本科大三的时候,打过一次美赛,当时租了一个民宿,和队友一起度过了专注的四天。当时比赛结束之后,拿着手机,看到四天没回的消息,四天没刷过的朋友圈,有种很新奇的感觉,谢谢美赛给了我消失的自由。
入学后,九月的时候,师姐邀请室友和我打华为杯。美赛的时候,我是论文手,感觉收获不大,不止一次后悔过为什么不平时多敲点代码,争取当编程手,或者辅助编程手。一年半中,我确实看了或敲了不少代码,这次比赛我主动请缨想写代码。嗯,还是建模写代码有意思多了。
由于我和室友周一周二有课,所以我们一开始就确定下来,要早点确定选题,并争取前三天周五到周日的时候,把题目做完。22号早上,我八点就守到电脑前准备接收赛题了,但是网络拥堵,八点二十队长才把赛题下载下来,上午经过简单的讨论,我们和一开始计划的一样,选了确保我们能够做出来的,预测类的数据分析题E题。
我和队长一起负责建模和编程,我们会一起讨论每道题的做题思路,然后每个人依次负责下一道需要做的题。在这里我们分享一下我主要负责的题1b,2b,2d和3b的思路。
1b)请以是否发生血肿扩张事件为目标变量,基于“表1” 前100例患者(sub001至sub100)的个人史,疾病史,发病及治疗相关特征(字段E至W)、“表2”中其影像检查结果(字段C至X)及“表3”其影像检查结果(字段C至AG,注:只可包含对应患者首次影像检查记录)等变量,构建模型预测所有患者(sub001至sub160)发生血肿扩张的概率。
注:该问只可纳入患者首次影像检查信息。
这道题需要用到1a的结果作为label,利用题目中指定的表1,2,3的特征做预测。表1是个人史和疾病史,一共给定的二十列中有17列都是0,1表示的二分类离散变量,表2(血肿的位置分布),表3(血肿的形状、颜色)是高维离散数据。题目一共只给了160个样本,并且只有100个是训练样本。针对本题数据小样本高维度的特点,我选择先对连续变量使用PCA降维。对于离散数据和连续数据使用两个不同的模型训练后集成起来。最后,离散数据选择的是l1正则项的逻辑回归,连续数据选择的是随机森林。
import pandas as pd
from sklearn.decomposition import PCA
#主成分分析降维及数量选择.import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler# 数据缩放
scaler = StandardScaler()
X_2_scaled = scaler.fit_transform(X_2)# 使用PCA降维
pca = PCA()
data_pca = pca.fit_transform(X_2_scaled)# 设定阈值
threshold = 0.98# 计算主成分数量
explained_variance_ratio = pca.explained_variance_ratio_.cumsum()
n_components = (explained_variance_ratio < threshold).sum() + 1# 输出信息
print("Variance Threshold: ", threshold)
print("Number of Principal Components: ", n_components)# 得到降维后的数据
X_2_reduced = data_pca[:, :n_components]#模型训练及预测#交叉验证训练单模型
import xgboost as xgb
from sklearn.linear_model import LogisticRegressionscaler = StandardScaler()model = xgb.XGBClassifier()
model = LogisticRegression(penalty='l1', solver='liblinear')
pipeline = Pipeline([('scaler', scaler),('model', model)
])# 交叉验证
ss = ShuffleSplit(n_splits=5, test_size=0.2, random_state=43) # 每次交叉验证中随机抽样20%的数据
scores = cross_val_score(pipeline, X_1, y, cv=ss, scoring='accuracy')# 输出交叉验证准确率
print(f'Cross-Validation Accuracy Scores: {scores}')
print(f'Average Cross-Validation Accuracy: {scores.mean()}')#集成模型
predictions1 = model1.predict_proba(X_1) # 模型1的预测概率
predictions2 = model2.predict_proba(X_2) # 模型2的预测概率# 集成两个模型的预测概率,这里以平均值为例
#0.8 1.2
ensemble_predictions = (0.5*predictions1 + 1.5*predictions2) / 22b)请探索患者水肿体积随时间进展模式的个体差异,构建不同人群(分亚组:3-5个)的水肿体积随时间进展曲线,并计算前100个患者(sub001至sub100)真实值和曲线间的残差。
这道题我的理解是,每个患者的水肿体积随时间的变化可以绘制一条曲线,对这些曲线做聚类,得到几类不同的变化模式。然后分别统计每类变化模式的人群的特点,比如年龄,是否患高血压。
首先是曲线的绘制,横轴是时间,纵轴的水肿的体积。我们需要根据每位患者的几次检查的时间和体积,绘制曲线。由于每个患者的变化情况都不同,所以如果要用时间序列拟合曲线的话,需要分别对100个患者确定做一百次平稳性检验,确定一百个不同的ARIMA参数,所以放弃了这个思路。我选择直接用多项式做拟合。由于从第一问绘制的图可以看出,大多数曲线都呈现上升后下降的变化趋势,加上数据点只有几个,所以选择的多项式的阶数为2。最终用二阶多项式对100个患者绘制的曲线如下:
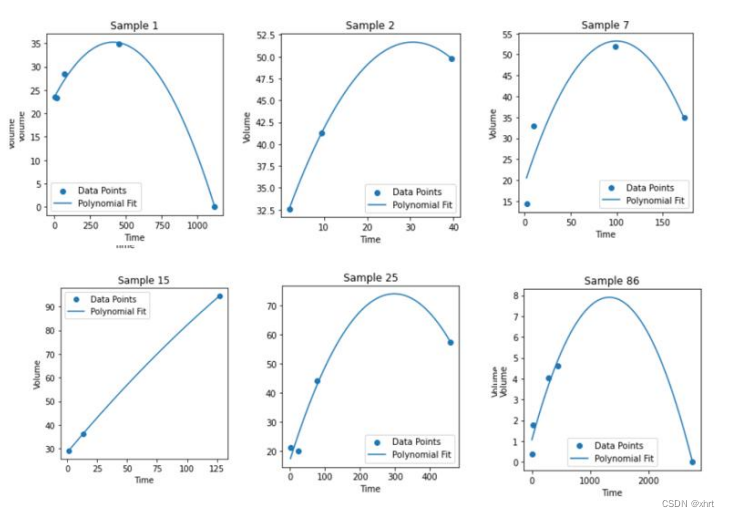
对曲线聚类是这道题的难点,因为患者做随访检查的次数,时间都不同。我们需要同一时间跨度后在进行聚类。最开始的想法是,对每条曲线都等间隔取若干点,用这些点代表曲线,送入kmeans做聚类。但是效果不怎么好,95个点都被分为了同一类。
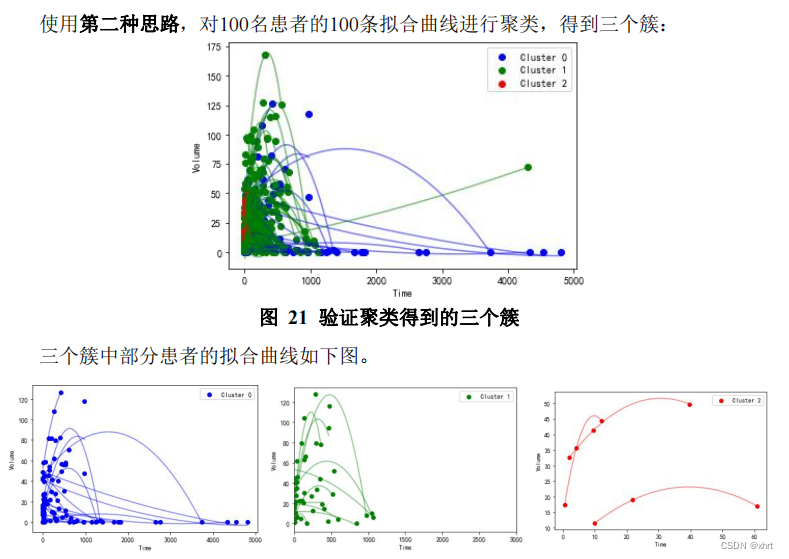
第二天早上,我睡醒之后思考,效果不好的原因在于,只用50个点,并不能很好的代表二次曲线。对于每条二次曲线,我最关注的点有两个:一是曲线最后的趋势是上升还是下降,因为这决定了患者最后的情况是恶化还是好转;而是,在患者最后恶化或者好转的趋势前,是否还有其他趋势,比如先好转再恶化,或者先恶化再好转。而这两个点正好分别由二次曲线的a(开口方向和大小)和对称轴-b/2a(单调性变化的位置是大于0还是小于0)决定。所以最后是使用(a,-b/2a)代表每条曲线,聚类的效果优于前一种方式。
2d)请分析血肿体积、水肿体积及治疗方法(“表1”字段Q至W)三者之间的关系。
首先统计发现每次检查的血肿体积和水肿体积都近似正态分布,所以计算了两者的皮尔逊相关系数。其次使用血肿体积和水肿体积预测治疗方法,发现能够较为准确的预测,说明三者具有相关性。
3b)根据前100个患者(sub001至sub100)所有已知临床、治疗(表1字段E到W)、表2及表3的影像(首次+随访)结果,预测所有含随访影像检查的患者(sub001至sub100,sub131至sub160)90天mRS评分。
3b和3a的差别在于,补充了随访数据。虽然只是补充了随访数据,但是每次随访都包含了将近100个特征,所以如何使用正确的方式降维是这个问的重点。由于随访数据是一个时间序列,所以如果直接把所有数据拼接起来的话会损失时间信息。假设每次随访有100个特征,如果直接把所有特征直接拼接起来的话,其实第一列和第一百零一列是同一个特征在不同时间点的取值,而直接拼接会损失这个信息。所以我一开始的想法是,对于每个患者的三次随访数据,竖着拼接起来。每个患者的数据原本是1*300,我把第一列,第一百零一列,第二百零一列的数据竖着拼在一列,把每个患者的数据变成[3*100]的格式。但是由于没有找到适合二维数据的降维方法,所以这个思路失败了。
结果出来了,是二等奖,也算给三天四晚的付出一个不错的回答吧,