🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
介绍
ALBERT
1.因式分解参数嵌入
2. 跨层参数共享
3. 句子顺序预测
BERT vs ALBERT
结论
资源
介绍
近年来,大型语言模型的发展突飞猛进。BERT 成为最流行、最高效的模型之一,可以高精度地解决各种 NLP 任务。BERT 之后,一系列其他模型随后出现,也表现出了出色的效果。
显而易见的趋势是,随着时间的推移,大型语言模型 (LLM) 往往会变得更加复杂,因为它们所训练的参数和数据的数量呈指数级增加。深度学习研究表明,此类技术通常会带来更好的结果。不幸的是,机器学习世界已经解决了有关法学硕士的几个问题,可扩展性已成为有效训练、存储和使用它们的主要障碍。
因此,最近开发了新的LLM来解决可扩展性问题。在本文中,我们将讨论 2020 年发明的 ALBERT,其目标是显着减少 BERT 参数。
ALBERT
要了解 ALBERT 的底层机制,我们将参考其官方论文。在很大程度上,ALBERT 源自 BERT 的相同架构。模型架构的选择存在三个主要差异,下面将讨论和解释这些差异。
ALBERT 中的训练和微调过程与 BERT 中的类似。与 BERT 一样,ALBERT 在英语维基百科(2500M 单词)和 BookCorpus(800M 单词)上进行了预训练。
1.因式分解参数嵌入
当输入序列被标记化时,每个标记都会被映射到词汇嵌入之一。这些嵌入用于 BERT 的输入。
令V为词汇量(可能嵌入的总数),H为嵌入维数。然后,对于每个V嵌入,我们需要存储H值,从而生成V x H嵌入矩阵。实践证明,这个矩阵通常尺寸很大,需要大量内存来存储。但一个更普遍的问题是,大多数时候嵌入矩阵的元素是可训练的,并且模型需要大量资源来学习适当的参数。
例如,让我们以 BERT 基础模型为例:它有 30K 个标记的词汇表,每个标记由 768 个组件嵌入表示。总共需要存储和训练 2300 万个权重。对于较大的型号,这个数字甚至更大。
使用矩阵分解可以避免这个问题。原始词汇矩阵V x H可以分解为一对大小为V x E和E x H的较小矩阵。
词汇矩阵分解
因此,分解不会使用O(V x H)参数,而是仅产生O(V x E + E x H)权重。显然,当H >> E时,该方法有效。
矩阵分解的另一个重要方面是它不会改变获取标记嵌入的查找过程:左侧分解矩阵V x E的每一行以与原始相同的简单方式将标记映射到其相应的嵌入矩阵V x H。这样,嵌入的维数从H减少到E。
然而,在分解矩阵的情况下,为了获得 BERT 的输入,需要将映射的嵌入投影到隐藏的 BERT 空间中:这是通过将左矩阵的相应行乘以右矩阵的列来完成的。
2. 跨层参数共享
减少模型参数的方法之一是使它们可共享。这意味着他们都拥有相同的价值观。在大多数情况下,它只是减少了存储权重所需的内存。然而,反向传播或推理等标准算法仍然必须对所有参数执行。
当权重位于模型的不同但相似的块中时,共享权重的最佳方法之一就是发生。将它们放入相似的块中会导致前向传播或反向传播期间可共享参数的大多数计算相同的可能性更高。这为设计高效的计算框架提供了更多机会。
上述想法在 ALBERT 中实现,ALBERT 由一组具有相同结构的 Transformer 块组成,使得参数共享更加高效。事实上,Transformer 中存在多种跨层参数共享的方式:
- 只共享注意力参数;
- 仅共享前向神经网络(FNN)参数;
- 共享所有参数(在 ALBERT 中使用)。
 不同的参数共享策略
不同的参数共享策略
一般来说,可以将所有变压器层划分为 N 个大小为 M 的组,每个组共享其所拥有的层内的参数。研究人员发现,群体规模M越小,结果就越好。然而,减小组大小 M 会导致总参数显着增加。
3. 句子顺序预测
BERT 在预训练时重点关注掌握两个目标:掩码语言建模(MSM)和下一句预测(NSP)。总的来说,MSM 的目的是提高 BERT 获取语言知识的能力,NSP 的目标是提高 BERT 在特定下游任务上的性能。
然而,多项研究表明,与 MLM 相比,摆脱 NSP 目标可能是有益的,主要是因为它的简单性。遵循这个想法,ALBERT 研究人员还决定删除 NSP 任务,并将其替换为句子顺序预测(SOP)问题,其目标是预测两个句子的位置是否正确或相反。
说到训练数据集,输入句子的所有正对都在同一文本段落中按顺序收集(与 BERT 中的方法相同)。对于否定句,除了两个句子的顺序相反之外,原理是相同的。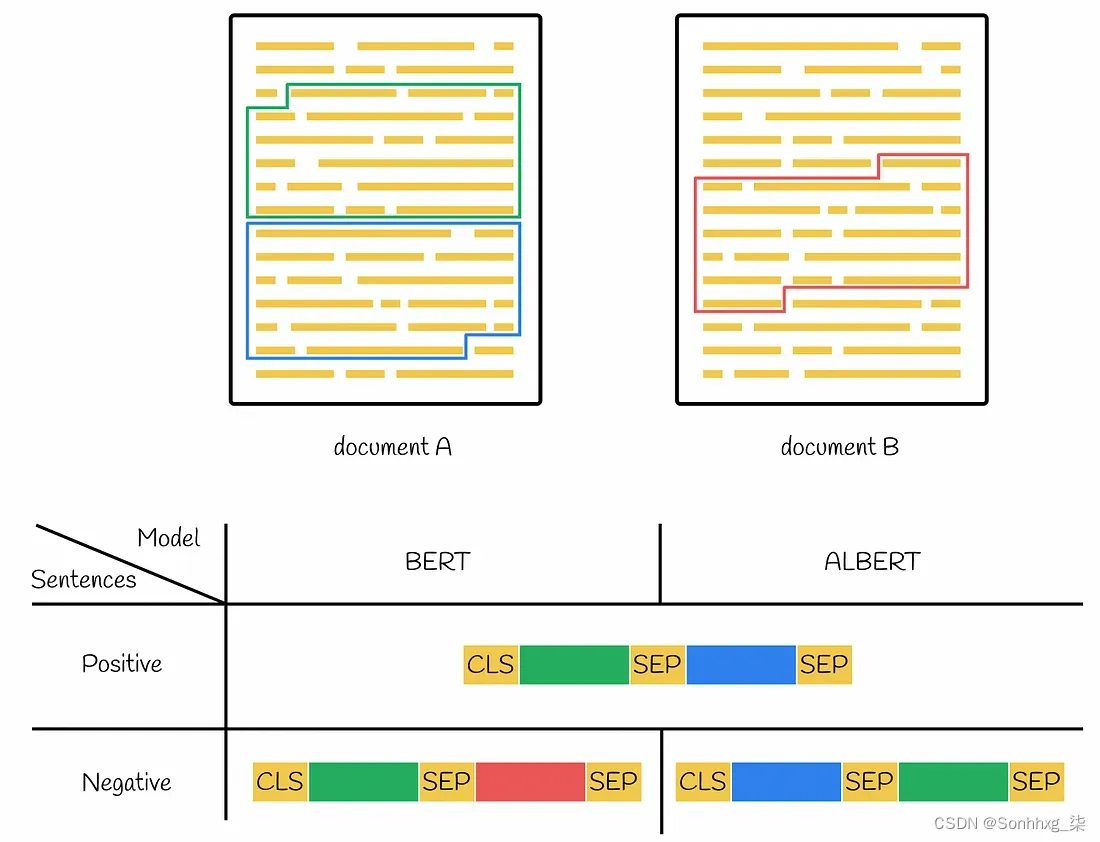
BERT 和 ALBERT 中正负训练对的组成
结果表明,使用 NSP 目标训练的模型无法准确解决 SOP 任务,而使用 SOP 目标训练的模型在 NSP 问题上表现良好。这些实验证明 ALBERT 比 BERT 更适合解决各种下游任务。
BERT vs ALBERT
BERT 和 ALBERT 的详细比较如下图所示。

BERT 和 ALBERT 模型不同变体之间的比较。在相同配置下测量的速度显示了模型迭代训练数据的速度。每个模型的速度值都是相对显示的(以 BERT Large 作为速度等于 1x 的基线)。准确度分数是在 GLUE、SQuAD 和 RACE 基准测试上测量的。
以下是最有趣的观察结果:
- 由于只有 BERT Large 70% 的参数,ALBERT 的 xxlarge 版本在下游任务上取得了更好的性能。
- 与 BERT Large 相比,ALBERT Large 实现了可比的性能,并且由于大量参数大小压缩,速度快了 1.7 倍。
- 所有 ALBERT 模型的嵌入大小均为 128。正如论文中的消融研究所示,这是最佳值。增加嵌入大小(例如增加到 768)可以改进指标,但绝对值不会超过 1%,这与模型复杂性的增加并没有多大关系。
- 尽管 ALBERT xxlarge 处理单次数据迭代的速度比 BERT Large 慢 3.3 倍,但实验表明,如果训练这两个模型相同的时间,则 ALBERT xxlarge 在基准测试中表现出比 BERT Large 更好的平均性能(88.7% vs 87.2%)。
- 实验表明,具有较宽隐藏尺寸(≥ 1024)的 ALBERT 模型并不会从层数的增加中获益匪浅。这就是层数从 ALBERT Large 中的 24 层减少到 xxlarge 版本中的 12 层的原因之一。

ALBERT Large(18M参数)随层数增加的性能。图中≥3层的模型是根据之前模型的检查点进行微调的。可以观察到,达到12层后,性能提升变慢,24层后逐渐下降。
- 随着隐藏层大小的增加,也会出现类似的现象。将其值增加到大于 4096 会降低模型性能。
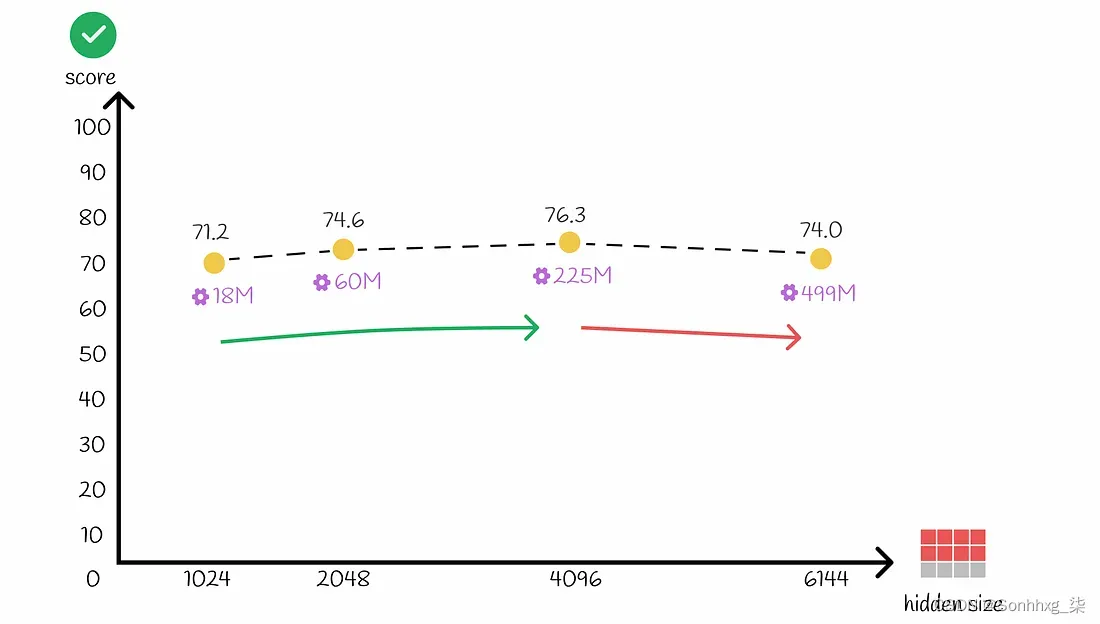
随着隐藏层大小的增加,ALBERT Large(上图中的 3 层配置)的性能。隐藏大小 4096 是最佳值。
结论
乍一看,ALBERT 似乎比原始 BERT 模型更可取,因为它在下游任务上的表现优于它们。然而,由于 ALBERT 的结构较长,因此需要更多的计算。这个问题的一个很好的例子是 ALBERT xxlarge,它有 235M 参数和 12 个编码器层。这些 235M 重量中的大部分属于单个变压器块。然后为 12 层中的每一层共享权重。因此,在训练或推理过程中,算法必须在超过 20 亿个参数上执行!
由于这些原因,ALBERT 更适合解决可以牺牲速度以获得更高准确度的问题。最终,NLP 领域永远不会停止,并且不断向新的优化技术发展。ALBERT 的速度很可能在不久的将来会得到提高。该论文的作者已经提到了稀疏注意力和块注意力等方法作为 ALBERT 加速的潜在算法。
资源
- ALBERT:用于语言表示自监督学习的 Lite BERT