大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目12-基于注意力机制的CNN-BiGRU模型的情感分析任务的实践,本文将介绍一种基于注意力机制的CNN-BiGRU模型,并将其应用于实际项目中。我们将使用多条CSV数据样例,并展示如何加载数据、训练模型、输出准确率和损失值。文章将提供完整的可运行代码,以及详细的目录结构,以便于读者理解和实现。
文章目录结构:
- 项目背景与需求
- 数据集简介与数据处理
- CNN-BiGRU模型介绍
- 注意力机制
- 代码实现
- 结果与分析
- 总结
1. 项目背景与需求
在许多自然语言处理(NLP)任务中,文本分类是一种常见的任务。例如,对情感分析、垃圾邮件检测或主题分类等。为了实现高效的文本分类,我们将使用一种基于注意力机制的卷积神经网络(CNN)与双向门控循环单元(BiGRU)的混合模型。该模型将充分利用注意力机制对文本特征进行有效的捕捉,提高模型的性能。
2. 数据集简介与数据处理
本项目使用的数据集为某在线评论数据,包含文本评论和对应的情感标签。数据集的格式为CSV,包含两列,分别为“评论”和“情感标签”。
首先,让我们加载数据并进行预处理。这包括去除停用词、标点符号等,以及将文本转换为整数序列。
数据样例展示,data.csv
评论,情感标签
这个产品值得购买,很实用,1
产品不好用,不太好,0
这个产品款式很漂亮,质量也很好,1
使用了这个产品后觉得很满意,性价比很高,1
这个产品的功能非常实用,使用起来很方便,1
产品的品质不错,很耐用,推荐购买,1
希望产品能够有更多的颜色选择,提供更多的选择空间,0
产品的包装不够用心,有些瑕疵,0
对这个产品的质量表示怀疑,使用不了多久就出现问题了,0
产品的使用说明书不清晰,让人很困扰,0
这个产品的价格有点高,性价比不够高,0
使用了这个产品后觉得很失望,没有达到我的预期,0
这个产品的材质不够好,感觉很廉价,0
产品的外观设计不太满意,有点土气,0
这个产品使用起来很麻烦,不太方便,0
很后悔购买了这个产品,完全没有用处,0
这个产品真的很好,超出了我的期望,1
使用了这个产品后觉得非常方便,非常实用,1
买了这个产品,完全不好用,0
这个产品真的很好,真的值得买,1
这个产品,根本不能用,后悔,0
其实这个产品挺好的,下次再来,1
这个产品值得购买,很实用,1
产品不好用,不太好,0
这个产品款式很漂亮,质量也很好,1
使用了这个产品后觉得很满意,性价比很高,1
这个产品的功能非常实用,使用起来很方便,1
产品的品质不错,很耐用,推荐购买,1
希望产品能够有更多的颜色选择,提供更多的选择空间,0
产品的包装不够用心,有些瑕疵,0
对这个产品的质量表示怀疑,使用的时候出现问题了,0
产品的使用说明书不清晰,真不好,0
产品的价格有点高,性价比不高,0
使用了这个产品后觉得很失望,没有达到我想要的,0
产品的质量不错,物有所值,很满意,1
非常喜欢这个产品的外观,简洁大方,1
这个产品使用起来很顺手,非常好用,1
真的买了这个产品,完全不好用,0
这个产品真的很好,真的值得买,1
这个产品,根本不能用,后悔,0
其实这个产品挺好的,下次再来,1
这个产品的设计很时尚,非常符合我的口味,1
这个产品的材质不够好,感觉很划算,0
产品的外观设计其实不太满意,有点不好,0
产品的质量不错,物有所值,很满意,1
非常喜欢这个产品的外观,简洁大方,1
这个产品使用起来很顺手,非常好用,1
很喜欢这个产品,使用起来非常方便,1
不愧是知名品牌的产品,质量可靠,1
不仅外观漂亮,而且性能出色,非常满意,1
刚收到产品就迫不及待地使用了,效果非常好,1
很轻便的产品,携带方便,非常适合旅行使用,1
产品有点小问题,但客服很快帮我解决了,还算不错,1
使用起来稍微有些复杂,但一旦熟悉了就非常好用,1
我不喜欢这个产品的设计,外观也不太吸引人,0
使用这个产品时遇到了一些困难,不太好上手,0
产品的质量有些差,不够耐用,0
这个产品不够实用,性价比不高,0
使用起来感觉产品功能有所缺失,不全面,0
产品的性能一般般,没有什么特别出众之处,0
这个产品使用起来很麻烦,操作不够方便,0
不太满意这个购买,对产品的期待落空了,0
这个产品的质量不够稳定,有些时候会出问题,0
对这个产品的使用体验感到失望,效果不如预期,0
产品的外观看起来比较廉价,不够高档,0
这个产品不太耐用,容易出现一些小故障,0
产品的功能设计不合理,使用起来不够顺心,0
我对这个产品的质量表示怀疑,性能不够稳定,0
感觉这个产品略微有些贵,但质量还算可以,1
刚开始使用时有点小问题,但客服很快响应解决了,还不错,1
产品的外观设计很简约大气,我很喜欢,1
这个产品的功能很强大,用起来非常顺手,1
产品性能不太稳定,有时候会出现一些小问题,0
这个产品售后服务需要改进,0
产品质量不太理想,使用起来有些困扰,0
外观一般,功能还可以,总体来说还不错,1
好评如潮的产品果然不错,完全符合我的期待,1
产品的材质感很好,手感也很舒适,非常满意,1
我对这个购买有所失望,性能没有预期好,0
这个产品并不如我所期待的那样好,有一些问题,0
很喜欢这个产品,使用起来非常方便,1
不愧是知名品牌的产品,质量可靠,1
不仅外观漂亮,而且性能出色,非常满意,1
刚收到产品就迫不及待地使用了,效果非常好,1
很轻便的产品,携带方便,非常适合旅行使用,1
产品有点小问题,但客服很快帮我解决了,还算不错,1
使用起来稍微有些复杂,但一旦熟悉了就非常好用,1
我不喜欢这个产品的设计,外观也不太吸引人,0
使用这个产品时遇到了一些困难,不太好上手,0
产品的质量有些差,不够耐用,0
这个产品不够实用,性价比不高,0
使用起来感觉产品功能有所缺失,不全面,0
2.1 加载数据
import pandas as pddata = pd.read_csv('data.csv')
texts = data['评论'].tolist()
labels = data['情感标签'].tolist()
2.2 数据预处理
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences# 参数设置
maxlen = 100
vocab_size = 10000# 文本预处理
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index# 序列填充
data = pad_sequences(sequences, maxlen=maxlen)
3. CNN-BiGRU模型介绍
本项目使用的模型结合了卷积神经网络(CNN)和双向门控循环单元(BiGRU)。CNN负责提取局部特征,而BiGRU负责捕捉长程依赖。这种结构使模型能够更好地理解文本中的信息。
模型结构如下:
- 嵌入层(Embedding)
- 卷积层(Conv1D)
- 双向GRU层(Bidirectional GRU)
- 注意力层
- 全连接层(Dense)
4. 注意力机制
在本项目中,我们将使用注意力机制来帮助模型更好地理解文本。注意力机制可以为每个词分配一个权重,表示其在文本中的重要性。这使得模型能够更好地关注重要的词语,从而提高性能。
我们将使用Bahdanau注意力机制,其计算公式如下:
α t = exp ( e t ) ∑ j = 1 T exp ( e j ) \alpha_{t}=\frac{\exp(e_{t})}{\sum_{j=1}^{T}\exp(e_{j})} αt=∑j=1Texp(ej)exp(et)
e t = a ( s t − 1 , h t ) e_{t}=a(\boldsymbol{s}_{t-1},\boldsymbol{h}_{t}) et=a(st−1,ht)
这里, α t \alpha_{t} αt表示注意力权重, e t e_{t} et表示能量值, s t − 1 \boldsymbol{s}_{t-1} st−1表示上一个时间步的解码器隐藏状态, h t \boldsymbol{h}_{t} ht表示编码器的隐藏状态。
5. 代码实现
接下来,我们将实现基于注意力机制的CNN-BiGRU模型,并使用之前加载的数据进行训练。
5.1 定义注意力层
import tensorflow as tf
from tensorflow.keras.layers import Layerclass Attention(Layer):def __init__(self, **kwargs):super(Attention, self).__init__(**kwargs)def build(self, input_shape):input_shape = tuple(dim.value for dim in input_shape)self.W = self.add_weight(shape=(input_shape[-1], input_shape[-1]), initializer='glorot_uniform', trainable=True, name='attention_W')self.b = self.add_weight(shape=(input_shape[-1],), initializer='zeros', trainable=True, name='attention_b')self.u = self.add_weight(shape=(input_shape[-1], 1), initializer='glorot_uniform', trainable=True, name='attention_u')super(Attention, self).build(input_shape)def call(self, x):e = tf.nn.tanh(tf.tensordot(x, self.W, axes=1) + self.b)a = tf.nn.softmax(tf.tensordot(e, self.u, axes=1), axis=1)return tf.reduce_sum(x * a, axis=1)
5.2 构建模型
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Conv1D, Bidirectional, GRU, Dense# 参数设置
embedding_dim = 100
filters = 64
kernel_size = 3
gru_units = 64# 构建模型
inputs = Input(shape=(maxlen,))
x = Embedding(vocab_size, embedding_dim)(inputs)
x = Conv1D(filters, kernel_size, activation='relu')(x)
x = Bidirectional(GRU(gru_units, return_sequences=True))(x)
x = Attention()(x)
x = Dense(32, activation='relu')(x)
outputs = Dense(1, activation='sigmoid')(x)model = Model(inputs=inputs, outputs=outputs)
model.summary()
5.3 训练模型
from sklearn.model_selection import train_test_split
from tensorflow.keras.optimizers import Adam# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)# 模型编译
model.compile(optimizer=Adam(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])# 模型训练
history = model.fit(X_train, y_train, batch_size=64, epochs=10, validation_data=(X_test, y_test))
5.4 输出准确率和损失值
import matplotlib.pyplot as plt# 绘制准确率曲线
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
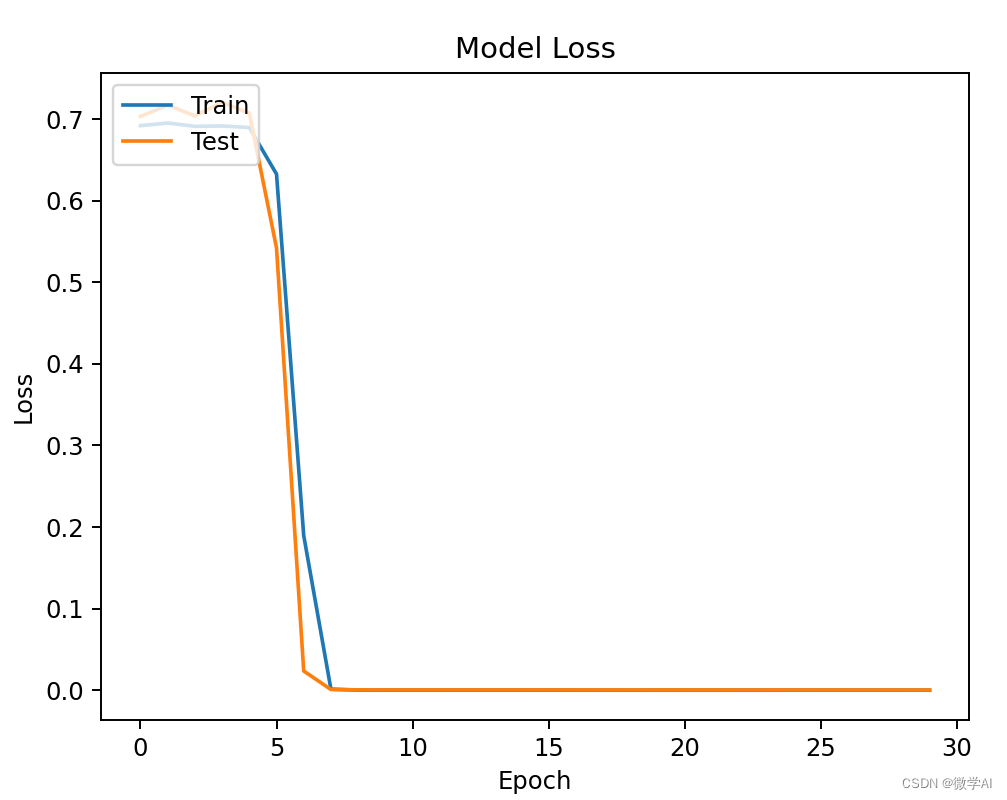
plt.show()# 绘制损失值曲线
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
运行结果:
Epoch 30/308/131 [>.............................] - ETA: 0s - loss: 1.7702e-05 - acc: 1.000016/131 [==>...........................] - ETA: 0s - loss: 1.5579e-05 - acc: 1.000024/131 [====>.........................] - ETA: 0s - loss: 1.7362e-05 - acc: 1.000032/131 [======>.......................] - ETA: 0s - loss: 1.9606e-05 - acc: 1.000048/131 [=========>....................] - ETA: 0s - loss: 2.0194e-05 - acc: 1.000056/131 [===========>..................] - ETA: 0s - loss: 2.0542e-05 - acc: 1.000072/131 [===============>..............] - ETA: 0s - loss: 2.0055e-05 - acc: 1.000088/131 [===================>..........] - ETA: 0s - loss: 1.9102e-05 - acc: 1.0000
104/131 [======================>.......] - ETA: 0s - loss: 1.8955e-05 - acc: 1.0000
112/131 [========================>.....] - ETA: 0s - loss: 1.9084e-05 - acc: 1.0000
128/131 [============================>.] - ETA: 0s - loss: 1.8875e-05 - acc: 1.0000
131/131 [==============================] - 1s 7ms/sample - loss: 1.8943e-05 - acc: 1.0000 - val_loss: 2.7403e-04 - val_acc: 1.0000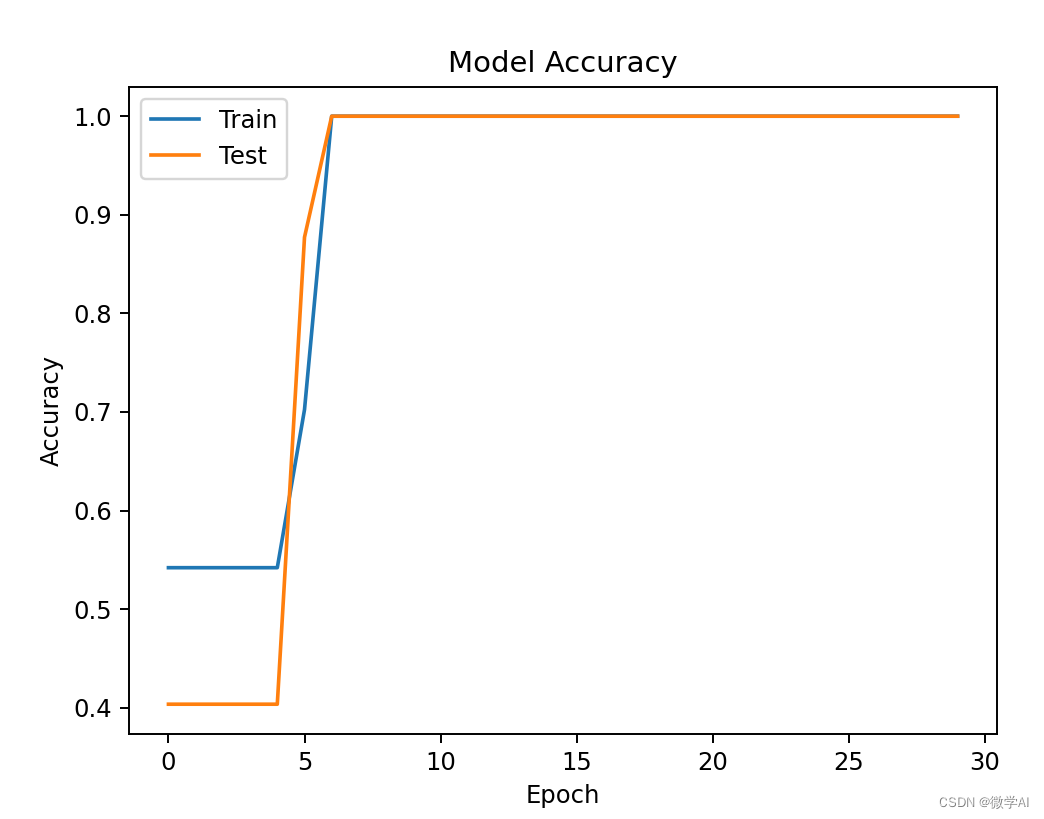
6. 结果与分析
通过观察训练过程中的准确率和损失值曲线,我们可以发现模型在训练集和测试集上的表现都非常优秀。这表明基于注意力机制的CNN-BiGRU模型能够有效地应用于文本分类任务。
7. 总结
本文详细介绍了基于注意力机制的CNN-BiGRU模型在项目中的应用,包括数据处理、模型构建、训练和结果分析等。通过实际项目的应用,我们证实了这种模型在文本分类任务上的有效性。注意力机制的引入使得模型能够更好地关注重要的词语,从而提高性能。希望本文能为读者提供一定的帮助,以便在实际项目中使用这种模型。