文章目录
- 前言
- 分库分表方法
- 一致性哈希
- 介绍
- 分库分表的应用
- 总结
前言
大家应该都知道一些哈希算法,比如MD5、SHA-1、SHA-256等,通常被用于唯一标识、安全加密、数据校验等场景。除此之外,还有一种应用是对某个数据进行哈希取模映射到一个有限的范围,比如哈希表快速定位、分库分表数据分配等。本文将以分库分表为主题,介绍另外一种哈希算法,并详细说明其在分库分表中的应用与优势。
分库分表方法
在对数据进行分库分表时,通常有两个策略(这里主要说的是水平分库分表):
-
第一种是范围分库分表,比如将ID1~1000W的数据存放在第一个表或库中,或者将某个时间段的数据放在第一个表或库中,以此类推。这种方式会带来几个问题:
- 数据倾斜:因为某些时间段的数据的多少是不确定的,可能会出现数据量超过预期而造成的查询性能下降,或者是数据量远远小于预期造成的空间浪费。
- 没有分担压力:分库分表的一个主要目的是避免单节点的数据量过大造成性能下降。另一个目的是可以在高并发的场景下分担压力,但是范围策略中总是在对一个库或者表在操作,起不到分担压力的作用,毕竟一个数据库的连接和处理能力是有限的。
-
第二种是哈希分库分表,通常都是将某个数据进行哈希后进行取模,然后映射到对应的库或表中,这个模一般就是库的个数或者表的个数,所以个数是固定的。
同样,如果哈希不当也会存在数据倾斜问题,所以通常对那些随机、不连续的数据进行哈希效果较好。
但是同样存在一个问题那就是:当现有的表和库容量不足也就是需要扩容的时候,涉及到数据迁移的问题,因为模数变了,之前的数据都需要重新取模重新分配到新的库和表中,不然就会出现“查无此人”的错误了。如下图,添加“DB4“后,旧数据进行hash后会映射到“DB0“上,如果不迁移数据就会出现问题。
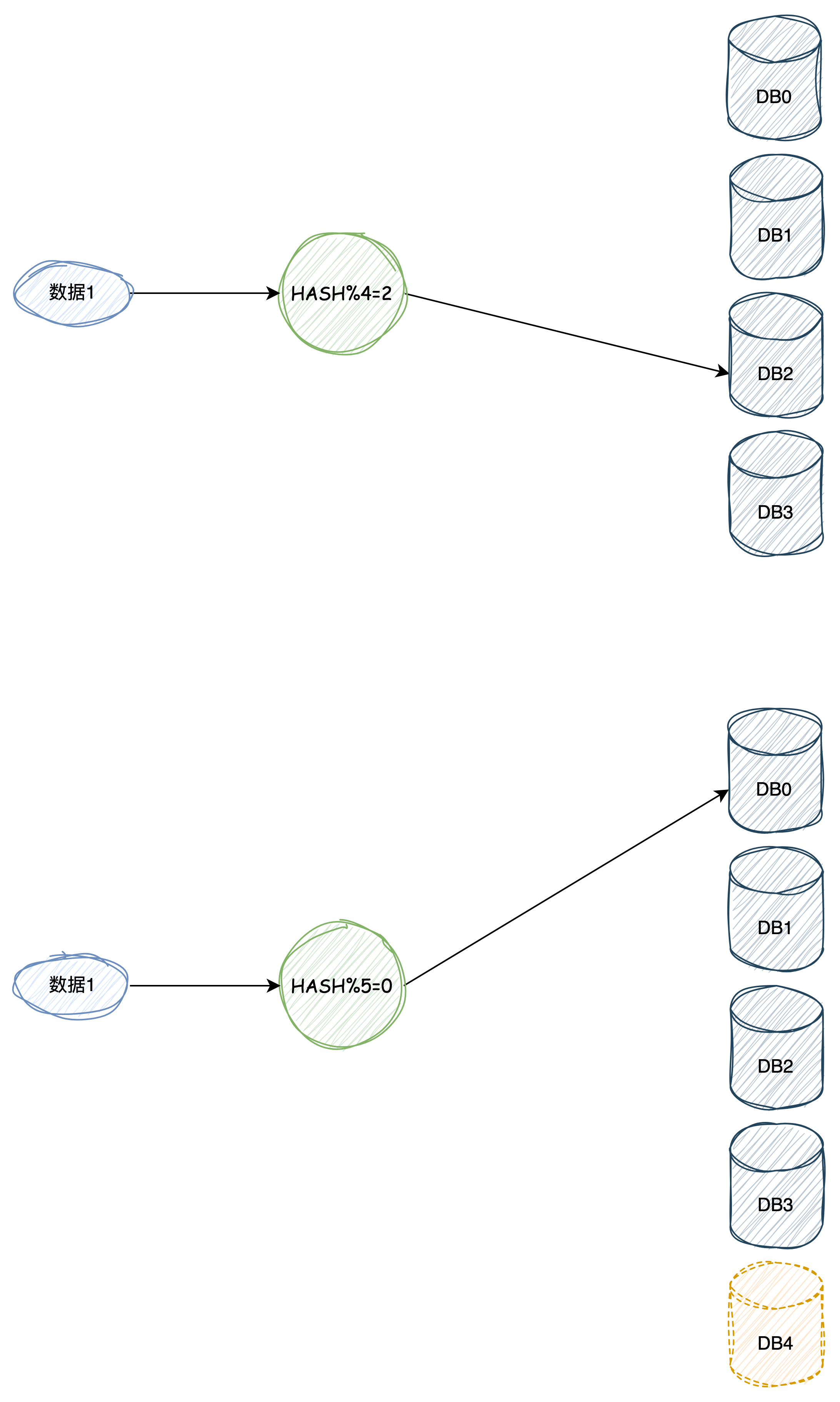
很显然,以上两种方法都存在问题,但是哈希这种方法更能体现分库分表的作用,但是带来的代价是全量数据的迁移,需要考虑迁移带来的风险,迁移之后的数据一致性、完整性等各种因素。
那有没有方法可以避免迁移,答案是没有的,只要是使用哈希这种方式,在改变模个数后一定是要迁移数据的。但是有一种方法可以降低迁移量以及带来的风险,那就是一致性哈希。
一致性哈希
介绍
一致性哈希算法是一种特殊的哈希算法,通常用于分布式系统中,比如分布式缓存、分布式数据库等解决数据的分配和负载均衡的场景。与其他哈希算法一样,具有单向性、离散性、平衡性。不同的是,一致性哈希算法在取模时这个模足够大,比如 Fowler–Noll–Vo (FNV) 哈希函数,就是是一种高效、分布均匀的哈希函数,其模数也就是输出域在0~232-1区间。
其原理是将输出域构成一个环,数据和节点通过一致性哈希算法后映射到环中的某个点,当需要把数据插入某个节点或查找数据在某个节点时,这个数据对应的哈希值只需在这个环上顺时针找到第一个节点进行操作即可。当节点数量改变时,只需要重新分配一小部分数据即可。
分库分表的应用
如下图,共有3个节点(也可以理解成3个数据库实例),经过一致性哈希算法后映射到环中的某个点。图中的“数据1”经过相同的一致性哈希算法后也映射到环中的某个点,这个时候如果要存储或者查找该数据就需要顺时针找到第一个节点,也就是“节点2”。
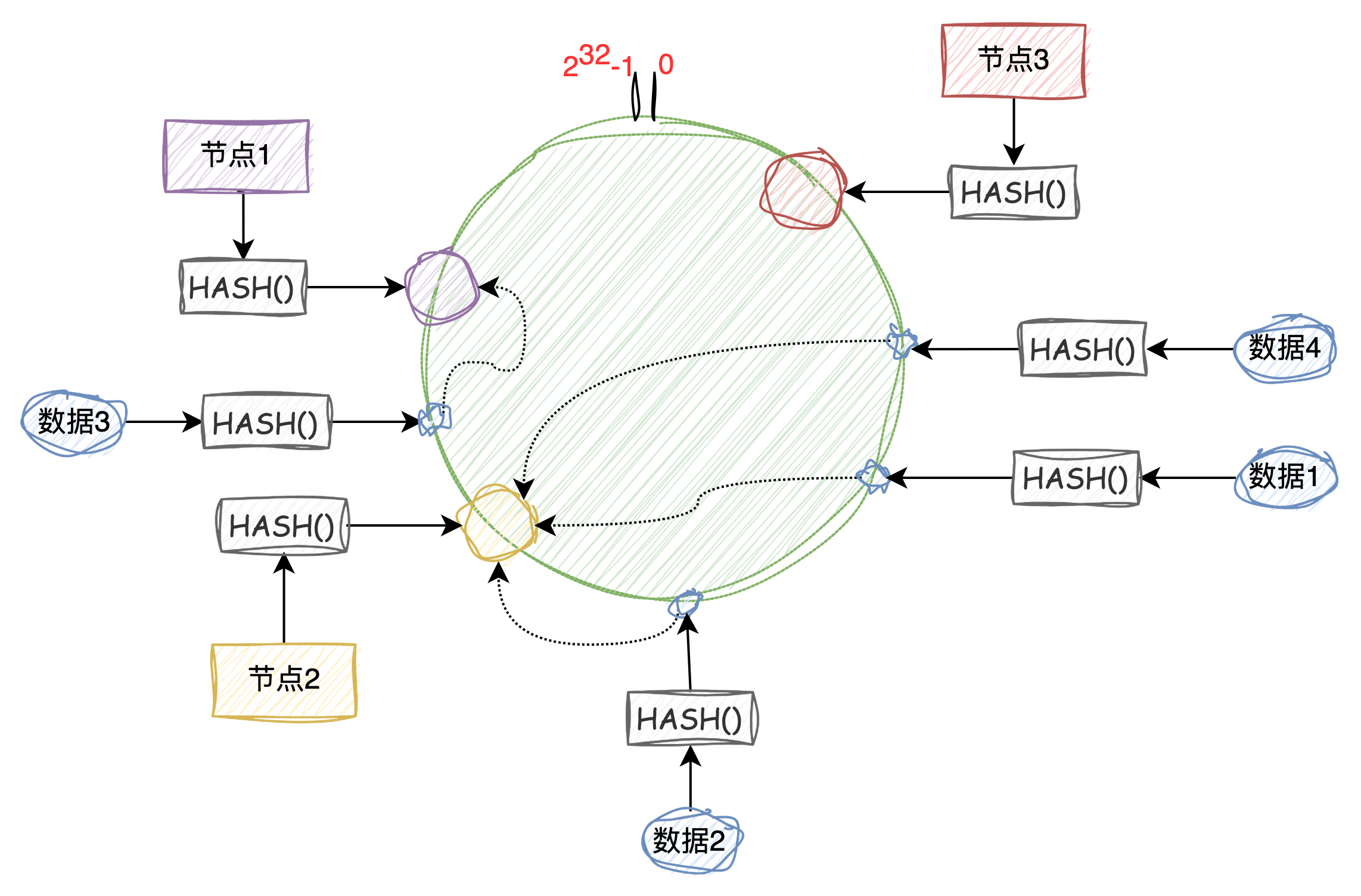
那当添加一个节点后数据怎么迁移?如下图,当添加“节点4“后,只需要将“节点2“中的部分数据迁移到“节点4“中。实现上就是将“节点2“中的哈希值大于“节点3“小于等于“节点4“的数据迁移到“节点4“中,这样在分库分表中就最大程度减少的数据的迁移,也降低了迁移数据的风险。
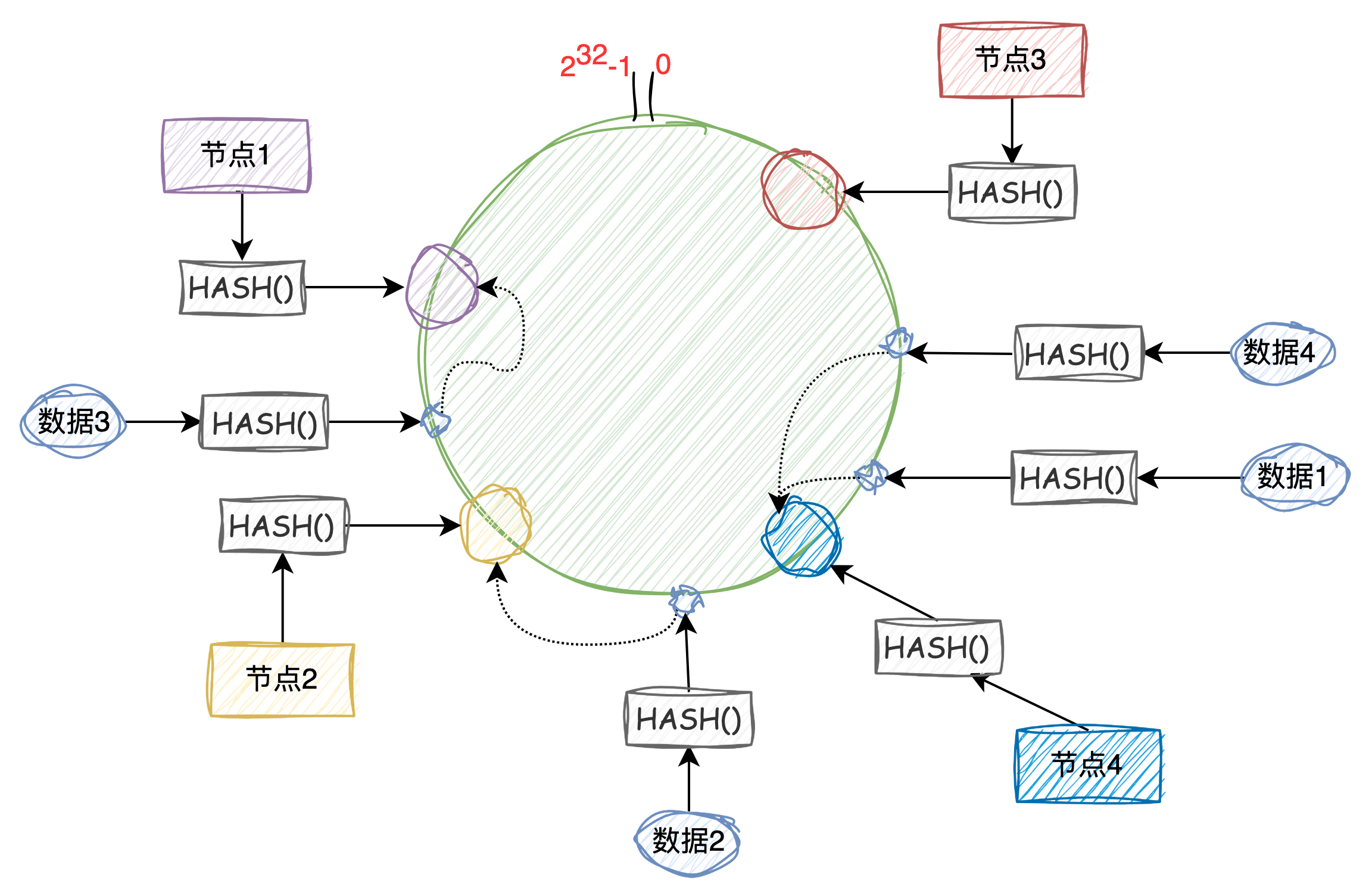
通常在进行分库分表时我们的节点个数时有限的,前期可能如图1的分布一样,由于节点在环中分配不均匀,数据映射到环中也不均匀,就会有大量的数据会分布到“节点2”中,同样会造成数据倾斜问题。
怎么办?那就让节点分布均匀,这时候就要引入虚拟节点了。就是说真实的节点虽然只有三个,但是我们可以让每个节点作为大节点管理1000、10000、100000个虚拟的节点,使得每个大节点在环中分布均匀,如下图。
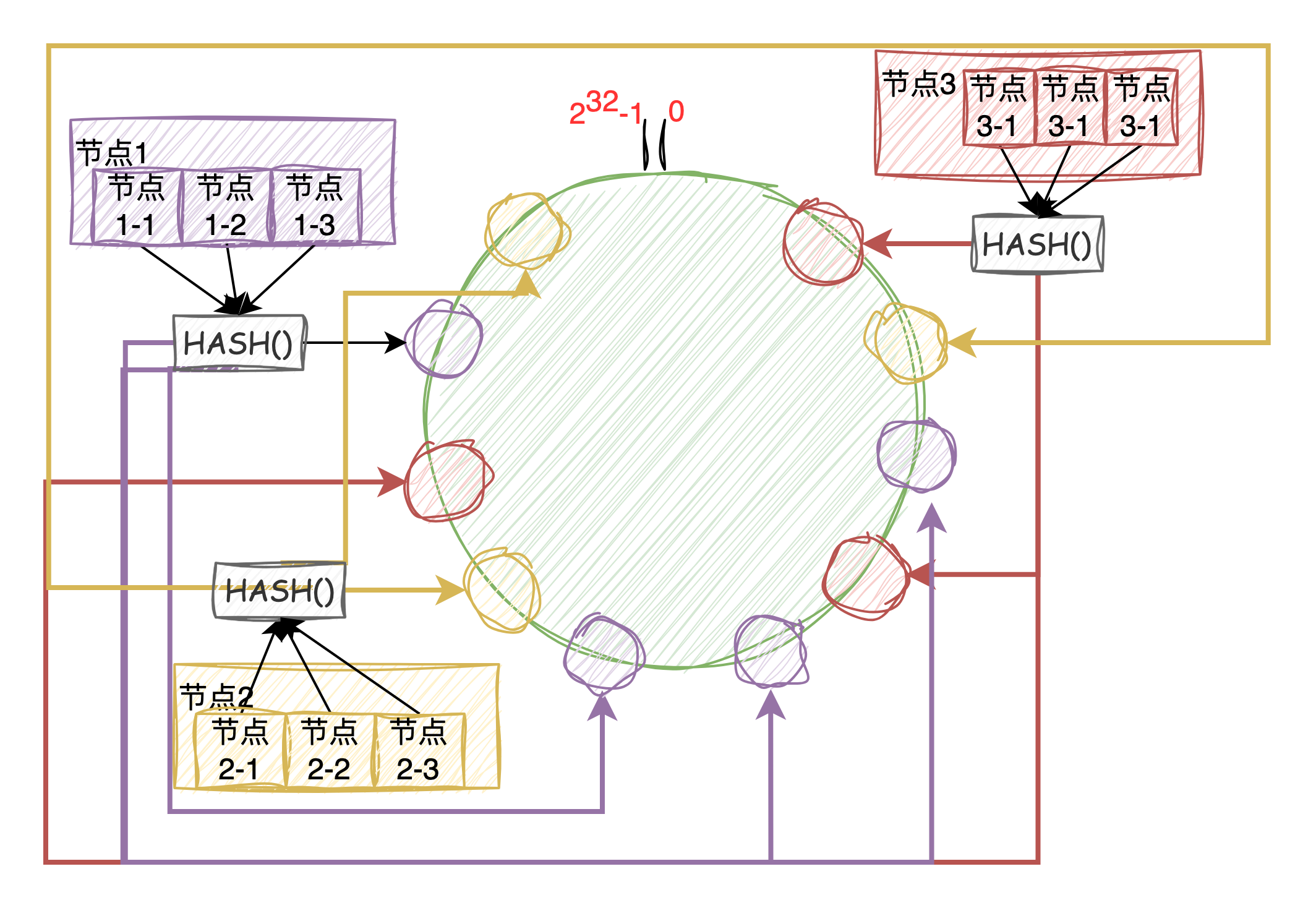
这样之后,根据哈希的平衡性,数据会均匀的分布到3个节点中,如果需要添加一个大节点,同样是分发给虚拟节点到环上,然后根据迁移规则进行部分数据的迁移。
总结
一致性哈希算法在分库分表的应用中提供了一种高效、均匀且易于扩展的数据分布方式,同时在节点增减时最小化数据迁移成本,是一种还不错的分库分表方案。