✨个人主页: 北 海
🎉所属专栏: C++修行之路
🎃操作环境: Visual Studio 2019 版本 16.11.17

文章目录
- 🌇前言
- 🏙️正文
- 1、模拟实现哈希表(闭散列)
- 1.1、存储数据结构的定义
- 1.2、查找
- 1.3、插入
- 1.4、删除
- 2、模拟实现哈希表(开散列)
- 2.1、存储节点结构的定义
- 2.2、析构函数
- 2.3、查找
- 2.4、插入
- 2.5、删除
- 2.6、桶的长度
- 3、源码
- 🌆总结
🌇前言
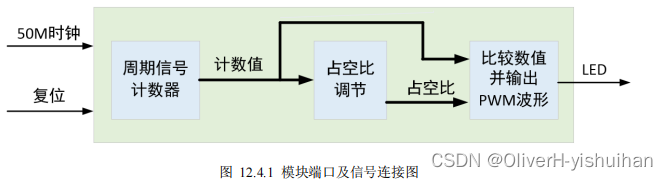
哈希表的核心思想是 映射,对数据的键值进行处理后,映射 至表中对应的位置,实现存储,利用空间换时间,哈希表的查找效率非常高,可以达到 O(1),哈希表的实现主要分为两种:闭散列 与 开散列,本文中将利用这两种方案实现哈希表

🏙️正文
1、模拟实现哈希表(闭散列)
闭散列与开散列是解决哈希冲突的两种方法
闭散列的关键在于 线性探测:当映射位置被占用时,向后移动,找到可用位置存储数据
探测后一定能找到可用的位置 [空 / 删除]
因为在闭散列中,还有一个 负载因子 用于控制是否需要扩容,确保一定有剩余空间
闭散列 存在 踩踏 问题,并不是很推荐使用
所谓的线性探测其实就是找位置,比如在停车场中,你中意的车位被占了,那只能在周围寻找可用车位(探测),找到后停好车,不过,你找的位置可能是别人中意的车位,别人停车时同样需要找车位(探测)
如此一来,本来大家都可以停在合适的位置,但因车位占用问题,局部秩序被打乱,最终导致整体秩序被打乱,而这就是 踩踏,秩序打乱后的直接影响是 寻找车位 变慢了!

1.1、存储数据结构的定义
闭散列中存储的数据至少包含两个信息:键值对、状态表示
键值对既可以是 K 也可以是 K / V,我们这里实现的是 K / V
而状态分为三种:
- 空
EMPTY初始状态 - 存在
EXIST插入数据后的状态 - 删除
DELETE删除数据后的状态
其实简单分为 [可用 / 不可用] 两种状态也行,细分出
EMPTY与DELETE是为了在进行 探测 时,提高效率
- 探测 时,如果探测到空,就不必再探测,因为后面必然不存在我们想找的数据,如果存在,这里就不会为空了
所以闭散列中的 存储数据结构 可以用一个结构体定义
//节点状态
enum Status
{//空、被占用、删除EMPTY,EXIST,DELETE
};//存储数据结构类
template<class K, class V>
struct HashData
{pair<K, V> _kv; //键值对Status _status = EMPTY; //状态
};
哈希表 的整体框架如下:
//闭散列
namespace ClosedHash
{//……//哈希表template<class K, class V>class HashTable{typedef HashData<K, V> Data;public://……private:vector<Data> _table; //数据表size_t _n; //有效数据量(用于计算负载因子)};
1.2、查找
查找 的过程其实就是 找车位 的过程,无非就是判断 当前位置的数据是否为目标值
因为在 插入 时,是 线性探测式插入 的,所以 查找 时同样进行 线性探测,一旦发现当前位置为 空,就不必向后继续探测了,因为 后面必然不存在目标数据

查找 的代码如下:
HashData<K, V>* Find(const K& key)
{//如果其中没有数据,则查找失败if (_n == 0)return nullptr;//计算哈希值size_t HashI = key % _table.size();size_t index = HashI; //保存位置,后面用来判断是否套圈了//查找(如果为空,说明其后面没有数据,不必继续探测)while (_table[index]._status != EMPTY){//判断当前位置是否有数据+是否为目标if (_table[index]._status == EXIST && _table[index]._kv.first == key)return &_table[index];//线性探测index++;index %= _table.size();//判断是否绕圈了(找了一圈还没有找到)if (index == HashI)break;}return nullptr;
}
注意:
- 需要先保存哈希值,用于判断是否被套圈(找了一圈还没找到目标值)
- 函数返回的是当前位置存储数据的指针,如果不存在,则返回空
nullptr
1.3、插入
在进行数据插入前,可以 先通过查找判断该值是否已存在,避免数据冗余
如果不存在,则可以进行插入,插入步骤如下:
- 根据键值计算出下标(哈希值)
- 线性探测,找到可用的位置 [空 / 删除]
- 插入数据,有效数据量
+1
插入部分的具体操作代码如下:
bool Insert(const pair<K, V>& kv)
{//首先查找当前 key 是否已经存在了if (Find(kv.first) != nullptr)return false;//扩容问题//……//获取下标(哈希值)size_t HashI = kv.first % _table.size();int i = 0; //探测时的权值,方便改为二次探测//如果为存在,进行探测while (_table[HashI]._status == EXIST){HashI += i; //向后移动HashI %= _table.size();i++;}//找到空位置了,进行插入_table[HashI]._kv = kv;_table[HashI]._status = EXIST;_n++; //插入一个数据return true;
}
如果想降低踩踏发生的概率,可以将 线性探测 改为 二次探测
HashI += (i * i); //二次探测
以上就是 插入操作 的具体实现,此时面临着一个棘手的问题:扩容问题
当数据 第一次插入 或 负载因子达到临界值 时,需要进行 扩容(因为 vector<Data> _table 一开始为空,所以第一次插入也要扩容)
当空间扩容后,容量发生了改变,这也就意味着 数据与下标 的映射关系也发生了改变,需要更新数据,即重新进行线性探测
扩容可分为 传统写法 和 现代写法
传统写法
bool Insert(const pair<K, V>& kv)
{//查找//……//考虑扩容问题(存储数据超过容量的 70% 就扩容)if (_table.size() == 0 || _n * 10 / _table.size() == 7){size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;vector<Data> newTable(newSize); //创建新表//将老表中的数据,挪动至新表(需要重新建立映射关系)for (auto& e : _table){//获取下标(哈希值)size_t HashI = e._kv.first % newTable.size();int i = 0; //探测时的权值,方便改为二次探测//如果为空,进行探测while (newTable[HashI]._status == EXIST){HashI += i; //向后移动HashI %= newTable.size();i++;}//找到空位置了,进行插入newTable[HashI]._kv = e._kv;newTable[HashI]._status = EXIST;_n++; //插入一个数据}//交换新表、旧表(成本不大)_table.swap(newTable);}//插入//……
}
传统写法思路:创建一个容量足够的 新表,将 原表 中的数据映射至 新表 中,映射完成后,交换 新表 和 原表,目的是为了更新当前哈希表对象中的 表
关于
平衡因子的控制
根据别人的试验结果,哈希表中的存储的有效数据量超过哈希表容器的70%时,推荐进行扩容
假设容量为M,存储的有效数据量为N,两者比率N / M == 0.7时进行扩容
因为我们这里的容量和数据量都是整数,所以在等式两边*10,可得N * 10 / M == 7
传统写法比较繁琐,下面就来看看 现代写法
现代写法
bool Insert(const pair<K, V>& kv)
{//查找//……//现代写法:调用 Insertif (_table.size() == 0 || _n * 10 / _table.size() == 7){size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;HashTable<K, V> newHashTable; //创建新哈希表newHashTable._table.resize(newSize); //直接扩容,后续调用 Insert 插入数据时,空间是绝对够的//将老表中的数据,插入至新表(建立映射关系的工作交给 Insert)for (auto& e : _table)newHashTable.Insert(e._kv);//交换新表、旧表(成本不大)_table.swap(newHashTable._table);//细节:需不需要交换 _n ?}//插入//……
}
其实 传统写法 中的 插入部分逻辑 与 Insert 中的 插入操作 重复了,因此我们可以借助现代思想(白嫖),创建一个 容量足够的哈希表,将 原表 中的数据遍历插入 新的哈希表 中,插入的过程调用 Insert,代码极其间接,并且不容易出错
细节:需不需将当前对象中的 有效数据量 _n 进行更新?
- 答案是不需要,往新的哈希表中插入
_n个数据,意味着无论是 新的哈希表 还是当前对象,它们的有效数据量都是一致的,因此不需要更新
可以对 查找 和 插入 这两个功能进行测试
//测试
void TestCloseHash1()
{int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(15, 15));if (ht.Find(13)){cout << "13在" << endl;}else{cout << "13不在" << endl;}
}

数据在 哈希表 的存储关系如下:

1.4、删除
删除 操作就十分简单了,获取待删除数据,将其中的状态改为 删除 DELETE 即可,不必清空数据,只要访问不到就行了,当然,有效数据量-1
此时可以调用 查找 Find,如果待 删除 数据存在,可以得到指向它的指针,进行状态修改即可,如果不存在,就不进行操作,返回 false
bool Erase(const K& key)
{//查找目标是否存在HashData<K, V>* pret = Find(key);if (pret != nullptr){//进行删除,更改状态为删除,数量-1即可pret->_status = DELETE;_n--;return true;}return false;
}
测试 删除 功能
void TestCloseHash2()
{int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(15, 15));if (ht.Find(13)){cout << "13在" << endl;}else{cout << "13不在" << endl;}ht.Erase(13);if (ht.Find(13)){cout << "13在" << endl;}else{cout << "13不在" << endl;}
}

哈希表(闭散列)实战价值不大,因此只做简单了解即可,真正重点在于 开散列
2、模拟实现哈希表(开散列)
哈希表(开散列) 又称为 哈希桶
因为它的下面挂着一个 单链表,形似一个 桶
哈希表(开散列) 就比较有 研究价值 了,因为它在解决 哈希冲突 的同时,不会产生 踩踏 问题,是一种比较灵活且强大的解决方案

2.1、存储节点结构的定义
哈希桶 中需要维护一个 单链表,因此需要一个 _next 指针指向下一个节点
//节点类
template<class K, class V>
struct HashNode
{HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}pair<K, V> _kv;HashNode<K, V>* _next; //指向下一个节点
};
因为引入了 单链表,所以 哈希桶 中 表 的存储类型也变成了 节点指针
//哈希表(哈希桶)
template<class K, class V>
class HashTable
{typedef HashNode<K, V> Node;//……private://哈希桶中不需要平衡因子,节点存储满后,进行扩容就行了vector<Node*> _table;size_t _n = 0; //有效数据量
};
注意: 哈希桶中不需要状态表示,因为可以直接插入
2.2、析构函数
因为有 单链表,所以在对象析构时,需要手动遍历其中的节点,将其释放,避免 内存泄漏
~HashTable()
{//因为哈希桶中涉及了我们直接写的单链表,因此需要手动释放节点//顺便把 vector 中的节点释放了for (auto& pnode : _table){Node* cur = pnode;while (cur){//保存下一个节点Node* next = cur->_next;//释放当前节点delete cur;cur = next;}pnode = nullptr;}
}
为什么 哈希表(闭散列) 中不需要写 析构函数?
- 因为在闭散列中,表中存储的数据不涉及自定义类型的动态内存管理,并且
vector在对象调用默认析构时,会被调用其析构,释放其中的内存
2.3、查找
哈希桶 在查找时,只需要先定位至具体的位置,然后遍历其中的 桶 中是否存在 目标 即可
//查找
Node* Find(const K& key)
{if (_table.size() == 0)return nullptr;//计算哈希值size_t HashI = key % _table.size();//在哈希值对应的桶里查找是否存在目标值Node* cur = _table[HashI];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;
}
本质上就是单链表的遍历~
2.4、插入
在进行数据插入时,既可以尾插,也可以头插,因为桶中的存储顺序没有要求
为了操作简单,我们选择 头插
同样的,哈希桶在扩容时,也有传统写法和现代写法,这里采用 传统写法
//插入
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first) != nullptr)return false; //冗余//判断扩容if (_n == _table.size()){//传统写法size_t newSize = _table.size() == 0 ? 5 : _table.size() * 2;vector<Node*> newTable(newSize); //新的表for (auto& cur : _table){while (cur){size_t HashI = cur->_kv.first % newSize; //计算新的哈希值Node* next = cur->_next;//节点头插至新表(回收节点)cur->_next = newTable[HashI];newTable[HashI] = cur;cur = next;}}_table.swap(newTable);现代写法//size_t newSize = _table.size() == 0 ? 5 : _table.size() * 2;//HashTable<K, V> newHashTable;//newHashTable._table.resize(newSize); //直接就扩容了//for (auto& cur : _table)//{// while (cur)// {// newHashTable.Insert(cur->_kv);// cur = cur->_next;// }//}//_table.swap(newHashTable._table);}//插入size_t HashI = kv.first % _table.size(); //计算哈希值//单链表头插Node* cur = _table[HashI]; //原来的头节点_table[HashI] = new Node(kv); //创建新的头_table[HashI]->_next = cur; //连接_n++;return true;
}
这里的 传统写法 有一个很巧妙的地方:节点回收
既然 旧表 中节点不用了,那我可以直接把其中的节点 转移链接 至 新表 中,这样可以提高效率,且代码十分优雅
简单对 插入(含查找) 功能进行测试
//测试
void TestOpenHash1()
{int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(15, 15));ht.Insert(make_pair(25, 25));ht.Insert(make_pair(35, 35));ht.Insert(make_pair(45, 45));cout << ht.Find(5) << endl;cout << ht.Find(50) << endl;
}

注意: 进行单链表链接操作时,要注意野指针问题
2.5、删除
哈希桶 的删除本质上就是 单链表 的删除,不过先要根据 哈希值 获取对应的 头节点
bool Erase(const K& key)
{//这里直接查找,因为需要保存上一个节点信息(单链表的删除)size_t HashI = key % _table.size();Node* prev = nullptr;Node* cur = _table[HashI];//单链表的删除while (cur){Node* next = cur->_next;if (cur->_kv.first == key){//删除if (prev == nullptr){//头删_table[HashI] = next;}elseprev->_next = next;delete cur;_n--;return true;}else{prev = cur;cur = next;}}return false;
}
测试 删除 功能
void TestOpenHash2()
{int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}cout << ht.Find(5) << endl;ht.Erase(12);ht.Erase(5);ht.Erase(33);cout << ht.Find(5) << endl;
}

注意: 单链表删除时,需要考虑删除的是头节点的情况
2.6、桶的长度
哈希桶 中的长度不会太长,因为存在 扩容 机制,并且 每次扩容后,映射关系会进行更新,桶的整体高度会降低
可以插入大量数据,查看 哈希桶 的最大高度
class HashTable
{//……size_t MaxBucketSize(){size_t max = 0;for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];size_t size = 0;while (cur){++size;cur = cur->_next;}if (size > max)max = size;}return max;}//……
};void TestOpenHash3()
{//插入大量随机数,查看最长的桶长度srand((size_t)time(nullptr));HashTable<int, int> ht;int n = 1000000;for (int i = 0; i < n; i++){int val = rand() + i;ht.Insert(make_pair(val, val));}//查看最长的长度cout << ht.MaxBucketSize() << endl;
}

插入约 100w 数据,哈希桶 的最大高度不过为 2
因此,哈希桶可以做到常数级别的查找速度,并且不存在 踩踏 问题
其实库中的 unordered_set 和 unordered_map 就是使用 哈希桶 封装实现的,就像 红黑树 封装 set 和 map 那样
不过我们当前的 哈希桶 仍然存在不少问题且不够完善,在下一篇文章中,我们首先对其进行完善,然后直接利用一个 哈希桶 封装实现 unordered_set 与 unordered_map
3、源码
本文中涉及的所有代码位于下面这个 Gitee 仓库中
《哈希表的模拟实现》

🌆总结
以上就是本次关于 C++【哈希表的模拟实现】的全部内容了,在本文中,我们主要对哈希表的两种实现方式:闭散列与开散列(哈希桶)进行了简单模拟实现,学习了 线性探测 和 单链表 这两种哈希冲突的解决方法,之前觉得没什么用的单链表,在此处闪闪发光

相关文章推荐
C++ 进阶知识
C++【初识哈希】
C++【一棵红黑树封装 set 和 map】
C++【红黑树】
C++【AVL树】
C++【set 和 map 学习及使用】
C++【二叉搜索树】
C++【多态】
C++【继承】