from sklearn.cluster import KMeans
model = KMeans(n_clusters=)...
model.labels_
6.3 降维
PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=)
x = pca(X)
指定n_components为降维后的维度
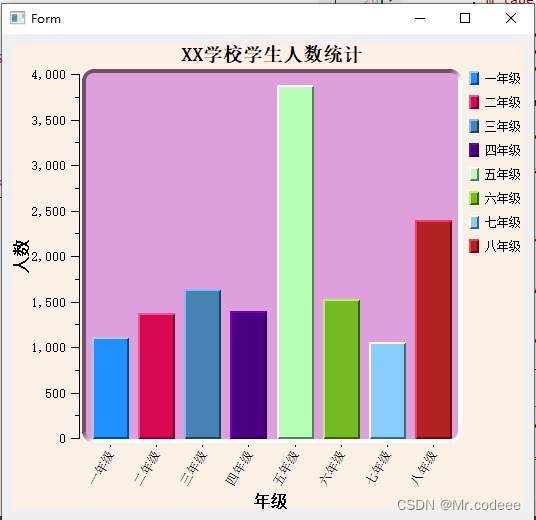
3D图
from mpl_toolkits.mplot3d import Axes3D
6.4 机器学习步骤
① 导入数据 ② 数据概览 ③ 数据可视化 ④ 模型评估 ⑤ 实施预测
6.5 图像
概念
含义
二值图像
0,1。1个二进制位
灰度图像
0~255。8位无符号整数, convert(‘L’)
通道分割
split
通道合并
merge
轮廓提取
filter
七、Tensorflow
会使用keras搭建序列网络、卷积网络。ppt的图像分类例子会独立编写。
7.1 评价指标-分类
名称
含义
计算公式
混淆矩阵
预测结果与真是结果组成矩阵
TP预测为正实际为正,TN预测为副实际为副,FN,预测为负实际为正,FP预测为正实际为负
精确率(metrics.precison_score)
预测为正中实际为正比例
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
召回率(recall_score)
实际为正的样本中预测为正的样本
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
F1-Score(f1_score)
2 ∗ P ∗ R P + R \frac{2*P*R}{P+R} P+R2∗P∗R
准确率(accuracy_score)
预测正确的样本比例
T P + T N T P + T N + F P + F N \frac{TP+TN}{TP+TN+FP+FN} TP+TN+FP+FNTP+TN
7.2 评价指标-回归
名称
含义
计算公式
平均绝对误差(metrics.mean_absolute_error)
MAE
1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \frac{1}{n}\sum\limits_{i=1}^{n} \lvert y_i - \hat y_i \rvert n1i=1∑n∣yi−y^i∣
均方误差(mean_squared_error)
MSE
1 n ∑ i = 1 n ( y i − y ^ i ) 2 \frac{1}{n} \sum\limits_{i=1}^{n}(y_i - \hat y_i)^2 n1i=1∑n(yi−y^i)2
决定系数(r2_score)
R 2 R^2 R2
R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ i ) 2 R^2 = 1 - \frac{\sum\limits_{i=1}^{n}(y_i-\hat y_i)^2}{\sum\limits_{i=1}^{n}(y_i - \bar y_i)^2} R2=1−i=1∑n(yi−yˉi)2i=1∑n(yi−y^i)2,其中 y ˉ = 1 n ∑ i = 1 n y i \bar y = \frac{1}{n} \sum\limits_{i=1}^{n}y_i yˉ=n1i=1∑nyi
7.3 激活函数
函数名
表达式
备注
Sigmoid
f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
值域0~1
tanh
f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=ex+e−xex−e−x
分析
根据平衡二叉树的定义,只需要满足:1、根节点两个子树的高度差不超过1;2、左右子树都为平衡二叉树
代码
public class BalancedBinaryTree {public class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(){}TreeNode(int va…
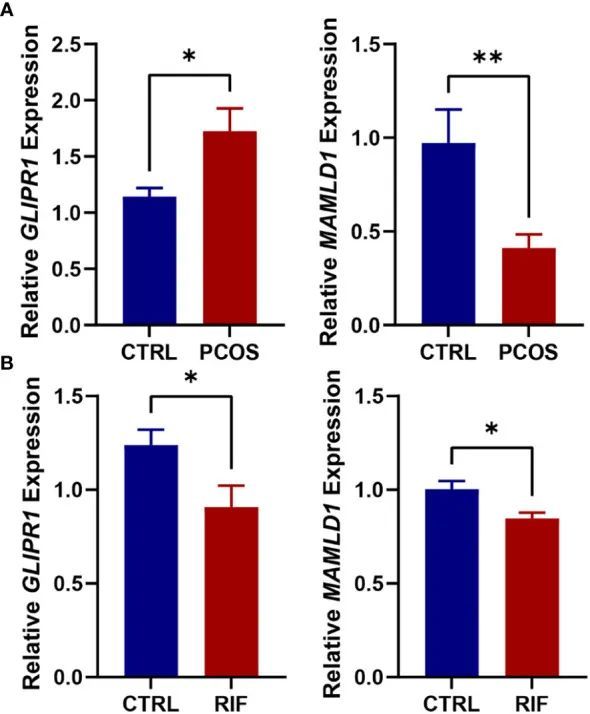
今天给同学们分享一篇双疾病WGCNA多机器学习的生信文章“Shared diagnostic genes and potential mechanism between PCOS and recurrent implantation failure revealed by integrated transcriptomic analysis and machine learning”,这篇文章于2023年5月16日发表…





![[java/力扣110]平衡二叉树——优化前后的两种方法](https://img-blog.csdnimg.cn/ac5f043c9c894051bb5062d8f5c8ee8d.png)