前言
今天实在不知道学点什么好了,早上学了3个多小时的 Flink ,整天只学一门技术是很容易丧失兴趣的。那就学点新的东西 Flume,虽然 Kafka 还没学完,但是大数据生态圈的基础组件也基本就剩这倆了。
Flume 概述
生产环境中的数据一般都是用户在客户端的一些行为操作形成的日志,一般操作日志都会先存到服务器,而不是直接就存到 HDFS 当中去。那么如何把服务器中的日志数据传输到 HDFS 中呢?这就需要一个采集功能。
大数据主要解决的三大问题:采集、存储和计算。我们大数据框架也正是围绕着这这三大问题,此外还有一些工具框架,比如 Azkaban ,它是一个任务调度框架。类似我们 linux 中 crontab 命令,可以帮我们定时地执行任务。但是 Linux 中的 crontab 不能完全胜任生产中的需求,比如依赖管理,crontab无法处理任务之间的依赖关系。如果你有一系列的任务需要按照一定的顺序执行,crontab可能不是最好的选择。此外 Azkaban 提供了更多专业的功能,比如工作流管理、可视化界面以及故障处理和告警等。
Flume 官方文档地址:Flume 1.11.0 User Guide — Apache Flume
1、Flume 定义
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
这里的分布式的概念不同于 hadoop ,这里的分布式指的是它可以从分布式的各个节点的日志数据收集起来,而不是说 Flume 需要搭建一个分布式的集群环境。
这里的日志指的是文本数据,而视频、音频、ppt这种数据是不能够传输的。
Flume 是动态地传输数据(实时),你上传一条它就传输一条。
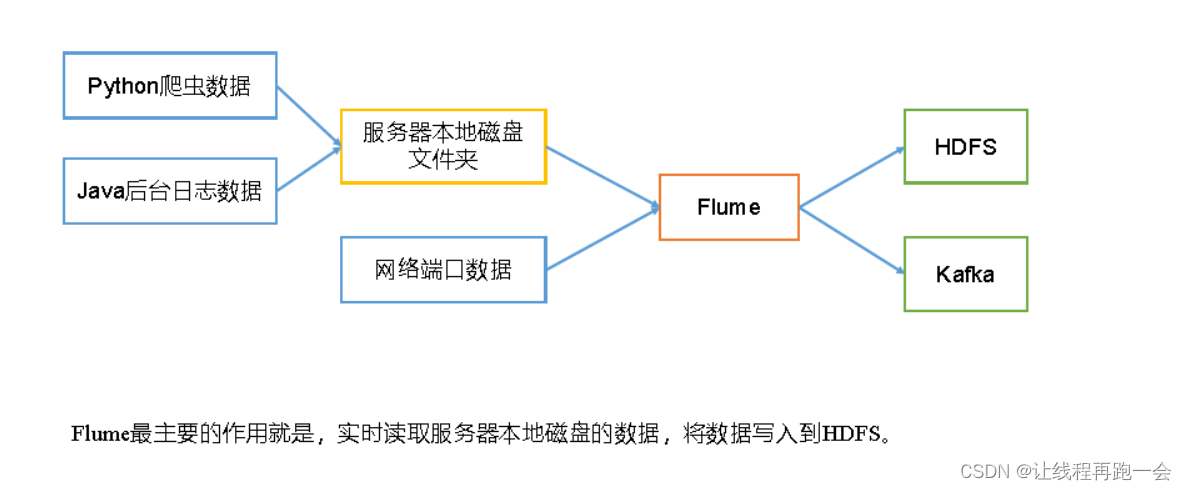
对于服务器本地磁盘中的数据,既然我们可以使用 hadoop fs -put 命令来直接上传到 HDFS 为什么还要使用 Flume 呢?
因为 Flume 是实时的!
2、Flume 基础架构
这里 flume 官网的一个架构图:

2.1、Agent
Flume agent 是一个 JVM(Java 虚拟机)进程,它以事件的形式将数据从一个外部源传递到下一个目的地(hop)。
Agent 由 3个部分组成,Source、Channel、Sink。
2.2、Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、 taildir 、sequence generator、syslog、http、legacy。
2.3、Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
2.4、Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
比如我们的 Source 接受日志数据的速度和 Sink 往下游发送数据的速度不对等,那么这就需要一个缓冲区来暂时存储我们的数据。
Flume自带两种Channel:Memory Channel (内存,速度快但不安全)和 File Channel(磁盘,速度慢但安全)。
Memory Channel 是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
2.5、Event
Event 是Flume 的传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。
Event 由 Header 和 Body 两部分组成,Header 用来存放该event的一些属性,为K-V结构;Body 用来存放该条数据,形式为字节数组。
Flume 入门案例
1、监控端口数据打印到控制台
这是 flume 官网的一个案例。
1、案例需求:
使用Flume监听一个端口,收集该端口数据,并打印到控制台。
2、需求分析:
- 通过 netcat 工具向本机的 4444 端口发送数据
- Flume 监听本机的 4444 端口,并使用 Source 收集数据
- Flume 通过 Sink(这里用 logSink只做打印,如果要上传HDFS 可以使用 hdfsSink) 直接打印到控制台
3、实现步骤
(1)安装 netcat
yum -y install nc(2)判断端口是否被占用
sudo netstat -nlp | grep 44444(3)创建Flume Agent配置文件flume-netcat-logger.conf
我们先在 flume 目录下创建 job目录
touch netcat-flume-logger.conf# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# source 配置
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# sink 配置
a1.sinks.k1.type = logger # 输出到控制台# channel 配置: 这里使用是 memory channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000 # 事件容量
a1.channels.c1.transactionCapacity = 100 # 事务容量(单个事务最大的发送容量,收集到100个事件再去提交事务,事务容量必须<事件容量,事务的作用是保证数据不丢失,回滚)# 绑定 source 和 sink 到 channel
a1.sources.r1.channels = c1 # 将source 和 channel绑定起来(一个source可以绑定多个channel)
a1.sinks.k1.channel = c1 #将 sink 和 channel 绑定起来(一个sink只能绑定一个channel)(4) 开启 flume 监听端口
bin/flume-ng agent -n a1 -c conf/ -f job/netcat-flume-logger.conf -Dflume.root.logger=INFO,console(5)使用netcat工具向本机的44444端口发送内容
nc localhost 44444
>hello
>flume
>flink
>spark(6)在 flume 窗口查看
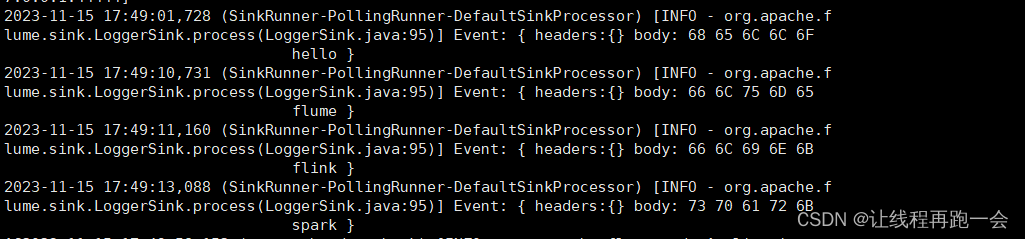
2、实时监控单个追加文件
抽时间更新

![半平面求交 - 洛谷 - P3194 [HNOI2008] 水平可见直线](https://img-blog.csdnimg.cn/2020121310235323.png#pic_center)