分类目录:《深入理解强化学习》总目录
目前为止我们讨论的所有方法都在一定程度上依赖于初始动作值 Q 1 ( a ) Q_1(a) Q1(a)的选择。从统计学角度来说,这些方法(由于初始估计值)是有偏的。对于采样平均法来说,当所有动作都至少被选择一次时,偏差就会消失。但是对于步长为常数的情况,偏差会随时间减小,但不会消失。在实际中,这种偏差通常不是一个问题,有时甚至还会很有好处。缺点是,如果不将它们全部设置为0,则初始估计值实际上变成了一个必须由用户选择的参数集。好处是,通过它们可以简单地设置关于预期收益水平的先验知识。
初始动作的价值同时也提供了一种简单的试探方式。比如一个10臂的测试平台,我们替换掉原先的初始值0,将它们全部设为 + 5 +5 +5。注意,如前所述,在这个问题中, q ∗ ( a ) q_*(a) q∗(a)是按照均值为0方差为1的正态分布选择的。因此 + 5 +5 +5的初始值是一个过度乐观的估计。但是这种乐观的初始估计却会鼓励动作一价值方法去试探。因为无论哪一种动作被选择,收益都比最开始的估计值要小;因此学习器会对得到的收益感到“失望",从而转向另一个动作。其结果是,所有动作在估计值收敛之前都被尝试了好几次。即使每一次都按照贪心法选择动作,系统也会进行大量的试探。
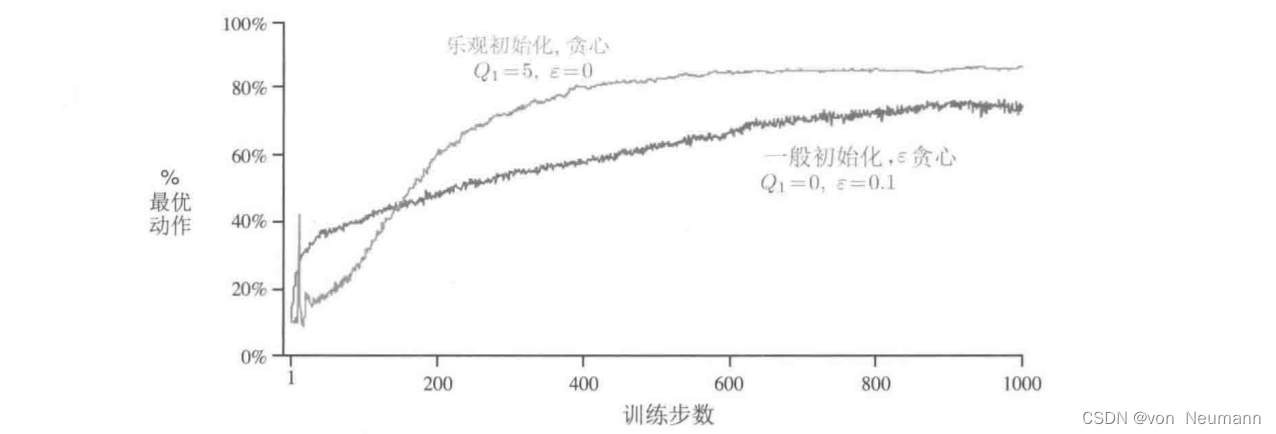
下图展示了在一个10臂测试平台上设定初始值 Q 1 ( a ) = + 5 Q_1(a)=+5 Q1(a)=+5,并采用贪心算法的结果。为了比较,同时展示了 ϵ − \epsilon- ϵ−贪心算法使用初始值 Q 1 ( a ) = 0 Q_1(a)=0 Q1(a)=0的结果。刚开始乐观初始化方法表现得比较糟糕,因为它需要试探更多次,但是最终随着时间的推移,试探的次数减少,它的表现也变得更好。我们把这种鼓励试探的技术叫作乐观初始价值。我们认为这是一个简单的技巧,在平稳问题中非常有效,但它远非鼓励试探的普遍有用的方法。例如,它不太适合非平稳问题,因为它试探的驱动力天生是暂时的。如果任务发生了变化,对试探的需求变了,则这种方法就无法提供帮助。事实上,任何仅仅关注初始条件的方法都不太可能对一般的非平稳情况有所帮助。开始时刻只出现一次,因此我们不应该过多地关注它。对于采样平均法也是如此,它也将时间的开始视为一种特殊的事件,用相同的权重平均所有后续的收益。但是所有这些方法都很简单,其中一个或几个简单的组合在实践中往往是足够的。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022