1、安装包下载
elasticsearch
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
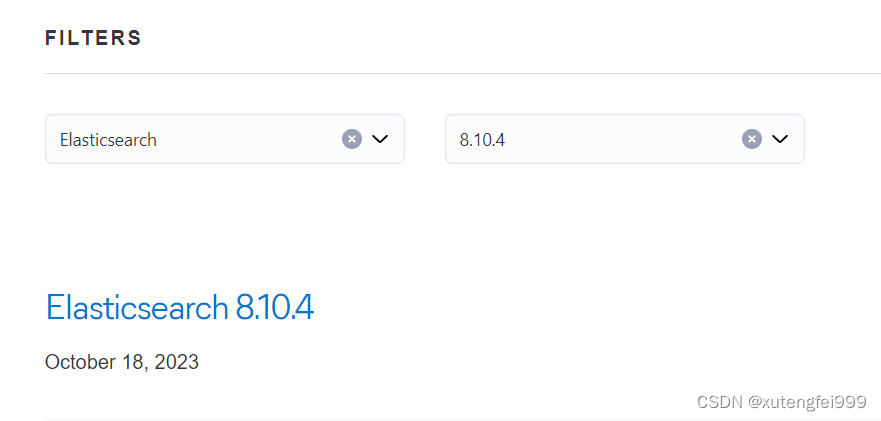
kibana安装包地址:
https://www.elastic.co/cn/downloads/past-releases/kibana-8-10-4

logstash安装包地址:
https://www.elastic.co/cn/downloads/past-releases/logstash-8-10-4

elasticsearch-analysis-ik包下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
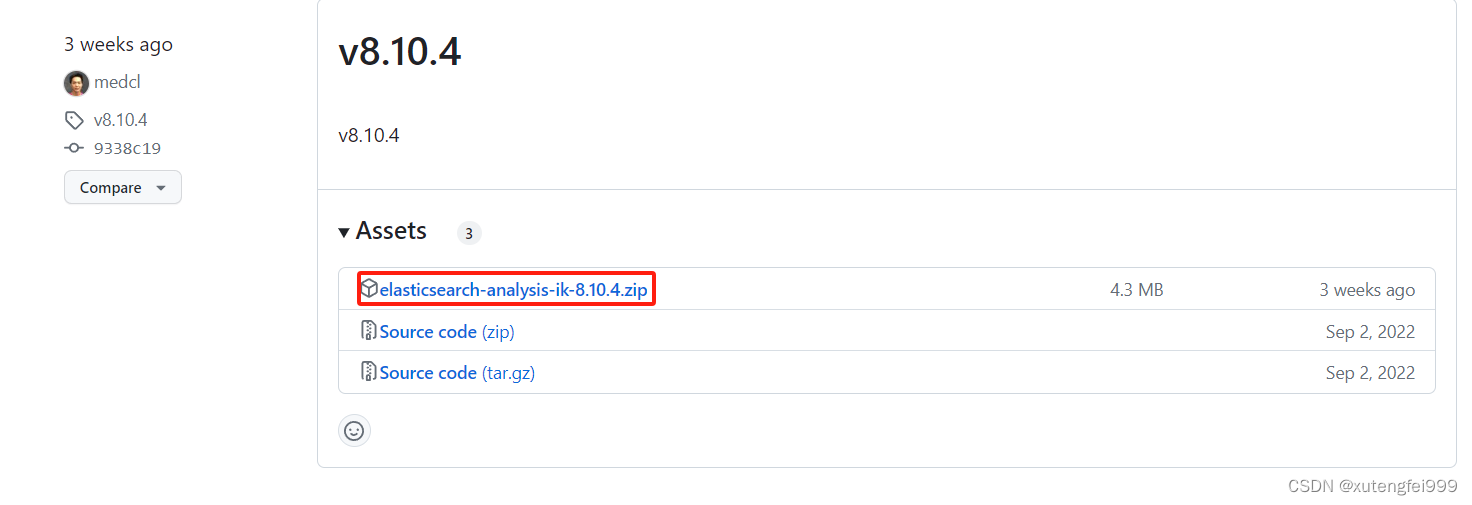
2、解压安装包,并将elasticsearch-analysis-ik-8.10.4目录放到es的plugins目录下
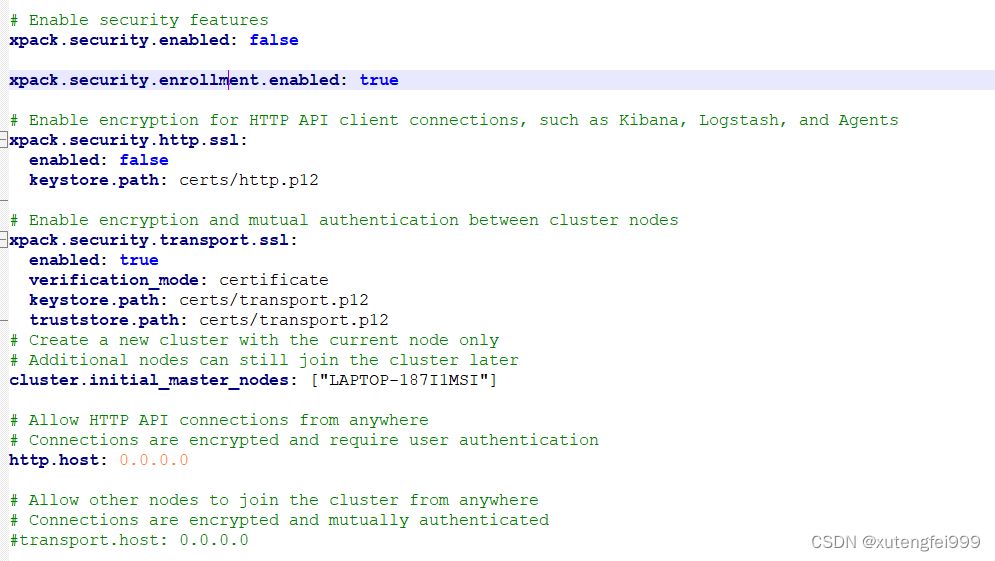
3、修改es的config目录下的elasticsearch.yml
4、在终端启动es,在bin目录下点击elasticsearch.bat
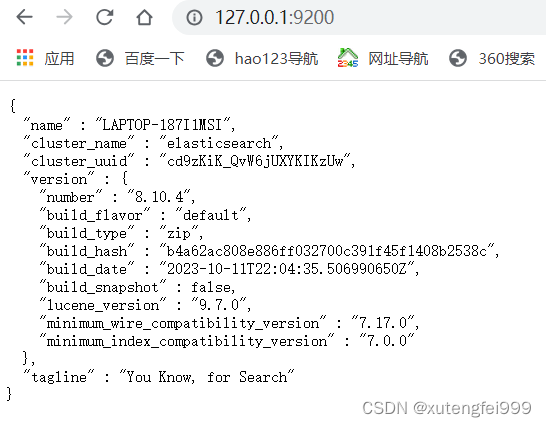
5、在浏览器上查看
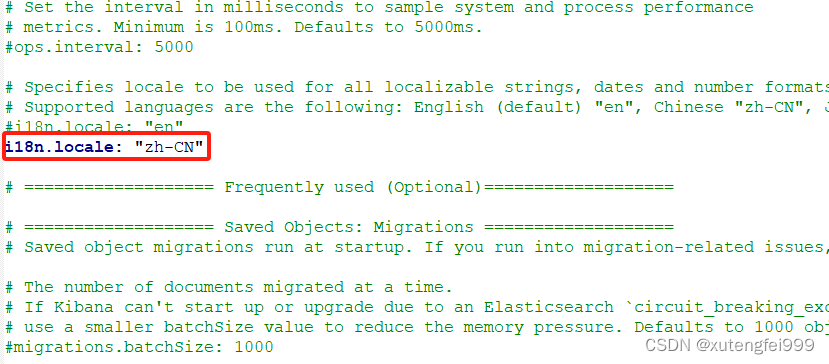
6、设置kibana的中文显示,修改kibana.yml
7、使用logstash进行mysql数据库数据同步到es配置
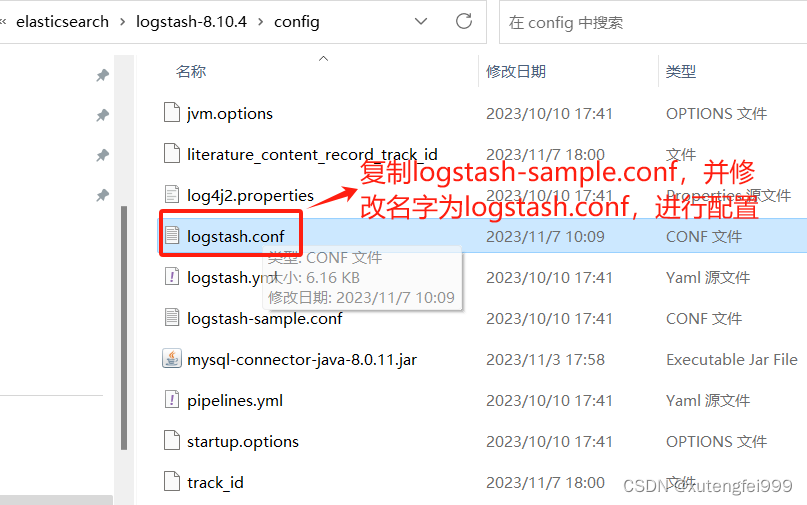
logstash.conf配置
# 连接到mysql数据库
input {
jdbc {
# MySQL JDBC驱动库的路径
jdbc_driver_library => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\mysql-connector-java-8.0.11.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# MySQL数据库的连接字符串
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/main_literature?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
# MySQL数据库的用户名
jdbc_user => "root"
# MySQL数据库的密码
jdbc_password => "****"
# 开启分页
jdbc_paging_enabled => true
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 查询语句
statement => "SELECT * FROM literature_parsing_record WHERE id > :sql_last_value"
# 定时执行的时间间隔,这里设置为每分钟执行一次。含义:分、时、天、月、年
schedule => "* * * * *"
# 定义的类型名称,说明哪个输入到哪个输出类型,与output中的if判断值对应
type => "literature_parsing_record"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到last_run_metadata_path的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\track_id"
# 用于增量同步的字段,如果use_column_value为true,配置本参数,追踪的column名,可以是自增id或时间
tracking_column => "id"
# tracking_colum 对应字段的类型
tracking_column_type => numeric
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 列字段是否都转为小写名称
lowercase_column_names => false
# 设置时区
jdbc_default_timezone =>"Asia/Shanghai"
}
jdbc {
# MySQL JDBC驱动库的路径
jdbc_driver_library => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\mysql-connector-java-8.0.11.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# MySQL数据库的连接字符串
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/main_literature?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
# MySQL数据库的用户名
jdbc_user => "root"
# MySQL数据库的密码
jdbc_password => "*****"
# 开启分页
jdbc_paging_enabled => true
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 查询语句
statement => "SELECT * FROM literature_content_record WHERE id > :sql_last_value"
# 定时执行的时间间隔,这里设置为每分钟执行一次。含义:分、时、天、月、年
schedule => "* * * * *"
# 定义的类型名称,说明哪个输入到哪个输出类型,与output中的if判断值对应
type => "literature_content_record"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到last_run_metadata_path的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\literature_content_record_track_id"
# 用于增量同步的字段,如果use_column_value为true,配置本参数,追踪的column名,可以是自增id或时间
tracking_column => "id"
# tracking_colum 对应字段的类型
tracking_column_type => numeric
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 列字段是否都转为小写名称
lowercase_column_names => false
# 设置时区
jdbc_default_timezone =>"Asia/Shanghai"
}
}
# 过滤数据
filter {
mutate {
# 移除Logstash自动生成的字段
remove_field => ["@version", "@timestamp"]
}
}
# 连接到Elasticsearch
output {
if[type]=="literature_parsing_record" {
elasticsearch {
# Elasticsearch的主机和端口
hosts => ["http://localhost:9200"]
# 写入es的索引名称
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
index => "literature_parsing_record"
# es的文档类型名称,6.x版本可以是一个索引对应多个文档类型,不建议这么做。之后版本只支持一个索引对应一个文档类型
document_type => "doc"
# 使用数据中的id字段作为文档id
document_id => "%{id}"
# 如果使用自己配置的模板,必须配置true
# manage_template => true
#
# template_overwrite => true
# 模板名称,与定义的模板名称对应
# template_name => "literature_parsing_record"
# 使用自定义模板的文件路径,模板用于创建es的索引,决定了索引的创建方式
# template => "/opt/elasticsearch/logstash-6.6.1/template/literature_parsing_record_logstash.json"
#user => "elastic"
#password => "changeme"
}
}
if[type]=="literature_content_record" {
elasticsearch {
# Elasticsearch的主机和端口
hosts => ["http://localhost:9200"]
# 写入es的索引名称
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
index => "literature_content_record"
# es的文档类型名称,6.x版本可以是一个索引对应多个文档类型,不建议这么做。之后版本只支持一个索引对应一个文档类型
document_type => "doc"
# 使用数据中的id字段作为文档id
document_id => "%{id}"
# 如果使用自己配置的模板,必须配置true
# manage_template => true
#
# template_overwrite => true
# 模板名称,与定义的模板名称对应
# template_name => "literature_content_record"
# 使用自定义模板的文件路径,模板用于创建es的索引,决定了索引的创建方式
# template => "/opt/elasticsearch/logstash-6.6.1/template/literature_content_record_logstash.json"
#user => "elastic"
#password => "changeme"
}
}
stdout {
codec => json_lines
}
}
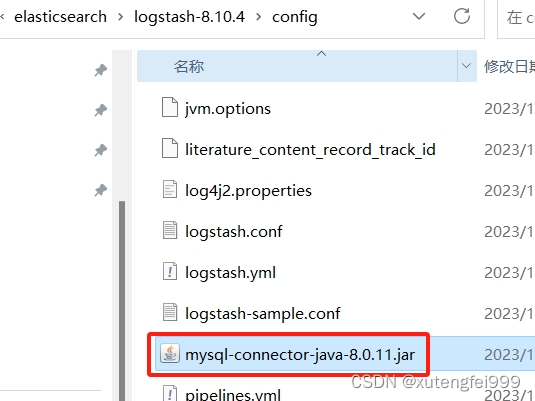
8.下载mysql-connector-java-8.0.11.jar,放到配置的路径下
9、在终端启动logstash就可以进行数据同步了
logstash -f D:\soft\third_soft\elasticsearch\logstash-8.10.4\config\logstash.conf
10、在bin目录下启动kibana
11、点击开发工具查看

12、查看es中的数据