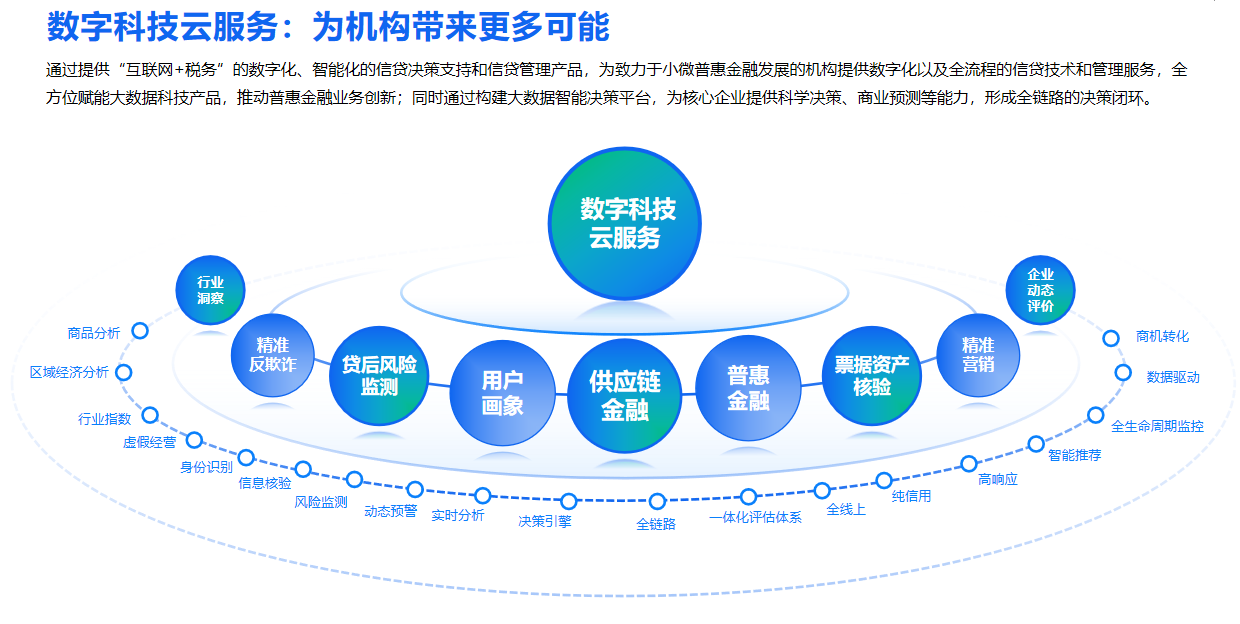
指令调优(IT),一种针对大型语言模型(LLMs)的训练方法,是提高大型语言模型能力和可控性的关键技术。该方法的核心目标是使LLM具备遵循自然语言指令并完成现实世界任务的能力。它弥补了LLM的下一个单词预测目标与用户让LLM遵循人类指令的目标之间的差距,约束了模型的输出,使其符合预期的响应特征或领域知识。
随着计算机技术的发展,指令调优在一些需要执行特定任务的场景上,如机器翻译、问答系统等,都有着广泛的应用前景。
为帮助大家理解并掌握IT,我这次整理了18种指令调优方法,包含指令微调LLMs、多模态指令微调两个方向,每个方法的原文及模型源码也都整理了,需要的同学看文末
指令微调LLMs
1.InstructGPT
论文:Training language models to follow instructions with human feedback
通过人类反馈训练语言模型遵循指令
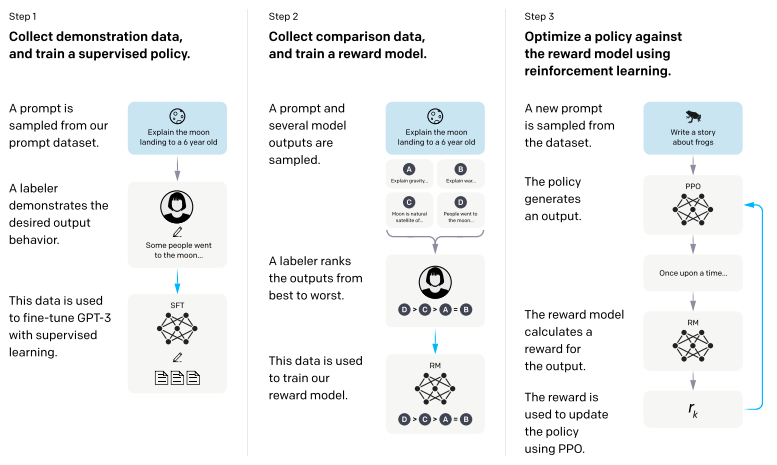
简述:本文提出一种通过人类反馈微调语言模型的方法,使其与用户意图对齐。作者收集了标注者演示所需行为的数据集和模型输出排名的数据集,微调GPT-3得到InstructGPT模型。在人机评估中,1.3B参数的InstructGPT模型比175B GPT-3更受青睐,同时减少了输出不真实和有害的情况,性能下降不大。
2.BLOOMZ
论文:Crosslingual Generalization through Multitask Finetuning
跨语言泛化通过多任务微调实现
简述:本文将多任务微调应用于预训练的多语言BLOOM和mT5模型族,生成了名为BLOOMZ和mT0的微调变体。研究发现,在英语任务上微调大型多语言语言模型并使用英文提示可以使模型泛化到非英语语言的任务中。在多语言任务上使用英文提示进行微调进一步提高了性能,实现了各种最先进的零样本结果。

3.FLAN-T5
论文:Scaling Instruction-Finetuned Language Models
缩放指令微调语言模型
简述:本文研究了在一系列指令性数据集中微调语言模型的效果,并发现这可以提高模型性能和对未见过的任务的泛化能力。作者特别关注三个方面:扩展任务数量、扩大模型规模、在思维链数据上进行微调。研究发现,在这些方面进行指令微调可以显著提高各种模型类别、提示设置和评估基准的性能。例如,Flan-PaLM 540B在1.8K个任务上进行了指令微调,比PaLM 540B高出很多(平均+9.4%)。作者还公开发布了Flan-T5检查点,它在少样本性能方面表现强劲,甚至与更大的模型相比也毫不逊色。

4.Alpaca
论文:Alpaca: A Strong, Replicable Instruction-Following Model
一种强大、可复制的指令跟随模型
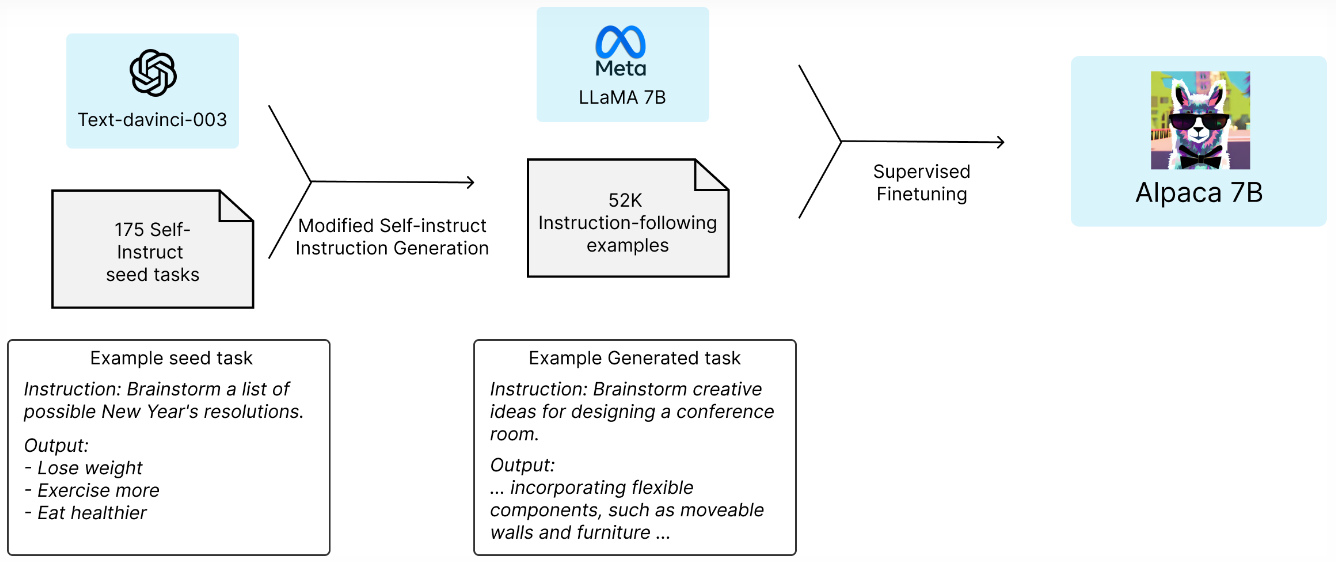
简述:指令跟随模型越来越强大,但仍然存在许多缺陷。为了解决这些问题,研究人员发布了一种名为Alpaca的指令跟随语言模型,它是基于Meta的LLaMA 7B模型微调而来的。该模型在52K个以text-davinci-003的自我指导风格生成的指令跟随演示上进行了训练。
5.Vicuna
项目:Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Qualit
一个开源聊天机器人,以90%的ChatGPT质量给GPT-4留下深刻印象
简述:LMSYS介绍了开源聊天机器人Vicuna-13B,它是通过在ShareGPT上收集的用户共享对话中微调LLaMA进行训练的。初步评估使用GPT-4作为评判标准显示,Vicuna-13B实现了超过90%*的OpenAI ChatGPT和Google Bard的质量,并在超过90%*的情况下优于其他模型,如LLaMA和斯坦福Alpaca。
6.GPT-4-LLM
论文:Instruction tuning with gpt-4
使用GPT-4进行指令调优
简述:本文介绍了使用GPT-4生成指令跟随数据来微调大型语言模型(LLMs)的首次尝试。早期的实验表明,使用GPT-4生成的52K英文和中文指令跟随数据比先前最先进的模型生成的指令跟随数据在全新任务上表现出更出色的零样本性能。作者还收集了来自GPT-4的反馈和比较数据,以实现全面的评估和奖励模型训练。

7.WizardLM
论文:WizardLM: Empowering Large Language Models to Follow Complex Instructions
赋予大型语言模型遵循复杂指令的能力
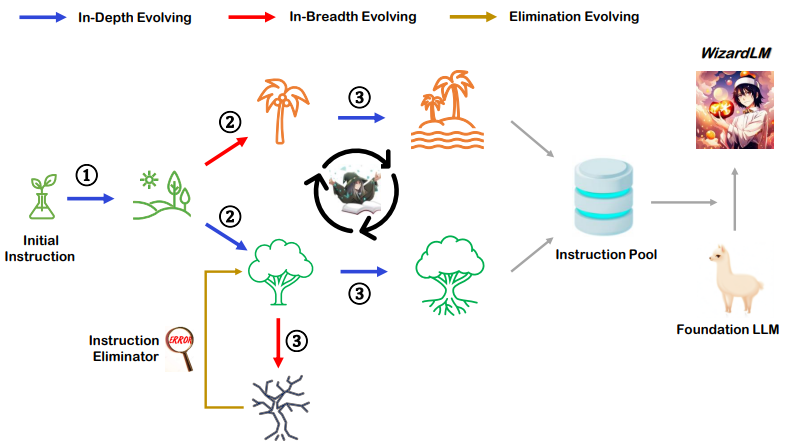
简述:本文提出了一种使用大型语言模型(LLM)生成指令数据的方法,以代替人工创建。通过逐步将初始指令重写为更复杂的指令,并将所有生成的指令数据混合到一起微调LLaMA,得到的结果被称为WizardLM。在人类评估和GPT-4自动评估中,WizardLM表现出比ChatGPT更好的能力。
8.LIMA
论文:Lima: Less is more for alignment
对齐时,少即是多
简述:本文介绍了一种使用大型语言模型(LLM)进行训练的方法,分为无监督预训练和大规模指令微调两个阶段。作者通过训练LIMA来证明,在有监督损失微调中,只需要少量示例即可让LLM学习到高质量的输出。LIMA表现出非常出色的性能,能够遵循特定的响应格式,并泛化到未见过的任务上。
9.OPT-IML
论文:OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
通过泛化的视角扩展语言模型指令元学习
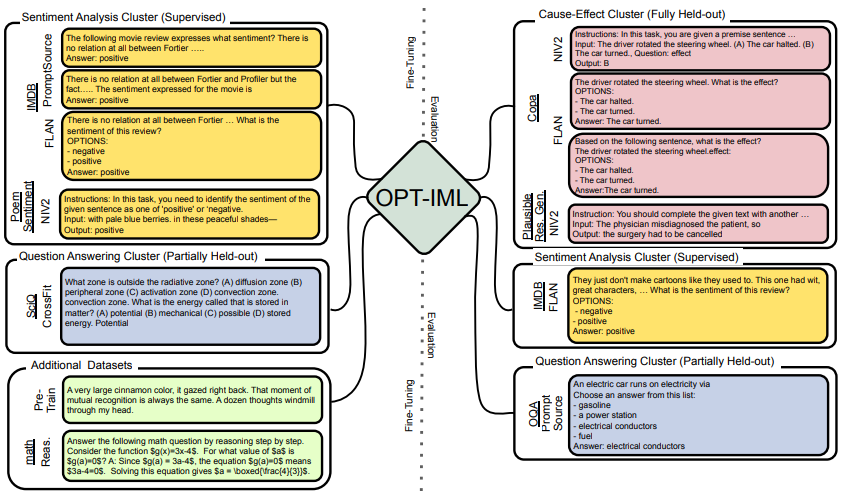
简述:论文提出了一种使用大型预训练语言模型进行指令元学习的方法,通过扩展模型和基准规模来提高其在未见过的任务上的泛化能力。作者创建了一个包含2000个NLP任务的大型基准测试集,并展示了在不同指令微调决策下的应用效果。通过这个框架,作者训练了OPT-IML 30B和175B,这两个模型是OPT的指令微调版本,并在四个不同的评估基准测试集上表现出了很好的性能。
10.Dolly 2.0
项目:Free dolly: Introducing the world’s first truly open instruction-tuned llm
介绍世界上第一个真正开放的指令调优LLM
简述:Dolly 2.0 是第一个开源的、指令遵循的、120亿参数的语言模型,完全基于EleutherAI pythia模型系列进行微调,并专门使用了一个新的、高质量的人工生成指令遵循数据集,该数据集是在Databricks员工中进行众包收集的。
11.Tülu
论文:How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
探索开放资源上的指令调优状态
简述:本文研究了在一系列开放指令遵循数据集上进行指令调优的语言模型的最新进展,提供了一组从67亿到650亿参数规模的指令调优模型,并使用自动、基于模型和基于人类的指标对其进行了评估。实验表明,不同的指令调优数据集可以发现或增强特定的技能,但没有单个数据集(或组合)在所有评估中提供最佳性能。作者还介绍了Tülu,这是在高质量的开放资源组合上微调的最佳表现的指令调优模型套件。
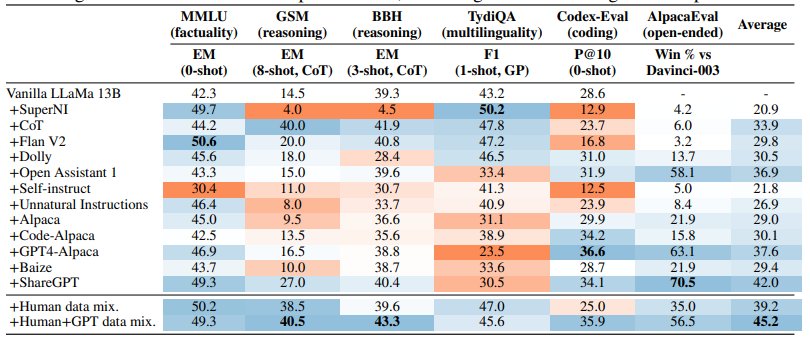
12.UltraLM
论文:Enhancing chat language models by scaling high-quality instructional conversations
通过扩展高质量的指导性对话来增强聊天语言模型
简述:作者提供了一个多样化、信息量大的指导性对话数据集UltraChat,并基于该数据集微调了一个强大的对话模型UltraLLaMA。评估结果表明,UltraLLaMA优于其他开源模型。
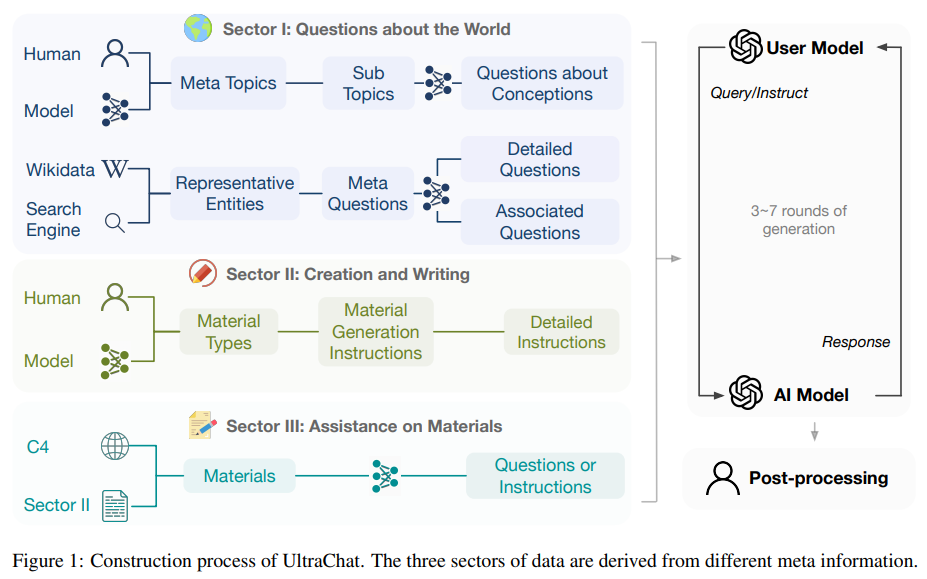
多模态指令微调
1.InstructPix2Pix
论文:Instructpix2pix: Learning to follow image editing instructions
学习遵循图像编辑指令
简述:本文提出了一种根据人类指令快速编辑图像的方法。作者结合了两个大型预训练模型的知识来生成大量的图像编辑示例数据集,并使用这个数据集训练了一个新的条件扩散模型InstructPix2Pix。该模型可以在几秒钟内快速编辑图像,并在推理时推广到真实图像和用户编写的指令。

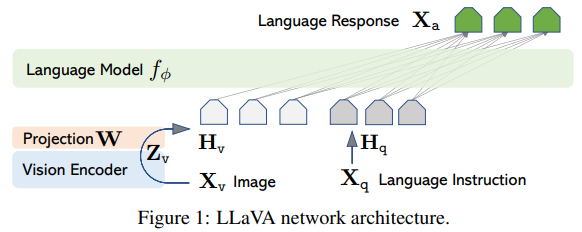
2.LLaVA
论文:Visual instruction tuning
可视化指令调优
简述:本文介绍了一种使用语言模型生成多模态语言-图像指令遵循数据的可视化指令调优方法,以改善新任务的零样本能力。作者首次尝试使用只有语言的GPT-4来生成多模态语言-图像指令遵循数据,并通过这种生成的数据进行指令调优,引入了LLaVA。LLaVA是一个端到端训练的大型多模态模型,将视觉编码器和LLM连接起来,用于通用的视觉和语言理解。
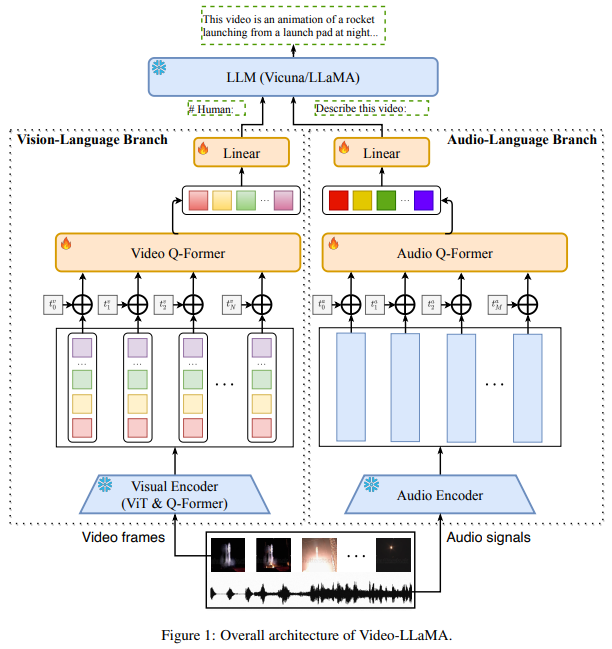
3.Video-LLaMA
论文:Video-llama: An instruction-tuned audio-visual language model for video understanding
一种用于视频理解的指令调优的视听语言模型
简述:论文提出了一种多模态框架Video-LLaMA,可让大型语言模型理解视频中的视觉和听觉内容。该模型从冻结的预训练视觉和音频编码器以及冻结的LLMs开始进行跨模态训练,解决了捕捉视觉场景中的时间变化和整合视听信号两个挑战。作者还提出了一个Video Q-former来将预训练的图像编码器组装到视频编码器中,并引入了一个视频到文本生成任务来学习视频-语言对应关系。
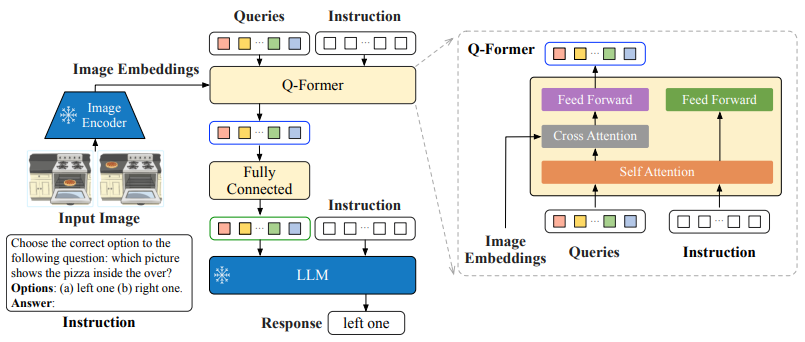
4.InstructBLIP
论文:Instructblip: Towards general-purpose visionlanguage models with instruction tuning
通过指令调优实现通用视觉语言模型
简述:本文介绍了一种通用视觉语言模型InstructBLIP,通过大规模的预训练和指令调优实现了广泛的能力。作者使用26个公开可用的数据集进行训练,引入了一种指令感知的查询转换器来提取相关信息特征。在13个持有数据集中进行训练后,InstructBLIP在所有测试集上都达到了最先进的零样本性能,显著优于其他模型。在单个下游任务上进行微调时,InstructBLIP也取得了很好的性能。
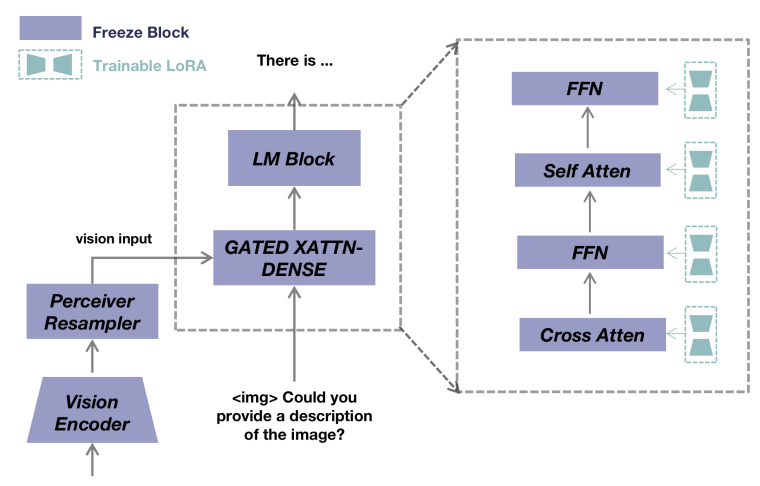
5.Otter
论文:Otter: A multi-modal model with in-context instruction tuning
一种具有上下文指令调优的多模态模型
简述:本文介绍了多模态模型Otter,它基于DeepMind的Flamingo模型并通过上下文指令调优进行了训练。作者使用类似的方式构建了MultI-Modal In-Context Instruction Tuning(MIMIC-IT)数据集,并展示了Otter在遵循指令和上下文学习方面的优秀能力。

6.MultiModal-GPT
论文:Multimodal-gpt: A vision and language model for dialogue with humans
一种用于与人类对话的视觉和语言模型
简述:本文介绍了一种名为MultiModal-GPT的视觉和语言模型,用于与人类进行多轮对话。该模型可以从人类那里遵循各种指令,例如生成详细的描述、计算感兴趣的对象数量以及回答用户提出的一般问题。作者使用视觉和语言数据构建了多模态指令调优的指令模板,以使模型能够理解和遵循人类的指令。作者还利用仅语言指令跟随数据对MultiModal-GPT进行联合训练,有效地提高了对话性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“指令调优”领取全部论文及模型源码
码字不易,欢迎大家点赞评论收藏!