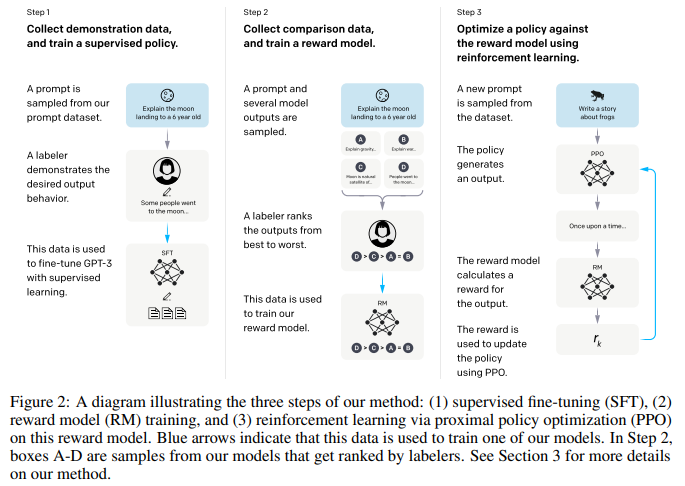
训练流程
Step1:根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT):
首先,从测试用户提交的 prompt 中随机抽取一批,然后请专业的标注人员为这些 prompt 给出高质量答案。接下来,我们使用这些<prompt,answer>数据来Fine-tune GPT-3模型,以使其初步具备理解人类prompt中所包含意图,并根据这个意图给出相对高质量回答的能力。虽然这个过程是有效的,但显然这还不足以解决所有问题:此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
这一步骤中包含了1.2万条训练demonstration数据,其包括prompt和labeled answer。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler),并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;Few-shot任务:labeler给出一个指示,以及该指示的多个查询-响应对;用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示。
这里使用余弦学习率衰减和残差 dropout 为0.2进行了16个epoch的训练,根据验证集上的RM分数进行最终的SFT模型选择。论文发现SFT模型在第1个epoch后会出现过拟合情况,然而后来实验发现训练更多的epoch会提高RM分数和人类偏好评分,尽管会出现过拟合,所以看来过拟合即使出现也不影响最终的学习结果。
Step2:收集人工标注的对比数据,训练奖励模型(Reword Model,RM):
具体地,Fine-tuning完之后,再给一个prompt让SFT模型生成出若干结果,通过人工为其排序,可以得到标注的排序pair;基于标注的排序结果(来自于Human Feedback),训练一个Reward Model。
Step3:使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型:
使用第二步训练得到的reward model和PPO算法,对第一步的模型进行 fine-tune。具体地:用生成出来的结果训练SFT,并通过强化学习的PPO方法,最大化SFT生成出排序靠前的answer。
base模型是绿色的,RL Policy是灰色的:
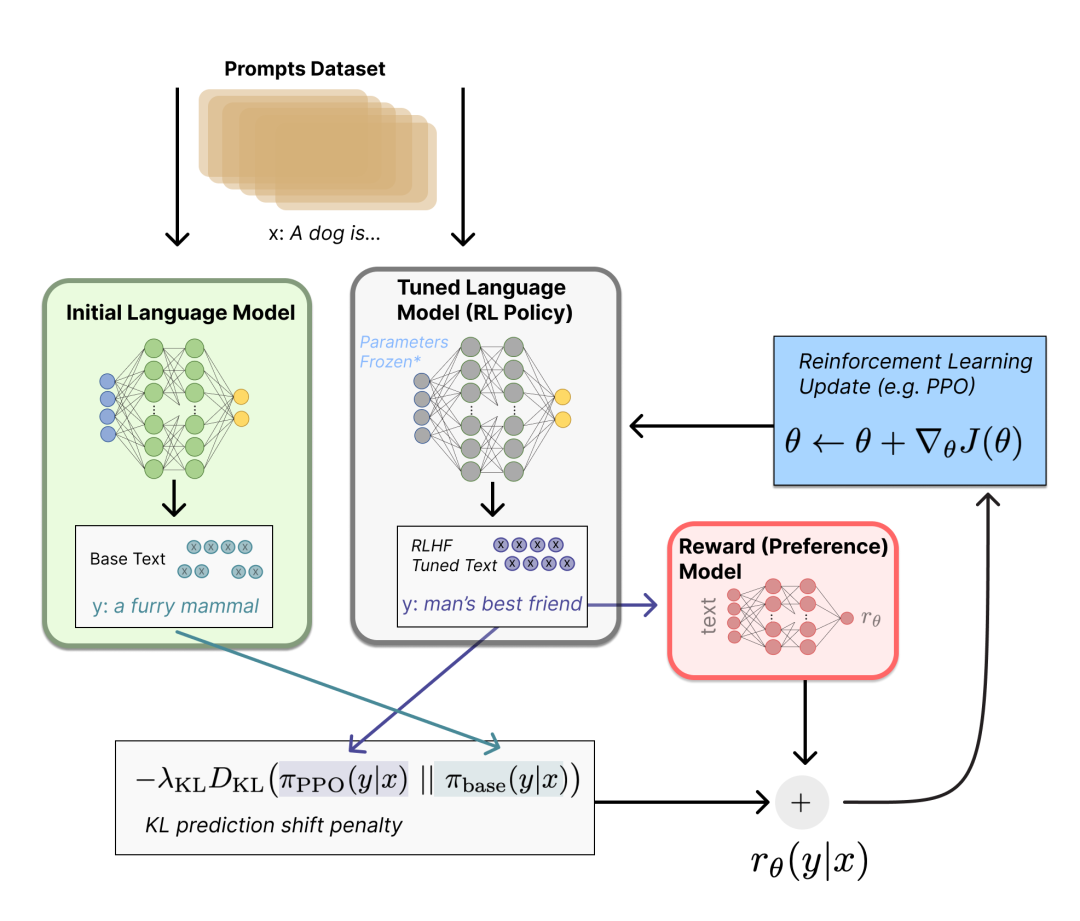
奖励模型(RM)
因为训练RM的数据是一个labeler根据生成结果排序的形式,所以它可以看做一个回归模型。RM结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。
RM模型接受输入<prompt,answer>,给出评价回答质量高低的奖励值——回报分数Score。
具体的讲,对弈每个prompt,InstructGPT/ChatGPT会随机生成K个输出( 4≤K≤9 )(可通过beam search等方法),然后它们向每个labeler成对的展示输出结果,也就是每个prompt共展示![]() 个结果,然后用户从中选择效果更好的输出。
个结果,然后用户从中选择效果更好的输出。
在训练时,对多个排序结果,两两组合,形成多个训练数据对。接下来,研究者使用这个排序结果数据进行pair-wise learning to rank训练模式,训练回报模型。对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
奖励模型的损失函数:最大化labeler更喜欢的响应和不喜欢的响应之间的差值。

另外InstructGPT/ChatGPT将每个prompt的![]() 个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。(作者也尝试了shuffle,这样很容易过拟合)
个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。(作者也尝试了shuffle,这样很容易过拟合)
PPO-ptx模型
通过第2步得到的奖励模型来指导SFT模型的继续训练。
强化学习的三要素:策略(policy)、动作空间(action space)和奖励函数(reward function)。策略就是基于该语言模型,接收 prompt 作为输入,然后输出一系列文本(或文本的概率分布);动作空间就是词表所有 token 在所有输出位置的排列组合(单个位置通常有50k左右的token候选);奖励函数(reward)则是基于训好的RM模型计算得到初始reward,再叠加上一个约束项来;观察空间则是可能的输入token序列(即prompt),为词表所有token在所有输入位置的排列组合。
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
PPO-ptx模型训练目标:

- 随着模型的更新,强化学习模型产生的数据和训练奖励模型的数据的差异会越来越大。作者的解决方案是在损失函数中加入KL惩罚项
 来确保PPO模型的输出和SFT的输出差距不会很大。
来确保PPO模型的输出和SFT的输出差距不会很大。 - 只用PPO模型进行训练的话,会导致模型在通用NLP任务上性能的大幅下降,作者的解决方案是在训练目标中加入了通用的语言模型目标
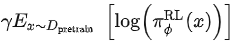 ,这个变量在论文中被叫做PPO-ptx。
,这个变量在论文中被叫做PPO-ptx。
初始化时![]() ,期望在训练πϕ时能够最大化reward的得分。
,期望在训练πϕ时能够最大化reward的得分。
为什么不用 Reward-Model 的数据直接fine-tune而用 RL
用 supervised finetune(sft)很容易做到返回“我不知道”,但是很难让模型不去编内容。或者说,在标注的时候,对于一个模型不会的问题,标注员应该要标注为“不知道”,而不是给一个回答,不然 sft 的时候相当于训练模型怎么编答案。
我们最好划出一个边界,哪些是模型不知道的,哪些是知道但是不确定的,哪些是知道的,并通过训练加强这些不同分类的分界,让模型能稳定回答它明确知道的东西,让模型不要回答它不知道的/错误的内容,这样才能保持或提升模型的 factual truthfulness;
如果我们可以有一个 reward model,他根据这个边界返回 reward 就好了,这样的话模型的训练就能集中于我们上面描述的目标,这也是为啥他们要用 RL。但是实际上 InstructGPT 里的 loss 也并不是以找到这个边界为指标,而是优化正例和负例之间的差别,这使得当前的 reward model 没有做到预期的效果,还有优化的空间。[为什么不用 Reward-Model 的数据直接 fine-tune]
关键是要有个RM模型去评估不同回答的好坏。(当然有了一个RM模型后,是否真的必须使用PPO呢?如果跑很多数据,使用第一步得到的模型loss+RM的打分差作为新loss去finetune第一步得到的模型,是不是也可以?但是有可能因为有限的Prompt,我们不能够训练无限多的Prompt,类似于强化学习中无限的环境,所以只能够通过新旧模型预测的差别来进行学习速度上的提升。)
训练细节
数据
因为InstructGPT/ChatGPT是在GPT-3基础上做的微调,而且因为涉及了人工标注,它们数据总量并不大:
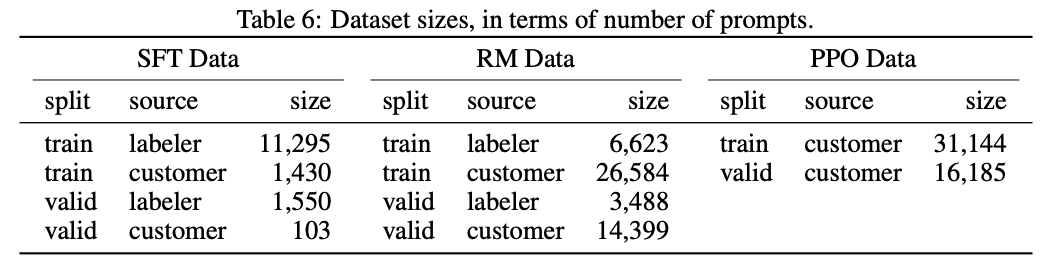
其中labeler指的是openai的标注人员,customer指gpt-3 api的用户。
论文的附录A对数据的分布进行了更详细的讨论,几个可能影响模型效果的几项:
1 数据中96%以上是英文,其它20个语种例如中文,法语,西班牙语等加起来不到4%,这可能导致InstructGPT/ChatGPT能进行其它语种的生成,但效果应该远不如英文;
2 提示种类共有9种,而且绝大多数是生成类任务,可能会导致模型有覆盖不到的任务类型;
3 40名外包员工来自美国和东南亚,分布比较集中且人数较少, InstructGPT/ChatGPT的目标是训练一个价值观正确的预训练模型,它的价值观是由这40个外包员工的价值观组合而成。而这个比较窄的分布可能会生成一些其他地区比较在意的歧视,偏见问题。
prompts示例
‘instruction-style’的user prompts示例
Illustrative user prompts from InstructGPT distribution
| Use Case | Example |
| brainstorming | What are 4 questions a user might have after reading the instruction manual for a trash compactor? {user manual} 1. |
| classification | Take the following text and rate, on a scale from 1-10, how sarcastic the person is being (1 = not at all, 10 = extremely sarcastic). Also give an explanation {text} Rating: |
| {java code} What language is the code above written in? | |
| extract | Extract all course titles from the table below: | Title | Lecturer | Room | | Calculus 101 | Smith | Hall B | | Art History | Paz | Hall A | |
| Given the following list of movie titles, write down any names of cities in the titles. {movie titles} | |
| generation | Write a creative ad for the following product to run on Facebook aimed at parents: Product: {product description} |
| Write a short story where a brown bear to the beach, makes friends with a seal, and then return home. | |
| Here’s a message to me: — {email} — Here are some bullet points for a reply: — {message} — Write a detailed reply | |
| rewrite | Translate this sentence to Spanish: <English sentence> |
| Rewrite the following text to be more light-hearted: — {very formal text}— | |
| hatZ | The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly. Human: Hello, who are you? AI: I am an AI created by OpenAI. How can I help you today? Human: I’d like to cancel my subscription. AI: |
| closed qa | Help me answer questions about the following short story: {story} What is the moral of the story? |
| Answer the following question: What shape is the earth? A) A circle B) A sphere C) An ellipse D) A plane | |
| open qa | I am a highly intelligent question answering bot. If you ask me a question that is rooted in truth, I will give you the answer. If you ask me a question that is nonsense, trickery, or has no clear answer, I will respond with "Unknown". Q: What is human life expectancy in the United States? A: Human life expectancy in the United States is 78 years. Q: Who was president of the United States in 1955? A: |
| How do you take the derivative of the sin function? | |
| summarization | Summarize this for a second-grade student: {text} |
| {news article} Tl;dr: | |
| other | start with where |
| Look up "cowboy" on Google and give me the results. |
less ‘instruction-style’式的GPT-3 user prompts示例
Illustrative user prompts from GPT-3 distribution: These are generally less ‘instruction-style’, and contain more explicit prompting. Note that there are some prompts where the user intent is unclear. 给人的感觉就是更more-shot一些,更in context一些,提示更多更明确。另外instructgpt有点命令的意思,如closed qa时,instruct要先说一下“请回答问题”,然后再提问?
| Use Case | Example |
| brainstorming | Tell me a list of topics related to: - interior design - sustainable ecosystems - fake plants |
| classification | This is a tweet sentiment classifier. {tweet} Sentiment: negative === {tweet} Sentiment: neutral === {tweet} Sentiment: |
| extract | Text: {text} Keywords: |
| generation | This is the research for an essay: === {description of research} === Write a high school essay on these topics: === |
| closed qa | When you drop a heavy stone from a tree, what happens? A. The stone falls to the ground. B: The stone stays in the tree. C: The stone floats. D: Nothing happens. Answer: |
评价
1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,尽管参数少了 100 多倍。
InstructGPT/ChatGPT的效果是非常棒的,尤其是引入了人工标注之后,让模型的“价值观”和的正确程度和人类行为模式的“真实性”上都大幅的提升。
优点
引入了人工标注之后,让模型的“价值观”和的正确程度和人类行为模式的“真实性”上都大幅的提升。
InstructGPT/ChatGPT的效果比GPT-3更加真实:这个很好理解,因为GPT-3本身就具有非常强的泛化能力和生成能力,再加上InstructGPT/ChatGPT引入了不同的labeler进行提示编写和生成结果排序,而且还是在GPT-3之上进行的微调,这使得我们在训练奖励模型时对更加真实的数据会有更高的奖励。作者也在TruthfulQA数据集上对比了它们和GPT-3的效果,实验结果表明甚至13亿小尺寸的PPO-ptx的效果也要比GPT-3要好。
InstructGPT/ChatGPT在模型的无害性上比GPT-3效果要有些许提升:原理同上。但是作者发现InstructGPT在歧视、偏见等数据集上并没有明显的提升。这是因为GPT-3本身就是一个效果非常好的模型,它生成带有有害、歧视、偏见等情况的有问题样本的概率本身就会很低。仅仅通过40个labeler采集和标注的数据很可能无法对模型在这些方面进行充分的优化,所以会带来模型效果的提升很少或者无法察觉。
缺点
InstructGPT/ChatGPT会降低模型在通用NLP任务上的效果:我们在PPO的训练的时候讨论了这点,虽然修改损失函数可以缓和,但这个问题并没有得到彻底解决。
有时候InstructGPT/ChatGPT会给出一些荒谬的输出:虽然InstructGPT/ChatGPT使用了人类反馈,但限于人力资源有限。影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用。所以很有可能受限于纠正数据的有限,或是有监督任务的误导(只考虑模型的输出,没考虑人类想要什么),导致它生成内容的不真实。就像一个学生,虽然有老师对他指导,但也不能确定学生可以学会所有知识点。
模型对指示非常敏感:这个也可以归结为labeler标注的数据量不够,因为指示是模型产生输出的唯一线索,如果指示的数量和种类训练的不充分的话,就可能会让模型存在这个问题。
模型对简单概念的过分解读:这可能是因为labeler在进行生成内容的比较时,倾向于给给长的输出内容更高的奖励。
对有害的指示可能会输出有害的答复:例如InstructGPT/ChatGPT也会对用户提出的“AI毁灭人类计划书”给出行动方案。这个是因为InstructGPT/ChatGPT假设labeler编写的指示是合理且价值观正确的,并没有对用户给出的指示做更详细的判断,从而会导致模型会对任意输入都给出答复。虽然后面的奖励模型可能会给这类输出较低的奖励值,但模型在生成文本时,不仅要考虑模型的价值观,也要考虑生成内容和指示的匹配度,有时候生成一些价值观有问题的输出也是可能的。
未来工作
人工标注的降本增效。
模型对指示的泛化/纠错等能力:指示作为模型产生输出的唯一线索,模型对他的依赖是非常严重的,如何提升模型对指示的泛化能力以及对错误指示示的纠错能力是提升模型体验的一个非常重要的工作。这不仅可以让模型能够拥有更广泛的应用场景,还可以让模型变得更“智能”。
避免通用任务性能下降。
from: -柚子皮-
ref: [InstructGPT: Training language models to follow instructions with human feedback]
[ChatGPT/InstructGPT详解 - 知乎][GPT3.5 (Instruct GPT)]
[ChatGPT 背后的“功臣”——RLHF 技术详解]
[OpenAI RLHF 的第一个项目][Fine-Tuning Language Models from Human Preferences]
[Learning to summarize from human feedback]
[Deep reinforcement learning from human preferences]