目录
136. 只出现一次的数字 - 力扣(LeetCode)
771. 宝石与石头 - 力扣(LeetCode)
旧键盘 (20)__牛客网 (nowcoder.com)
138. 随机链表的复制 - 力扣(LeetCode)
692. 前K个高频单词 - 力扣(LeetCode)
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :
输入:nums = [2,2,1] 输出:1
示例 2 :
输入:nums = [4,1,2,1,2] 输出:4
示例 3 :
输入:nums = [1] 输出:1
我们采用hashSet来完成这道题目

HashSet里面:add()添加元素,remove()删除元素,contains()包含元素(布尔类型)
class Solution {public int singleNumber(int[] nums) {HashSet<Integer> set = new HashSet<>();for(int x : nums){if(!set.contains(x)){set.add(x);}else{set.remove(x);}}//集合当中只有一个元素了,但不知道是哪个元素//所以我们需要再遍历一遍确定元素for(int x : nums){//找到元素就返回if(set.contains(x)){return x;}}return -1;}
}当然这道题更好的解法是异或,但不合主题我就不赘述了
运行时间:TreeSet > HashSet > 异或
771. 宝石与石头 - 力扣(LeetCode)
给你一个字符串 jewels 代表石头中宝石的类型,另有一个字符串 stones 代表你拥有的石头。 stones 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
字母区分大小写,因此 "a" 和 "A" 是不同类型的石头。
示例 1:
输入:jewels = "aA", stones = "aAAbbbb" 输出:3
示例 2:
输入:jewels = "z", stones = "ZZ" 输出:0
和上面那道题一样,指定一个空集合,遍历jewel的字符串,如果有集合里面不包含就加入,有重复的就删除。
🆗现在该集合里面包含了jewel里面不重复的字符,再遍历一次stones,如果有重复的就计数器++,最后返回计数器就行了
class Solution {public int numJewelsInStones(String jewels, String stones) {HashSet<Character> set = new HashSet<>();for(char ch : jewels.toCharArray()){if(!set.contains(ch)){set.add(ch);}else{set.remove(ch);}}int count = 0;for(char ch : stones.toCharArray()){if(set.contains(ch)){count++;}}return count;}
}旧键盘 (20)__牛客网 (nowcoder.com)
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及实际被输入的文字,请你列出
肯定坏掉的那些键。
输入描述:
输入在2行中分别给出应该输入的文字、以及实际被输入的文字。每段文字是不超过80个字符的串,由字母A-Z(包括大、小写)、数字0-9、 以及下划线“_”(代表空格)组成。题目保证2个字符串均非空。
输出描述:
按照发现顺序,在一行中输出坏掉的键。其中英文字母只输出大写,每个坏键只输出一次。题目保证至少有1个坏键。
示例1
输入
7_This_is_a_test<br/>_hs_s_a_es
输出
7TI
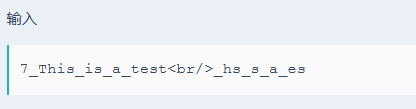
这个<br/>的意思是换行
7_This_is_a_test
_hs_s_a_es
这道题依然是找到第一行字符串中与第二行相异的字符,样例里面第一行的7,T,和i在第二行里面找不到对应字符,所以返回这三个字符并以大写形式输出
那这道题就老样子了,设置一个空集合,遍历第二行字符串,把字符转成大写后扔进去(不重复)
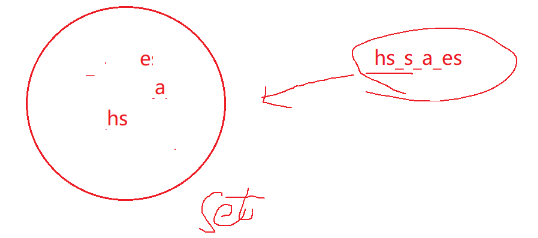
然后再遍历第一行字符串,看看集合里面有没有包含这个字符,不包含就打印出来
转成大写:toUpperCase()方法
public static void main(String[] args) {Scanner in = new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseString str1 = in.nextLine();String str2 = in.nextLine();func(str1,str2);}}private static void func(String str1,String str2){HashSet<Character> set1 = new HashSet<>();for(char ch:str2.toUpperCase().toCharArray()){set1.add(ch);}for(char ch : str1.toUpperCase().toCharArray()){if(!set1.contains(ch)){System.out.print(ch);}}}但是运行出来会有重复输出坏键的现象

我们可以把这些坏掉的键再放到一个集合里面,这个集合放的元素都不重复(集合互异性)

HashSet<Character> set2 = new HashSet<>();for(char ch : str1.toUpperCase().toCharArray()){if(!set1.contains(ch) && !set2.contains(ch)){System.out.print(ch);set2.add(ch);}
138. 随机链表的复制 - 力扣(LeetCode)
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
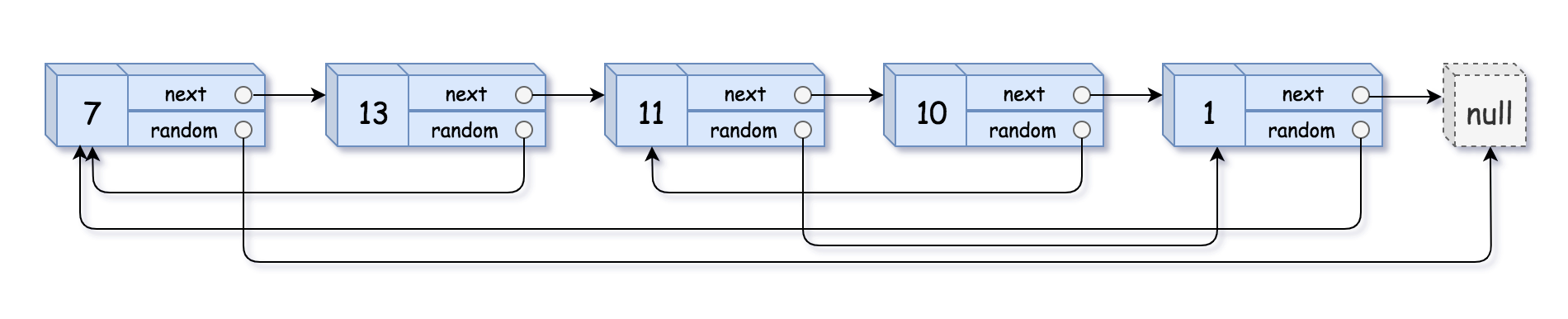
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]
这道题每个链表的结点比较有意思,由三个域组成,val,next和random
random指向的位置是随机的,可以指向别人也可以指向自己
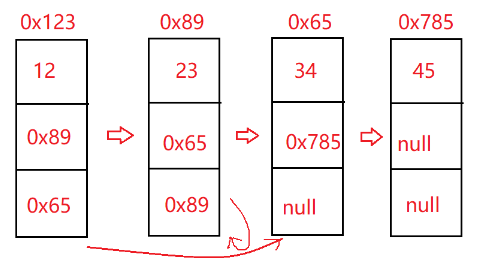
现在我们要深拷贝一份链表,这个链表的特点就是,当前结点next仍然指向下一个结点,random与被拷贝的链表一样,老链表指向哪个位置,新链表也指向哪个位置
比如老链表第一个结点的random指向第三个结点,那新链表第一个结点random也得指向第三个结点
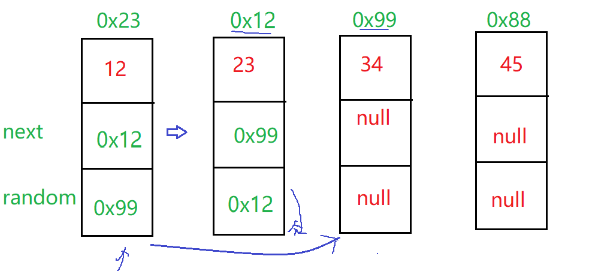
我们可以用map来关联两个链表,key存老链表结点的位置,value存新链表结点的位置
第一步:设置一个cur遍历老链表,每次遍历一个结点就创建一个新的结点,把遍历到的结点值放进新节点中,然后把新老结点放入map中
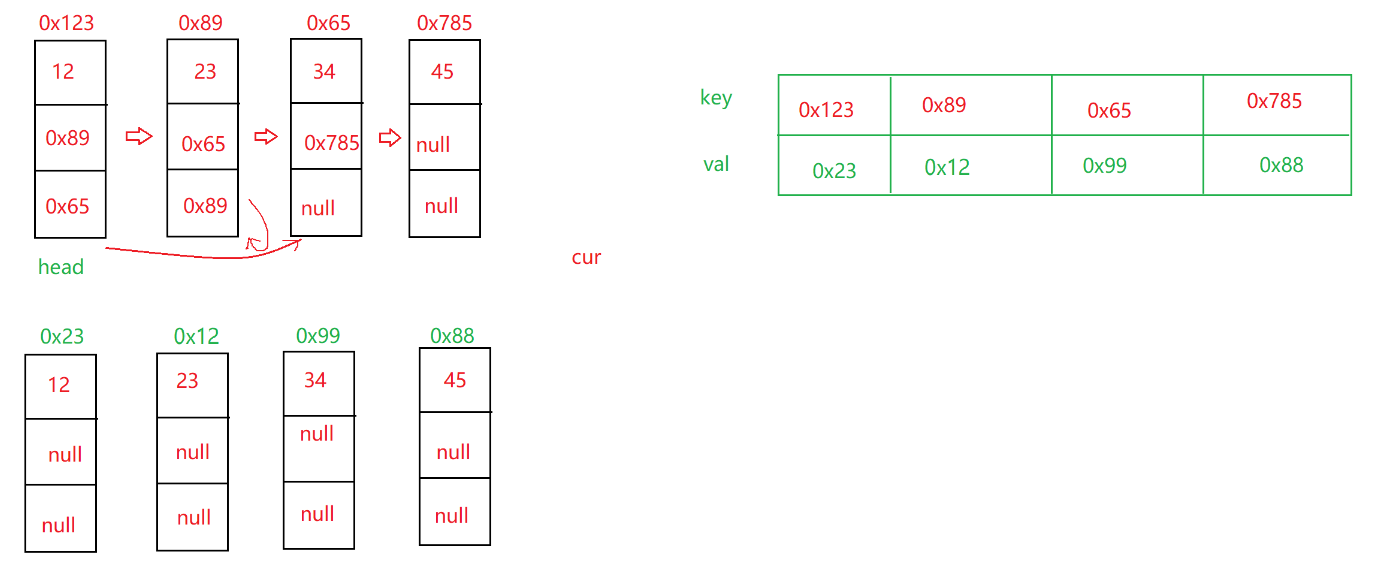
HashMap<Node,Node> map = new HashMap<>();Node cur = head;while(cur != null){Node node = new Node(cur.val);map.put(cur,node);cur = cur.next;}第二步:第二次遍历链表,把next和random的地址给新节点加上
cur遍历到第一个老节点0x123,对应的新节点0x23,新节点0x23的next可以表示为
map.get(cur).next
0x23的next其实相当于第一个老节点0x123下一个结点0x89对应的新节点0x12
所以我们可以创造这样的等式:
map.get(cur).next = map.get(cur.next);
random的获取和next差不多
map.get(cur).random = map.get(cur.random);
cur = head;while(cur!=null){map.get(cur).next = map.get(cur.next);map.get(cur).random = map.get(cur.random);cur = cur.next;}第三步:返回新链表头节点就行了
return map.get(head);
现在来思考一下两个问题:
给你一组数字:1 2 3 3 2
要求:
1.去除重复的数据,重复的数据只保留一份
用set就可以了
public static void main(String[] args) {int[] array = {1,2,3,3,2};HashSet<Integer> set = new HashSet<>();for (int i = 0; i < array.length; i++) {set.add(array[i]);}System.out.println(set);}
2.如何统计每个数字出现几次,比如1 - 1次;2 - 2次;3 - 2次
这道题我们可以用map来做,key用来记录列表里面出现的数字,val用来记录每个数字出现的次数
首先遍历这个列表,如果是第一次存放这个数字x的话,就map.put(x,1)
后面遇到重复数字的时候,用val记录这个数字出现了几次,再map.put(x,val+1)
public static void main(String[] args) {int[] array = {1,2,3,3,2};Map<Integer,Integer> map = new HashMap<>();for(Integer x : array){if(map.get(x) == null){//说明是第一次存放map.put(x,1);}else{//遇到重复数字了Integer val = map.get(x);map.put(x,val+1);}}//遍历整个mapfor(Map.Entry<Integer,Integer> entry :map.entrySet()){System.out.println("key: " + entry.getKey() +" val: " + entry.getValue());}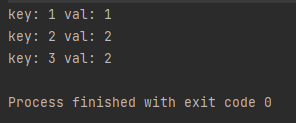
有了上面两道题目的铺垫,我们来看下面这道题
692. 前K个高频单词 - 力扣(LeetCode)
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序排序。
示例 1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2 输出: ["i", "love"] 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。注意,按字母顺序 "i" 在 "love" 之前。
示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4 输出: ["the", "is", "sunny", "day"] 解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,出现次数依次为 4, 3, 2 和 1 次。
第一步:计算每个单词出现的频率,和上面的第二问一样
HashMap<String,Integer> map = new HashMap<>();//1.统计每个单词出现的频率for(String word:words){if(map.get(word) == null){map.put(word,1);}else{Integer val = map.get(word);map.put(word,val+1);}}第二步:建立小根堆,为什么建立小根堆?
1.因为小根堆的话我们可以很快找到前k个频率最小的元素,然后进行逆转就可以满足题目从大到小排序的要求
2.因为建立大根堆之后,当两个单词频率相同时,无法直接将较小字典序的单词放到前面
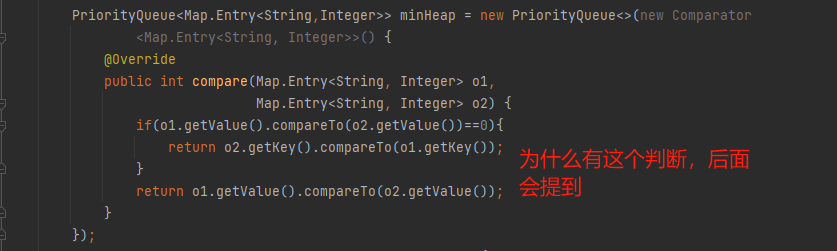
首先创建优先级队列,因为我们要进行map对象进行比较,所以我们需要对compareTo方法进行重写
注意在遍历map的时候, 每个对象转换成Entry<key:String,value:Integer>
for(Map.Entry<String,Integer> entry:map.entrySet()){if(minHeap.size() < k){minHeap.offer(entry);}else{Map.Entry<String,Integer> top = minHeap.peek();if(top.getValue().compareTo(entry.getValue()) < 0){minHeap.poll();minHeap.offer(entry);}else{if(top.getValue().compareTo(entry.getValue()) == 0){if(top.getKey().compareTo(entry.getKey()) > 0){minHeap.poll();minHeap.offer(entry);}}}}}第三步:因为题目要输出从大到小的排列,所以我们要把小根堆里的元素加到数组里然后逆转
List<String> ret = new ArrayList<>();for (int i = 0; i < k; i++) {Map.Entry<String,Integer> top = minHeap.poll();ret.add(top.getKey());}Collections.reverse(ret);return ret;在一开始写代码的时候,我没有在重写comapareTo方法的时候加上这句
if(o1.getValue().compareTo(o2.getValue())==0){return o2.getKey().compareTo(o1.getKey());
}
出现了下面的错误
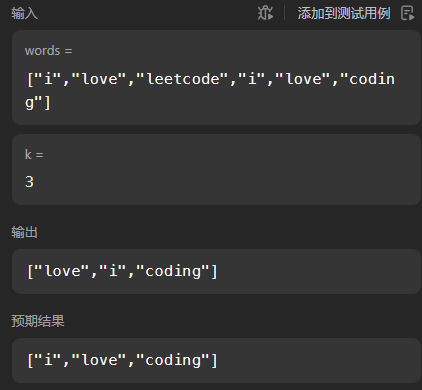
其中love和i都是出现2次,逆转前的ret长这样
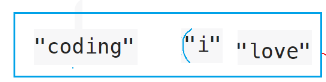
但是正确答案的逆转前数组长这样
这是因为当两个单词频率相同时,题目要求采用字典排序,而l字母排在i之后,在这段代码中需要利用大根堆把l排在i前面,后面逆转的时候整个顺序才是对的