Abstract
车道标记检测是自动驾驶和驾驶辅助系统的重要组成部分。采用基于行的车道表示的现代深度车道检测方法在车道检测基准测试中表现出色。通过初步的Oracle实验,我们首先拆分了车道表示组件,以确定我们方法的方向。我们的研究表明,现有的基于行的检测器已经能预测出正确的车道位置,而准确表示与地面实况相交-不相交(IoU)的置信度分数是最有利的。基于这一发现,我们提出了 LaneIoU,通过考虑局部车道角度,更好地与度量相关联。我们开发了一种新颖的检测器(CLRerNet),它采用 LaneIoU 作为目标分配成本和损失函数,旨在提高置信度分数的质量。通过包括交叉验证在内的仔细、公平的基准测试,我们证明了 CLRerNet 的性能大大优于最先进的方法--在 CULane 上,CLRerNet 的 F1 得分为 81.43%,而现有方法为 80.47%;在 CurveLanes 上,CLRerNet 的 F1 得分为 86.47%,而现有方法为 86.10%。代码和模型见 https://github.com/hirotomusiker/CLRerNet。
1. Introduction
车道(标记)检测在自动驾驶和驾驶辅助系统中发挥着重要作用。与其他计算机视觉任务一样,卷积神经网络(CNN)的出现在车道检测性能方面带来了快速进步。就车道实例表示而言,现代车道检测方法可分为四类。基于分割的表示法 [18, 27] 和基于关键点的表示法 [21] 分别将车道视为分割掩膜和关键点。参数表示法 [25, 16] 利用曲线参数来回归车道形状。基于行的表示法 [24、28、19、20、15] 将车道视为特定水平线上的一组坐标。前两种表示法用于自下而上的检测模式,即直接检测图像中的车道位置,然后将其分组为车道实例。后两种则用于自上而下的实例检测方法,在这种方法中,每个车道检测都被视为全局车道实例和一组局部车道点。在上述表示类型中,基于行的表示是检测性能的事实标准。我们选择基于行的方法中性能最好的 CLRNet [28] 作为基准。
车道检测的性能取决于车道点定位和实例分类。车道检测基准[18, 7]采用了预测车道与地面实况(GT)车道之间基于分割掩码的交集联合(IoU)作为评估指标。在计算 F1 分数时,分数高于预定阈值的预测车道被视为有效预测。因此,与 GT 之间基于分段的 IoU 较大的预测车道应具有较大的分类分数。
为了确定我们方法的方向,我们首先进行了初步的甲骨文(Oracle)实验 h,用Oracle值替换置信分、锚参数和每个预测的长度。将置信度分数设为oracle值后,F1得分接近完美的98.47%。这一结果表明,预测结果中已经包含了正确的车道,但是还需要准确预测置信度得分,以表示度量 IoU。图 1(中)显示了所有预测(蓝色)和 GT(橙色虚线)之间的比较。预测结果的颜色深度与其置信度得分成正比。最左侧的预测是高置信度的假阳性,与地面实况不符,但在具有高 IoU 的 GT 附近有一个正确的低置信度预测。
下一个问题是:如何将基于分割的 IoU 实现为学习目标?在基于行的方法中,预测车道和 GT 车道都表示为固定行的 x 坐标集。[28]引入了 LineIoU 损失,以逐行测量交集和联合,并分别求和。然而,这种方法并不等同于基于分割的 IoU,尤其是对于非垂直、倾斜的车道(如图 1 底部)或曲线。我们引入了被称为 LaneIoU 的新型 IoU,它将车道的局部车道角考虑在内。LaneIoU 整合了每一行的角度感知交叉和联合,以匹配基于分割的 IoU。
基于行的方法为每个锚点学习全局车道概率分数。最近的物体检测器[4, 5]中采用的动态样本分配对于车道检测训练也很有效[28]。预测车道和 GT 之间的 IoU 矩阵和成本矩阵分别决定了为每个 GT 分配锚点的数量以及分配哪些锚点。分配的锚点的置信度目标设置为正(1)。因此,样本分配负责学习置信度分数。我们在样本分配中引入了 LaneIoU,以使检测器的置信度得分接近基于分割的 IoU。LaneIoU 动态决定要分配的锚点数量,并以成本函数的形式确定要分配的锚点的优先级。此外,我们的 LaneIoU 还取代了用于回归水平坐标的 loU 损失,从而对不同倾斜角度的预测车道进行适当的惩罚。将 LaneIoU 整合到 CLRNet [28] 中使检测器的训练更加简单,因此我们将此方法命名为 CLRerNet。
我们在 CULane 和 CurveLanes 上进行了大量实验,展示了 LaneIoU 的有效性,并报告了这两个数据集的最新结果。重要的是,为了获得可靠、公平的基准,我们在每个实验条件下采用了五个模型的平均得分,而之前的工作只显示了一个模型的得分。此外,车道检测评估中使用的 F1 指标对检测器的车道置信度阈值非常敏感,因此我们通过对训练分割进行 5 倍交叉验证来确定阈值。
我们在本文中的贡献包括三个方面:
- 更清晰的关注点: 通过初步的Oracle实验,我们表明正确的车道位置已经在现有检测器的预测范围内,而代表与地面实况相交-联合(IoU)的置信度分数是提高性能的最有效方法
- 更清晰的训练方法: 作为车道相似性函数,我们利用了与评估指标密切相关的 LaneIoU,并将其作为样本分配成本和回归目标整合到训练中。
- 更清晰的基准测试: 我们采用了多模型评估和基于交叉验证的分数阈值来进行公平的基准测试。LaneIoU 的有效性和通用性得到了验证,CLRerNet 在 CULane 和 CurveLanes 基准测试中达到了最先进水平。
2. Related Work
2.1. Object detection
Training sample assignment. 样本分配是物体检测的主要研究重点。检测头的建议被分配给地面实况样本。文献 [22, 13, 8, 12] 通过静态计算特征图网格上的锚点与 GT 框之间的 IoU 来分配 GT。[4] 为物体探测器的训练样本分配引入了最优转移分配(OTA),动态地将预测框分配给 GT。[5] 简化了 OTA 并实现了无迭代分配。
IoU functions. 为了实现精确的边框回归和快速收敛,人们提出了几种 IoU 函数的变体 [23, 29, 30]。例如,广义 IoU(GIoU)[23] 引入了边界框的最小凸壳,使 IoU 即使在边界框不重叠时也可微分。我们的 LaneIoU 以 GIoU 为基础,但在基于行的表示中新增了曲线之间的 IoU 计算。
2.2. Lane detection
车道检测范例按车道表示类型分组,即基于分割的表示、基于关键点的表示、基于行的表示和参数表示。
Segmentation-based representation. 这种方法是基于像素自下而上地估计车道存在的概率。SCNN [18] 和 RESA [27] 采用语义分割范式将车道实例划分为每个像素上的不同类别。车道和类别之间的对应关系由注释决定,因此并不灵活(例如,某些车道位置可能属于两个类别)。基准数据集 [18, 7] 采用像素级 IoU 来比较预测车道和 GT,对基于分割的方法很友好。但是,这些方法没有将车道作为整体实例处理,需要进行计算成本高昂的后处理。[19,28]仅在训练期间利用分割任务作为辅助损失来改进骨干网络。我们沿用了这些方法,并采用了辅助分支和损失。
Keypoint-based representation. 与人体姿态估计类似,车道点作为关键点进行检测,然后分组为车道实例。PINet [11] 采用测试时间可分离的堆叠沙漏网络来学习关键点概率,并将关键点聚类为车道实例。FOLOLane [21] 也将车道作为关键点进行检测,其灵感来自自下而上的人体姿态检测方法 [1]。GANet [10] 将检测到的关键点的偏移量从相应车道实例的起点进行回归。这一系列方法需要进行后处理,将车道点分组为车道实例,计算成本较高。
Parametric representation. 在这一工作流程中,车道实例表示为一组曲线参数。PolyLaneNet [25] 使用多项式系数来表示曲线。LSTR [16] 采用基于端到端变换器的车道参数集检测。BSNet [2] 选择准均匀 b-spline 曲线,在该类别中显示出最高的 F1 分数。这些方法的推理速度相对较快,但一个参数的错误会对车道形状产生整体影响。
Row-based representation. 车道实例表示为固定行的一组 x 坐标。LaneATT [24] 采用车道锚点来学习每个锚点的置信度得分和局部 x 坐标位移。锚点被定义为一个固定角度和一个起点。训练目标是根据每个锚点到 GT 之间的水平距离静态分配的。CLRNet [28] 采用可学习的锚参数(起点 xa、ya 和 θa)和长度 l。在样本分配方面,采用简化的最优传输分配 [5(yolox)],动态分配最接近每个地面实况的预测值。这两种方法都通过锚点汇集特征图,并将提取的特征反馈给头部网络。头部网络为每个锚点输出分类和回归张量。这种模式与两阶段物体检测方法相对应,例如 UFLD [19] 通过扁平化特征图捕捉全局特征,并学习行向车道位置分类。UFLDv2 [20] 扩展了 [19] 的行向和列向车道表示法,以处理近水平车道。CondLaneNet [15] 可学习车道起点的概率热图,并从中提取动态卷积核。动态卷积应用于特征图,从而进行行向车道点分类和 x 坐标回归。LaneFormer [6] 采用了行和列注意力transformer,以端到端方式检测车道实例。此外,车辆检测结果也会反馈给解码器,使流程具有对象感知能力。就检测性能而言,基于行的表示是四种表示类型中的事实标准。
3. Methods
3.1. Network design and losses
在第 2 节所述的四种类型中,基于行的表示法 [28, 15, 24] 利用了最准确但最简单的检测管道。在基于行的方法中,我们采用了性能最好的 CLRNet [28] 作为基准。网络示意图如图 2 所示。骨干网络(如 ResNet [9] 和 DLA [26])和上采样网络提取多级特征图,其空间维度为输入图像的(1/8, 1/16, 1/32)。初始锚点由 Na 可学习的锚点参数 () 形成,其中 (
) 为起点,
为锚点的倾斜度。特征图沿每个锚点采样,并馈送至卷积层和全连接(FC)层。FC 层输出分类对数(classification logits) c、锚点细化(anchor refinement)
、长度
和局部
坐标细化(local xcoordinate refinement )
张量。由
和
精化的锚点对更高分辨率的特征图进行重新采样,该过程重复三次。汇集的特征通过交叉注意力与特征图交互,并在不同的细化阶段进行串联(concatenated )。车道预测以分类(置信度)对数(logits )和根据最终
、
和
计算的
行
坐标集表示。有关细化机制的更多详情,请参阅 [28]。在训练过程中,通过动态分配器[5]分配接近 GT 的预测结果。分配的预测结果向相应的 GT 回归,并被学习归类为阳性。

其中,是用于回归锚点参数(
)和
的平滑-L1 损失,
是用于正负锚点分类的焦点损失[14],
是用于每像素分割掩码的辅助交叉熵损失,
是新引入的 LaneIoU 损失。
3.2. Oracle experiments
我们进行了初步的预言实验,以确定我们方法的方向。我们用 GT 部分地替换了经过训练的基线模型中的预测组件,以分析每个车道表示组件的改进空间有多大。表 1 显示了预言实验结果。基线模型(第一行)是在没有冗余帧的情况下训练的 CLRNet-DLA34。置信度阈值设置为 0.39,这是通过交叉验证获得的(见第 4.1 和 4.2 小节)。
接下来,我们计算预测和 GT 之间的度量 IoU,作为 Oracle 信心分数。对于每项预测,GT 中的最大 IoU 将被用作 Oracle 分数。在这种情况下,预测的车道坐标不会改变。F1--50跃升至98.47--接近满分(第二行)。这一结果表明,预测结果中已经包含了正确的车道,但是置信度分数需要准确地代表 IoU 指标。
其他组成部分是决定车道坐标的锚参数--和长度
。我们用 GT 的参数来改变锚参数和车道长度(分别为第三行和第四行)。虽然行向细化
没有改变,但Oracle锚参数将
提高了 9 个点。另一方面,oracle 长度对性能的影响不大。这些结果提出了第二个建议,即锚参数(
)对车道定位非常重要。
我们将重点放在第一项发现上,旨在通过改进车道相似度函数来学习高质量的置信度分数。
3.3. LaneIoU
现有方法 [15] 和 [28] 分别利用水平距离和水平 IoU 作为相似性函数。然而,这些定义与使用分割掩码计算的度量 IoU 并不匹配。例如,当车道倾斜时,特定度量 IoU 所对应的水平距离要大于垂直车道的水平距离。为了弥补这一差距,我们引入了一种可微分的局部角度感知 IoU 定义,即车道 IoU。图 3 显示了两个倾斜曲线之间的 IoU 计算示例。我们在同一车道实例对上比较了 LineIoU [28] 和 LaneIoU。LineIoU 无论车道角度如何,都会应用恒定的虚拟宽度,并且虚拟车道在倾斜部分会变得 "薄"。在我们的 LaneIoU 中,计算重叠和联合时会考虑每一行局部车道部分的倾斜度。我们将定义为同时存在车道
和
的 y 切片集合,而
或
则定义为只存在一条车道的 y 切片集合。LaneIoU 的计算公式为

其中和
的定义为

当时。当车道重叠时,车道交点为正,否则为负。如果
,
和
的计算方法如下:
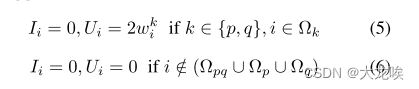
计算虚拟车道宽度和
时要考虑局部角度:

其中和
和
代表车道点坐标的局部变化。等式 7 补偿了车道的倾斜变化,代表了一般的行向车道 IoU 计算。当车道垂直时,
等于
,当车道倾斜时,
越大。CULane 指标采用 30 个像素,分辨率为(590,1640)。
注:
LineIoU存在问题
从下面图片及公式(CLRNet)可发现, 当车道线越水平时, 通过该公式计算出来的IoU越大, 比如从两侧出发的车道线, 预测线和GT离得很近, 但是使用该LineIoU计算得到较大的值, 导致在分配正负样本和计算loss时候均带来副作用, 导致模型效果不佳;
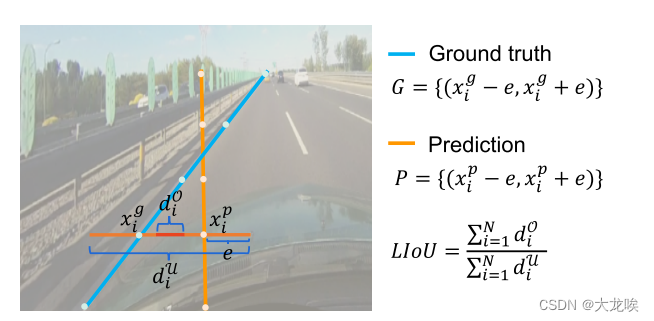
注意: 这里的e是一个常数, CLRNet中取得为15

而LaneIoU仅仅把
换成了
从一个固定值变成动态计算, 主要计算由公式7给出,
在图 4 中,通过计算与 CULane 指标的相关性,比较了 LineIoU [28] 和我们的 LaneIoU。我们用 LineIoU 或 LaneIoU 值代替每个预测的置信度得分,并计算指标 IoU。每次预测都会选择 IoU 最大的 GT。显然,我们的 LaneIoU 与指标 IoU 的相关性更好,这主要是由于消除了车道角度的影响。
3.4. Sample assignment
在训练过程中,如果锚点被指定为正值,那么置信度得分就会很高。我们采用 LaneIoU 进行样本分配,使检测器的置信分接近基于分割的 IoU。[28]采用 SimOTA 分配器[5]为每个 GT 车道动态分配
个锚点。锚点
的数量通过计算所有锚点的正 IoU 的总和来确定。我们采用的 LaneIoU 为
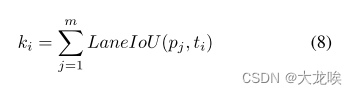
其中,是锚点的数量,
是
个 GT 车道的索引;
是预测的车道,
是
个预测的索引;
从 1 到
之间剪切。成本矩阵决定了每个 GT 分配的优先级。在物体检测中,[5] 采用了边界框 IoU 和分类成本之和。在车道检测中,CLRNet [28] 使用了分类成本和车道相似性成本,后者由水平距离、角度差和起点距离组成。不过,直接代表评价指标的成本更适合用于确定预测的优先级。我们将成本矩阵定义为
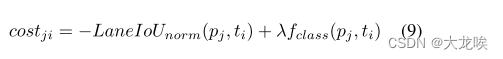
其中,是平衡两种成本的参数,
是分类成本函数,如焦点损失( focal loss ) [14]。LaneIoU 从最小值到最大值进行归一化。公式(等式 8 和 9)实现了动态样本分配,即根据评价指标优先分配适当数量的锚点。总之,与 CLRNet 相比,我们的 CLRerNet 引入了 LaneIoU 作为动态
分配函数、分配成本函数和损失函数,以学习与指标 IoU 更为相关的高质量置信度分数。
4. Experiments
4.1. Datasets
CULane 数据集1[18] 是事实上的标准车道检测基准数据集,包含 88,880 个训练帧、9,675 个验证帧和 34,680 个带有车道点注释的测试帧。测试分帧具有基于帧的场景注释,如正常、拥挤和曲线(见表 2)。CurveLanes2 [7] 数据集包含具有挑战性的曲线场景,由 100k 训练帧、20k 验证帧和 30k 测试帧组成。我们按照文献[15]的方法,使用val 分割进行评估。
Removing the redundant train data. CULane 数据集中包含了不可忽略的冗余帧,在这些冗余帧中,自我车辆(ego-vehicle)处于静止状态,车道注释也没有变化。我们发现,只需删除平均像素值与前一帧之差低于阈值的帧,即可避免对冗余帧的过度拟合。最佳阈值(=15)是通过经验验证选取的,详见补充材料。剩下的 55,698 帧(62.7%)用于训练。CLRNet-DLA34 的 F1 分数从 80.30±0.05 提高到 80.86±0.06(N = 5),训练时间同样为 15 次。
4.2. Training and evaluation
这些模型是在 PyTorch 和 MMDetection [3] 上实现的,并使用 AdamW [17] 优化器进行了 15 次历时训练。初始学习率为 0.0006,并应用余弦衰减。对于 CULane 数据集,我们裁剪了 y = 270 以下的输入图像,并将其大小调整为 (800, 320) 像素。按照 [28] 的方法,采用水平翻转、随机亮度和对比度、随机 HSV 调制、运动和中值模糊以及随机仿射调制作为数据增强。测试时只采用裁剪和调整大小,不应用测试时增强。在 CLRerNet 中,引入了 LaneIoU 作为损失函数、动态-k 计算和分配损失函数。为平衡分类成本,将损失和动态-k 的设为 15/800,成本设为 60/800。公式 1 中的损失权重与 [28] 相同,只是将
设为 4。此外,我们还对 CLRerNet-DLA34 模型进行了基准测试,该模型采用指数移动平均法(EMA)训练了 60 个历元。学习率衰减未应用,EMA 的动量设置为 0.0001。
为了验证我们方法的通用性,我们在 LaneATT[24] 中加入了基于 LaneIoU 的样本分配。最初,LaneATT 通过水平距离阈值将不可学习的静态锚点分配给 GT。我们通过计算预测车道和 GT 之间的 LaneIoU 来确定锚点的优先级,从而分配正置信度目标。更多详情请参见补充材料。
对于 CurveLanes [7],我们沿用了 [15] 的训练设置,即输入分辨率为 (800,320)。为了利用辅助分割损失,我们沿所有车道标签绘制宽度为 30 像素的分割掩码。与 [18] 不同的是,我们将所有车道掩码设置为第一类(前景)。由于没有测试注释,我们在验证分割上评估我们的方法。按照文献[15],我们将评估分辨率设为 (224,224) ,线宽设为 5。计算损失和动态 k 时,设为 5/224,计算成本时,
为 20/224。
Evaluation metric. 我们采用 F1 分数[18]作为评估指标。通过比较宽度为 30 像素的分割掩膜,计算出预测车道和地面实况之间的 IoU 矩阵(图 1 下部)。根据 IoU 矩阵,使用线性和赋值计算一对一匹配,将 IoU 超过 tIoU 的预测-GT 对视为真阳性(TP)。未匹配的预测和 GT 分别被视为假阳性(FP)和假阴性(FN)。我们采用两个 tIoU 值来计算 IoU: 0.5 和 0.75。F1 分数的计算公式为
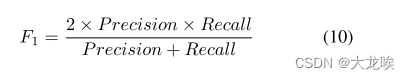
Cross validation and test. F1 指标对检测置信度得分的阈值很敏感。我们将训练视频随机分为五组,对训练视频进行五倍交叉验证。每个阈值的 F1 得分为 5 倍结果的平均值,并通过取其 argmax 来确定最佳阈值。
此外,我们发现使用不同随机种子训练的模型的 F1 分数偏差也不容忽视。例如,CLRNet-DLA34 的 F1 分数从最低的 80.20 到最高的 80.34 不等(N = 5)。为了在测试分割上获得更可靠、更公平的基准,我们在每个条件下使用不同的随机种子训练五个模型,并计算指标的平均值和标准偏差,在此基础上应用五倍交叉验证获得的置信度阈值。据我们所知,我们是第一个在车道检测中执行上述基准协议的人。至于没有测试注释的 CurveLanees 数据集,我们报告了验证分割中与置信度阈值相关的最大 F1 分数。
4.3. CULane benchmark results
此外,CULane 测试集的基准结果如表 2 所示。双横线下的各行是我们的实验结果。对于每个条件(行),我们显示了使用不同种子训练的五个模型的平均度量值。采用的是 5 倍交叉验证得到的置信度阈值。测试场景列中显示了分数,但交叉指标除外,显示的是误报数量。表 2 中的所有 FPS 结果都是使用 GeForce RTX 3090 GPU 测得的。
和
是使用我们的实现训练的基准模型。我们的方法
采用 LaneIoU 进行动态 K 计算、分配成本和损失函数。
是
的增强版,使用 EMA 训练了 60 个历元。
引入 LaneIoU 后,带有 DLA34 的在 F150 方面比
高出 0.26%。此外,增强模型
的平均
= 81.43%,远远超过了之前的方法(
= 80.47%,CLRNet+DLA34 的单次实验),达到了最先进的性能。LaneIoU 的性能改进还体现在具有其他骨干网的模型上--ResNet34 从 80.54% 提高到 80.76% (+0.22%),ResNet101 从 80.67% 提高到 80.91% (+0.24%)。基于 LaneIoU 的分配将
提高了 0.68%,验证了我们方法的通用性。CLRerNet 没有增加测试时间的计算复杂度,显示出与 CLRNet 相同的 GFLOPs 和 FPS。
图 5 显示了 CULane 测试集的定性结果。我们的能够在具有挑战性的场景中检测到车道。只有 CLRerNet 能以较高的置信度检测到第一幅图像(上图)中最右侧的倾斜车道和第二幅图像(下图)中最左侧的车道。这些示例定性地表明,CLRerNet 能够给出更多正确的预测分数,这将在 4.5 小节中进行分析。
4.4. CurveLanes validation results
CurveLane 的验证结果如表 3 所示。使用 DLA34 主干网的默认 CLRNet[28] 与 CondLane-L[15] 的 F1 分数相同,但计算成本更低。请注意,我们的结果是五次训练的平均值。置信度阈值设置为经验最优值 0.44。CLRerNet 的表现明显优于基线 0.37%,达到新的最先进水平 86.47%。
4.5. Ablation study and analysis
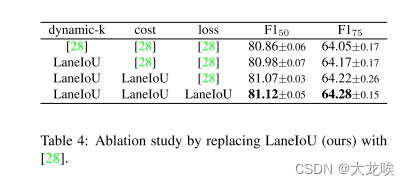
我们将 LaneIoU 从动态 k 计算、分配成本和损失函数中剔除,从而证实了我们方法的有效性。使用 DLA34 主干网的 CLRerNet 在每个条件下进行训练,省略多余的训练数据。我们按照 4.2 小节中描述的基准协议,对每个条件训练和验证了 10 个模型(5 个种子 + 5 个折叠)。表 4 中的结果显示,在动态 k 确定、成本函数和损失函数方面,分别用 [28] 替换 LaneIoU 会降低性能。通过 LaneIoU 确定每个 GT 车道的分配数量,可减轻车道倾斜度变化造成的不均匀性。基于 LaneIoU 的分配成本(式 9)优先考虑与 GT 具有较高度量 IoU 的预测车道,从而实现更准确的置信学习,如 3.2 小节所述。用车道 IoU 损失代替车道 IoU 损失还能减轻回归惩罚的倾斜依赖性。
图 6 显示了 CLRerNet 和 CLRNet 在不同角度范围内每个 GT 的锚点分配数的比较。分配数是在训练过程中累积并取平均值的。角度使用 GT 车道以(800,320)分辨率计算,90◦对应垂直车道。通过利用 LaneIoU,分配数在车道角度方面变得更加均匀,尤其是在 GT 通常存在的 至
和
至
角度范围内。
指定锚点的置信度目标被 LaneIoU 设置为正优先级。因此,不同车道角度的置信度训练更加均匀。从图 7 中可以看出,在非垂直角度范围内,CLRerNet 的预测置信度得分与度量 IoU 值之间的 l1 误差有所改善,这也证实了 LaneIoU 的有效性。
Discussion. 虽然 CLRerNet 的性能有了显著提高,但最佳 CLRerNet 模型的性能(81.43%)与oracle置信情况下的性能(98.47%)之间仍有差距。标签波动和数据不平衡等面向数据集的问题被认为是造成差距的部分原因。例如,在 CULane 测试集中,有些情况的检测非常困难(图 8)。如表 2 所示,Noline 测试类别最具挑战性,因为道路上没有视觉标记。这种情况下很容易出现标签波动和不一致。同样,静止场景等数据不平衡也会极大地影响模型训练。正如第 4.1 小节所述,我们发现减轻数据不平衡会显著提高性能。
5. Conclusion
我们通过oracle实验拆分了车道预测组件,并证明了高质量置信度对于更准确的车道检测的重要性。为了使置信度分数代表 IoU 指标,我们提出了新的 LaneIoU,并将其集成到基于行的车道检测基线中。通过引入 LaneIoU 作为样本分配和损失函数,开发了一种名为 CLRerNet 的新型检测器。利用五种子模型和五倍交叉验证,采用了统计公平基准协议。在具有挑战性的 CULane 和 CurveLanes 数据集上,CLRerNet 达到了最先进的性能,大大超过了基准。我们相信,我们的oracle 实验、基于 LaneIoU 的训练和基准协议将为业界带来更清晰的车道检测视角。
图和表
图
图 1:车道检测示例。上图:地面实况。中图:所有预测结果(蓝色,置信度越高则越深)和地面实况(橙色虚线)。下图:通过比较预测结果(蓝色)和地面实况(橙色)的分割掩码计算度量 IoU。以彩色显示效果最佳。

图2:CLRerNet的网络示意图。

图 3:在车道 A 和车道 B 之间计算 LineIoU [28] 和 LaneIoU 的示例。虚线矩形内的 、
和
分别代表车道宽度、[28] 的恒定宽度和我们的角度感知宽度。
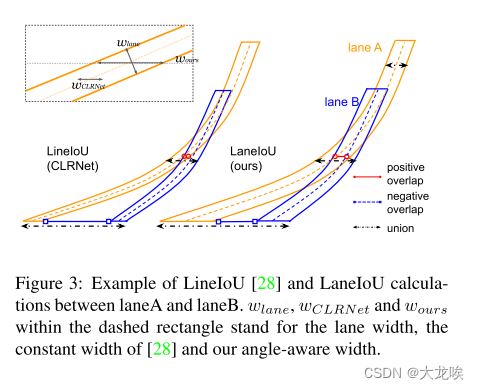
图 4:CULane 指标 IoU 与 (a) LineIoU [28] 和 (b) LaneIoU(我们的)之间的相关性。
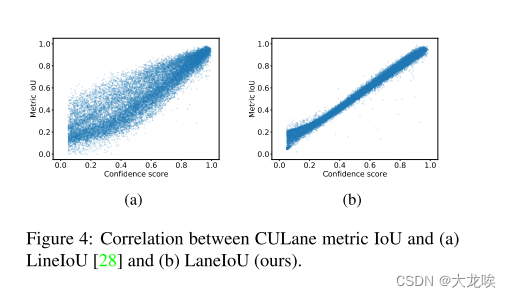
图 5:比较 LaneATT、CLRNet 和我们的的定性结果。预测和 GT 分别显示为蓝色和橙色。置信度不足的预测结果显示为蓝色圆圈。

图 6:不同角度范围内的平均分配次数。
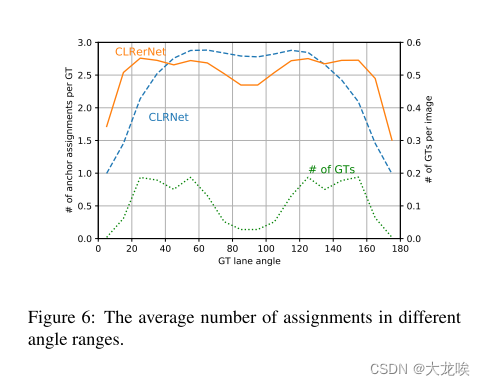
图 7:不同角度范围内置信度得分与指标 IoU 之间的平均误差。
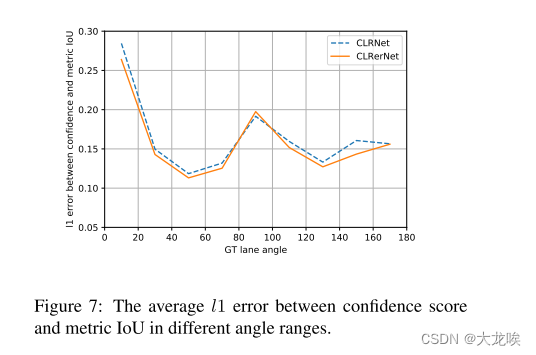
图 8:CULane 数据集中的极难案例。GT 重叠为橙色圆圈。

表
表1:Oracle实验结果。
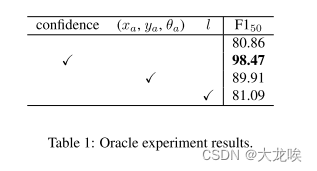
表 2:CULane 测试集的评估结果。我们的实验结果位于双横线下方。
表 3:各种方法在 CurveLanes val set 上的比较。我们的实验结果位于双横线下方。

表 4:用 [28] 代替 LaneIoU(我们的)进行消融研究。