一.开发框架:
.NetCore6.0
工具:Visual Studio 2022
二.思路:
1.使用SHA256Hash标识文档转换记录,数据库已经存在对应散列值,则直接返还已经转换过的文档
2.数据库没有对应散列值记录的话,则保存上传PDF文档,并进行文档转换,保留Word
3.转换成功,则在数据库记录对应文档的转换记录,用散列值做标识
三.C#后台包:
1.方法一:Spire.PDF转换包(免费的只能一次转换10页)

2.方法二:iTextSharp包,没有10页转换限制

3.mssql数据库连接包

4.iTextSharp包转换Word文档时,文档格式包

四:C#代码案例:
1.PDF转Word方法:
a.方法一:Spire.PDF包,PDF转Word方法(旧版,有页码限制):
/// <summary>/// PDF文件转化为Word文件/// </summary>/// <param name="pdfFilePath"></param>/// <param name="wordFilePath"></param>public static void ConvertPdfToWord(string pdfFilePath, string wordFilePath){try{Spire.Pdf.PdfDocument pdfDoc = new Spire.Pdf.PdfDocument();pdfDoc.LoadFromFile(pdfFilePath);pdfDoc.SaveToFile(wordFilePath, Spire.Pdf.FileFormat.DOCX);pdfDoc.Close();}catch (Exception ex){Console.WriteLine("Error converting PDF to Word: " + ex.Message);}}
b.iTextSharp包,没有页码限制:
/// <summary>/// iTextSharp库PDF文件转Word文件/// </summary>/// <param name="pdfFilePath"></param>/// <param name="wordFilePath"></param>public static void ConvertPdfToWordByText(string pdfFilePath, string wordFilePath){using (iText.Kernel.Pdf.PdfReader reader = new iText.Kernel.Pdf.PdfReader(pdfFilePath)){using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader)){Spire.Doc.Document doc = new Spire.Doc.Document();for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++){iText.Kernel.Pdf.PdfPage page = pdfDoc.GetPage(i);var strategy = new iText.Kernel.Pdf.Canvas.Parser.Listener.LocationTextExtractionStrategy();PdfCanvasProcessor parser = new PdfCanvasProcessor(strategy);parser.ProcessPageContent(page);string textFromPage = strategy.GetResultantText();var paragraph = doc.AddSection().AddParagraph();paragraph.AppendText(textFromPage);}doc.SaveToFile(wordFilePath, Spire.Doc.FileFormat.Docx);}}}
2.获取文件散列值方法(两种):
a.根据上传文件,获取散列值
/// <summary>/// 根据上传文件获取文件散列值/// </summary>/// <param name="file"></param>/// <returns></returns>public string CalculateSHA256Hash(IFormFile file){try{using (var sha256 = SHA256.Create()){using (var stream = file.OpenReadStream()){byte[] hashBytes = sha256.ComputeHash(stream);string hashString = BitConverter.ToString(hashBytes).Replace("-", String.Empty);return hashString;}}}catch (Exception ex){Console.WriteLine("Error calculating SHA256 hash: " + ex.Message);return null;}}
b.根据文件路径,获取散列值
/// <summary>/// 根据文件路径获取文件散列值/// </summary>/// <param name="filePath"></param>/// <returns></returns>public string CalculateSHA256Hash(string filePath){try{using (FileStream stream = System.IO.File.OpenRead(filePath)){SHA256 sha = SHA256.Create();byte[] hash = sha.ComputeHash(stream);string hashString = BitConverter.ToString(hash).Replace("-", String.Empty);return hashString;}}catch (Exception ex){Console.WriteLine("Error calculating SHA256 hash: " + ex.Message);return null;}}
3.上传PDF文件,转化为Word文件方法:
/// <summary>/// 文件上传/// </summary>/// <returns></returns>public ActionResult UploadFile(){var files = HttpContext.Request.Form.Files;if (files == null || files.Count <= 0){return Json(new { code = -1, msg = "请上传文件!" });}var file = files[0];if (file.ContentType != "application/pdf"){return Json(new { code = -1, msg = "不是PDF文件!" });}var SHA256Hash = CalculateSHA256Hash(file);long fileSize = file.Length;if (new FileConversionBll().ExistsSHA256Hash(SHA256Hash, fileSize)){var model = new FileConversionBll().GetFileBySHA256HashAndSize(SHA256Hash, fileSize);return Json(new { code = 0, msg = "",data = model.WordFilePath }); }else{string fileName = DateTime.Now.ToString("yyyyMMddHHmmssfff");//var filePath = $@"~/File/Pdf/{fileName}";string pdfFilePath = System.IO.Path.Combine("PDF文档路径", fileName + ".pdf");using (var fileStream = new FileStream(pdfFilePath, FileMode.Create)){file.CopyTo(fileStream);}string wordFilePath = System.IO.Path.Combine("Word文档路径", fileName + ".docx");//ConvertPdfToWord(pdfFilePath, wordFilePath);ConvertPdfToWordByText(pdfFilePath, wordFilePath);var res = new FileConversionBll().AddFileConversion(new FileConversion(){PdfFilePath = pdfFilePath,WordFilePath = wordFilePath,PdfSHA256Hash = SHA256Hash,FileSize = fileSize}) ;if (res){return Json(new { code = 0, msg = "",data = wordFilePath });}}return Json(new {code = -2,msg = "出错了!"});}
五.效果图:
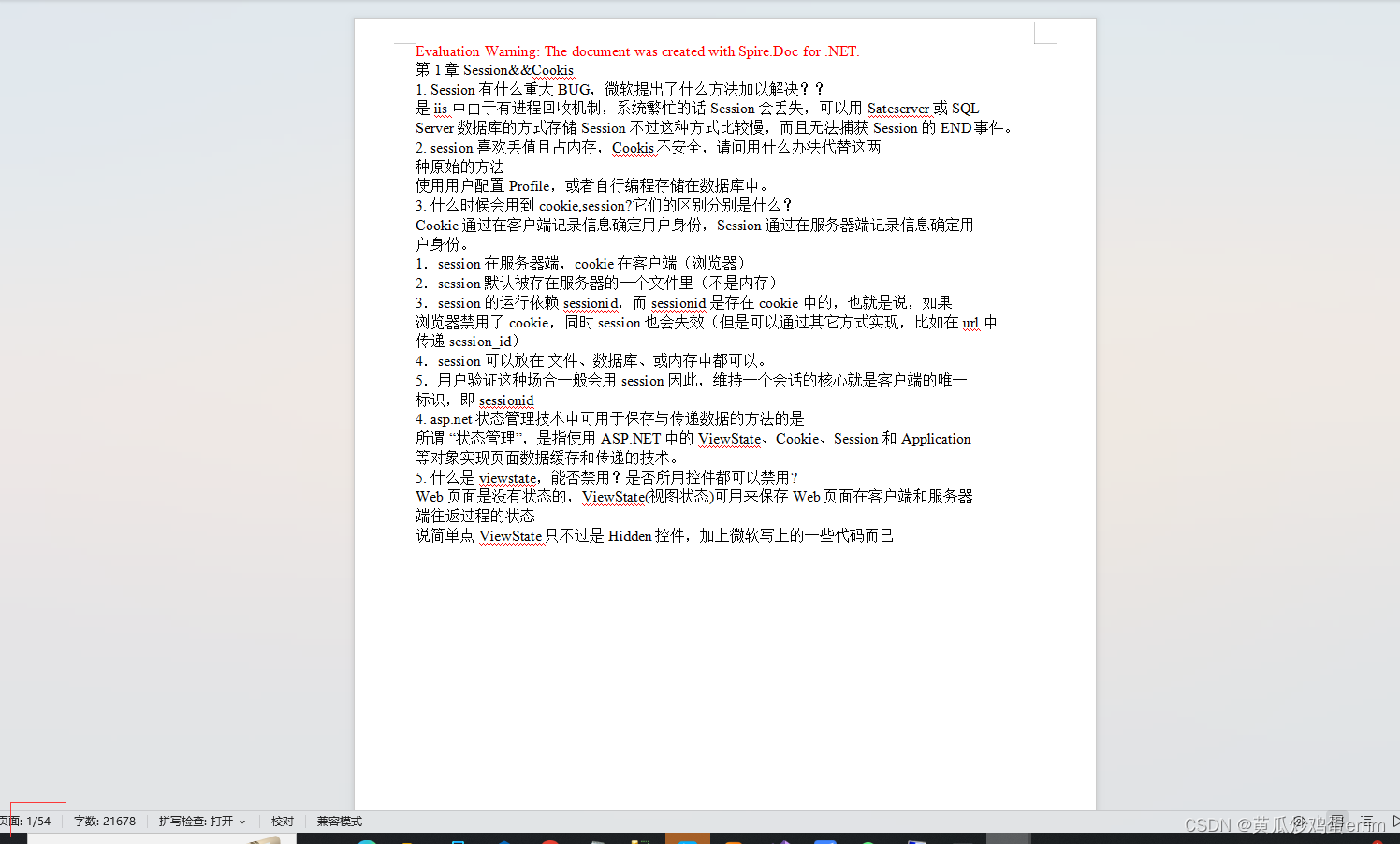
旧版Spire.PDF包,只转化了10页: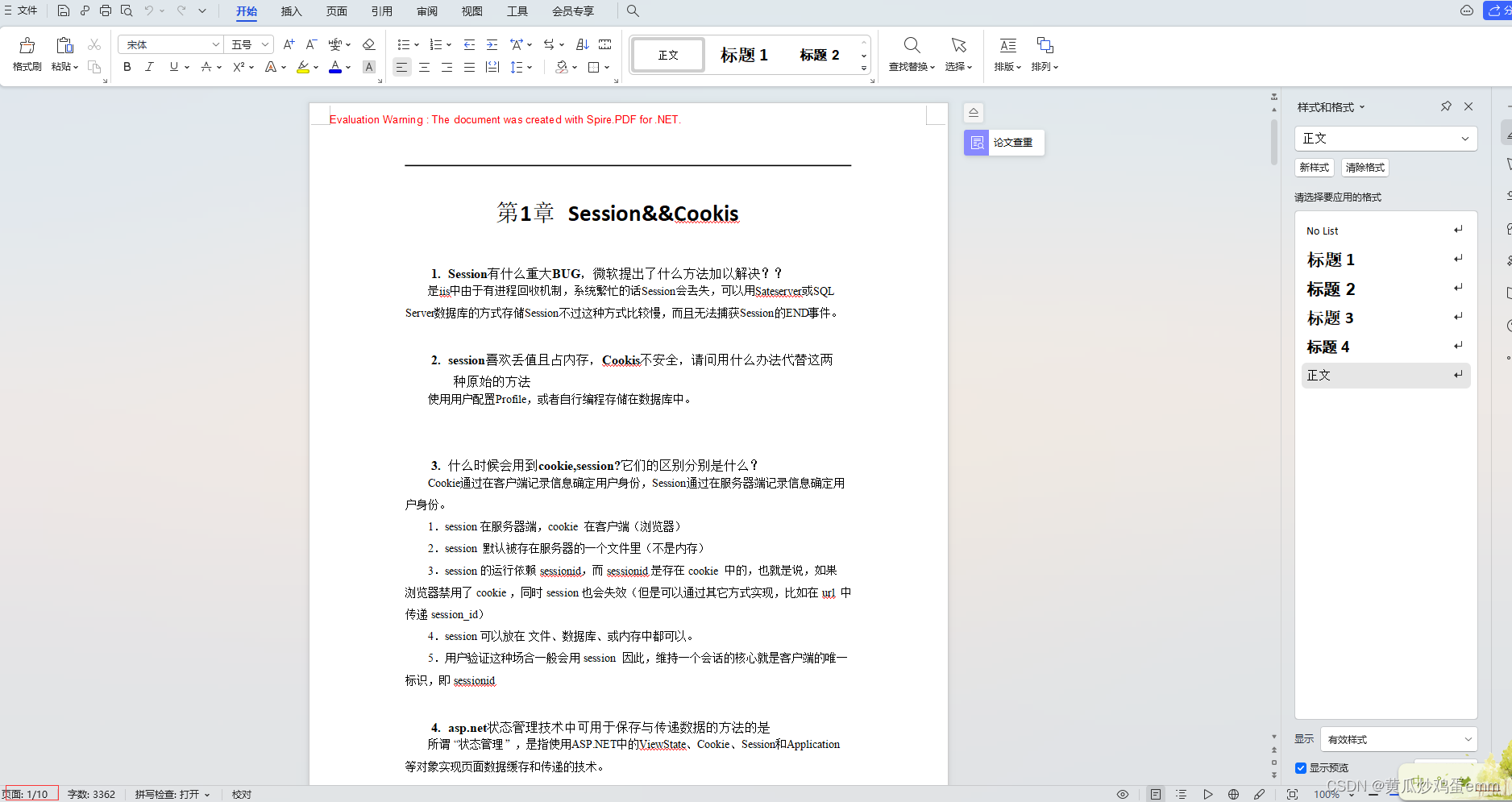
新版iTextSharp包,全部转化完成(但是去除了原本的Word文档格式):


![[数据结构大作业]HBU 河北大学校园导航](https://img-blog.csdnimg.cn/ef03404d3b3d47f7a198b3db1e2e9a59.jpeg)