环境
Linux:Hadoop2.x
Windows:jdk1.8、Maven3、IDEA2021
步骤
编程分析

编程分析包括:
1.数据过程分析:数据从输入到输出的过程分析。
2.数据类型分析:Map的输入输出类型,Reduce的输入输出类型;
编程分析决定了我们该如何编写代码。
新建Maven工程
打开IDEA–>点击File–>New–>Project
选择Maven–>点击Next
选择一个空目录作为项目目录,目录名称例如:wordcount,建议目录路径不包含中文和空格,点击Finish
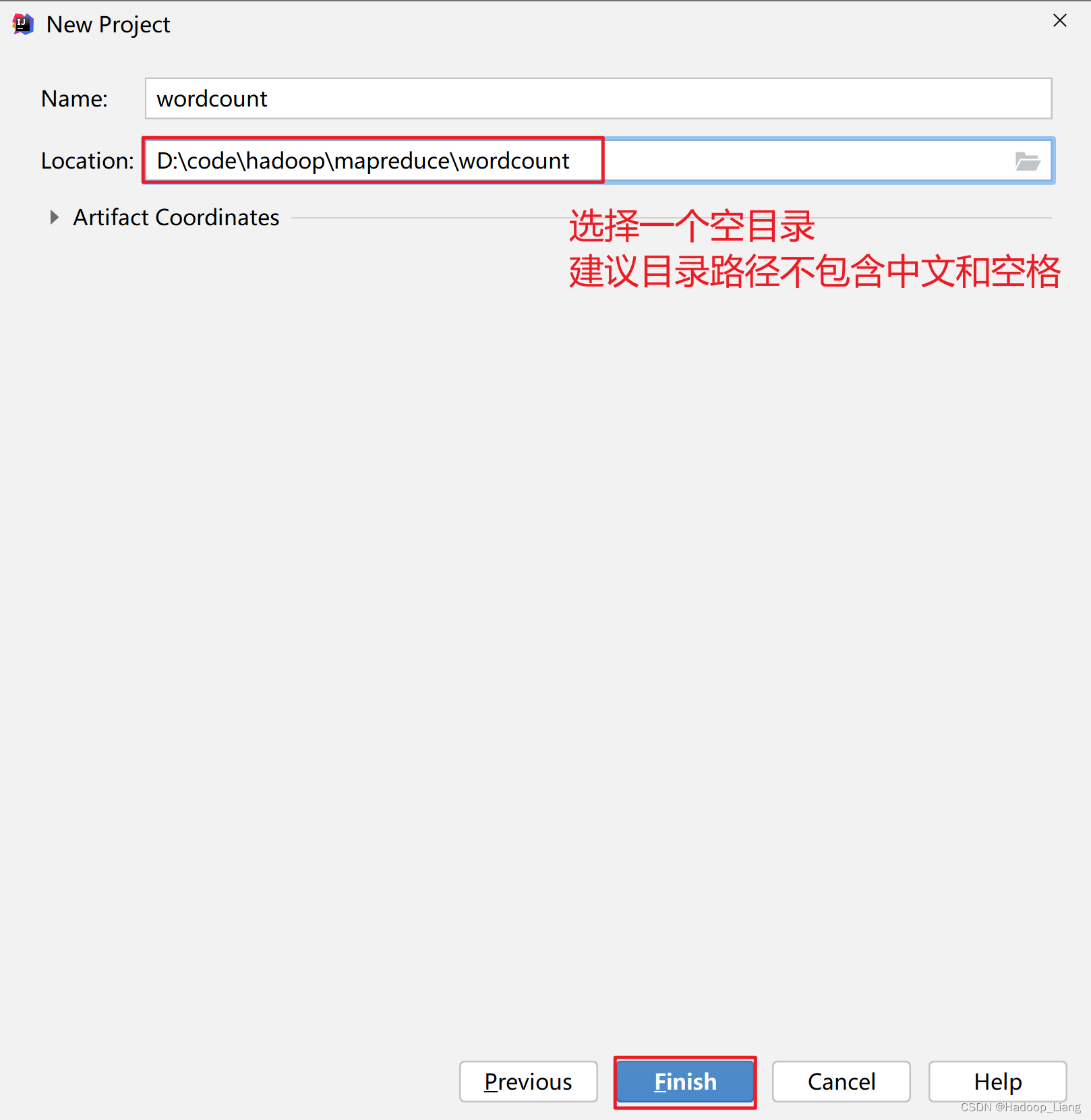
添加依赖
修改pom.xml,添加如下依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.7.3</version></dependency></dependencies>
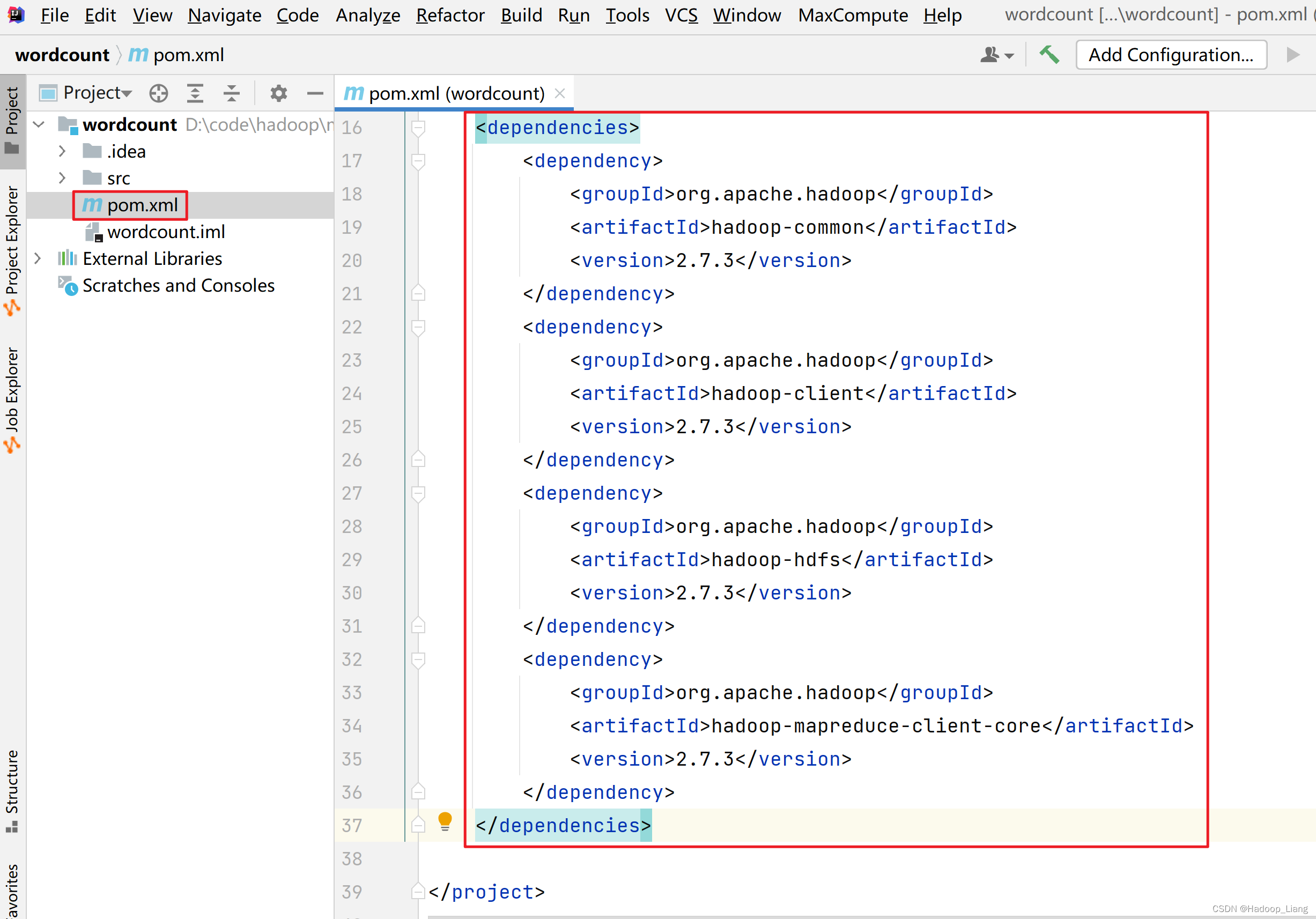
加载依赖
新建包
在src\main\java目录下,新建包:org.example
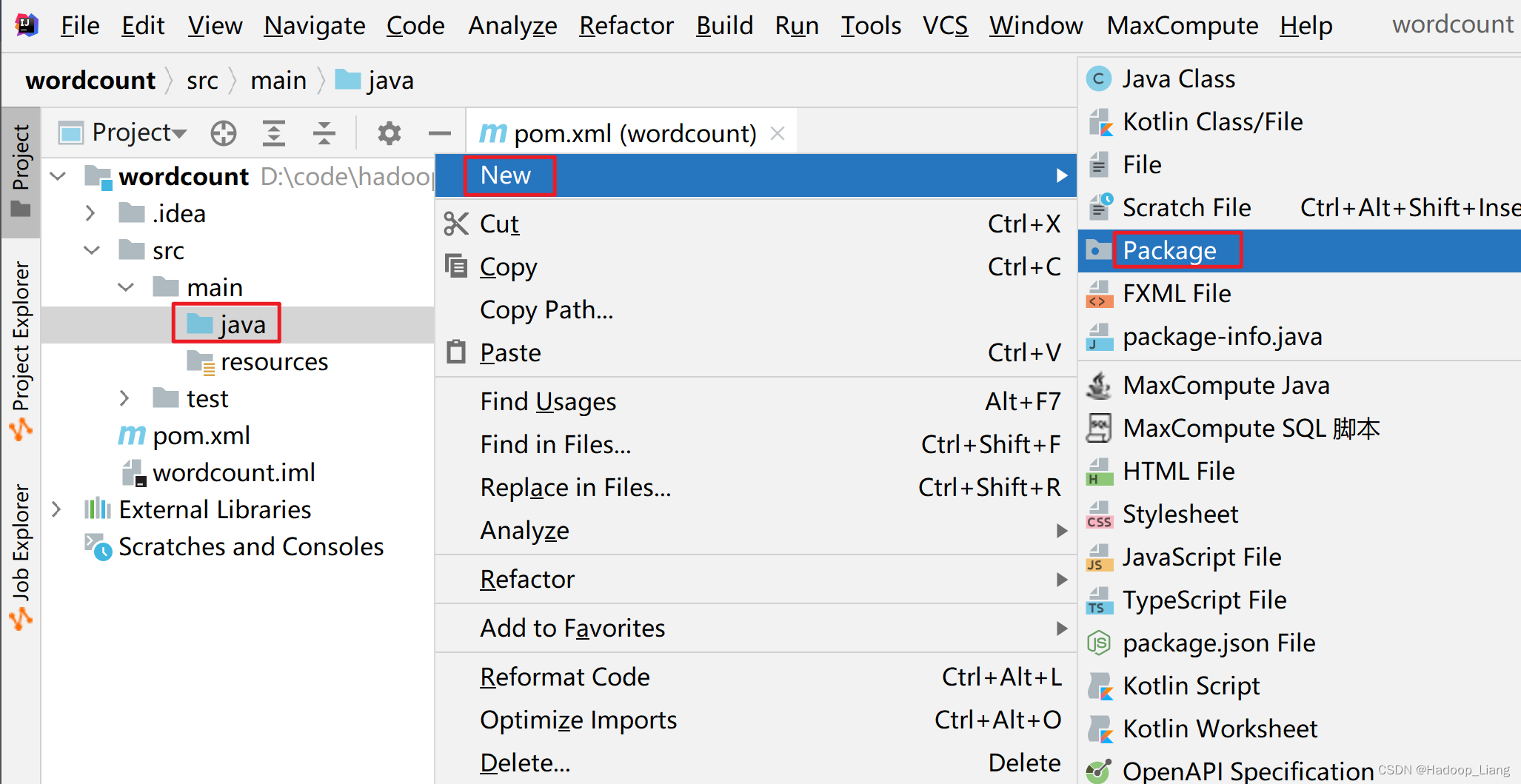
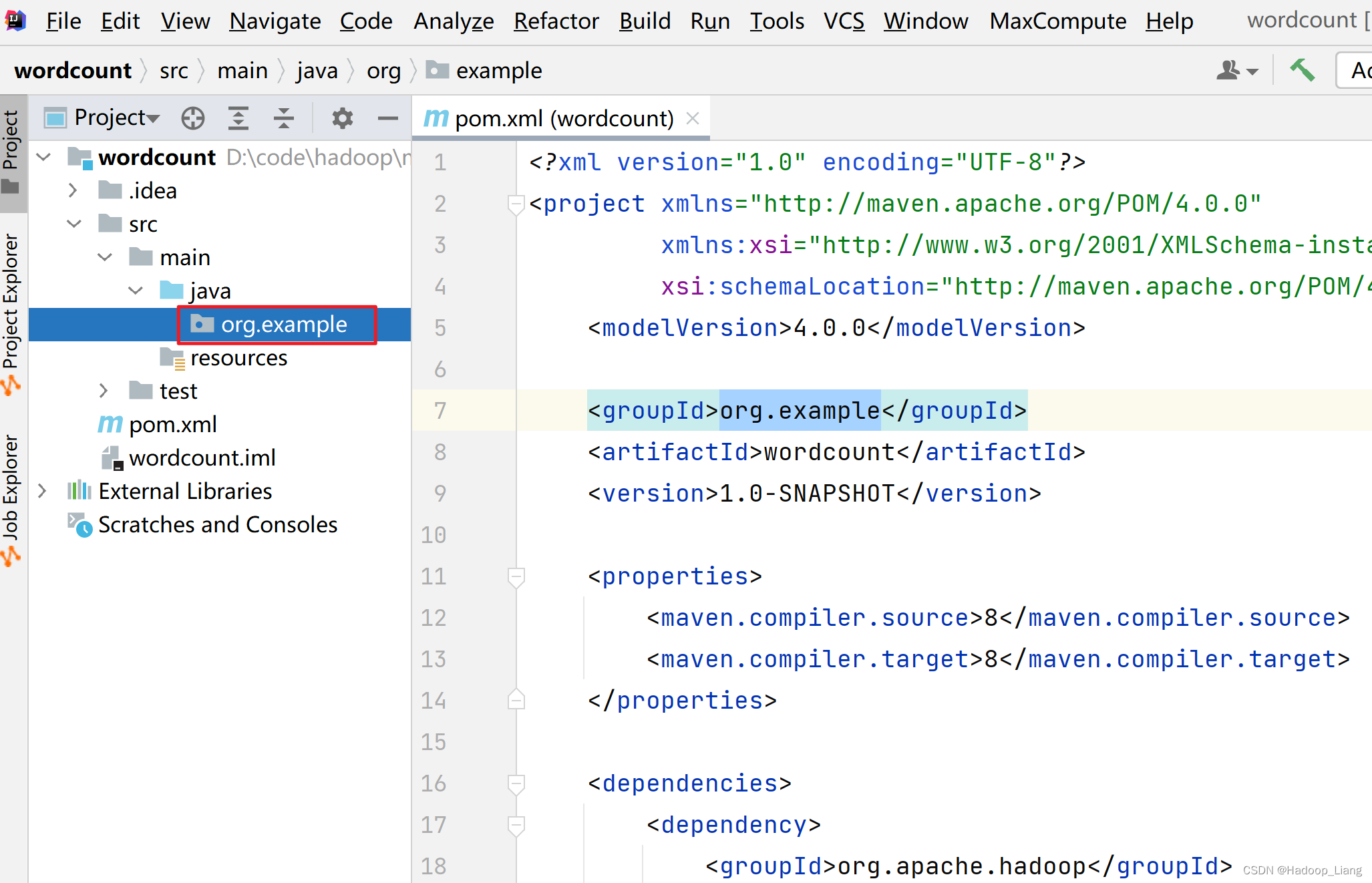
填入org.example,效果如下:
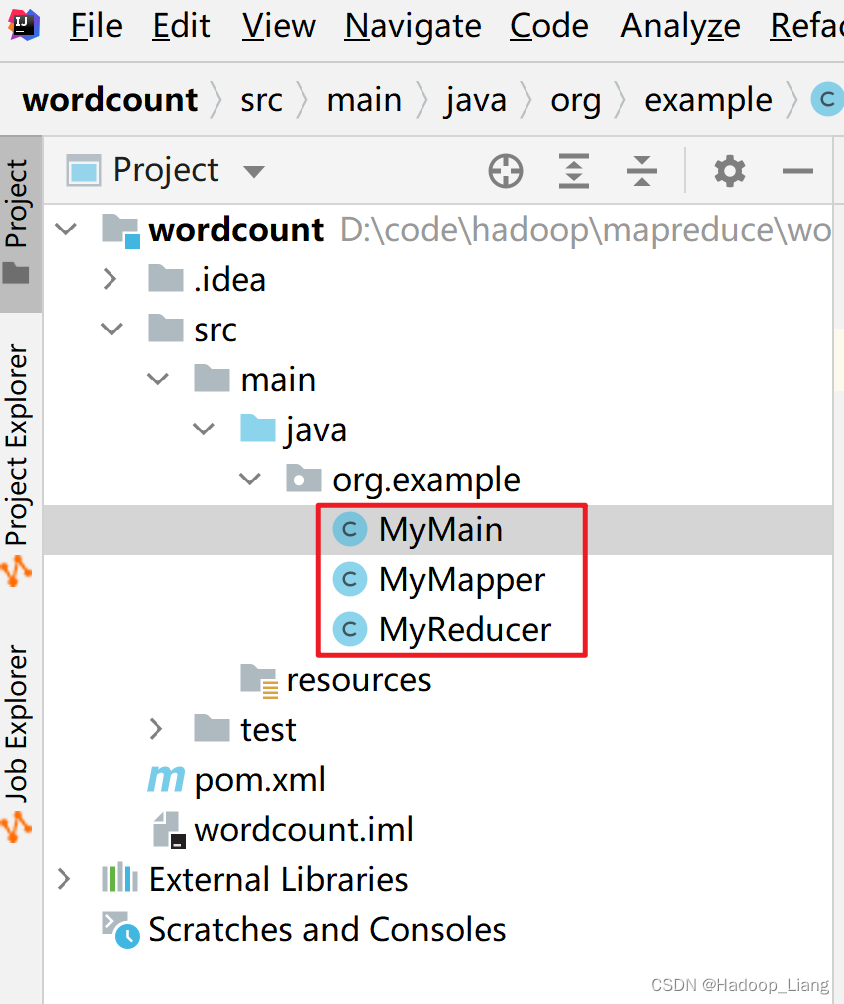
新建类
在org.example包下,新建出三个类,分别为:MyMapper、MyReducer、MyMain,效果如下:
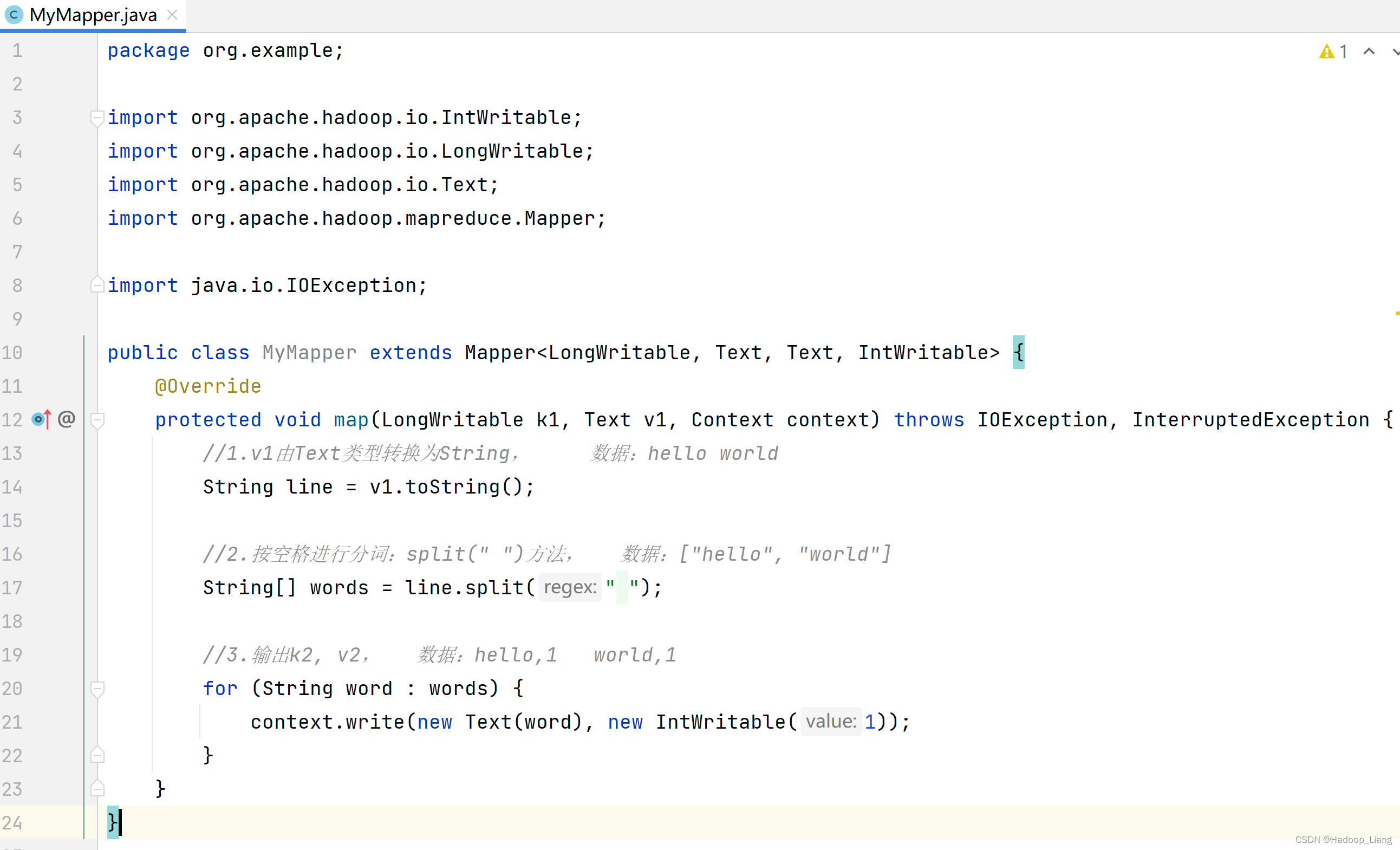
编写Map程序
编辑MyMapper类,步骤如下:
1.继承Mapper
2.重写map()方法
3.编写Map逻辑代码:1.v1由Text类型转换为String2.按空格进行分词:split(" ")方法3.输出k2, v2
编写Reduce程序
编辑MyReducer类,步骤如下:
1.继承Reducer
2.重写reduce()方法
3.编写Reduce逻辑代码:1.k4 = k32.v4 = v3元素的和3.输出k4, v4
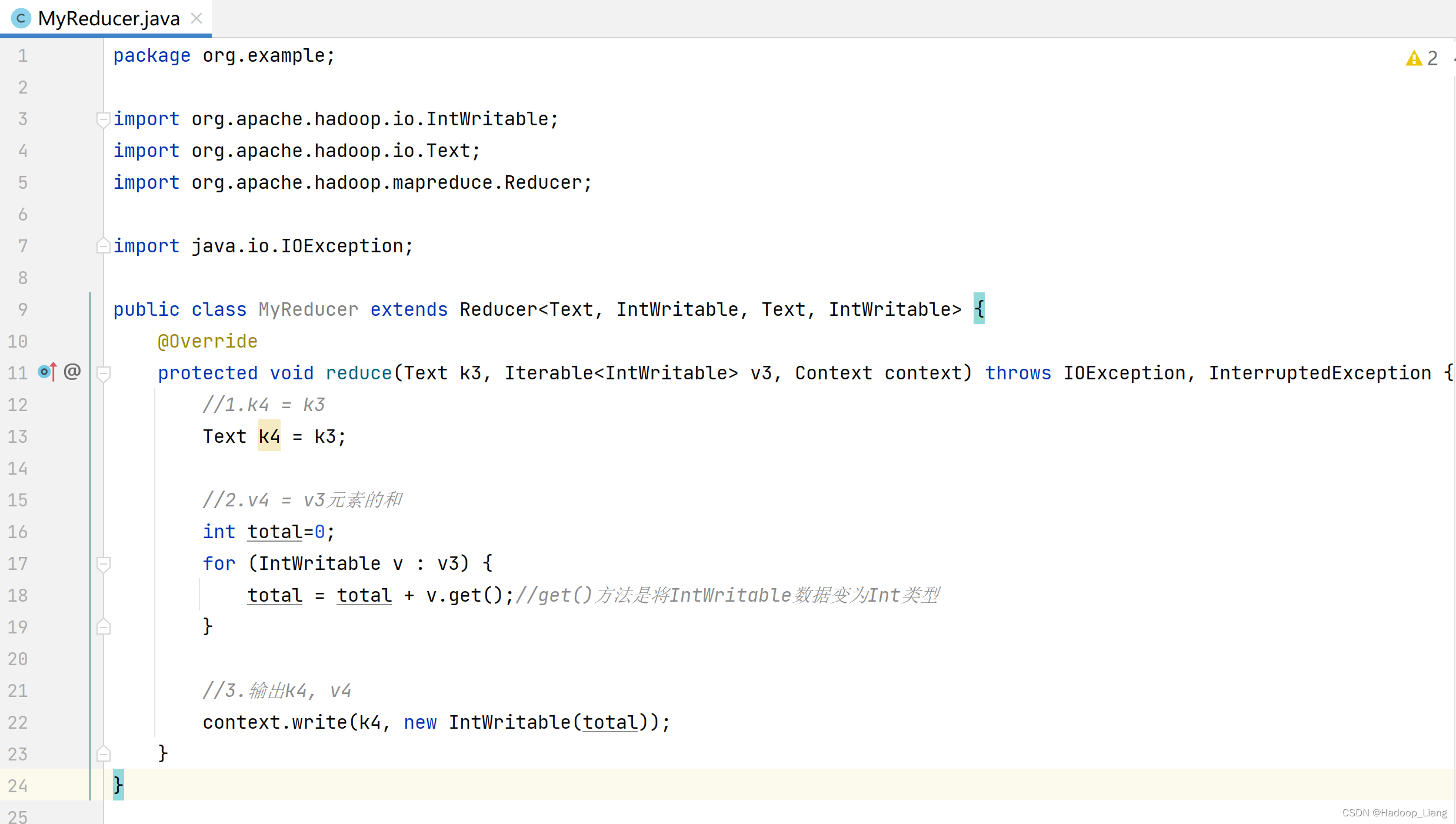
编写Main程序(Driver程序)
编辑MyMain类,步骤如下:
1. 创建一个job和任务入口(指定主类)
2. 指定job的mapper和输出的类型<k2 v2>
3. 指定job的reducer和输出的类型<k4 v4>
4. 指定job的输入和输出路径
5. 执行job
思考
代码编写完成后,可以先在Windows本地运行吗?
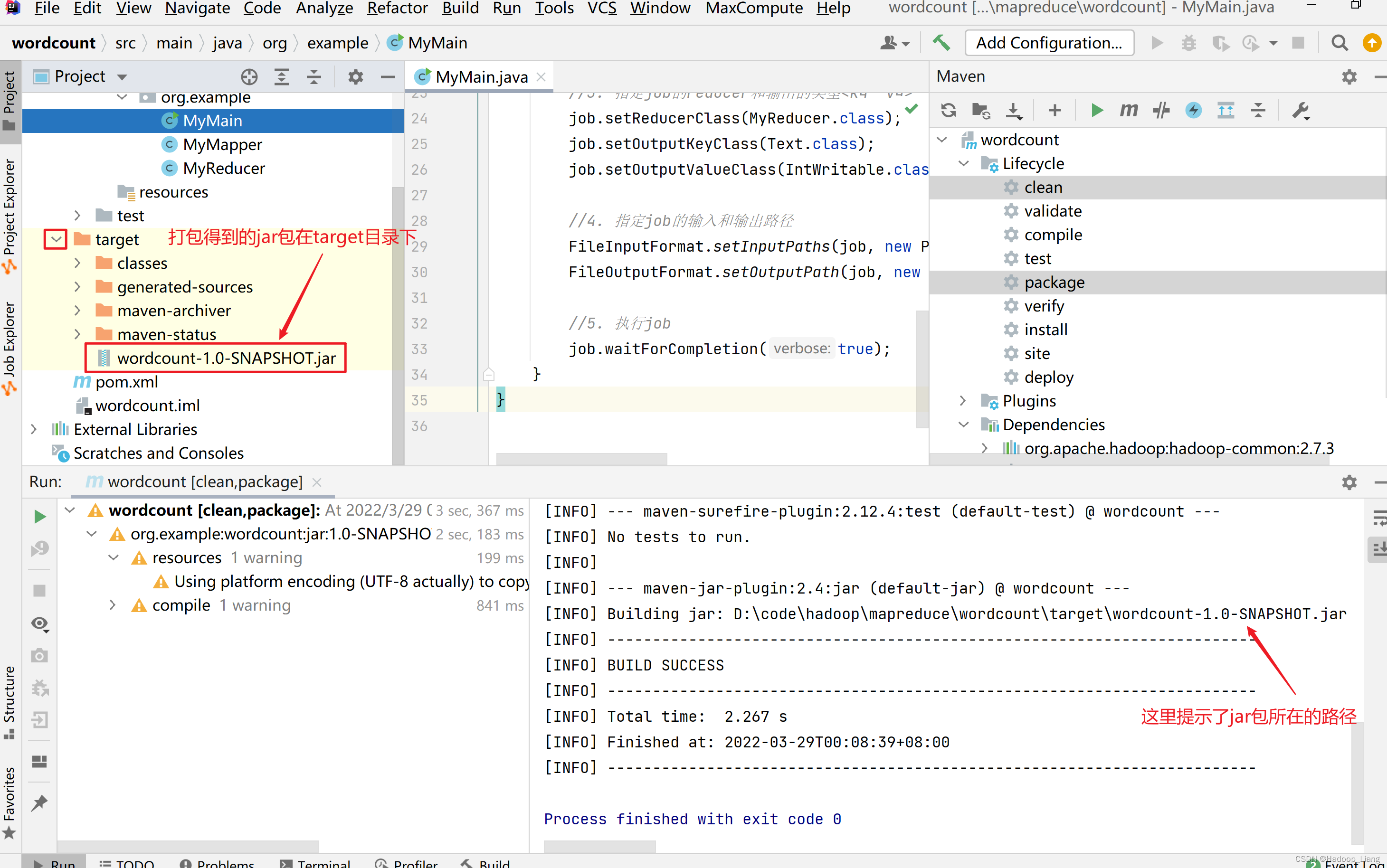
打包
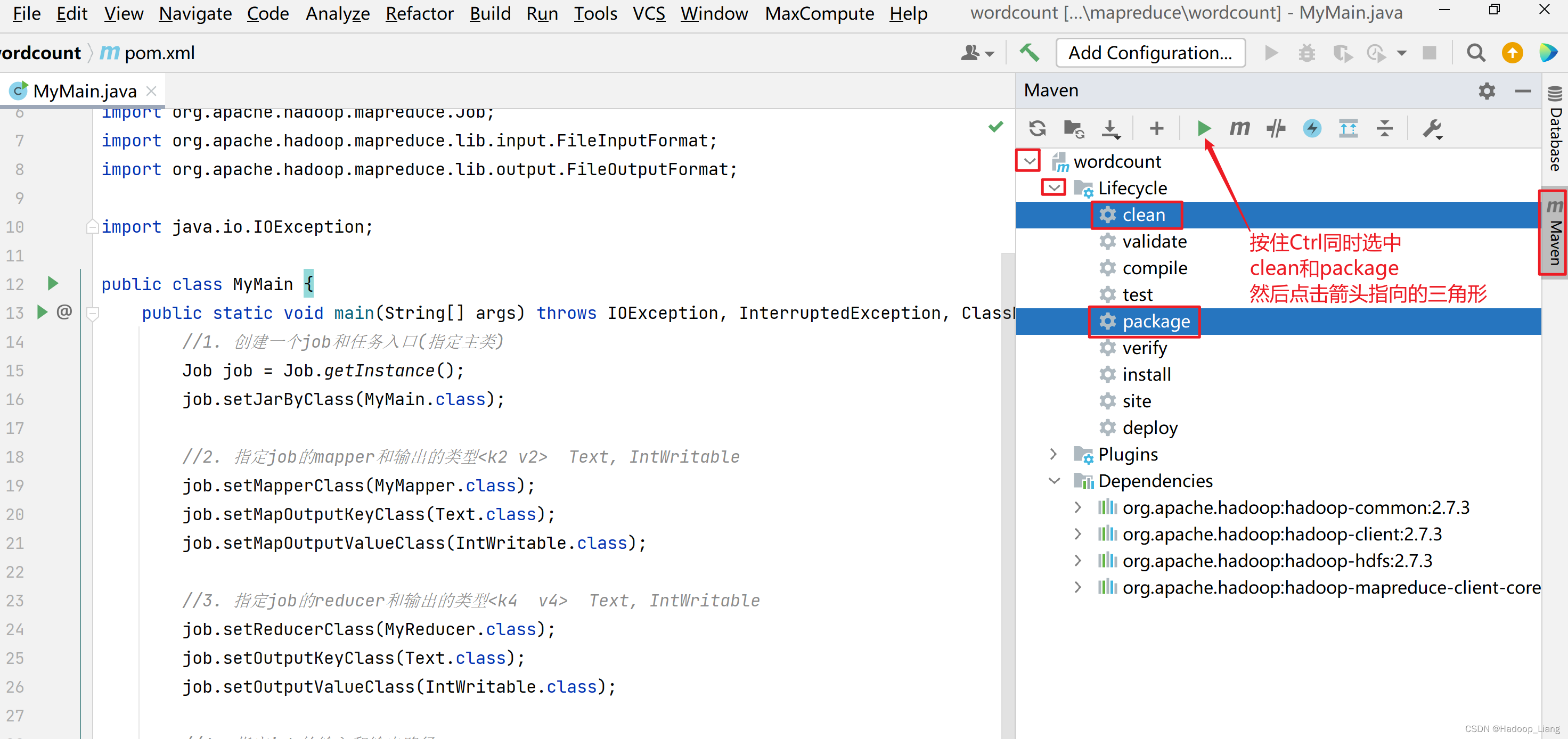
看到BUILD SUCCESS为打包成功
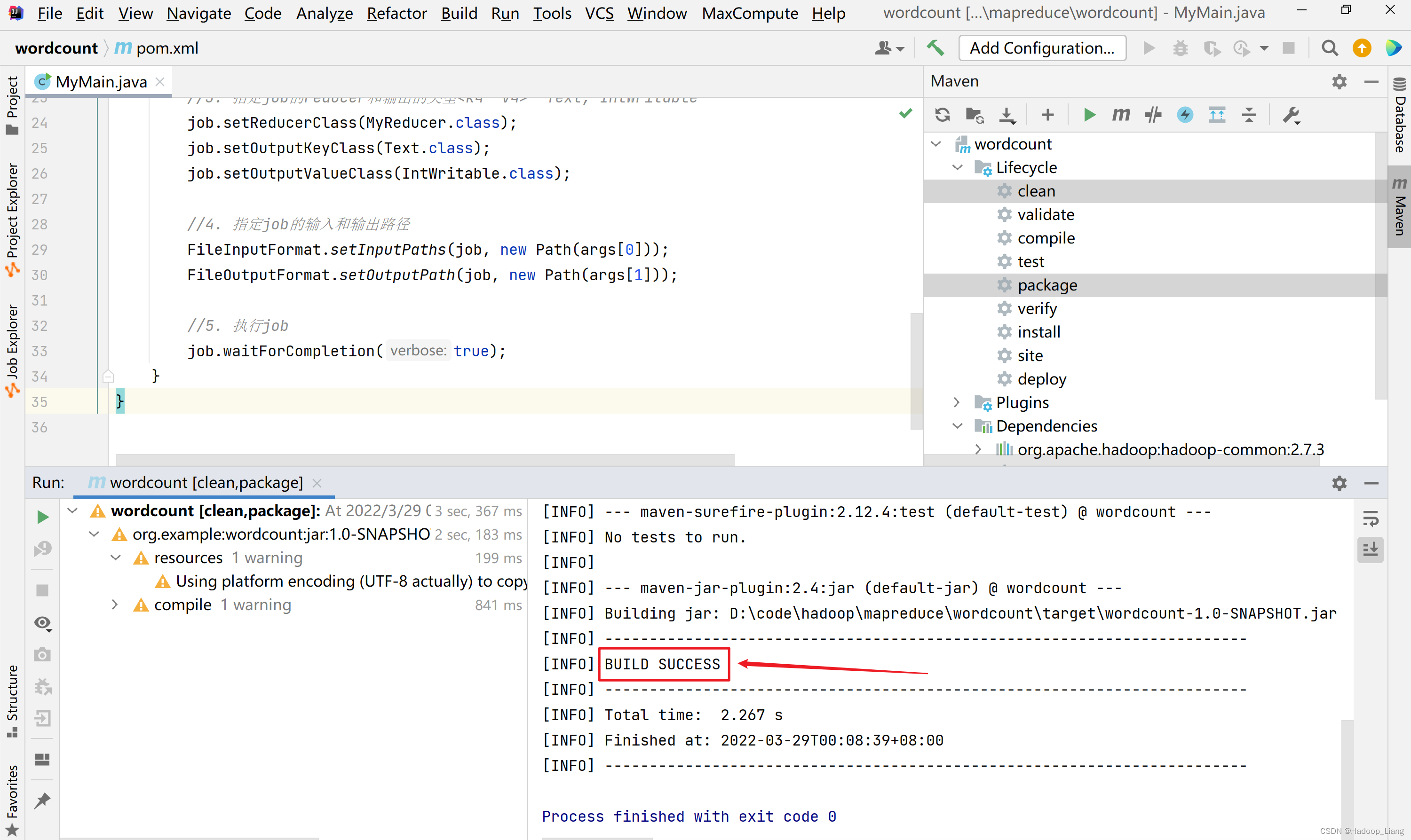
打包后得到的jar包,在项目的target目录下
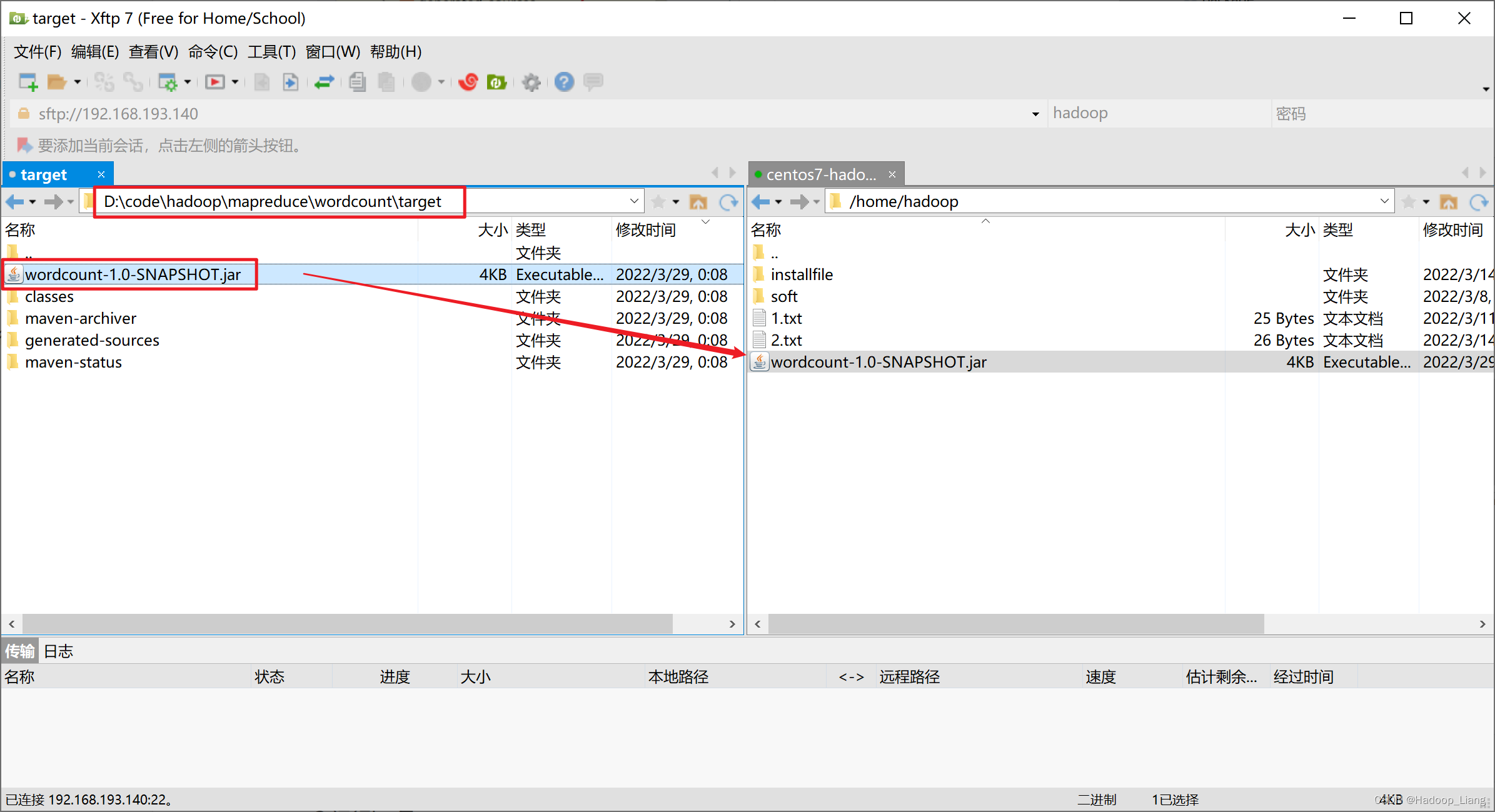
提交到Hadoop集群运行
1.将上一步打包得到的jar包,上传到linux
2.启动hadoop集群
start-all.sh
3.运行jar包
从Linux本地上传一个文件到hdfs
hdfs dfs -put 1.txt /input/1.txt
hdfs查看输入数据

运行jar包
hadoop jar wordcount-1.0-SNAPSHOT.jar org.example.MyMain /input/1.txt /output/wordcount
正常运行过程输出如下:
[hadoop@node1 ~]$ hadoop jar wordcount-1.0-SNAPSHOT.jar org.example.MyMain /input/1.txt /output/wordcount
22/03/29 00:23:59 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.193.140:8032
22/03/29 00:23:59 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
22/03/29 00:24:00 INFO input.FileInputFormat: Total input paths to process : 1
22/03/29 00:24:00 INFO mapreduce.JobSubmitter: number of splits:1
22/03/29 00:24:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1648484275192_0001
22/03/29 00:24:01 INFO impl.YarnClientImpl: Submitted application application_1648484275192_0001
22/03/29 00:24:01 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1648484275192_0001/
22/03/29 00:24:01 INFO mapreduce.Job: Running job: job_1648484275192_0001
22/03/29 00:24:08 INFO mapreduce.Job: Job job_1648484275192_0001 running in uber mode : false
22/03/29 00:24:08 INFO mapreduce.Job: map 0% reduce 0%
22/03/29 00:24:12 INFO mapreduce.Job: map 100% reduce 0%
22/03/29 00:24:17 INFO mapreduce.Job: map 100% reduce 100%
22/03/29 00:24:19 INFO mapreduce.Job: Job job_1648484275192_0001 completed successfully
22/03/29 00:24:19 INFO mapreduce.Job: Counters: 49File System CountersFILE: Number of bytes read=55FILE: Number of bytes written=237261FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=119HDFS: Number of bytes written=25HDFS: Number of read operations=6HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=2290Total time spent by all reduces in occupied slots (ms)=2516Total time spent by all map tasks (ms)=2290Total time spent by all reduce tasks (ms)=2516Total vcore-milliseconds taken by all map tasks=2290Total vcore-milliseconds taken by all reduce tasks=2516Total megabyte-milliseconds taken by all map tasks=2344960Total megabyte-milliseconds taken by all reduce tasks=2576384Map-Reduce FrameworkMap input records=2Map output records=4Map output bytes=41Map output materialized bytes=55Input split bytes=94Combine input records=0Combine output records=0Reduce input groups=3Reduce shuffle bytes=55Reduce input records=4Reduce output records=3Spilled Records=8Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=103CPU time spent (ms)=1200Physical memory (bytes) snapshot=425283584Virtual memory (bytes) snapshot=4223356928Total committed heap usage (bytes)=277348352Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=25File Output Format Counters Bytes Written=25
[hadoop@node1 ~]$ 查看输出结果

思考
-
如果运行过程报如下错误,该如何解决?
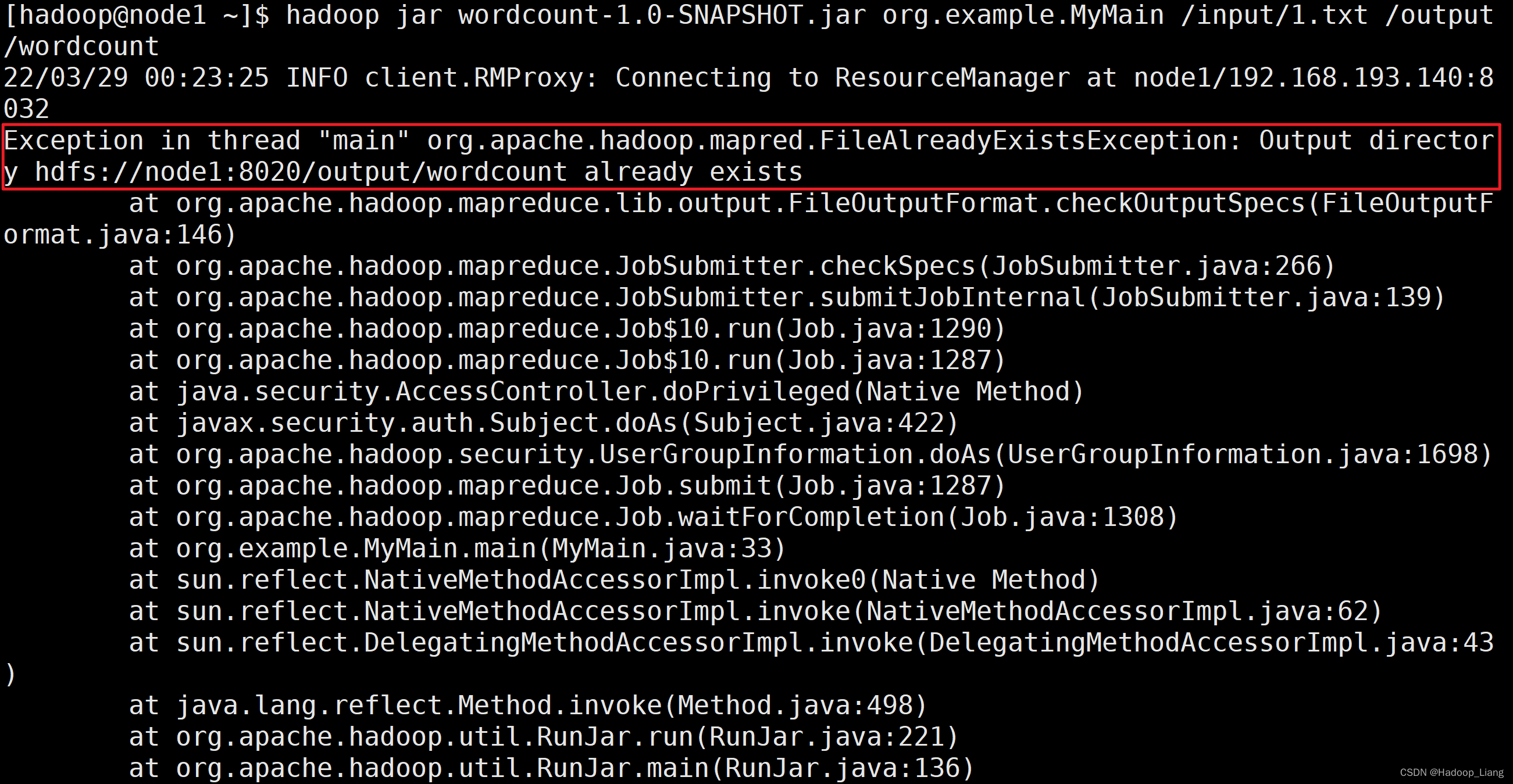
-
代码还可以优化吗?如何优化?
完成!enjoy it!