总言
主要内容:HTTP和HTTPS工作方式简述。
文章目录
- 总言
- 6、HTTP协议(应用层·二)
- 6.1、入门认识
- 6.1.1、认识URL
- 6.1.2、urlencode和urldecode
- 6.2、快速构建
- 6.2.1、快速构建http请求和响应的报文格式
- 6.2.2、http demo
- 6.2.2.1、sock.hpp && httpserver.hpp
- 6.2.2.2、httpserver.cc:试着读取一个http请求并构建一个http的响应正文
- 6.3、逐步细化
- 6.3.1、web根目录
- 6.3.1.1、基本说明
- 6.3.1.2、访问一个静态网页:util.hpp、index.html
- 6.3.2、http的请求方法
- 6.3.2.1、基本说明
- 6.3.2.2、在命令行中使用telnet命令测试GET方法
- 6.3.2.3、使用表单来测试GET、POST方法
- 6.3.3、http状态码
- 6.3.4、HTTP常见Header(报头)
- 6.3.5、会话管理(Cookie、Session)
- 6.3.6、短连接与长连接
- 7、HTTPS协议(应用层·三)
- 7.1、https是什么
- 7.2、预备知识
- 7.2.1、加密:是什么和为什么
- 7.2.2、常见加密方式(对称加密 && 非对称加密)
- 7.2.3、数据摘要(数据指纹) && 数字签名
- 7.3、HTTPS 的工作过程探究
- 7.3.1、方案 1:只使用对称加密
- 7.3.2、方案 2:只使用非对称加密
- 7.3.3、方案 3:双方都使用非对称加密
- 7.3.4、方案 4:非对称加密 + 对称加密
- 7.3.5、中间人攻击与CA证书认证流程
- 7.3.6、方案 5 : 非对称加密 + 对称加密 + 证书认证
6、HTTP协议(应用层·二)
6.1、入门认识
应用层就是程序员基于socket接口之上编写的具体逻辑,其中大部分工作和文本处理有关,也就是协议分析与处理。http协议作为现成的应用层协议,其中一定会具有大量的文本分析和协议处理!
6.1.1、认识URL
平时我们俗称的 “网址” 其实就是说的 URL。

因url能够定位互联网中唯一的一个资源,故url也称为统一资源定位符 ( Uniform Resource Locator,统一资源定位器 )。基于此方式获取资源,称其为www万维网(World Wide Web的简称,也称为Web、3W等。www是基于客户机/服务器方式的信息发现技术和超文本技术的综合。)
6.1.2、urlencode和urldecode
说明: 如果用户想在url中,包含url本身用来作为特殊字符的字符(如 /、 ? 等),url形式的时候, 浏览器会自动给我们进行编码(encode),即对特殊字符进行转义。一般服务端收到之后, 需要进行转回特殊字符。
PS:urldecode就是urlencode的逆过程。

转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
PS:汉字也是如此。
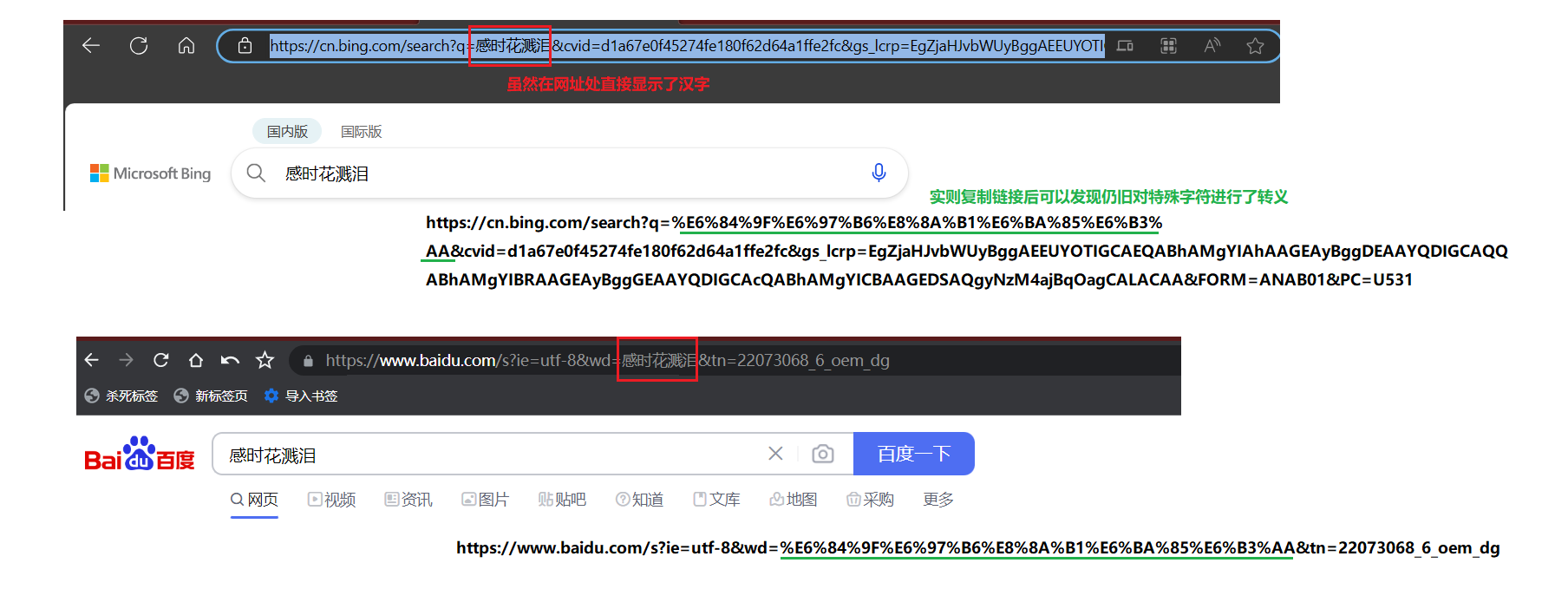
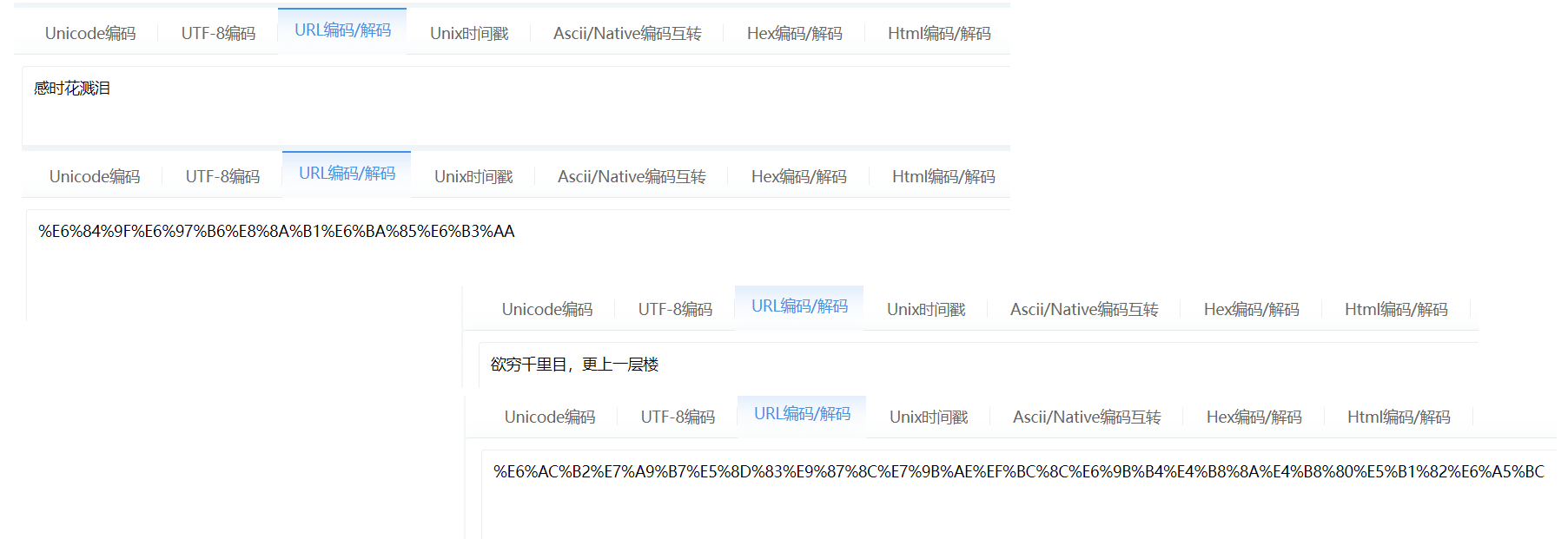
如果有需求,也可以使用一些在线小工具来达到转换:
6.2、快速构建
6.2.1、快速构建http请求和响应的报文格式
1)、基本说明
HTTP协议支持CS模式(即客户端服务器模式,也就是请求和响应模式:在一条通信线路上必定有一端是客户端,另一端是服务器端,请求从客户端发出,服务器响应请求并返回。)。
HTTP协议是应用层协议,底层采用的是TCP,双方交互的是报文。
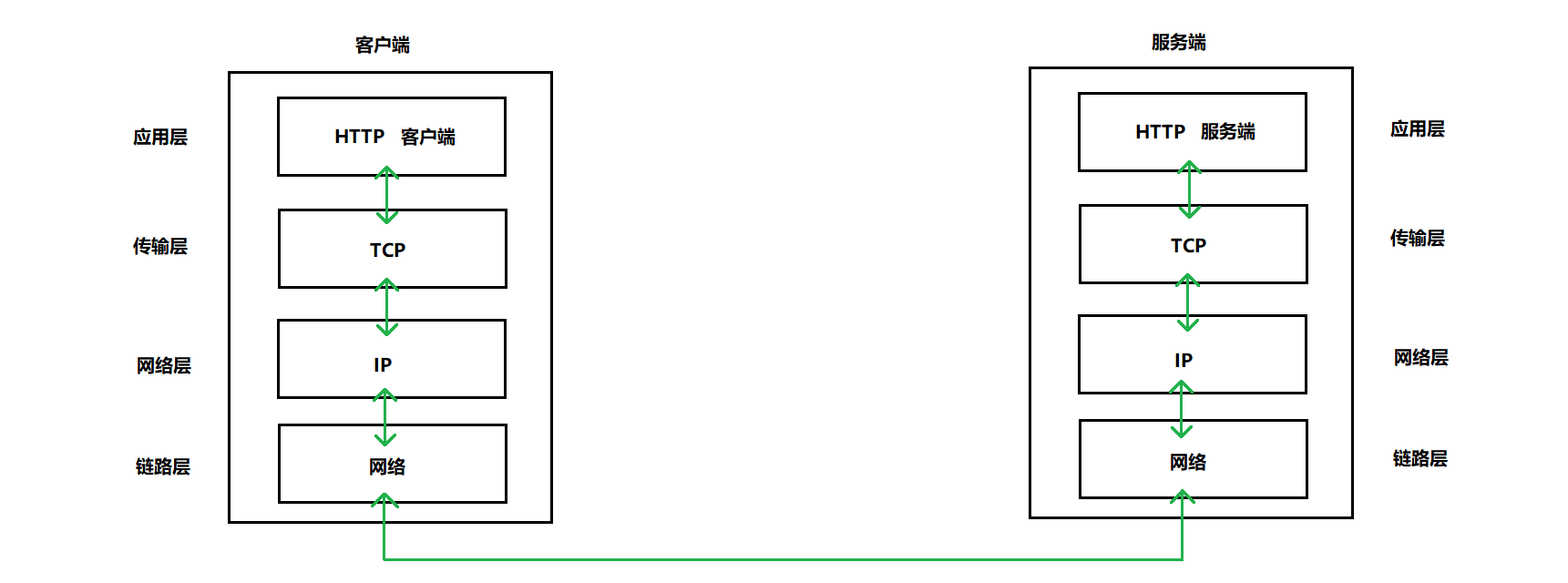
2)、http请求和响应的报文格式
简略图如下:
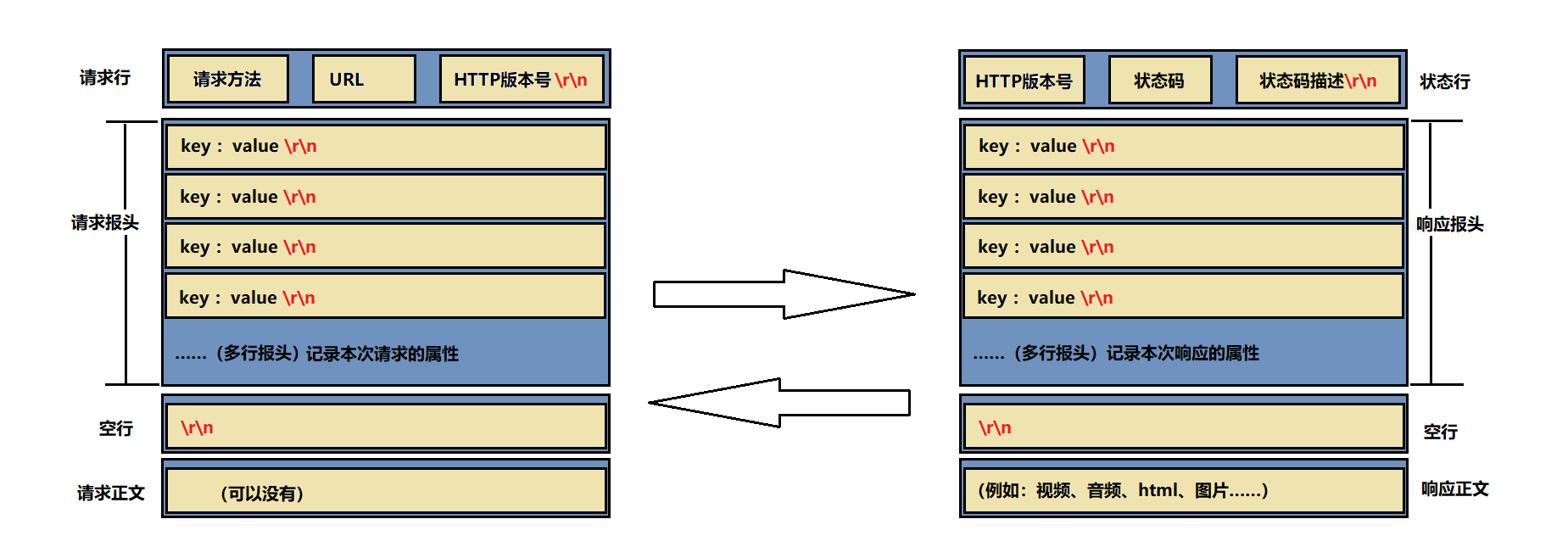
说明1: http其逻辑层面的结构如上述,但实际是线性结构存储发送。(类似于磁盘的物理结构和逻辑结构)。
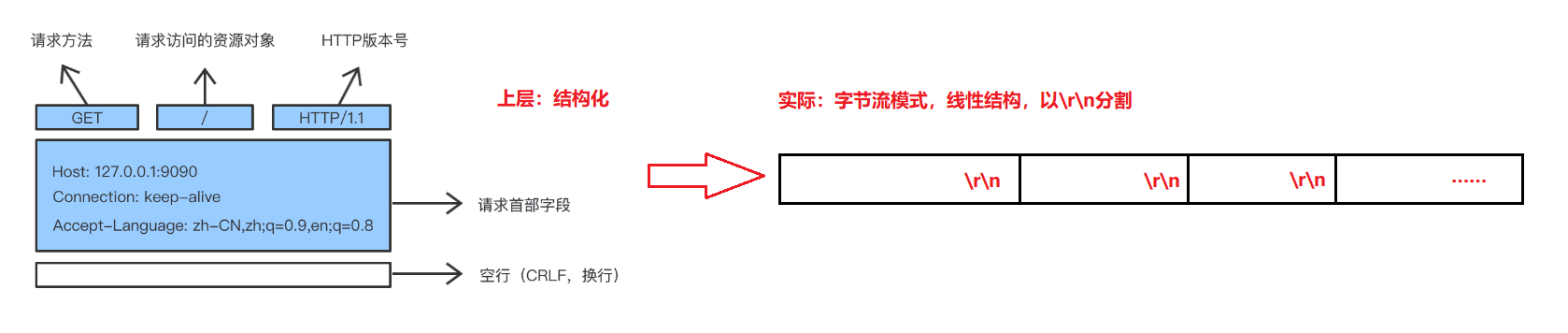
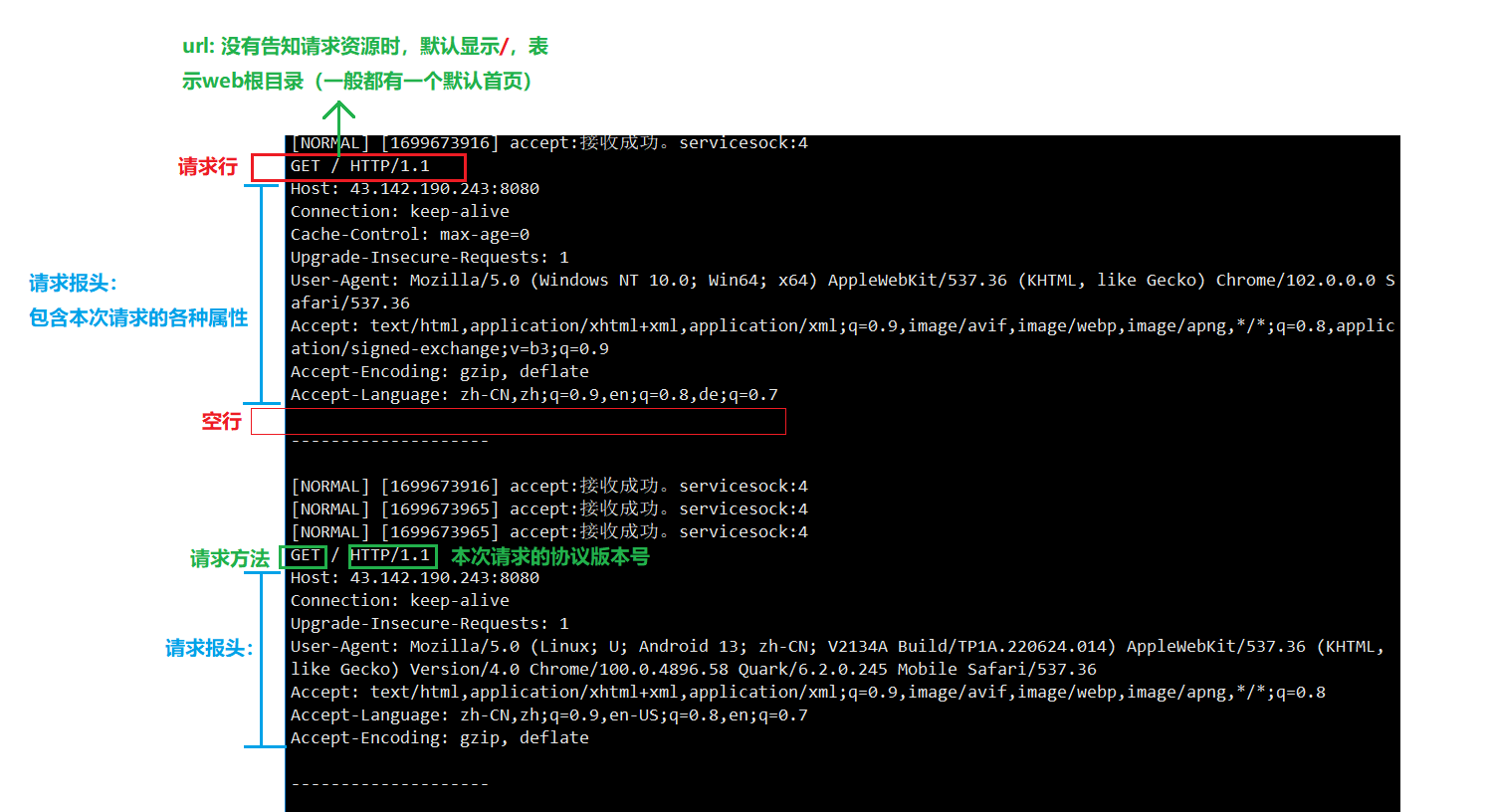
说明2: 如何看待请求行、状态行中都存在协议版本?
回答:客户端版本号和服务端需要匹配。客户端什么版本号,相应的服务端只能提供该版本能提供的服务。(举例:如我们使用的应用,若需要体验一些新功能,则需要把app升级,否则只能使用旧的版本号)
说明3: HTTP协议如何封装和解包,向上交付?
①\r\n: 通过空行的方式,可区分报头和有效载荷。因此,把报头读完,接下来读取到的就是正文部分。
②正文的大小:当把报头读完时,其中存储了Cotent-Length,即可获取正文大小。这是一个 [key, value]模式结构,例如:[Cotent-Length,123],后面的123即本次正文的大小。
6.2.2、http demo
6.2.2.1、sock.hpp && httpserver.hpp
sock.hpp:相关内容之前小节中讲述过,这里只是套用。
#pragma once#include <iostream>
#include <string>
#include <cstring>
#include <cerrno>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "Log.hpp"class Sock
{
private:const static int gbacklog = 20; // listen中参数设置:详细将在后续介绍public:// 构造Sock(){}; // 无参构造// 析构~Sock(){};// 创建套接字:int socket(int domain, int type, int protocol);int Socket(){int listensock = socket(AF_INET, SOCK_STREAM, 0);if (listensock < 0){logMessage(FATAL, "socket:创建套接字失败。%d:%s", errno, strerror(errno));exit(2); // 退出}logMessage(NORMAL, "socket:创建套接字成功, listensock:%d", listensock);return listensock; // 将套接字返回给TcpServer中的成员函数_listensock}// 绑定:int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);void Bind(int sock, uint16_t port, const std::string &ip = "0.0.0.0"){// 准备工作:sockaddr结构体struct sockaddr_in local;bzero(&local, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(port); // 对端口号:需要转换为网络字节序inet_pton(AF_INET, ip.c_str(), &local.sin_addr); // 对ip:点分十进制风格-->网络字节序+四字节// 绑定:if (bind(sock, (struct sockaddr *)&local, sizeof(local)) < 0){logMessage(FATAL, "bind:绑定失败。%d:%s", errno, strerror(errno));exit(3); // 退出}logMessage(NORMAL, "bind: 绑定成功。");}// 监听:int listen(int sockfd, int backlog);void Listen(int sock){if (listen(sock, gbacklog) < 0){logMessage(FATAL, "listen:监听失败。%d:%s", errno, strerror(errno));exit(4); // 退出}logMessage(NORMAL, "listen:监听成功。");}// 获取连接:int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);int Accept(int listensock, std::string *ip, uint16_t *port) // 后两个*为输出型参数:这里的作用是将accept接收到的ip、port返回给TcpServer。{// 准备工作:用于接收源IP、源端口号struct sockaddr_in src;memset(&src, 0, sizeof(src));src.sin_family = AF_INET;socklen_t len = sizeof(src);// 获取连接int servicesock = accept(listensock, (struct sockaddr *)&src, &len);if (servicesock < 0){logMessage(FATAL, "accept:接收失败。%d:%s", errno, strerror(errno));exit(5);}logMessage(NORMAL, "accept:接收成功。servicesock:%d", servicesock);if (ip) // 判空:获取源IP*ip = inet_ntoa(src.sin_addr); // 四字节+网络字节序--->主机字节序+点分十进制if (port) // 判空:获取源端口号*port = ntohs(src.sin_port); // 网络字节序--->主机字节序return servicesock;}// int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen);bool Connect(int sock, const uint16_t &port, const std::string &ip){// 准备工作struct sockaddr_in aim;bzero(&aim, sizeof(aim));aim.sin_family = AF_INET;aim.sin_port = htons(port); // 主机字节序--->网络字节序aim.sin_addr.s_addr = inet_addr(ip.c_str()); // 主机字节序+点分十进制风格--->网络字节序+四字节// 连接if (connect(sock, (struct sockaddr *)&aim, sizeof(aim)) < 0){logMessage(FATAL, "connect:连接失败。%d:%s", errno, strerror(errno));return false;}logMessage(NORMAL, "connect:连接成功。");return true;}
};
httpserver.hpp:这里使用的是多进程版本。让子进程进行业务处理,与sock.hpp配合,将业务处理函数和服务端网络套接字部分解耦。
#pragma once
#include <iostream>
#include <signal.h>
#include <functional>
#include "Sock.hpp"class HttpServer
{
public:using func_t = std::function<void(int)>;// 构造函数HttpServer() {}HttpServer(const uint16_t &port, func_t func): port_(port), func_(func){// 创建套接字listensock_ = sock_.Socket();// 绑定sock_.Bind(listensock_, port_);// 监听sock_.Listen(listensock_);}// 析构~HttpServer(){if (listensock_ > 0)close(listensock_);}// 启动服务端:接收连接客户端,派子进程处理业务void Start(){signal(SIGCHLD, SIG_IGN); // 子进程在终止时会自动清理,不会产生僵尸进程,也不会通知父进程。for (;;){std::string clientip;uint16_t clientport;int servicesock = sock_.Accept(listensock_, &clientip, &clientport); // 输出型参数if (servicesock < 0)continue; // 本次连接失败,重新连接if (fork() == 0) // 子进程:执行业务处理{close(listensock_); // 关闭无用套接字func_(servicesock); // 业务处理函数close(servicesock); // 完成后关闭套接字并退出进行exit(0);}close(servicesock); // 父进程也要关闭对其无用的套接字}}private:int listensock_; // 监听套接字uint16_t port_; // 端口号func_t func_; // 业务处理函数Sock sock_;
};
6.2.2.2、httpserver.cc:试着读取一个http请求并构建一个http的响应正文
1)、演示代码
相关代码如下:
#include <memory>
#include "HttpServer.hpp"// 使用手册
void Usage(std::string proc)
{std::cout << "\nUsage: " << proc << " port\n"<< std::endl;
}// 业务函数
void HandlerHttpRequest(int sock)
{//1、读取一个http请求char buffer[10240];ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);if (s > 0){buffer[s] = 0;std::cout << buffer << "--------------------\n"<< std::endl;}//2、返回一个http响应std::string httpresponse = "HTTP/1.1 200 OK\r\n";//状态行httpresponse += "\r\n";//此处暂时没有响应报头,故直接填\r\nhttpresponse += "<html><h3> 飘风不终朝,骤雨不终日。\r\n </h3></html>";httpresponse += "<html><h3> my one and only.\r\n </h3></html>";send(sock, httpresponse.c_str(), httpresponse.size(), 0);}// 服务端启动: ./HttpServer port
int main(int argc, char **argv)
{// 命令行参数检查if (argc != 2){Usage(argv[0]);exit(1);}// 创建服务器std::unique_ptr<HttpServer> server(new HttpServer(atoi(argv[1]), HandlerHttpRequest));// 启动服务器server->Start();return 0;
}
2)、演示结果
单纯读取一个http请求,结果如下:
// 业务函数
void HandlerHttpRequest(int sock)
{//1、读取一个http请求char buffer[10240];ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);if (s > 0){buffer[s] = 0;std::cout << buffer << "--------------------\n"<< std::endl;}}
可以看到相关的请求报文格式:由于服务端没有进行响应,这里显示无法操作。
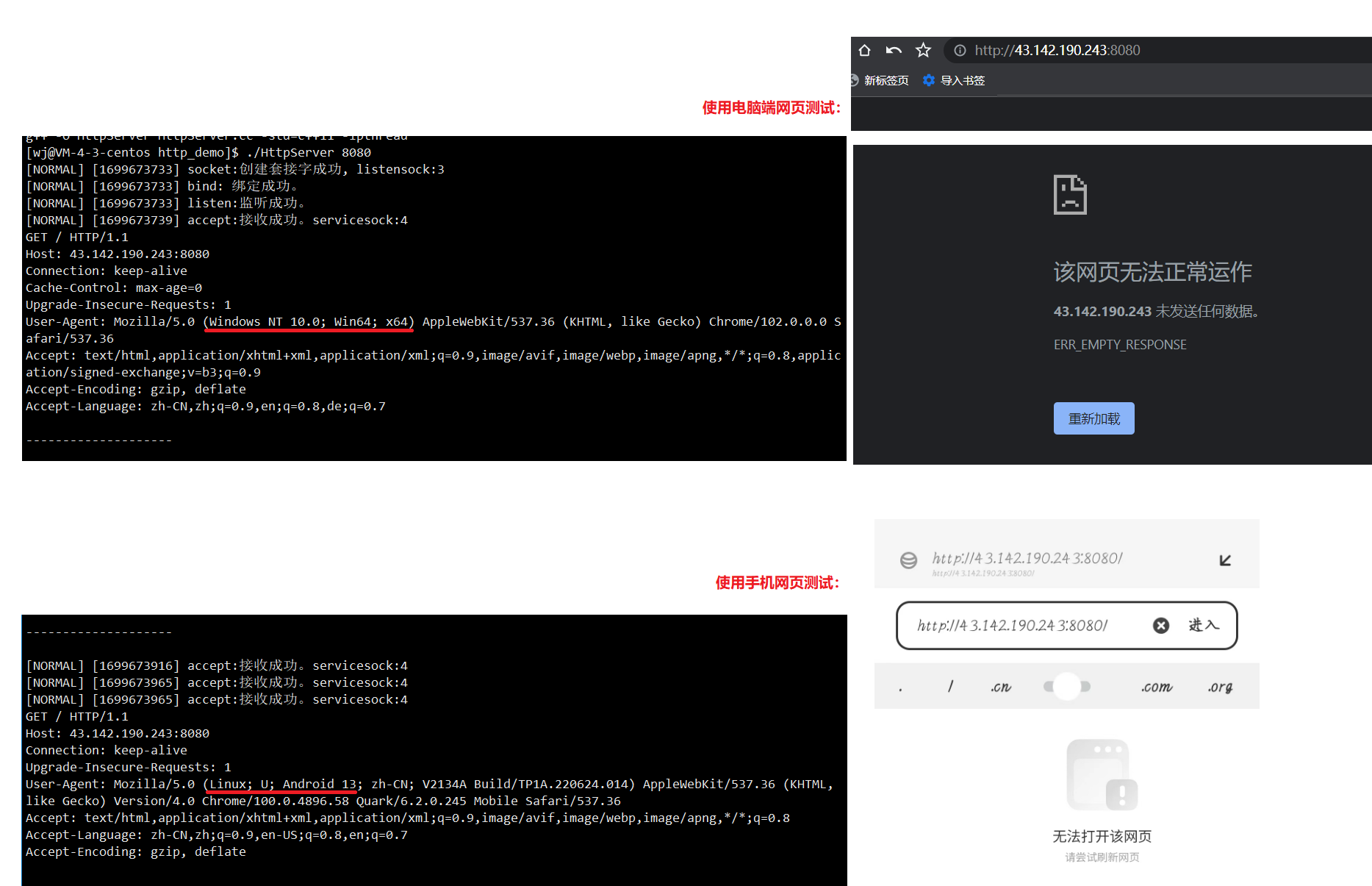
大体介绍:可与之前的示意图对比理解。
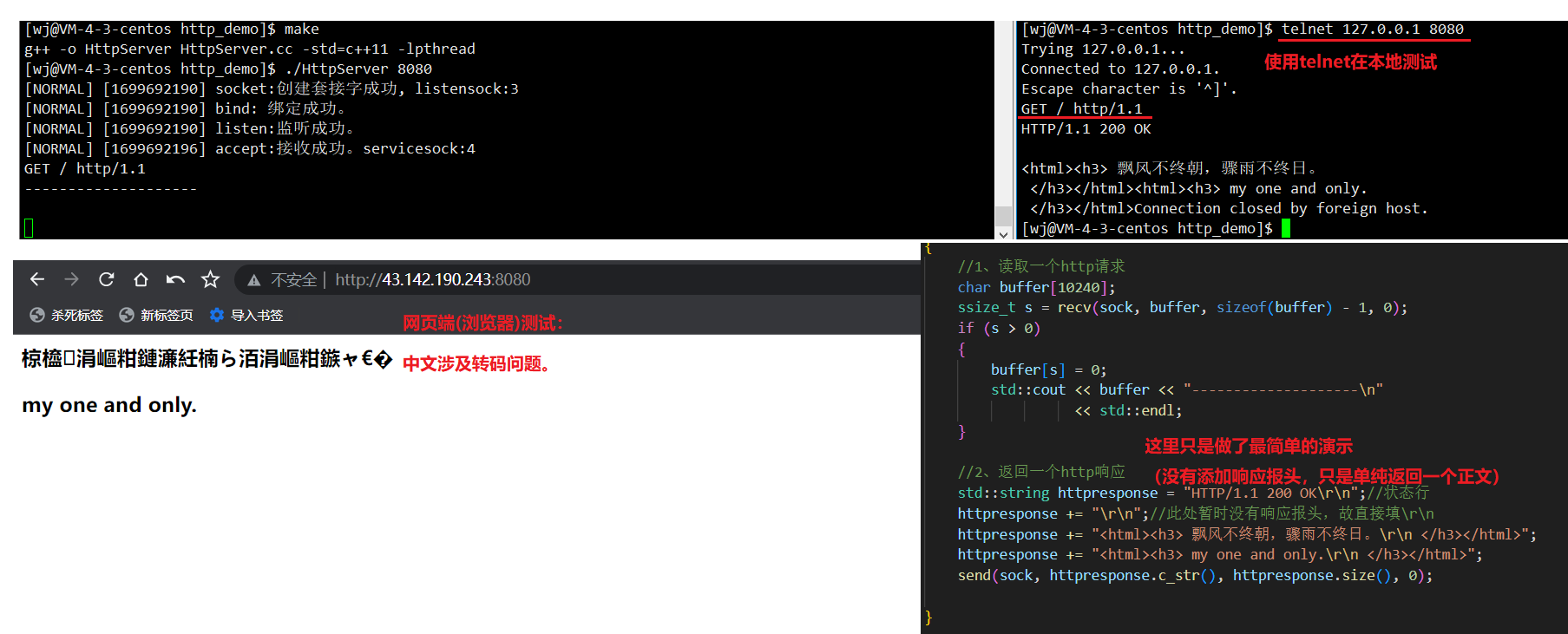
简单构建一个响应:
//2、返回一个http响应std::string httpresponse = "HTTP/1.1 200 OK\r\n";//状态行httpresponse += "\r\n";//此处暂时没有响应报头,故直接填\r\nhttpresponse += "<html><h3> 飘风不终朝,骤雨不终日。\r\n </h3></html>";httpresponse += "<html><h3> my one and only.\r\n </h3></html>";send(sock, httpresponse.c_str(), httpresponse.size(), 0);可以看到页面显示了我们的文本信息。
6.3、逐步细化
6.3.1、web根目录
6.3.1.1、基本说明
说明1: 默认情况下,请求到的是web根目录,即/。如果想要访问某一资源,可输入具体的目录信息,如/a/b/c/d,表示为/a/b/c目录下的资源d。
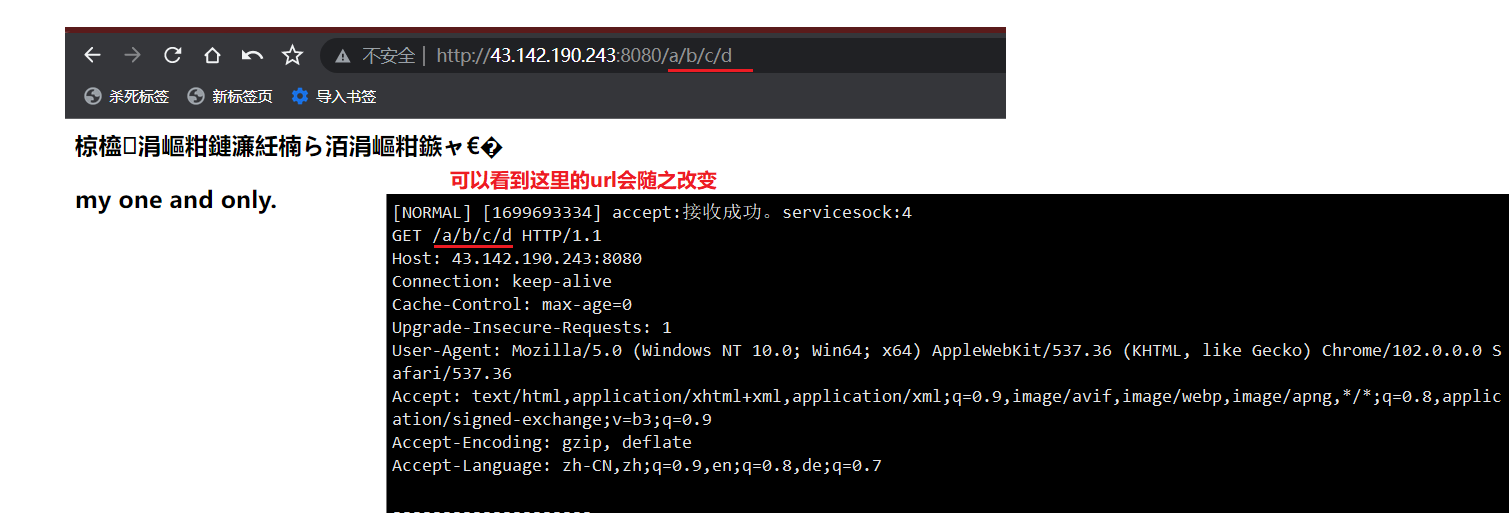
说明2: web根目录并非Linux的根目录,若有需要可以自定义位置设置web根目录所在路径。
以下将进行相关演示:以wwwroot文件作为web根目录。
[wj@VM-4-3-centos http_demo]$ tree
.
|-- HttpServer
|-- HttpServer.cc
|-- HttpServer.hpp
|-- Log.hpp
|-- Makefile
|-- Sock.hpp
|-- Util.hpp
`-- wwwroot //web根目录|-- a| `-- a-1.html //a目录下的资源|-- b| `-- b-1.html //b目录下的资源|-- c`-- index.html //首页4 directories, 10 files
[wj@VM-4-3-centos http_demo]$
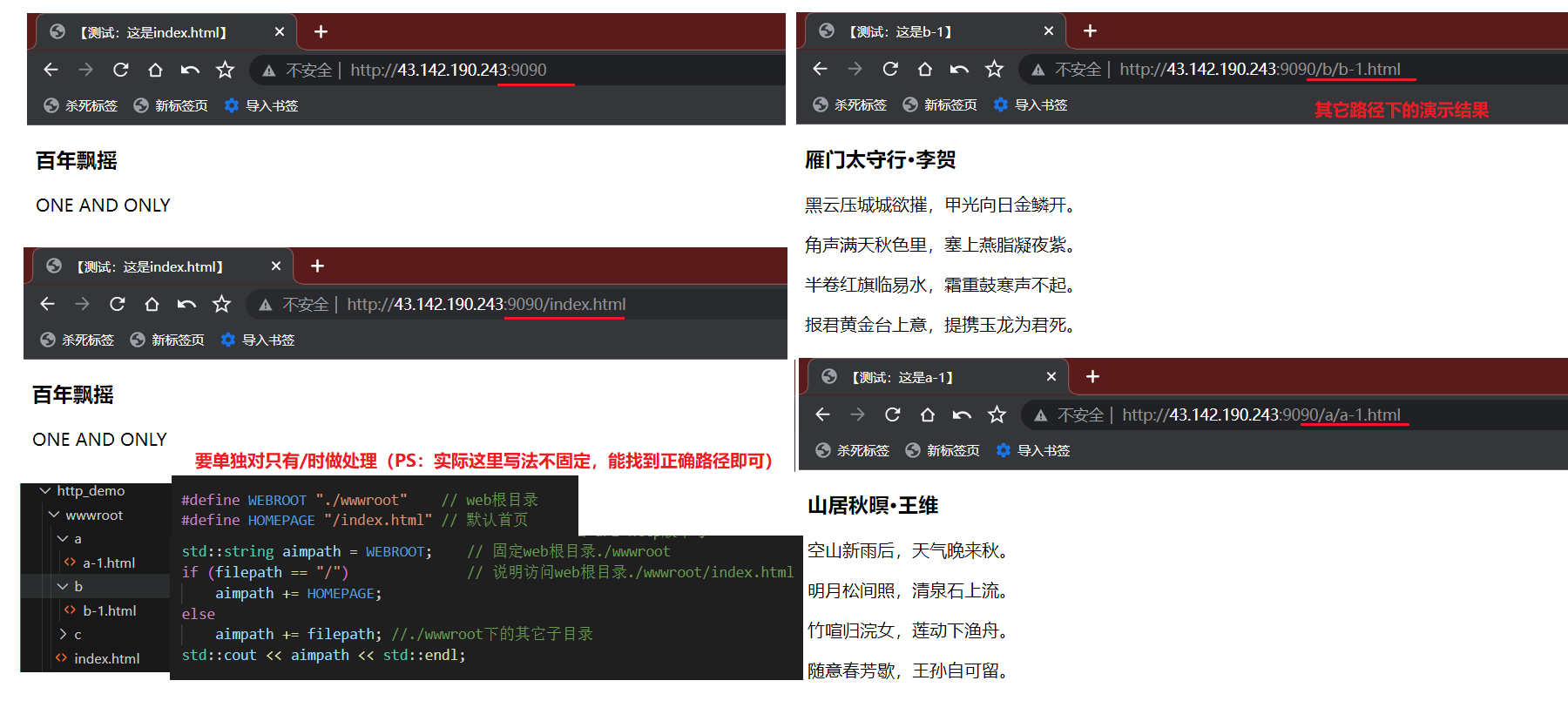
6.3.1.2、访问一个静态网页:util.hpp、index.html
在之前的演示中我们硬编码返回了一个响应,这里我们设置web根目录,并根据请求的url来打开相应目录下的资源,将其返回。
如下,对业务处理函数做了一定修改,增添了1.2提取路径和1.3打开文件。
// 业务函数
void HandlerHttpRequest(int sock)
{// 1.1、读取一个http请求char buffer[10240];ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);if (s > 0){buffer[s] = 0;std::cout << buffer << "--------------------\n"<< std::endl;}// 1.2、提取想要访问的资源路径std::vector<std::string> vline;Util::cutString(buffer, "\n", &vline); // 提取每一行(静态成员可直接用类访问)std::vector<std::string> vblock;Util::cutString(vline[0], " ", &vblock); // 提取第一行:将其每个部分分开std::string filepath = vblock[1]; // 请求行:方法 url http版本号std::string aimpath = WEBROOT; // 固定web根目录./wwwrootif (filepath == "/") // 说明访问web根目录./wwwroot/index.htmlaimpath += HOMEPAGE;elseaimpath += filepath; //./wwwroot下的其它子目录std::cout << aimpath << std::endl;// 1.3、打开待访问路径下的文件std::string content;std::ifstream in(aimpath);if (in.is_open()) // 若成功打开,读取文件内容{std::string line;while (std::getline(in, line))content += line;in.close();}// 2、返回一个http响应std::string httpresponse;if (content.empty())httpresponse = "HTTP/1.1 404 NotFound\r\n"; // 状态行elsehttpresponse = "HTTP/1.1 200 OK\r\n"; // 状态行httpresponse += "\r\n"; // 响应报头:此处暂时没有,故直接填\r\nhttpresponse += content; // 正文send(sock, httpresponse.c_str(), httpresponse.size(), 0);
}
这里路径提取使用的函数如下:
#pragma once#include <iostream>
#include <vector>
#include <string>class Util
{
public:// 以sep分割,从s中提取子串,存入out中(主要是为了获取url路径)// 例如: aaaaa\r\nbbbbbbb\r\nccc\r\nstatic void cutString(const std::string &s, const std::string &sep, std::vector<std::string> *out){std::size_t start = 0;while (start < s.size()){// 寻找分隔符std::size_t pos = s.find(sep, start); // size_t find (const char* s, size_t pos = 0) const;if (pos == std::string::npos)// 没找到break;// 若找到,提取子串std::string sub = s.substr(start, pos - start); // string substr (size_t pos = 0, size_t len = npos) const;// std::cout << "----" << sub << std::endl;//测试代码:用于检验提取子串是否成功out->push_back(sub); // 找到后,将其逐一存入vector中// 跳过已经截取的子串长度及分隔符长度,继续寻找(此处不能使用Pos,因为其是下标位置,不是间距)start += (sub.size() + sep.size());}if (start < s.size()) // 说明还剩下字符{out->push_back(s.substr(start)); // 剩余的字符自成一行}}
};
网页端使用的格式如下:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>【测试:这是index.html】</title>
</body><h3>百年飘摇</h3><p>ONE AND ONLY</p></body>
</html>
以下为测试结果:
6.3.2、http的请求方法
6.3.2.1、基本说明
常见HTTP方法如下:
| 方法 | 说明 | 支持的HTTP协议 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
说明:我们平时的上网行为其实就两种
a.从服务器端拿下来资源数据(GET方法)
b.把客户端的数据提交到服务器(POST方法、GET方法)
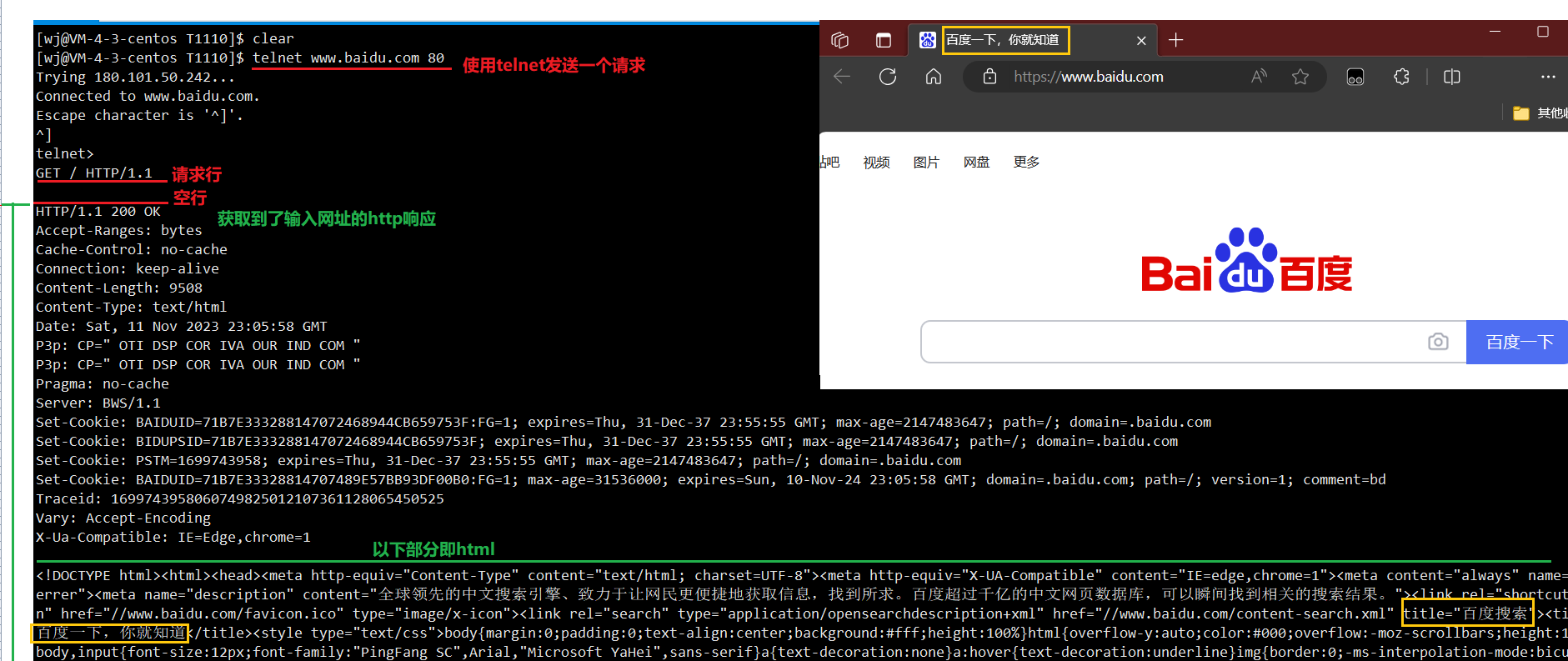
6.3.2.2、在命令行中使用telnet命令测试GET方法
例如:
6.3.2.3、使用表单来测试GET、POST方法
1)、准备知识
说明: HTML 表单用于收集用户的输入信息。HTML 表单表示文档中的一个区域,此区域包含交互控件,将用户收集到的信息发送到 Web 服务器。
表单作用①: 通过交互控件收集用户数据,并把用户数据按照一定方法推送给服务器(即表单中的数据,会被转成http request的部分,在递交时指明提交方法:get、post等等)
此时我们演示例子涉及文本域,其余表单用法可自行扩展学习。
2)、测试:get方法和post方法
根据上述简单演示一个html:
action :用于指定提交表单数据的请求URL。
method :表单数据发送至服务器的方法,常用的有两种, get(默认)/post。
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>GET方法和POST方法验证</title>
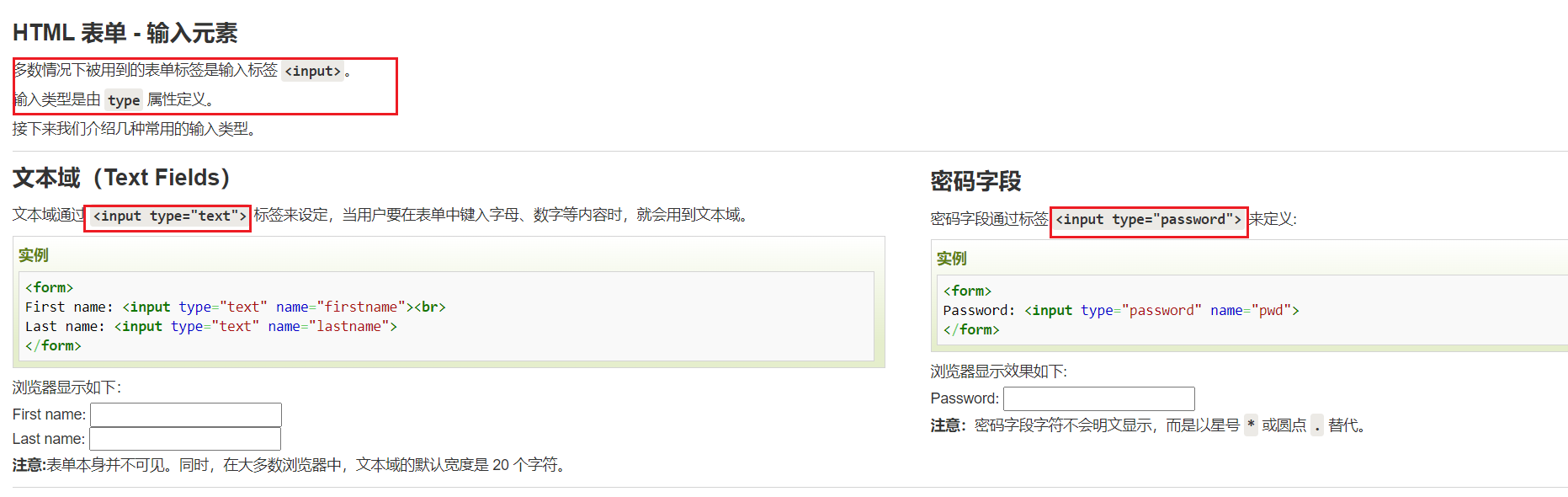
</head><body><h3>测试: GEt && POST</h3><form name="input" action="/index.html" method="GET">Username: <input type="text" name="user"> <br/>Password: <input type="password" name="pwd"> <br/><input type="submit" value="登陆"></form>
</body></html>
上述代码显示的网页信息如下:
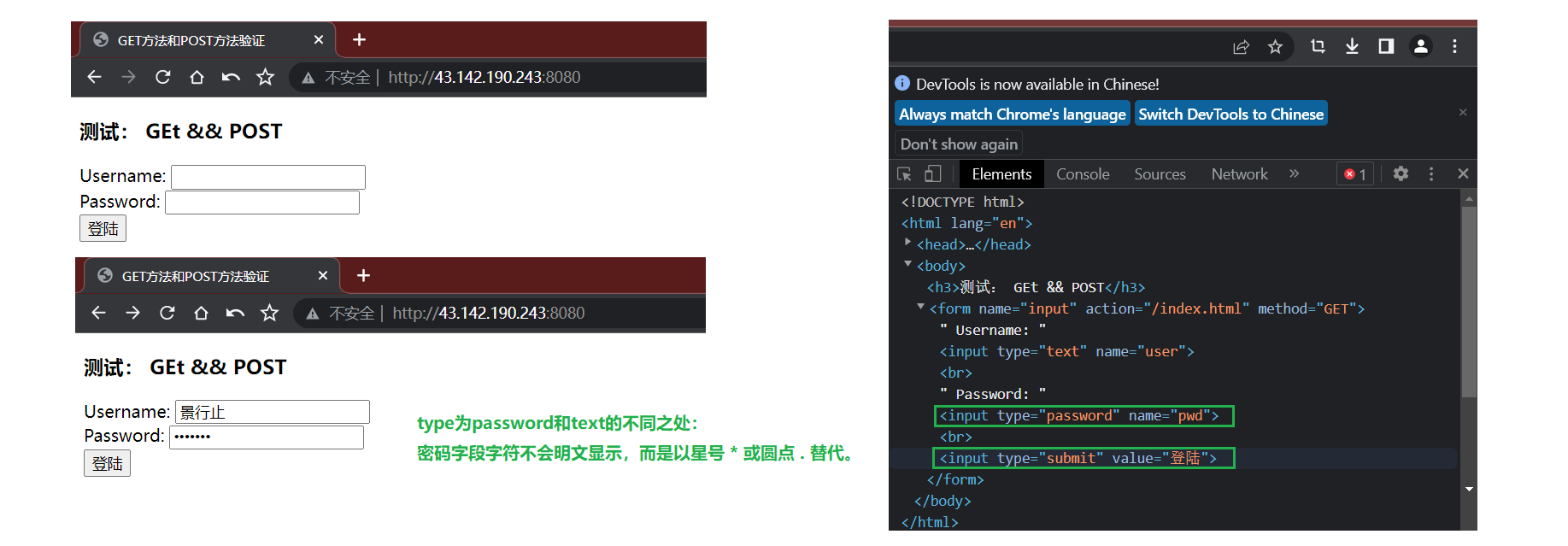
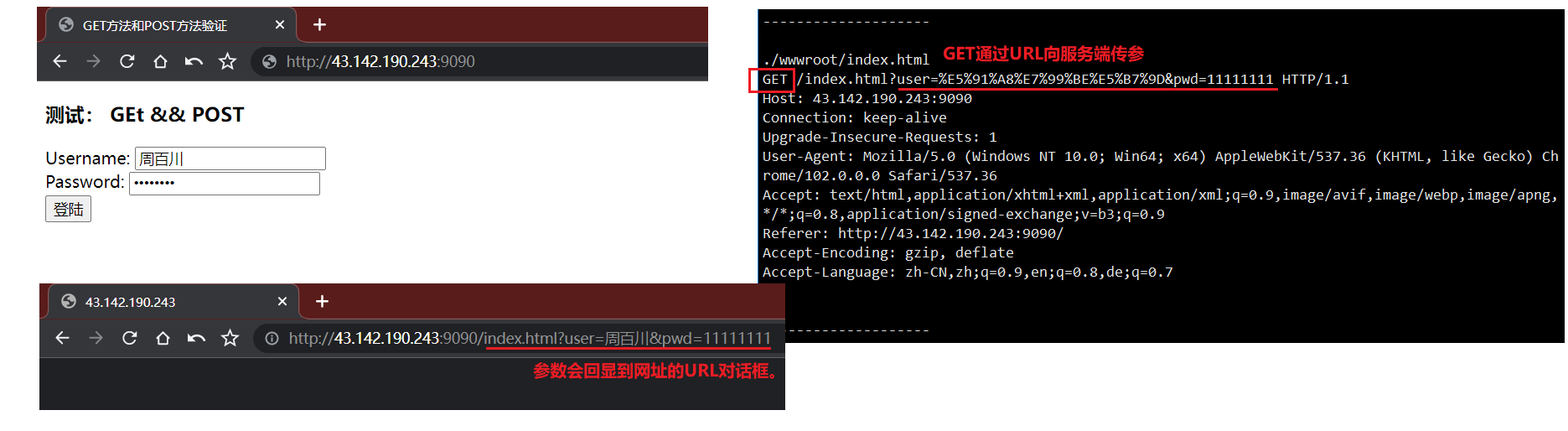
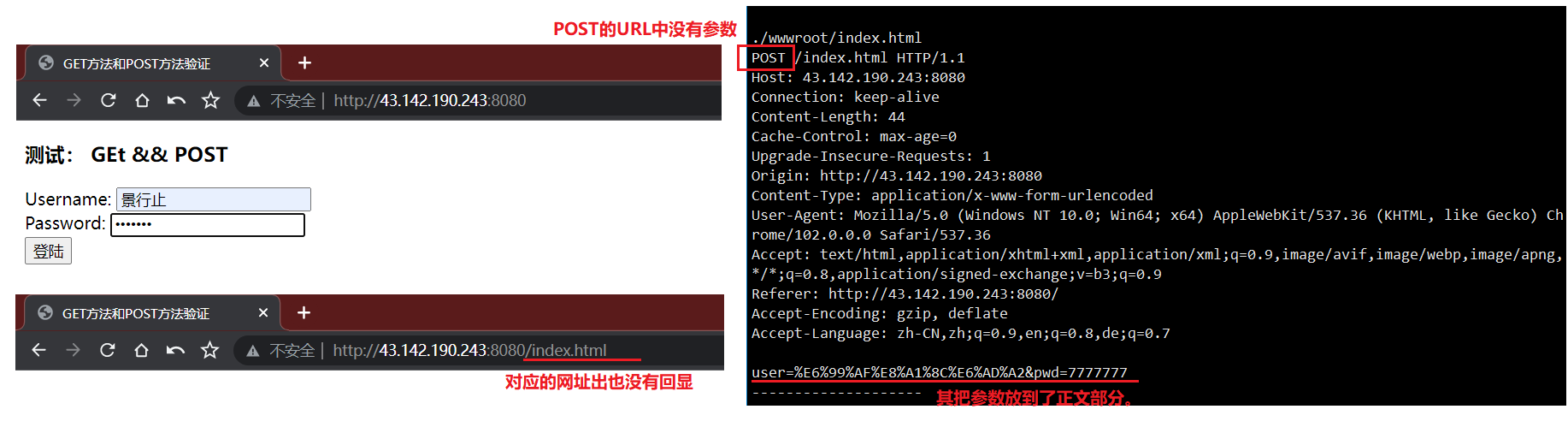
以下为相关验证结果:get方法通过url传参,回显输入的私密信息,不够私密。post方法通过正文提交参数,不会回显,一般私密性是有保证的。
PS:私密不代表安全,它们都属于明文的方式。实际 对数据加密和解密才是安全。
3)、get和post的区别说明
指代不同:
get:从指定的资源请求数据。
post:向指定的资源提交要被处理的数据规则不同:
get: 请求可被缓存;请求保留在浏览器历史记录中;请求可被收藏为书签;请求不应在处理敏感数据时 使用;请求有长度限制;请求应当用于获取数据。
post:请求不会被缓存;请求不会保留在浏览器历史记录中;不能被收藏为书签;请求对数据长度没有要求。数据要求不同:
get:当发送数据时,get 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是2048 个字符)。与 post 相比,get 的安全性较差,因为所发送的数据是 URL 的一部分。
POST:发送数据无限制。post 比 get更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。get请求的参数 url 可见,而 post 请求的参数 url 不可见。
post请求能发送更多的数据类型(get请求只能发送ASCII字符)。
6.3.3、http状态码
1)、基本说明
说明:常见的状态码,比如 200(OK)、404(Not Found)、403(Forbidden)、302(Redirect, 重定向)、504(Bad Gateway)。
| 类别 | 原因短语 | |
|---|---|---|
| 1XX | Informational (信息性状态码) | 接收的请求正在处理 |
| 2XX | Success (成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection (重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error (服务器错误状态码) | 服务器处理请求出错 |
2)、举例介绍:3XX, 永久重定向 301 & 临时重定向 302、307
相关参考文档:HTTP 的重定向。
说明:在 HTTP 协议中,重定向操作由服务器向请求发送特殊的重定向响应而触发。重定向响应包含以 3 开头的状态码,以及 Location 标头,其保存着重定向的 URL。浏览器在接收到重定向时,它们会立刻加载 Location 标头中提供的新 URL。除了额外的往返操作中会有一小部分性能损失之外,重定向操作对于用户来说是不可见的。
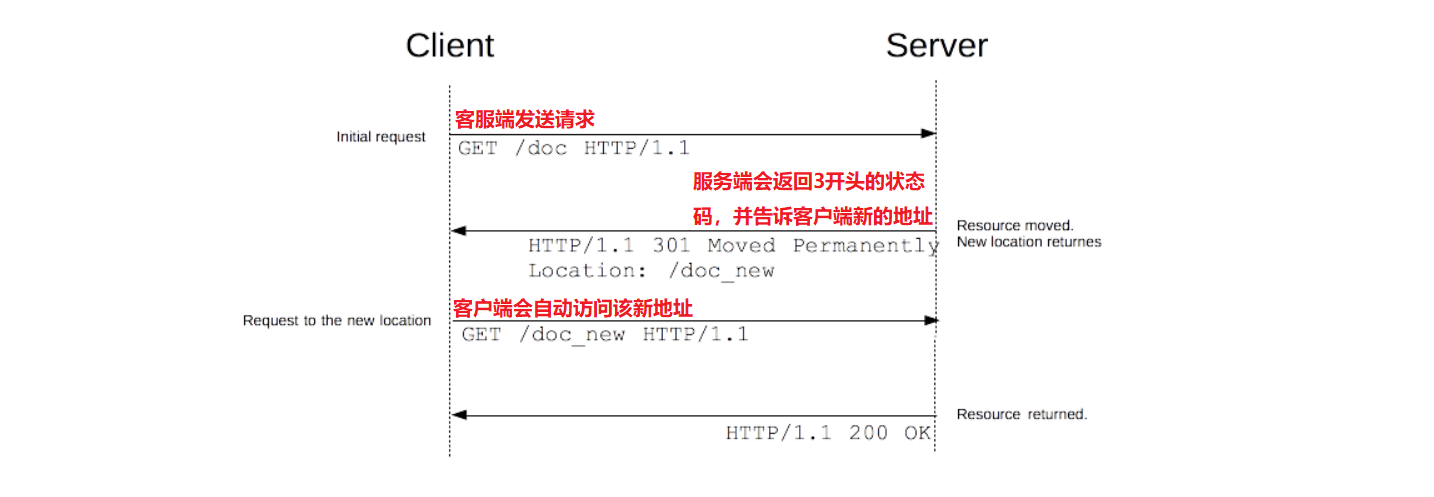
临时重定向: 不影响用户后续的请求策略。有时候请求的资源无法从其标准地址访问,但是却可以从另外的地方访问,在这种情况下,可以使用临时重定向。(举例:页面跳转,比如跳转到支付页面,完成后会跳转回主页)
永久重定向: 影响用户后续的请求策略。这种重定向操作是永久性的,它表示原 URL 不应再被使用,而选用新的 URL 替换它。(举例:新老域名变更,老的域名不用了,可以让用户访问老的域名时,跳转到新的域名)
演示代码:修改的只是httpserver.cc中的HandlerHttpRequest函数。如有需要也可以自定义一个.html文件。
// 2、返回一个http响应std::string httpresponse;if (content.empty()){httpresponse = "HTTP/1.1 302 Found\r\n"; // 状态行httpresponse += "Location: http://43.142.190.243:9090/b/b-1.html\r\n";//演示重定向到自己的网址}elsehttpresponse = "HTTP/1.1 200 OK\r\n"; // 状态行httpresponse += "\r\n"; // 响应报头:此处暂时没有,故直接填\r\nhttpresponse += content; // 正文send(sock, httpresponse.c_str(), httpresponse.size(), 0);
演示结果:
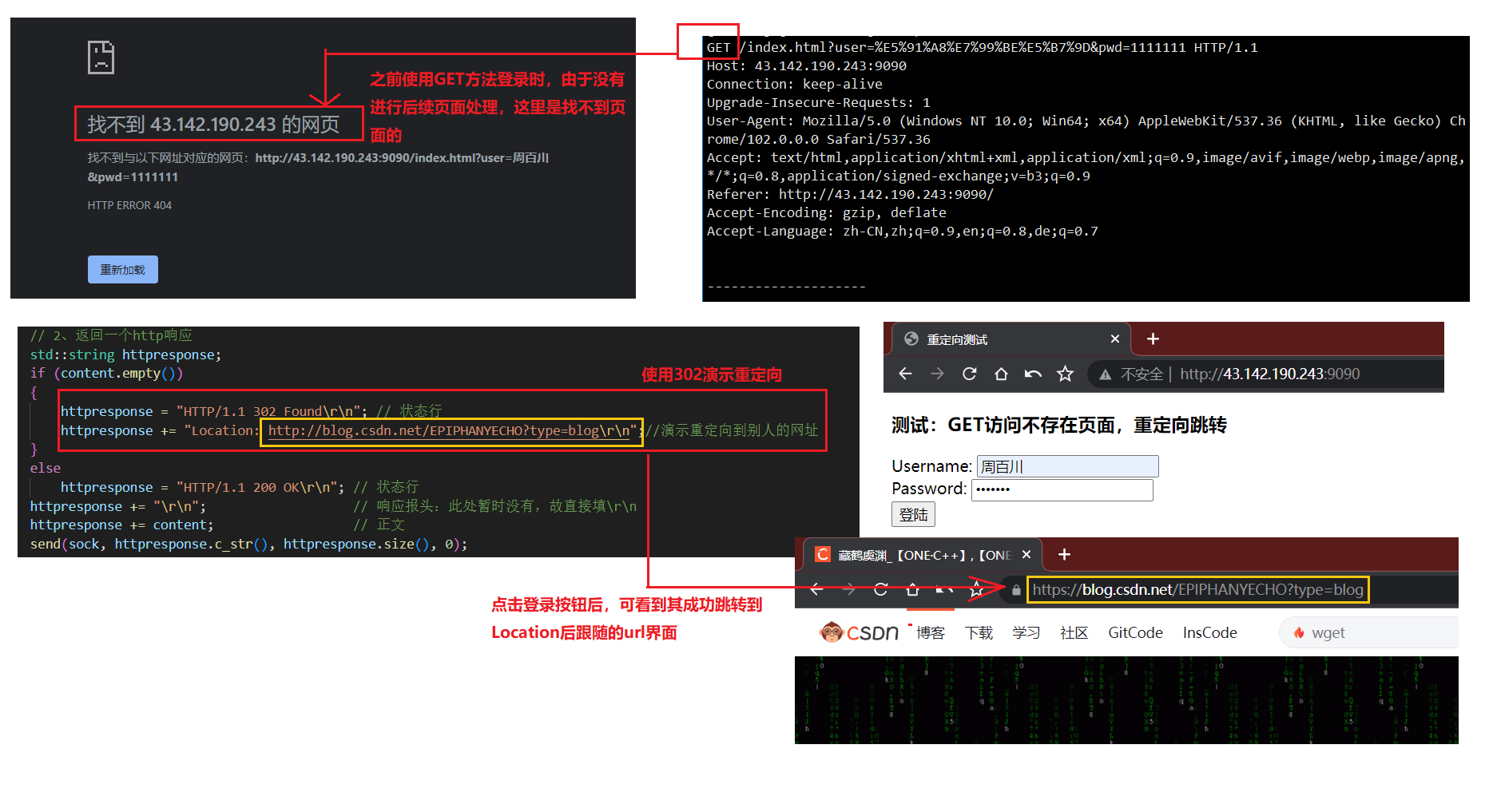
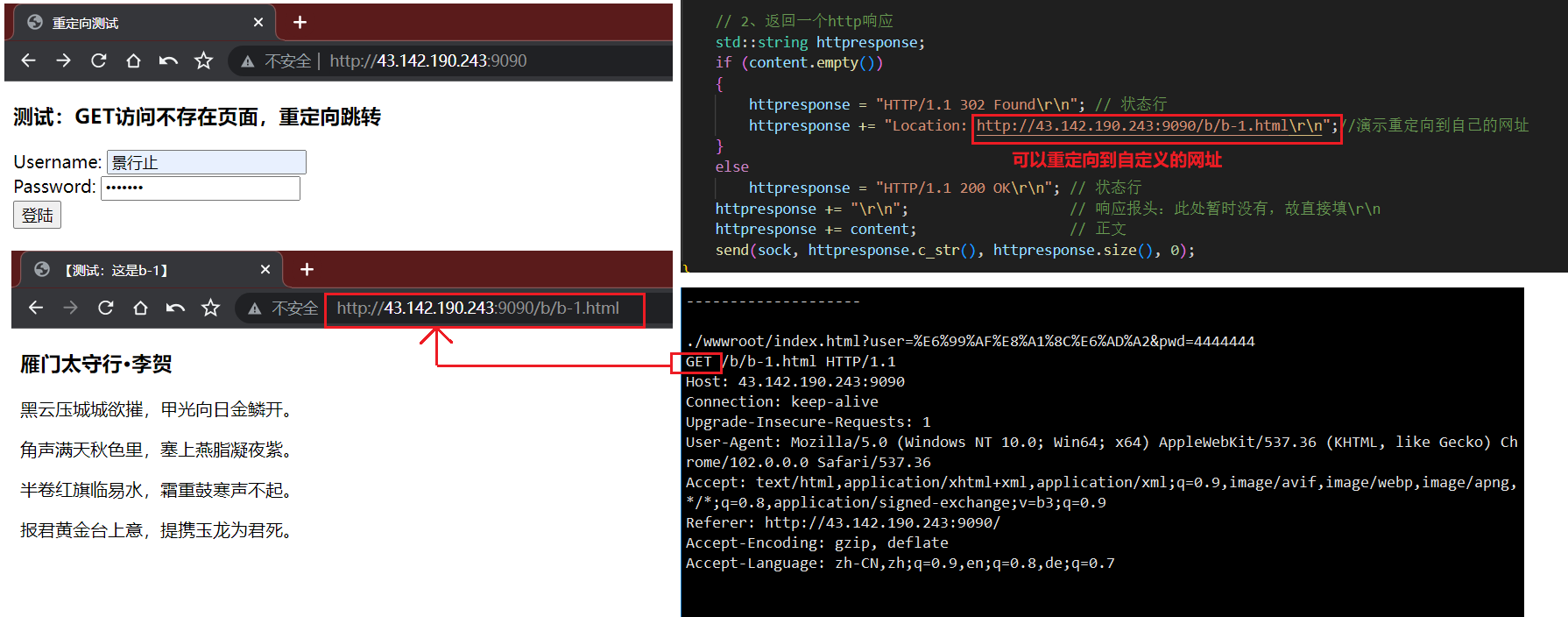
6.3.4、HTTP常见Header(报头)
1)、基本说明
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
2)、相关演示
演示代码如下:
<!DOCTYPE html>
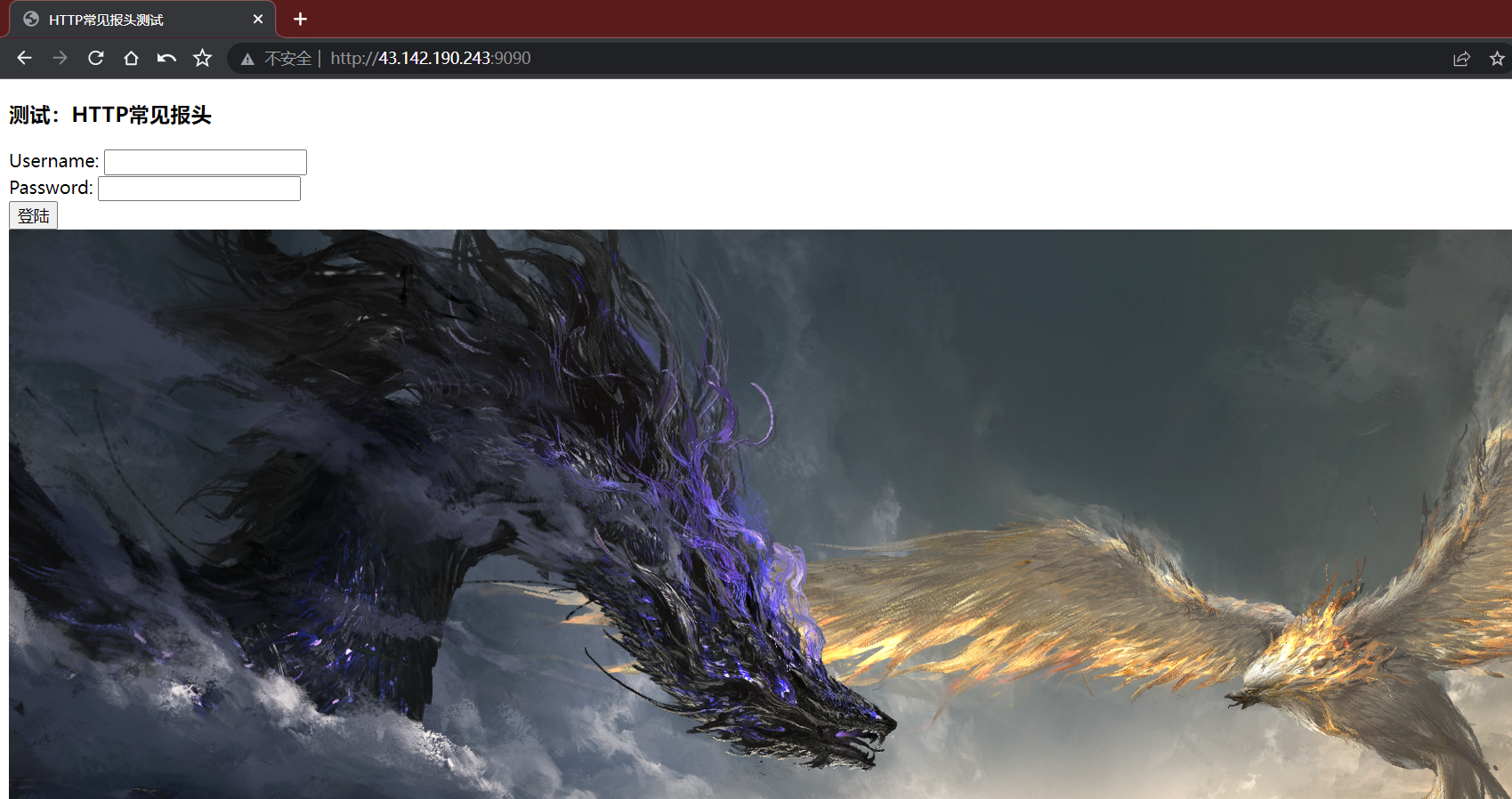
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>HTTP常见报头测试</title>
</head><body><h3>测试:HTTP常见报头</h3><form name="input" action="/index.html" method="GET">Username: <input type="text" name="user"> <br/>Password: <input type="password" name="pwd"> <br/><input type="submit" value="登陆"></form><img src="https://nie.res.netease.com/r/pic/20230524/4e16601a-0c79-4b2c-ac63-5bf637c1172c.png" alt="测试报头:添加图片" width="1722" height="950">
</body></html>
如下为尝试添加的报头信息:
// 2、返回一个http响应std::string httpresponse;if (content.empty()){httpresponse = "HTTP/1.1 302 Found\r\n"; // 状态行httpresponse += "Location: http://43.142.190.243:9090/b/b-1.html\r\n";//演示重定向到自己的网址}else{httpresponse = "HTTP/1.1 200 OK\r\n"; // 状态行httpresponse +=("Content-Type: text/html\r\n");// 报头:数据类型(text/html等) httpresponse +=("Content-Length: " + std::to_string(content.size()) + "\r\n"); //报头:Body的长度}httpresponse += "\r\n"; // 响应报头:此处暂时没有,故直接填\r\nhttpresponse += content; // 正文send(sock, httpresponse.c_str(), httpresponse.size(), 0);
演示结果如下:
6.3.5、会话管理(Cookie、Session)
1)、问题引入
问题说明:http具有简单快速、无连接、无状态的特征。其中,无状态指在HTTP协议中,服务器不会记录客户端的状态信息,每个请求都是独立的,服务器不会记住之前的请求信息,也被称为无状态传输协议(Stateless Transfer Protocol),这意味着服务器无法区分不同的请求是否来自同一个客户端,也无法知道客户端的历史状态。
然而,当用户登录一个网站时,再次登录可以看到用户并未退出,原先的状态信息仍旧保存着。这是因为:虽然HTTP无状态,但浏览器一般会记录下相关网址的状态信息。
HTTP的两个报头属性:①Cookie,在请求中;②Set-Cookie,在响应中。
2)、如何做到会话管理
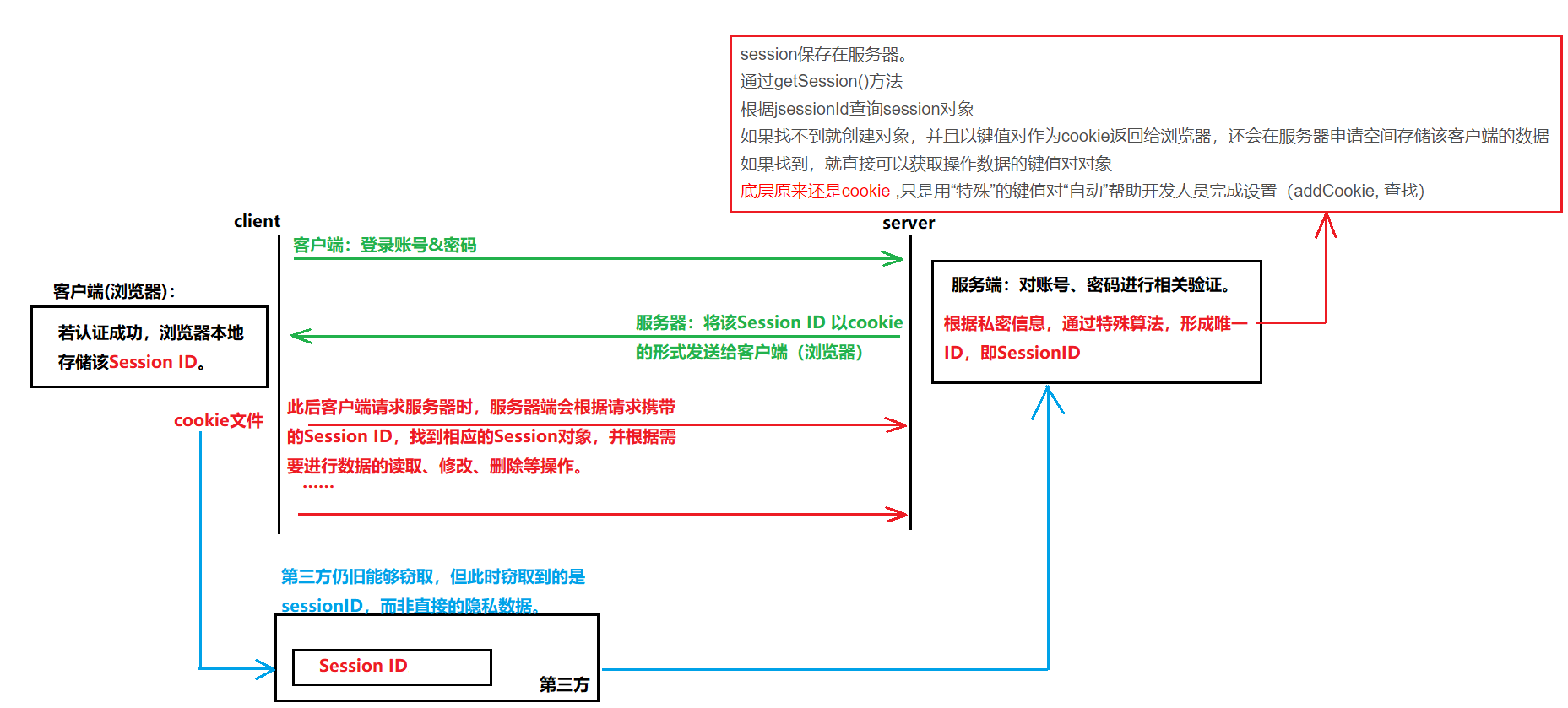
Cookie 访问服务器之后,服务器可以发送cookie给客户端,客户端默认就会保存这个cookie,下次自动发送。相关步骤简述如下:
1、服务端创建cookie对象,添加到响应中,发回给客户端。
2、客户端接收到响应,把cookie的数据保存“浏览器”中。
3、下次访问同一个“网站”时(服务器的服务),会自动携带cookie数据。
4、通过cookie的方式,实现了 “不同请求”之间数据“共享”。

因此,提出在服务端存储用户的会话状态Session,并通过SessionID,来替代直接通过Cookie来维持用户的登录状态。
SessionID可被设置过期时间,攻击者将更难维持持久的登录状态(这也是为什么有时用户登录的状态信息,隔一段时间就会被退出,需要重新登录的原因)SessionID实际不包含有意义的敏感信息,在诸如“需要原密码的密码重置”等场景,攻击者便难以简单地施展攻击。
3)、相关演示
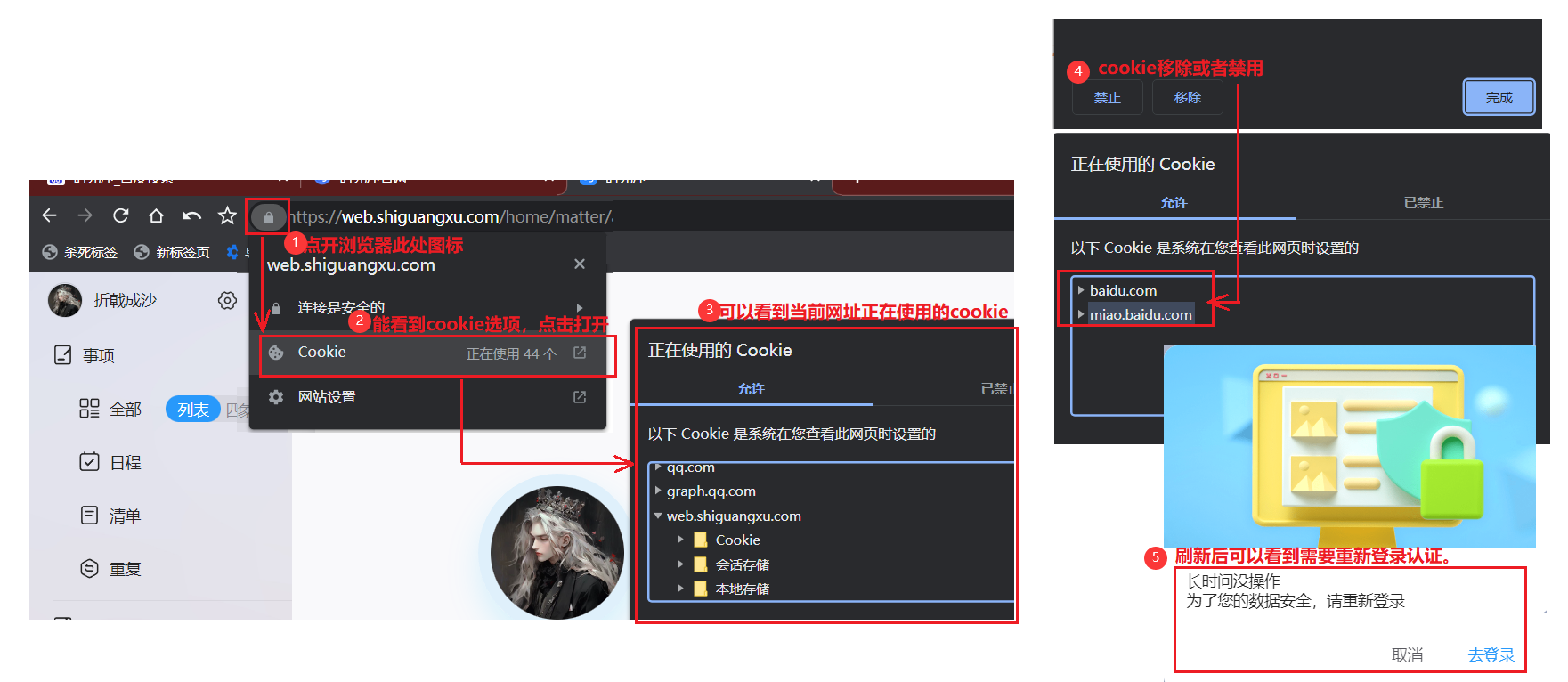
1、简单演示如何查看网页中的cookie,以及移除相应cookie的结果:
2、服务端响应时,返回cookie报头:
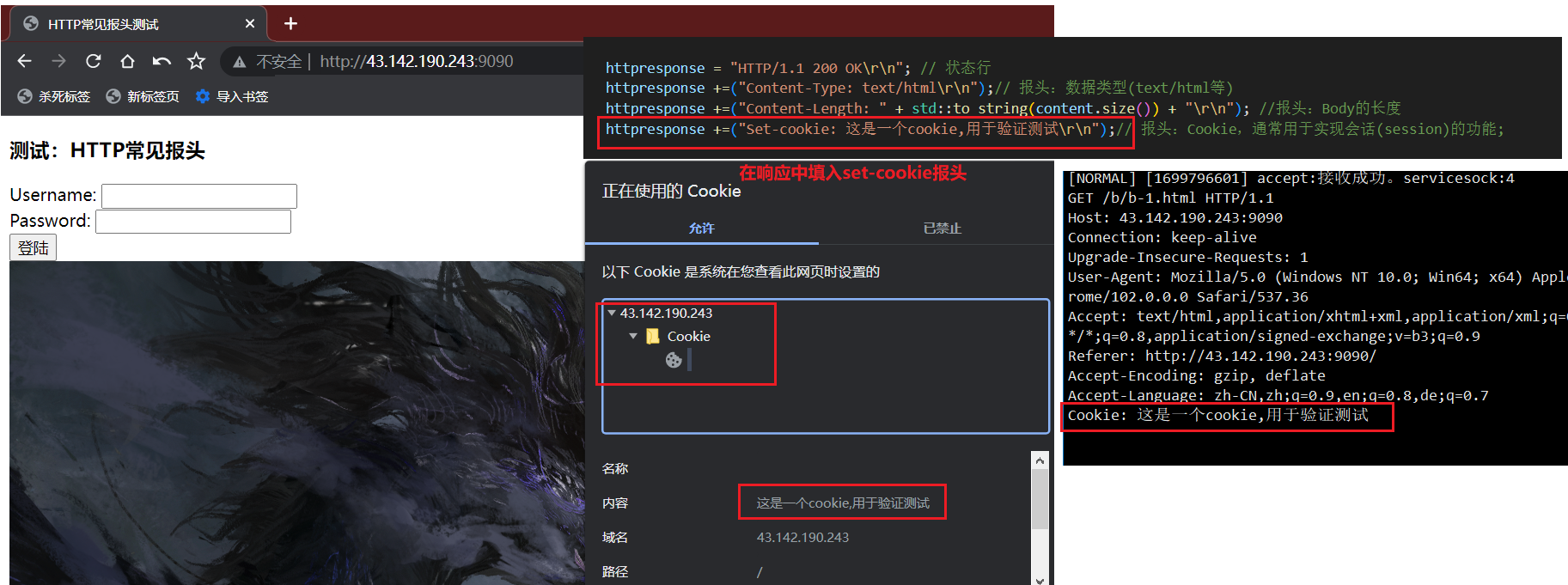
// 2、返回一个http响应std::string httpresponse;if (content.empty()){httpresponse = "HTTP/1.1 302 Found\r\n"; // 状态行httpresponse += "Location: http://43.142.190.243:9090/b/b-1.html\r\n";//演示重定向到自己的网址}else{httpresponse = "HTTP/1.1 200 OK\r\n"; // 状态行httpresponse +=("Content-Type: text/html\r\n");// 报头:数据类型(text/html等) httpresponse +=("Content-Length: " + std::to_string(content.size()) + "\r\n"); //报头:Body的长度httpresponse +=("Set-cookie: 这是一个cookie,用于验证测试\r\n");// 报头:Cookie,通常用于实现会话(session)的功能;}httpresponse += "\r\n"; // 响应报头:此处暂时没有,故直接填\r\nhttpresponse += content; // 正文send(sock, httpresponse.c_str(), httpresponse.size(), 0);
结果如下:该 Cookie 成功被服务端(浏览器)接收到。
当然,可以分为文件级的 Cookie 文件和内存级的 Cookie 文件。①文件级的 Cookie 文件是存储在用户计算机上的硬盘上,是一种持久性的 Cookie。它们的过期时间可以设置为一段时间,也可以永不过期。②内存级的 Cookie 文件是存储在内存中的临时 Cookie。当浏览器关闭时,它们会自动删除。
6.3.6、短连接与长连接
1)、基本说明
Connection: keep-alive //长连接
Connection: close //短连接
| 优点 | 缺点 | |
|---|---|---|
| 长连接 | 连接复用,每次请求耗时更短,性能更佳 | 维护成本大:需要维护连接池,需要对连接进行保活、需要及时清理空闲时间过长的连接,需要动态维护连接池的大小 |
| 短连接 | 实现简单,代码易于阅读和维护 | 连接无法复用,请求耗时长,容易把下游服务的连接打满 |
7、HTTPS协议(应用层·三)
7.1、https是什么
说明: HTTPS 也是⼀个应⽤层协议,其在 HTTP 协议的基础上,引⼊了⼀个加密层(TLS/SSL)。
问题一:HTTP与HTTPS有什么区别?
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,对比http协议要相对安全。

问题二:这里的安全是什么意思?
此次并非指HTTPS协议是绝对安全的,只是说明其破解的成本远大于破解的收益。
7.2、预备知识
7.2.1、加密:是什么和为什么
1)、什么是加密?
加密:就是把 明文 (要传输的信息)进⾏⼀系列变换,⽣成 密文 。
解密:就是把 密文 再进⾏⼀系列变换,还原成 明文 。
在这个加密和解密的过程中,往往需要⼀个或者多个中间的数据辅助进⾏这个过程,这样的数据称为 密钥。

2)、为什么要加密?
举例简述:http的内容是明⽂传输的,明⽂数据会经过路由器、wifi热点、通信服务运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双⽅察觉,这就是 中间⼈攻击 ,所以我们才需要对信息进⾏加密。
7.2.2、常见加密方式(对称加密 && 非对称加密)
1)、基本介绍

7.2.3、数据摘要(数据指纹) && 数字签名
1)、数据摘要(数据指纹)
概念: 数字指纹(数据摘要),其基本原理是利⽤单向散列函数(Hash函数)对信息进⾏运算,⽣成⼀串固定⻓度的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被窜改。
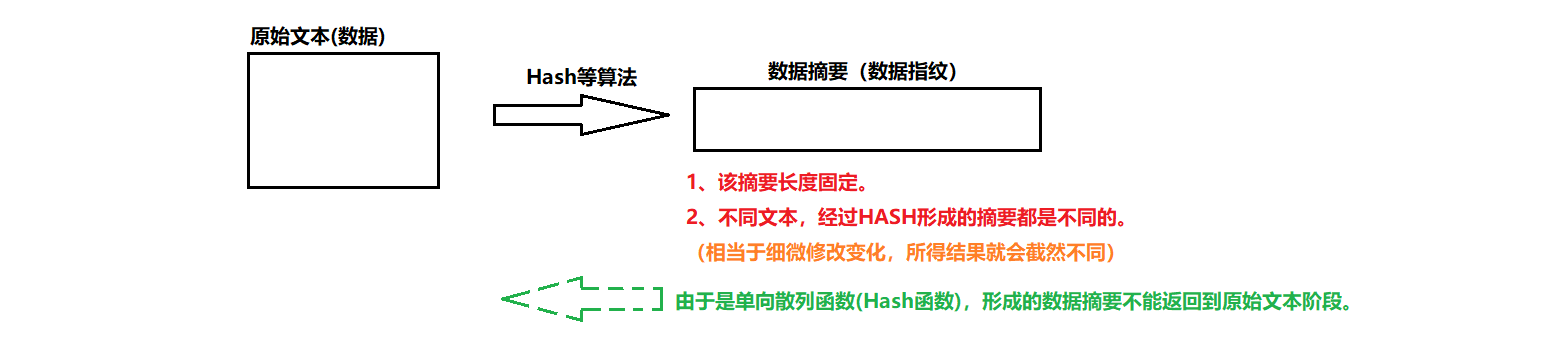
摘要常见算法: 有MD5、SHA1、SHA256、SHA512等,算法把⽆限的映射成有限,因此可能会有碰撞(两个不同的信息,算出的摘要相同,但是概率⾮常低)
以下为一个举例:
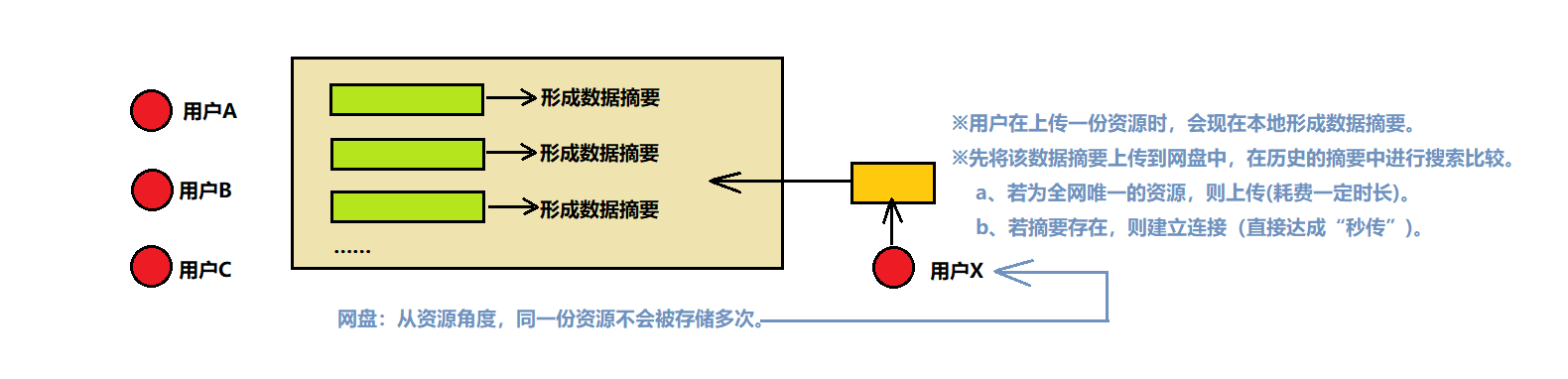
2)、数字签名
摘要经过加密,就得到数字签名。
7.3、HTTPS 的工作过程探究
7.3.1、方案 1:只使用对称加密
方式说明:通信双⽅都各自持有同⼀个密钥X,使用该密钥加密、解密。这样,除非密钥被破解,否则除通信两⽅外无人知晓密钥情况,故可保障通信安全当然是可以被保证的。
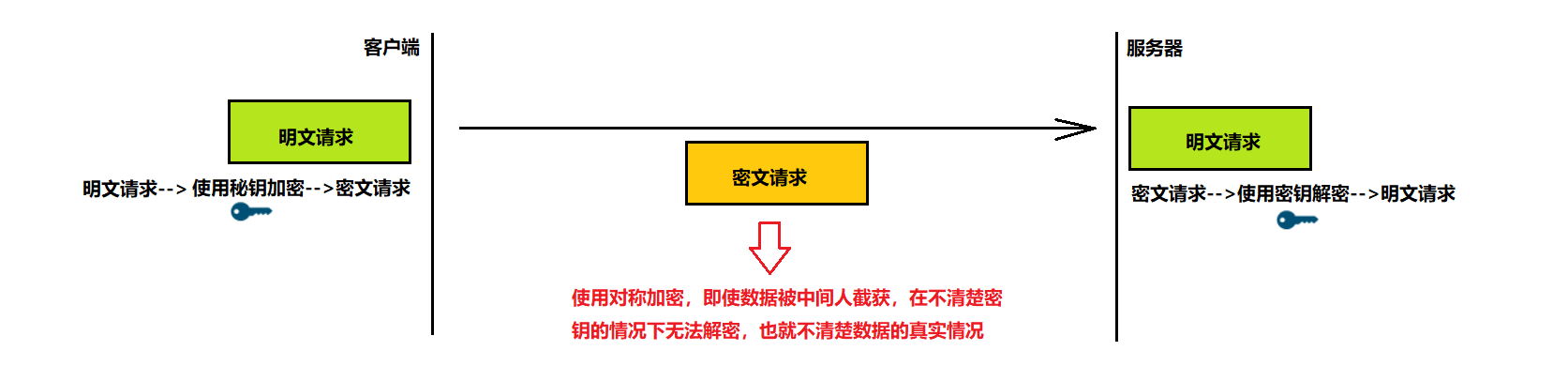
该方案存在的问题:
1、维护成本高,这种情况下服务器需要维护每个客户端和每个密钥之间的关联关系。
2、首次如何确保客户端和服务器共享密钥?
比较理想的做法是:在客户端和服务器建立连接的时候,双方协商确定本次的密钥。但这种方案下,密钥的传输也必须加密传输,也就是先协商确定⼀个 “密钥的密钥”。如果对于密钥的传输仍旧使用对称加密,则会类似于盗梦空间一样无限套娃。
7.3.2、方案 2:只使用非对称加密
方式说明:设服务器持有私钥,把公钥明文传输给客户端。
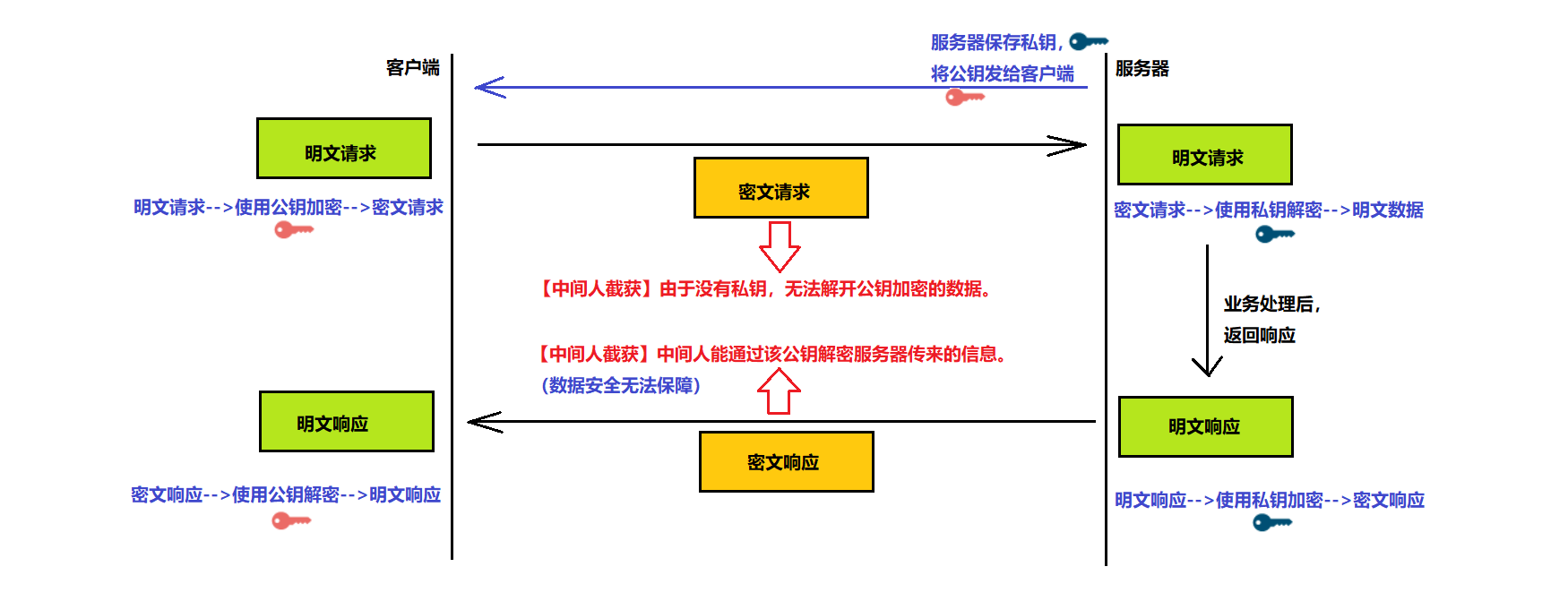
该方案存在的问题:
1、客户端—>服务器:经过公钥加密,服务器私钥解密,保证了安全;
2、服务器—>客户端:经过私钥加密,客户端公钥解密,不能保证安全。(公钥被中间⼈劫持到,那他也能⽤该公钥解密服务器传来的信息)
7.3.3、方案 3:双方都使用非对称加密
方式说明:服务端拥有公钥S与对应的私钥S’,客户端拥有公钥C与对应的私钥C’,客户和服务端交换彼此的公钥。
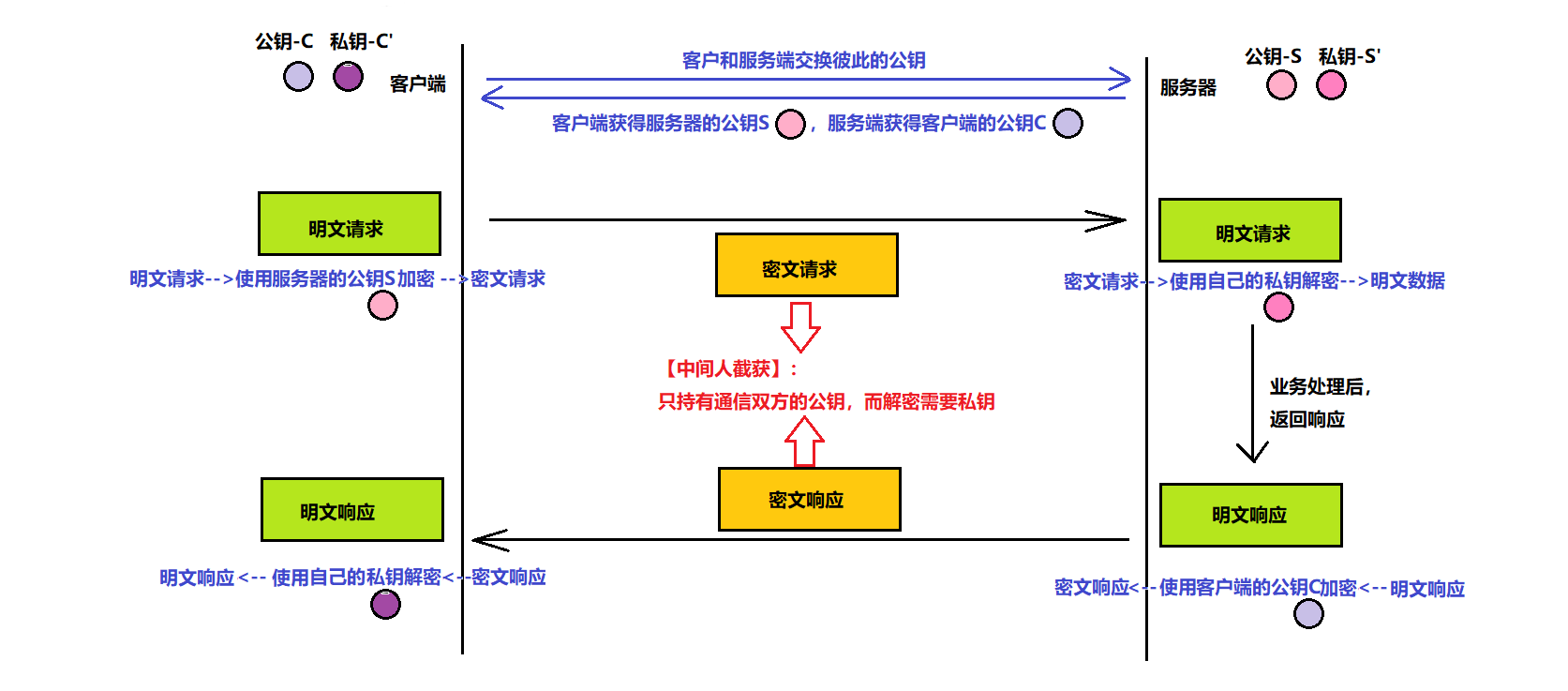
此方案问题说明:
1、效率太低
2、依旧有安全问题
7.3.4、方案 4:非对称加密 + 对称加密
方式说明: 由于对称加密的效率比非对称加密⾼很多,因此,①密钥协商阶段,使用非对称加密;②在数据通信阶段,使用对称加密。
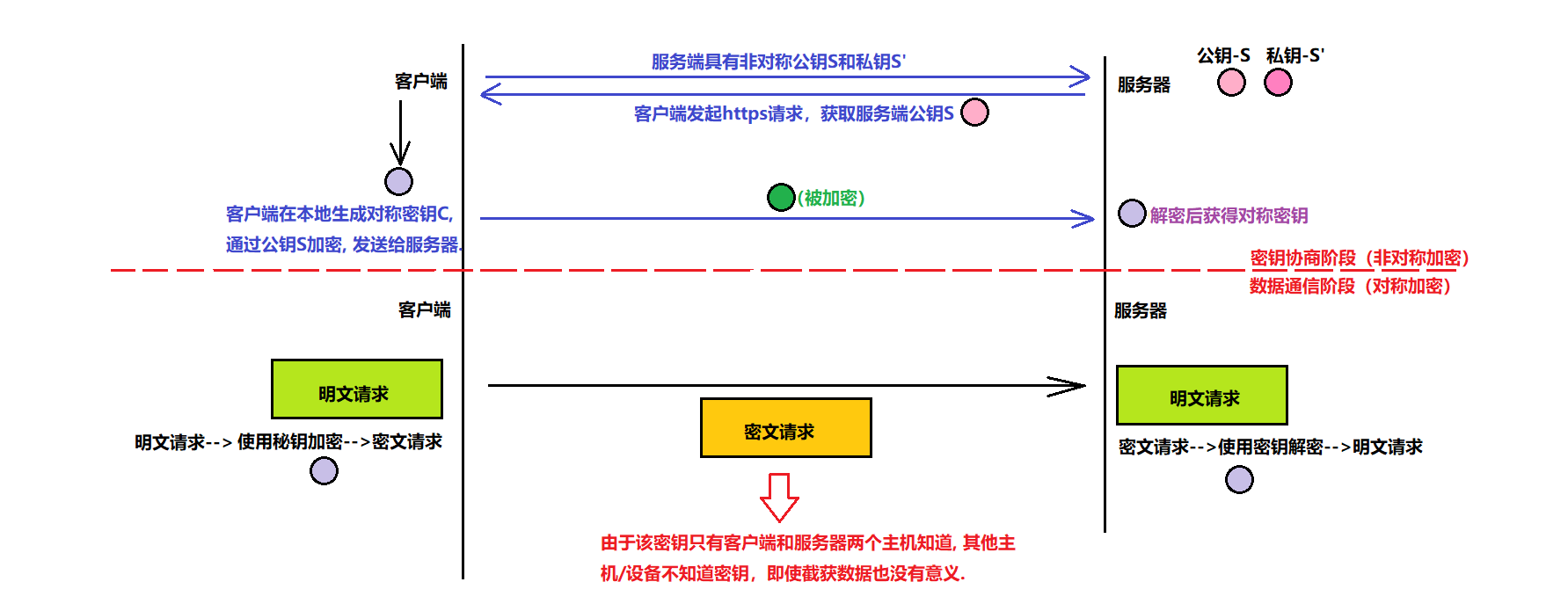
此方案问题说明:
1、依旧有安全问题:以下为一个演示。
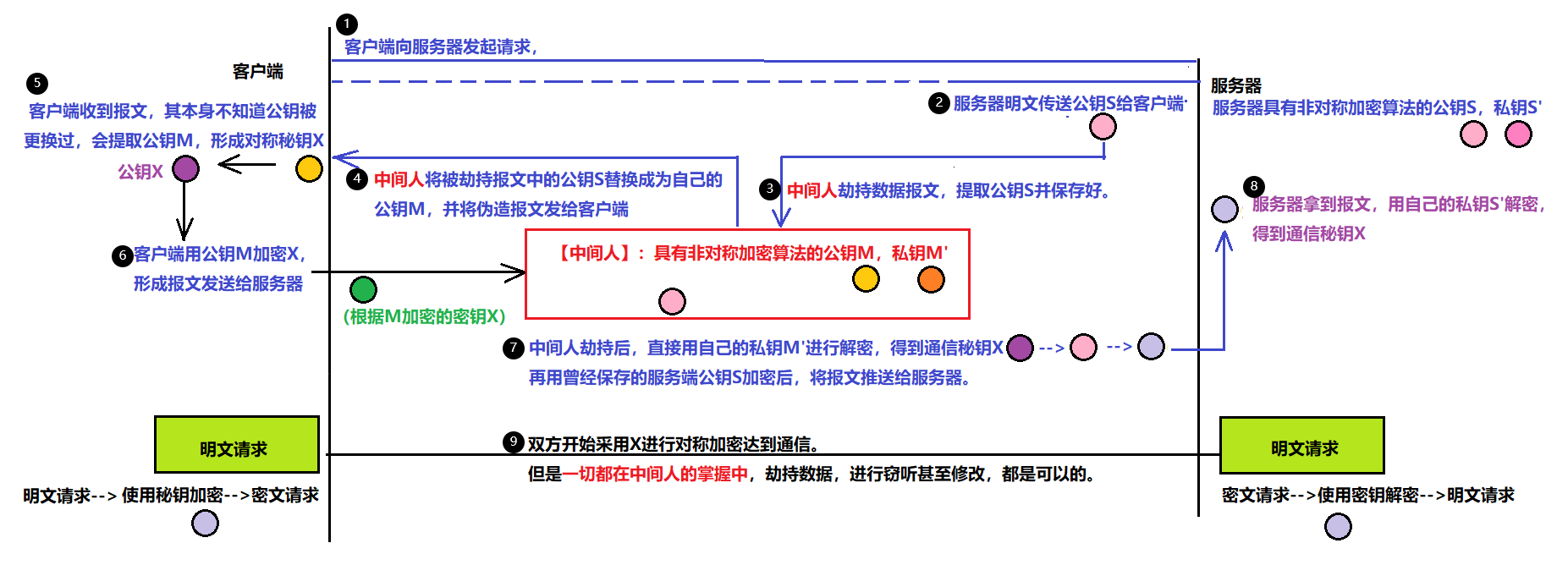
7.3.5、中间人攻击与CA证书认证流程
1)、问题引入
问题:在上述过程中,为什么中间人能够攻击成功?

2)、认识CA认证
1、CA,Catificate Authority,它的作用就是提供证书(即服务器证书,由域名、公司信息、序列号和签名信息组成)加强服务端和客户端之间信息交互的安全性,以及证书运维相关服务。任何个体/组织都可以扮演 CA 的角色,只不过难以得到客户端的信任,能够受浏览器默认信任的 CA 大厂商有很多。
相关文章:细说 CA 和证书。
2、服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就⾏了,证书就如⾝份证,证明服务端公钥的权威性。
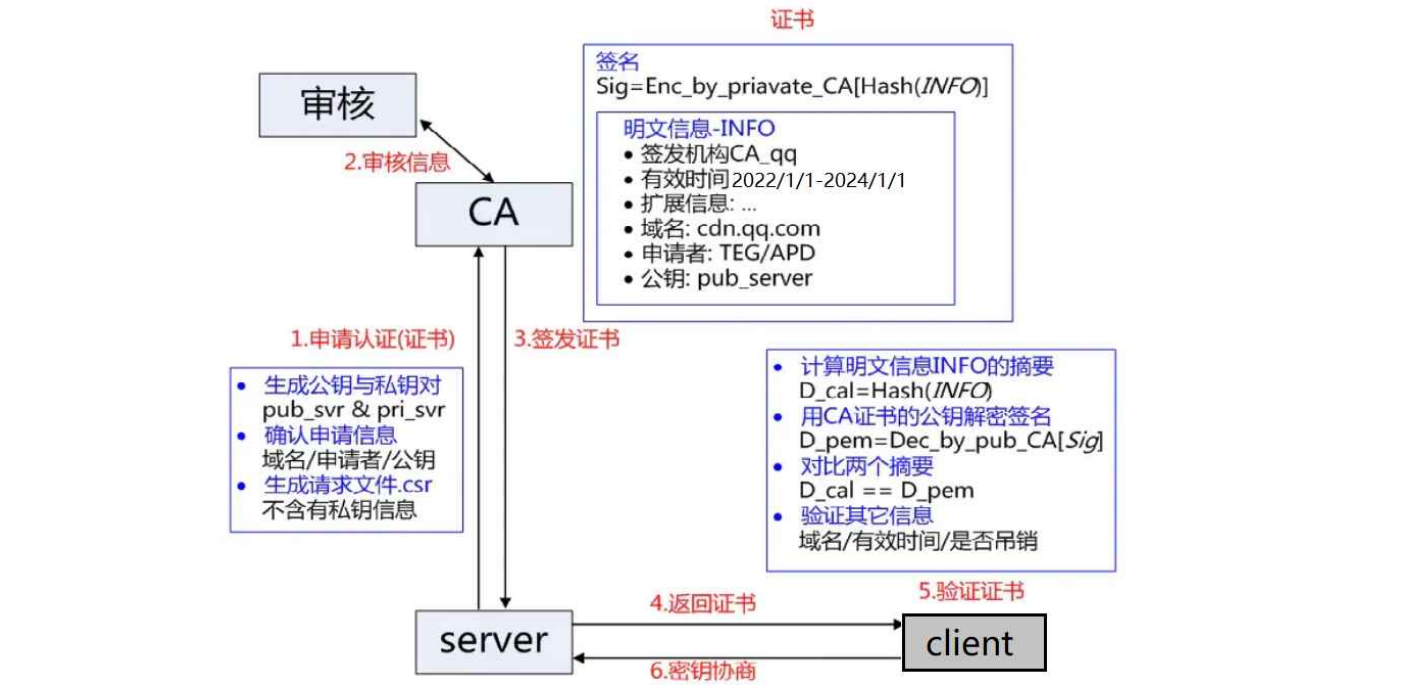
3)、理解数据签名(证书签发与验证)
【对于证书签发】当服务端申请CA证书的时候,CA机构会对该服务端进行审核,并专门为该网站形成数字签名,过程如下:
1. CA机构拥有非对称加密的私钥A和公钥A’
2. CA机构对服务端申请的证书明文数据进行hash散列,形成数据摘要。
3. 然后对数据摘要用CA私钥A’加密,得到数字签名S。服务端申请的证书明文和数字签名S共同组成了数字证书,这样⼀份数字证书就可以颁发给服务端了。
示意图如下:
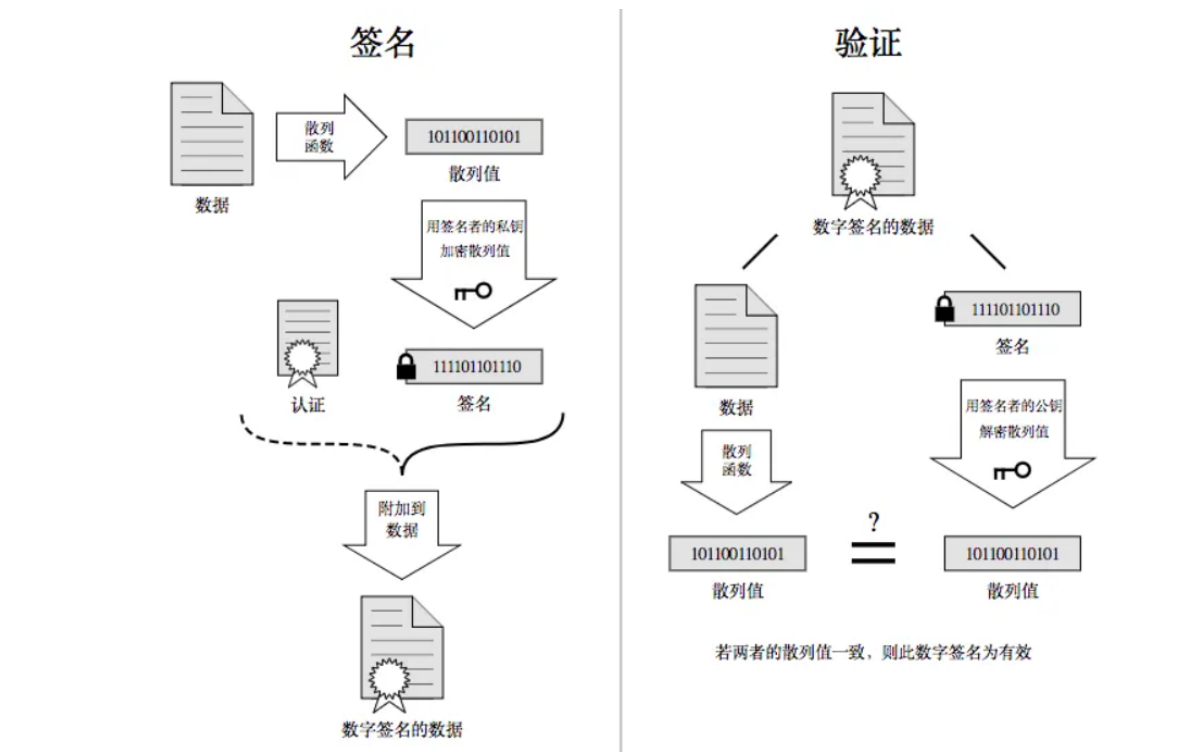
【对于证书验证】当客户端获取到这个证书之后, 会对证书进行校验,防止证书伪造:
1、判定证书的有效期是否过期。
2、判定证书的发布机构是否受信任。PS:操作系统中已内置的受信任的证书发布机构。
3、验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到⼀个 数据摘要(设为 hash1)。然后相同算法计算整个证书的 hash 值(设为 hash2)。对比 hash1 和 hash2 是否相等, 如果相等,则说明证书是没有被篡改过的。
7.3.6、方案 5 : 非对称加密 + 对称加密 + 证书认证
1)、基本说明
方式说明: 在客户端和服务器刚⼀建立连接的时候,服务器给客户端返回⼀个证书,该证书包含了之前服务端的公钥,也包含了⽹站的⾝份信息。
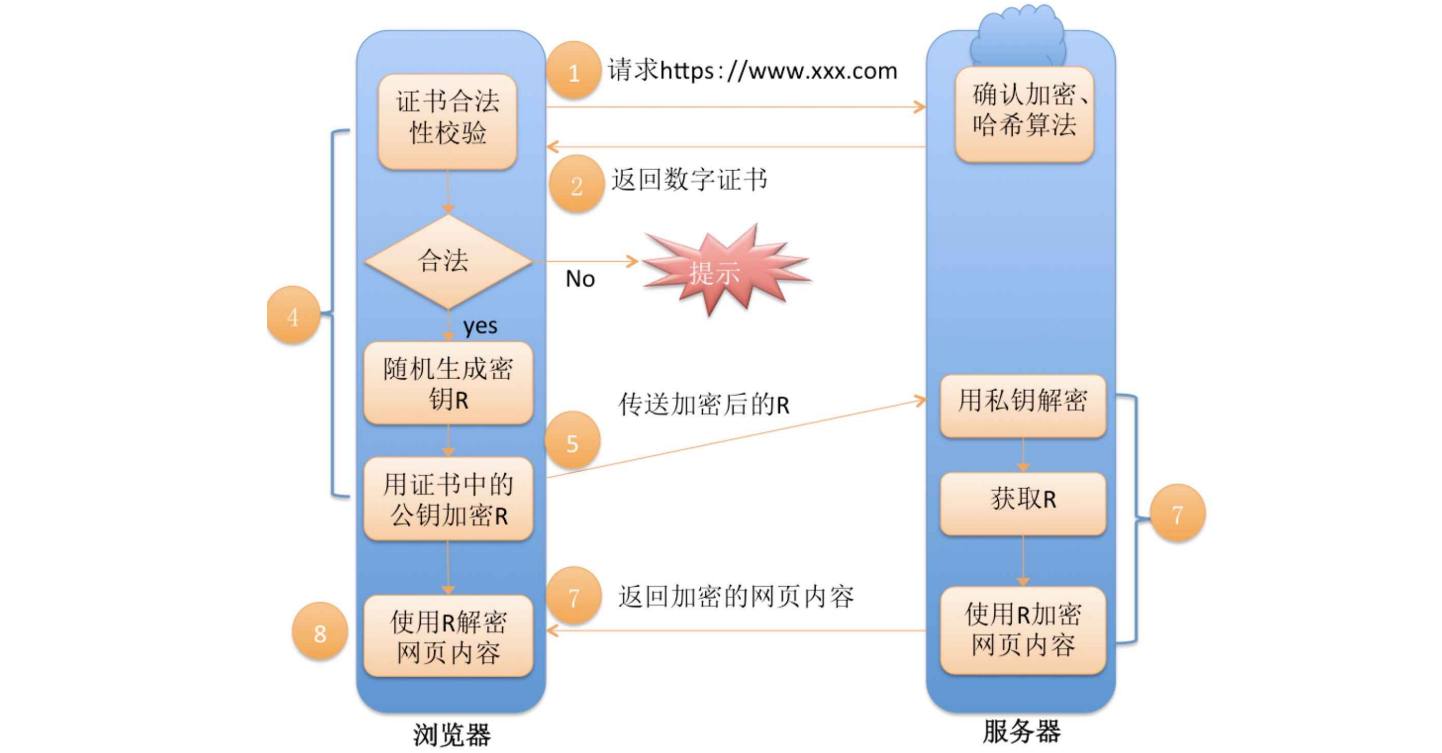
与方案4相比,数据通信阶段不变,仍旧采用对称加密。只是在密钥协商阶段引入了第三方CA机构,用于验证服务器身份信息,防止客户端与服务器直接通信时,由于不关心彼此身份而导致中间人钻篓子。
第⼀组(非对称加密):用于校验证书是否被篡改。服务器在客户端请求后返回携带签名的证书,客户端通过CA的公钥进行证书验证,保证证书的合法性,进⼀步保证证书中携带的服务端公钥权威性。
第二组(非对称加密):客户端用收到的CA证书中的公钥(是可被信任的)给随机生成的对称加密的密钥加密,传输给服务器,服务器通过私钥解密获取到对称加密密钥。
第三组(对称加密): 客户端和服务器后续传输的数据都通过这个对称密钥加密解密。
2)、常见问题
问题一:中间人有没有可能篡改该证书?
回答:若中间人篡改了证书的明⽂,由于他没有CA机构的私钥,所以无法hash之后用私钥加密形成签名,那么也就没法办法对篡改后的证书形成匹配的签名。
如果强行篡改,客户端收到该证书后会发现明文和签名解密后的值不⼀致,则说明证书已被篡改,证书不可信,从而终止向服务器传输信息,防止信息泄露给中间⼈。
问题二:中间人有没有可能掉包整个证书?
回答:因为中间⼈没有CA私钥,所以⽆法制作假的证书。如果要想不被客户端识别到,中间⼈只能以自己的身份向CA申请证书进行掉包。这个确实能做到证书的整体掉包,但是由于证书明文中包含了域名等服务端认证信息,客户端依旧能够识别出来。