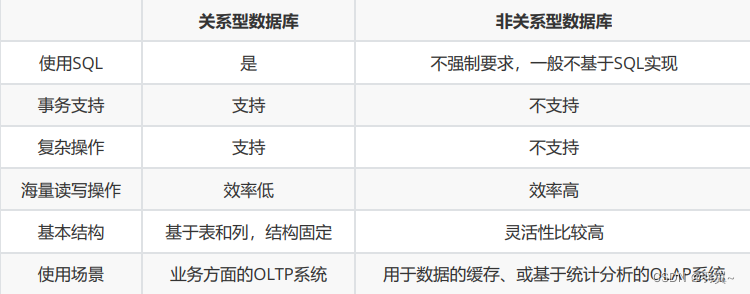
pip install websocket-client废话不多说数据展示:


代码:
创建工作簿和工作表
# 创建工作簿和工作表
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = '实时热榜'设置标题行
titles = ["序号", "平台", "热榜描述", "热度", "访问地址"]
for col, title in enumerate(titles, 1):sheet.cell(row=1, column=col).value = title数据获取核心代码:
def get_html(url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}resp = requests.get(url, headers=headers)return resp.textdef get_data(html):soup = BeautifulSoup(html, 'html.parser')nodes = soup.find_all('div', class_='cc-cd')return nodesurl = 'https://tophub.today'
html = get_html(url)
data = get_data(html)将数据保存到xlsx
for node in data:source = node.find('div', class_='cc-cd-lb').text.strip()print(source)if source == '实时榜中榜':# 终止循环continuemessages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')print(messages)for message in messages:rank = message.find('span', class_='s').text.strip()content = message.find('span', class_='t').text.strip()content1 = message.find('span', class_='e').text.strip()url = message["href"]sheet.append([rank, source, content, content1, url])# 保存数据到Excel文件
workbook.save('hot.xlsx')
workbook.close()完整code:
import requests
from bs4 import BeautifulSoup
import openpyxl# 创建工作簿和工作表
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = '实时热榜'# 设置标题行
titles = ["序号", "平台", "热榜描述", "热度", "访问地址"]
for col, title in enumerate(titles, 1):sheet.cell(row=1, column=col).value = titledef get_html(url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}resp = requests.get(url, headers=headers)return resp.textdef get_data(html):soup = BeautifulSoup(html, 'html.parser')nodes = soup.find_all('div', class_='cc-cd')return nodesurl = 'https://tophub.today'
html = get_html(url)
data = get_data(html)
# print(data)for node in data:source = node.find('div', class_='cc-cd-lb').text.strip()print(source)if source == '实时榜中榜':# 终止循环continuemessages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')print(messages)for message in messages:rank = message.find('span', class_='s').text.strip()content = message.find('span', class_='t').text.strip()content1 = message.find('span', class_='e').text.strip()url = message["href"]sheet.append([rank, source, content, content1, url])# 保存数据到Excel文件
workbook.save('hot.xlsx')
workbook.close()
关注公众号「码农园区」,获取多个项目源码及各大厂学习面试资源