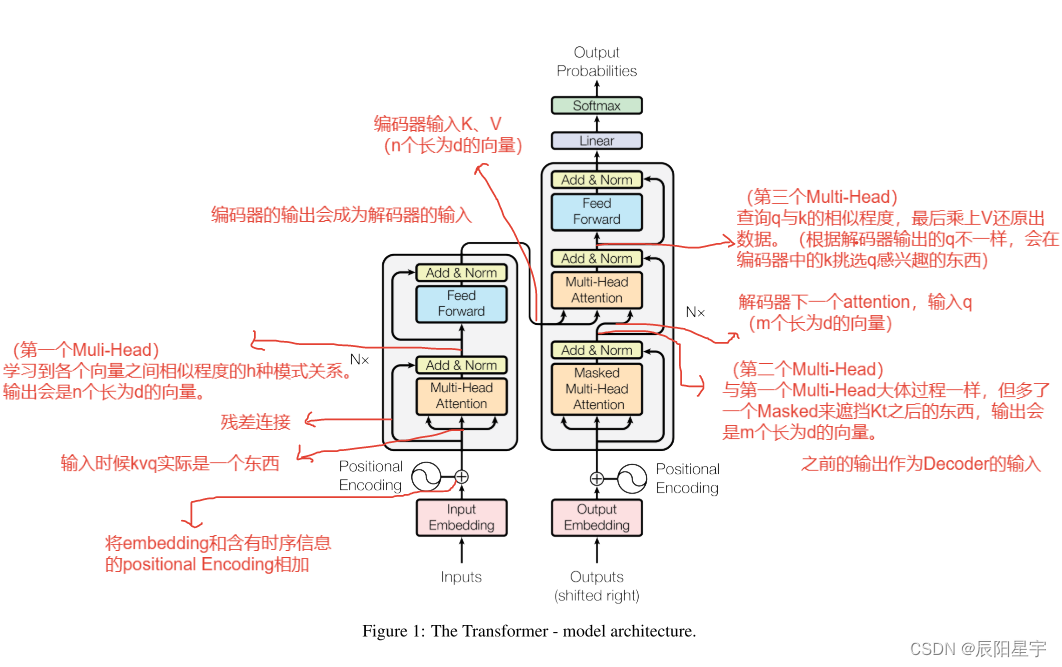
Transformer总架构
在实现完输入部分、编码器、解码器和输出部分之后,就可以封装各个部件为一个完整的实体类了。
【Transformer从零开始代码实现 pytoch版】(一)输入部件:embedding+positionalEncoding
【Transformer从零开始代码实现 pytoch版】(二)Encoder编码器组件:mask + attention + feed forward + add&norm
【Transformer从零开始代码实现 pytoch版】(三)Decoder编码器组件:多头自注意力+多头注意力+全连接层+规范化层
【Transformer从零开始代码实现 pytoch版】(四)输出部件:Linear+softmax
编码器-解码器总结构代码实现
class EncoderDecoder(nn.Module):""" 编码器解码器架构实现、定义了初始化、forward、encode和decode部件"""def __init__(self, encoder, decoder, source_embed, target_embed, generator):""" 传入五大部件参数:param encoder: 编码器:param decoder: 解码器:param source_embed: 源数据embedding函数:param target_embed: 目标数据embedding函数:param generator: 输出部分类被生成器对象"""super(EncoderDecoder, self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = source_embedself.tgt_embed = target_embedself.generator = generator # 生成器后面会专门用到def forward(self, source, target, source_mask, target_mask):""" 构建数据流入流出:param source: 源数据:param target: 目标数据:param source_mask: 源数据掩码张量:param target_mask: 目标数据掩码张量:return:"""# 注意这里先用的encode和decode函数,又才在其函数里面,再用了encoder和decoderreturn self.decode(self.encode(source, source_mask), source_mask, target, target_mask)def encode(self, source, source_mask):""" 编码函数,编码部件:param source: 源数据张量:param source_mask: 源数据的掩码张量:return: 经过解码器的输出"""return self.encoder(self.src_embed(source), source_mask)def decode(self, memory, source_mask, target, target_mask):""" 解码函数,解码部件:param memory:编码器的输出QV:param source_mask:源数据的掩码张量:param target:目标数据:param target_mask:目标数据的掩码张量:return:"""return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
示例
# 输入参数
vocab_size = 1000
size = d_model = 512# 编码器部分
dropout = 0.2
d_ff = 64 # 隐藏层参数
head = 8 # 注意力头数
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
encoder_layer = EncoderLayer(size, c(attn), c(ff), dropout)
encoder_N = 8
encoder = Encoder(encoder_layer, encoder_N)# 解码器部分
dropout = 0.2
d_ff = 64
head = 8
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
decoder_layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)
decoder_N = 8
decoder = Decoder(decoder_layer, decoder_N)# 用了nn的embedding作为输入示意
source_embed = nn.Embedding(vocab_size, d_model)
target_embed = nn.Embedding(vocab_size, d_model)
generator = Generator(d_model, vocab_size)# 输入张量和掩码张量
source = target = torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]])
source_mask = target_mask = torch.zeros(2, 4, 4)# 实例化编码器-解码器,再带入参数实现
ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
ed_res = ed(source, target, source_mask, target_mask)
print(f"ed_res: {ed_res}\n shape:{ed_res.shape}")ed_res: tensor([[[-0.1861, 0.0849, -0.3015, ..., 1.1753, -1.4933, 0.2484],[-0.3626, 1.3383, 0.1739, ..., 1.1304, 2.0266, -0.5929],[ 0.0785, 1.4932, 0.3184, ..., -0.2021, -0.2330, 0.1539],[-0.9703, 1.1944, 0.1763, ..., 0.1586, -0.6066, -0.6147]],[[-0.9216, -0.0309, -0.6490, ..., 1.0177, 0.5574, 0.4873],[-1.4097, 0.6678, -0.6708, ..., 1.1176, 0.1959, -1.2494],[-0.3204, 1.2794, -0.4022, ..., 0.6319, -0.4709, 1.0520],[-1.3238, 1.1470, -0.9943, ..., 0.4026, 1.0911, 0.1327]]],grad_fn=<AddBackward0>)shape:torch.Size([2, 4, 512])
编码器-解码器模型构建函数
def make_model(source_vocab, target_vocab, N=6, d_model=512, d_ff=2048, head=8, dropout=0.1):""" 用于构建模型:param source_vocab: 源数据词汇总数:param target_vocab: 目标词汇总数:param N: 解码器/解码器堆叠层数:param d_model: 词嵌入维度:param d_ff: 前馈全连接层隐藏层维度:param dropout: 置0比率:return: 返回构建编码器-解码器模型"""# 拷贝函数,来保证拷贝的函数彼此之间相互独立,不受干扰c = copy.deepcopy# 实例化多头注意力attn = MultiHeadedAttention(head, d_model)# 实例化全连接层ff = PositionwiseFeedForward(d_model, d_ff, dropout)# 实例化位置编码类,得到对象positionposition = PositionalEncoding(d_model, dropout)model = EncoderDecoder(Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),nn.Sequential(Embedding(d_model, source_vocab), c(position)),nn.Sequential(Embedding(d_model, source_vocab), c(position)),Generator(d_model, target_vocab))# 模型结构构建完成后,初始化模型中的参数for p in model.parameters():# 这里判定当参数维度大于1的时候,则会将其初始化成一个服从均匀分布的矩阵if p.dim() > 1:nn.init.xavier_normal(p) # 生成服从正态分布的数,默认为U(-1, 1),更改第二个参数可以改值return model
示例
source_vocab = target_vocab = 11
N = 6
res = make_model(source_vocab, target_vocab, N)
print(res)EncoderDecoder((encoder): Encoder((layers): ModuleList((0-5): 6 x EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0-3): 4 x Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionwiseFeedForward((w1): Linear(in_features=512, out_features=2048, bias=True)(w2): Linear(in_features=2048, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0-1): 2 x SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False)))))(norm): LayerNorm())(decoder): Decoder((layers): ModuleList((0-5): 6 x DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0-3): 4 x Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(src_attn): MultiHeadedAttention((linears): ModuleList((0-3): 4 x Linear(in_features=512, out_features=512, bias=True))(dropout): Dropout(p=0.1, inplace=False))(feed_forward): PositionwiseFeedForward((w1): Linear(in_features=512, out_features=2048, bias=True)(w2): Linear(in_features=2048, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False))(sublayer): ModuleList((0-2): 3 x SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1, inplace=False)))))(norm): LayerNorm())(src_embed): Sequential((0): Embedding((lut): Embedding(512, 11))(1): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False)))(tgt_embed): Sequential((0): Embedding((lut): Embedding(512, 11))(1): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False)))(generator): Generator((project): Linear(in_features=512, out_features=11, bias=True))
)