点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2306.11987.pdf
项目地址:https://github.com/xijiu9/Train_Transformers_with_INT4
计算机视觉研究院专栏
Column of Computer Vision Institute
将激活、权重和梯度量化为4-bit有望加速神经网络训练。然而,现有的4-bit训练方法需要定制的数字格式,这是当代硬件所不支持的。

01
概要简介
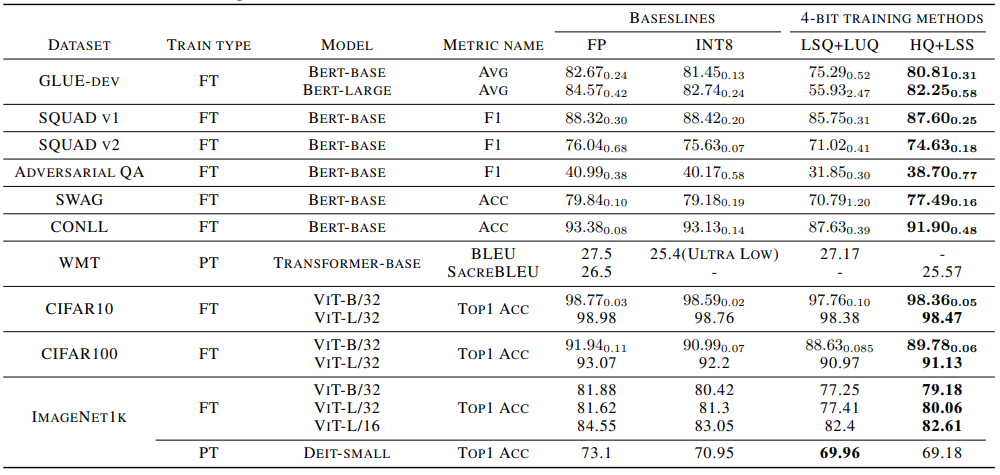
在这项工作中,研究者提出了一种用INT4算法实现所有矩阵乘法的transformers的训练方法。超低INT4精度的训练极具挑战性。为了实现这一点,我们仔细分析了transformer中激活和梯度的具体结构,为它们提出了专用的量化器。对于前向传播,我们识别了异常值的挑战,并提出了一种Hadamard量化器来抑制异常值。对于反向传播,我们通过提出比特分割和利用分数采样技术来精确量化梯度,从而利用梯度的结构稀疏性。我们的算法在包括自然语言理解、机器翻译和图像分类在内的广泛任务中实现了具有竞争力的准确性。
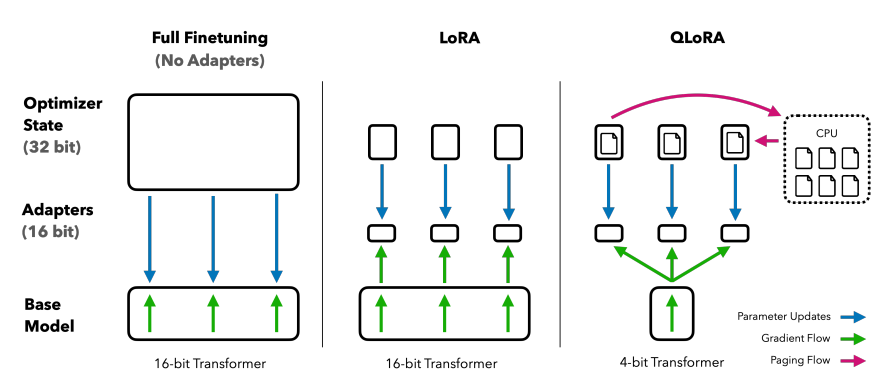
【QLoRA本身讲的是模型本身用4bit加载,训练时把数值反量化到bf16后进行训练,利用LoRA[2]可以锁定原模型参数不参与训练,只训练少量LoRA参数的特性使得训练所需的显存大大减少。例如33B的LLaMA模型经过这种方式可以在24 GB的显卡上训练,也就是说单卡4090、3090都可以实现,大大降低了微调的门槛】QLORA: Efficient Finetuning of Quantized LLMs
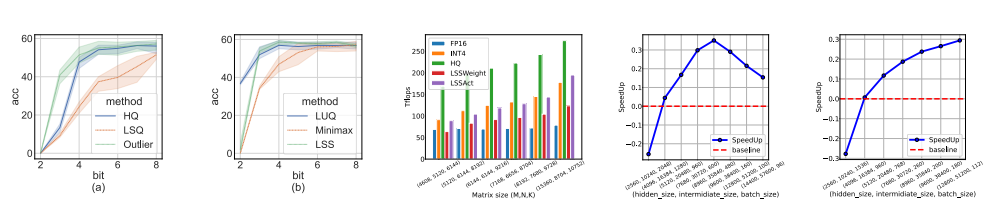
与以前的4-bit训练方法不同,我们的算法可以在当前一代的GPU上实现。我们的原型线性算子实现速度是FP16的2.2倍,训练速度提高了35.1%。

02
背景介绍
训练神经网络在计算上要求很高。低精度算术训练(也称为全量化训练或FQT)有望提高计算和记忆效率。FQT方法在原来的全精度计算图中添加了一些量化器和反量化器,并用廉价的低精度运算取代了昂贵的浮点运算。FQT的研究旨在降低训练的数值精度,而不牺牲太多的收敛速度或精度。所需的数值精度已从FP16降低到FP8、INT32+INT8和INT8+INT5。FP8训练是在英伟达的H100 GPU和变压器引擎中实现的,为大型变压器的训练实现了令人印象深刻的加速。
最近,训练数值精度已被降低到4位。Sun等人成功地用INT4激活/权重和FP4梯度训练了几个现代网络;和Chmiel等人提出了一种自定义的4位对数数字格式,以进一步提高精度。然而,这些4位训练方法不能直接用于加速,因为它们需要现代硬件不支持的自定义数字格式。在极低的4位水平上训练神经网络存在重大的优化挑战。首先,前向传播中的不可微量化器使损失景观变得崎岖不平,其中基于梯度的优化器很容易陷入局部最优。其次,梯度仅以低精度近似计算。这种不精确的梯度减缓了训练过程,甚至导致训练不稳定或偏离。
Fully Quantized Training
全量化训练(FQT)方法通过将激活、权重和梯度量化到低精度来加速训练,因此训练过程中的线性和非线性算子可以用低精度算法实现。FQT的研究设计了新的数值格式和量化算法,可以更好地逼近全精度张量。目前的研究前沿是4位FQT。由于梯度的巨大数值范围和从头开始训练量化网络的优化问题,FQT具有挑战性。由于这些挑战,现有的4位FQT算法在某些任务上的精度仍有1-2.5%的下降,并且它们无法支持当代硬件。
Other Efficient Training Methods
Mixture-of-experts【Outrageously large neural networks: The sparsely-gated mixture-of-experts layer】在不增加训练预算的情况下提高了模型的能力。结构丢弃利用计算上有效的方法来正则化模型。有效的注意力减少了计算注意力的二次时间复杂度。分布式训练系统通过利用更多的计算资源来减少训练时间。我们降低数值精度的工作与这些方向正交。

03
新框架
神经网络训练是一种迭代优化过程,通过前向和后向传播计算随机梯度。我们使用4位整数(INT4)算法加速正向和反向传播。首先描述我们的训练程序的正向传播。前向传播可以公式化为线性和非线性(GeLU、归一化、softmax等)算子的组合。在我们的训练过程中,我们使用INT4算法加速所有线性算子,并将所有计算密集度较低的非线性算子保留为16位浮点(FP16)格式。变压器中的所有线性运算都可以写成矩阵乘法(MM)形式。
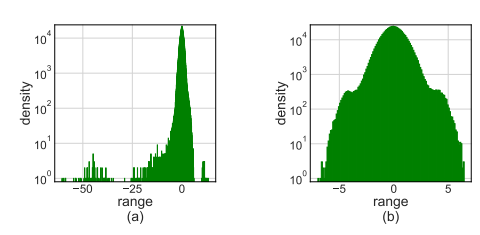
Histogram of activation of the linear-1-2 layer in a BERT-base-uncased model. (a) Original activation distribution; (b) Hadamard-transformed activation distribution.
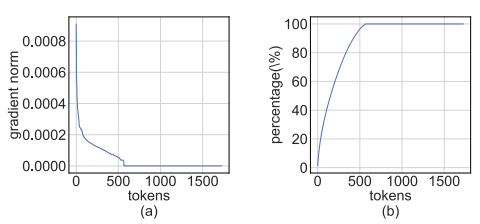
(a) The distribution of gradient norm along the token dimension. (b) The cumulative sum of the top X values as a percentage of the sum of all norms along the token dimension.
Hadamard Quantization
我们提出了一种Hadamard量化器(HQ)来解决异常值问题。它的主要思想是在另一个具有较少异常值的线性空间中量化矩阵。激活矩阵中的异常值形成了一个特征结构。它们通常集中在几个维度上,即只有少数X列比其他列大得多。Hadamard变换是一种线性变换,可以将异常值摊销为其他条目。具体地说,Hadamard变换Hk是2k×2k矩阵,其中:
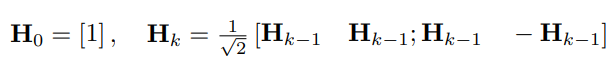
Hadamard矩阵是正交对称的:
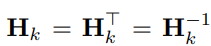
所以HkHk = I, ∀k ≥ 0。考虑任何坐标行向量e⊤i ∈ R2k。这证明了当单个异常值支配所有其他维度时的极端情况。在这种情况下,Hadamard变换有效地将矢量转变为量化友好的全一矢量。Hadamard变换在抑制激活异常值方面的实际效果如上图b所示。
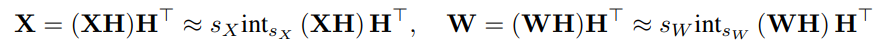
结合量化矩阵,我们得到:
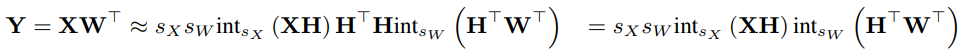


04
实验
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

往期推荐
🔗
中国提出的分割天花板 | 精度相当,速度提升50倍!
All Things ViTs:在视觉中理解和解释注意力
基于LangChain+GLM搭建知识本地库
OVO:在线蒸馏一次视觉Transformer搜索
最近几篇较好论文实现代码(附源代码下载)
AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)
CVPR 2023|EfficientViT:让ViT更高效部署实现实时推理(附源码)
VS Code支持配置远程同步了
基于文本驱动用于创建和编辑图像(附源代码)
基于分层自监督学习将视觉Transformer扩展到千兆像素图像
霸榜第一框架:工业检测,基于差异和共性的半监督方法用于图像表面缺陷检测
CLCNet:用分类置信网络重新思考集成建模(附源代码下载)
YOLOS:通过目标检测重新思考Transformer(附源代码)