| 文献阅读笔记(sel - CNN) | ||
| 简介 | 题目 | Visual Tracking with Fully Convolutional Networks |
| 作者 | Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu | |
| 原文链接 | http://202.118.75.4/lu/Paper/ICCV2015/iccv15_lijun.pdf 【DeepLearning】简述Visual Tracking with Fully Convolutional Networks-CSDN博客 | |
| 关键词 | Visual Tracking、fcn、sel - CNN | |
| 研究问题 |
顶层编码更抽象和更高层的语义特征,充当类别检测器,能够很好地区分不同类别的物体,对形变和遮挡具有很强的鲁棒性。 而下层携带更多的判别信息,能更好地将目标与外观相似的干扰目标分离,但是对外观的剧烈变化鲁棒性较差。
| |
| 研究方法 |
we propose to automatically switch the usage of these two layers during tracking depending on the occurrence of distracters.
A feature map selection method is developed to remove noisy and irrelevant feature maps, which can reduce computation redundancy and improve tracking accuracy.
through proper feature selection, the noisy feature maps not related to the representation of the target are cleared out and the remaining ones can more accurately highlight the target and suppress responses from background.
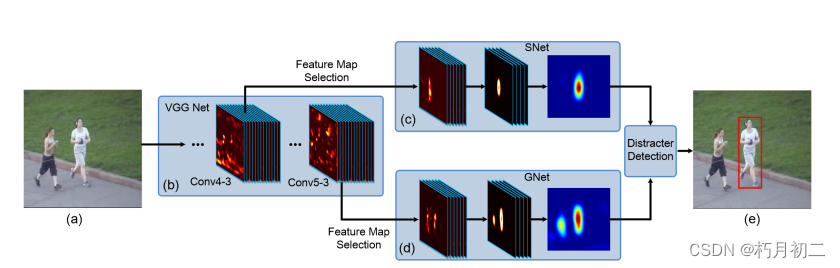
由13个卷积层和3个全连接层组成。 由于池化层和卷积层的存在,conv4 - 3和conv5 - 3层的感受野都非常大(分别为92 × 92和196 × 196像素)。 conv4 - 3层(第10层卷积层):捕获的特征对类内外观变化更加敏感,选择的特征图可以很好地将目标人物与其他非目标人物区分开。此外,不同的特征映射关注的对象部分也不同。 Conv5 - 3层(第13层卷积层):特征图编码了高层次的语义信息,能够更好地将人脸和非人脸物体区分开来。但它们在区分一个身份和另一个身份时的准确率低于conv4 - 3的特征图。 算法设置:
sel - CNN: sel - CNN模型由一个dropout层和一个没有任何非线性变换的卷积层组成。以待选特征图( conv4-3或con5-3)为输入,预测目标热力图M,M是以真值目标位置为中心的二维高斯,方差与目标尺寸成正比。通过最小化预测的前景热图( M )与目标热图M之间的平方损失来训练模型。
为了避免在线更新引入的背景噪声,我们固定GNet,只在第一帧初始化后更新SNet。SNet的更新遵循两种不同的规则:自适应规则和判别规则,其目的分别是使SNet适应目标外观变化和提高对前景和背景的判别能力。根据自适应规则,我们每隔20帧使用间隔帧中最可信的跟踪结果微调SNet。基于判别规则,当检测到干扰项时,利用第一帧和当前帧的跟踪结果,通过最小化进一步更新SNet。
| |
| 研究结论 | 虽然CNN特征图的感受野1较大,但激活的特征图稀疏且局部化。激活的区域与语义对象的区域高度相关。 许多CNN特征图对于从背景中区分特定目标的任务是有噪声或不相关的。 | |
| 创新不足 | 在低分辨率(LR)的情况下:FCNT具有较高的失败率, 是因为,VGG网络是利用高分辨率的图片进行预训练的。 | |
| 额外知识 | 前景掩码:前景掩码是指在图像处理中,将前景和背景分离的一种技术。它是一种二进制图像,其中前景像素被标记为1,背景像素被标记为0。前景掩码可以用于图像分割、目标跟踪、背景建模等应用中。在OpenCV中,可以使用不同的算法来生成前景掩码,例如基于高斯混合模型(GMM)的背景减法算法、基于自适应混合高斯模型(MOG)的背景减法算法等。 | |
(论文阅读24/100)Visual Tracking with Fully Convolutional Networks
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/179496.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
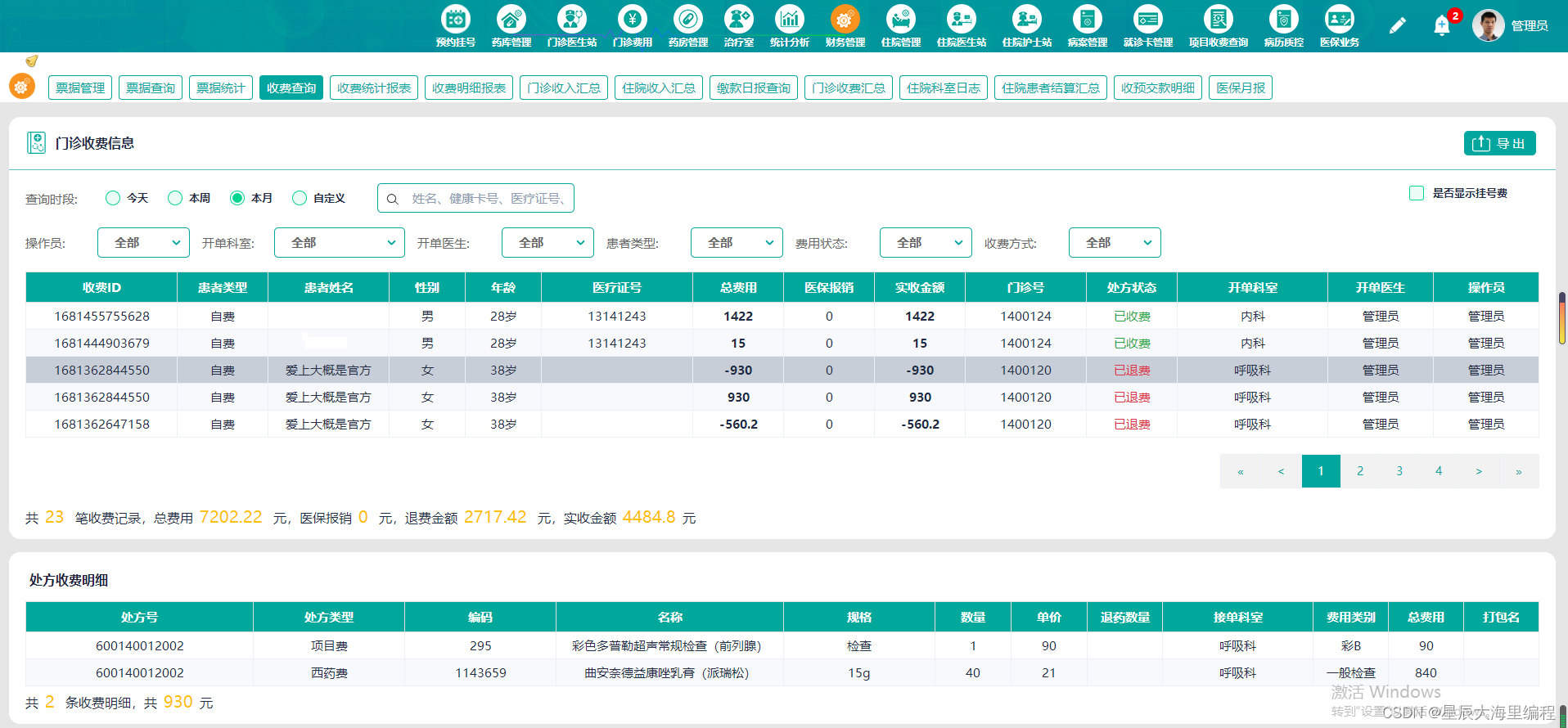
java语言开发B/S架构医院云HIS系统源码【springboot】
医院云HIS全称为基于云计算的医疗卫生信息系统( Cloud- Based Healthcare Information System),是运用云计算、大数据、物联网等新兴信息技术,按照现代医疗卫生管理要求,在一定区域范围内以数字化形式提供医疗卫生行业数据收集、存储、传递、…

Linux常用的磁盘使用情况命令汇总
1、查看分区使用百分比 df -h 2、查看指定目录磁盘使用情况 du -hac --max-depth1 /opt 参数:-a 查看所有文件,-c 汇总统计,max-depth1 查看深度为1,2级目录不再统计。 3、常用统计命令汇总
![[LeetCode]-622. 设计循环队列](https://img-blog.csdnimg.cn/4d11edafde924437baed73f24bada59a.gif)
[LeetCode]-622. 设计循环队列
目录
662. 设计循环队列
题目
思路
代码 662. 设计循环队列
622. 设计循环队列 - 力扣(LeetCode)https://leetcode.cn/problems/design-circular-queue/
题目 设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO&…
PostGIS学习教程六:几何图形(geometry)
文章目录 一、介绍二、元数据表三、表示真实世界的对象3.1、点(Points)3.2、线串(Linestring)3.3、多边形(Polygon)3.4、图形集合(Collection) 四、几何图形输入和输出五、从文本转换…
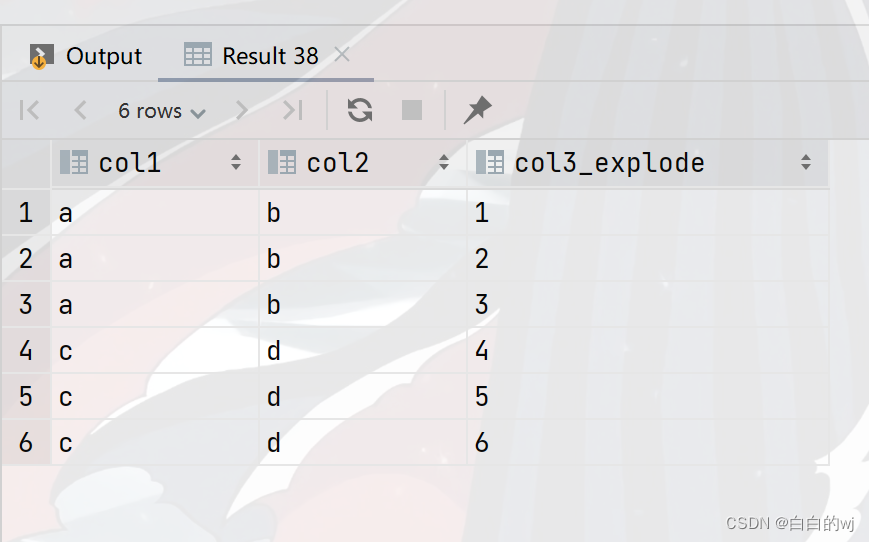
2023.11.16-hive sql高阶函数lateral view,与行转列,列转行
目录 0.lateral view简介
1.行转列 需求1:
需求2:
2.列转行
解题思路: 0.lateral view简介 hive函数 lateral view 主要功能是将原本汇总在一条(行)的数据拆分成多条(行)成虚拟表,再与原表进行笛卡尔积,…

JDK5,7,11,17特性
目录
JDK5
基本数据类型自动装箱拆箱
可变参数
增强for
注解
泛型
枚举
概述
定义
常用方法
自定义构造方法
枚举类中的抽象方法
JDK7
二进制字面量
switch
异常
try-with-resources,自动关流
JDK11
FileInputStream增强
String类增强
Stream流…
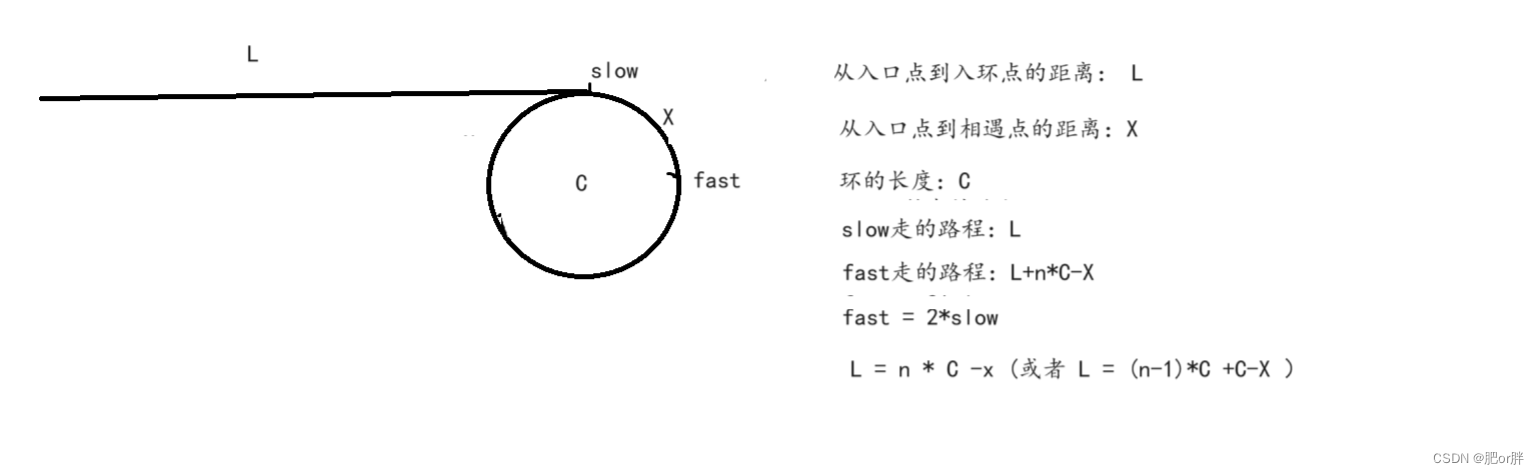
LeetCode - 142. 环形链表 II (C语言,快慢指针,配图)
如果你对快慢指针,环形链表有疑问,可以参考下面这篇文章,了解什么是环形链表后,再做这道题会非常简单,也更容易理解下面的图片公式等。
LeetCode - 141. 环形链表 (C语言,快慢指针,…
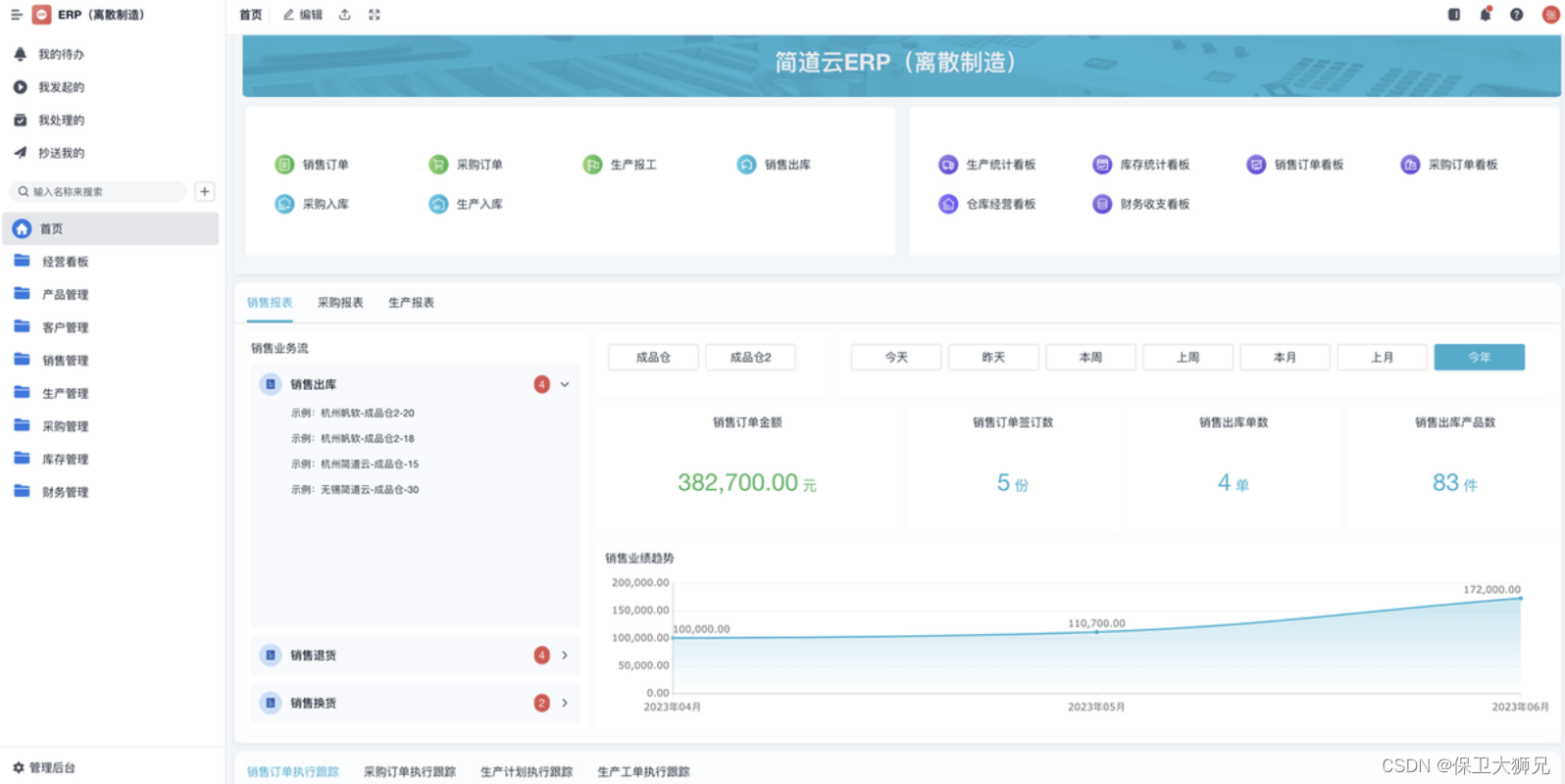
制造企业需要哪些管理系统?怎么选才最划算?
制造企业需要哪些管理系统?怎么选才最划算?
一般来说,制造企业必须要有的几大业务模块及其对应的业务系统有:
生产计划和控制:生产计划系统、MRP(物料需求计划)系统、ERP(企业资源…
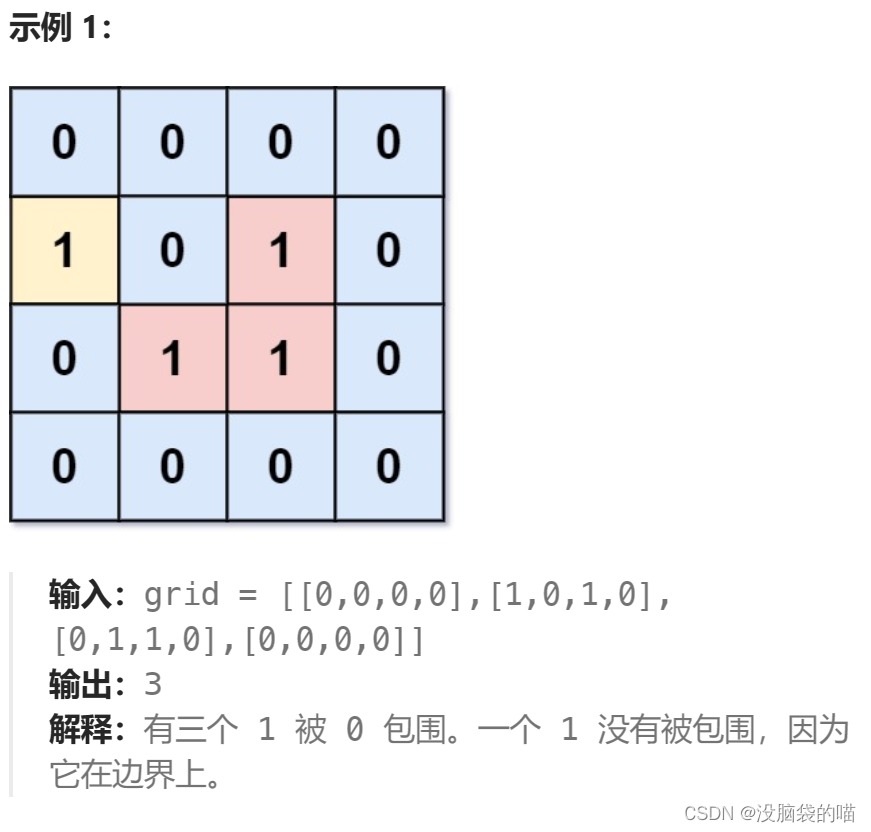
代码随想录图论部分-695. 岛屿的最大面积|1020. 飞地的数量
695. 岛屿的最大面积
题目:给你一个大小为 m x n 的二进制矩阵 grid 。岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水࿰…

聊聊leetcode可包含重复数字的序列的《47. 全排列 II》中的vis标记函数
1 题目描述(字节二面题目) 2 代码
class Solution {List<List<Integer>>res;List<Integer>list;boolean[]used;public List<List<Integer>> permuteUnique(int[] nums) {resnew ArrayList<>();listnew ArrayList&l…
list部分接口模拟实现(c++)
List list简介list基本框架list构造函数list_node结构体的默认构造list类的默认构造 push_back()iteartor迭代器迭代器里面的其他接口const迭代器通过模板参数实现复用operator->() insert()erase()clear()析构函数迭代器区间构造拷贝构造operator() list简介
- list可以在…
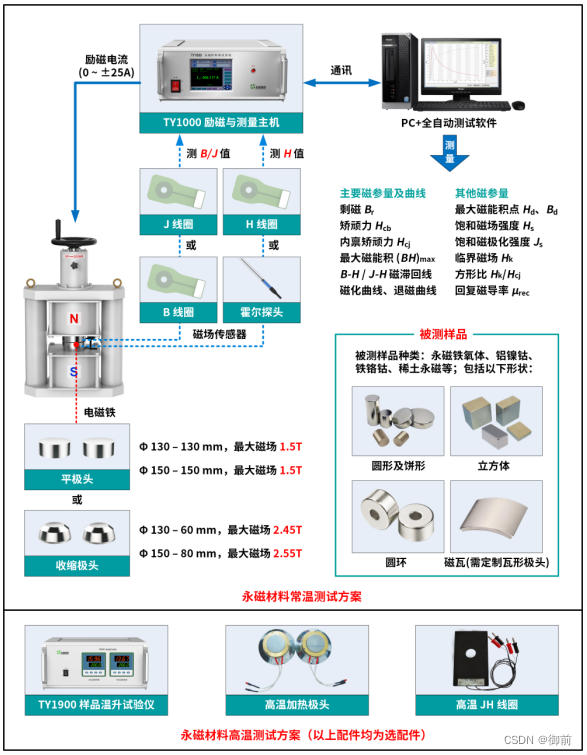
永磁材料测试系统主要应用
1. 产品特征
永磁材料测试系统装置具有独立的电参量校准功能。采用慢速减幅方式对样品退磁。超宽范围的电流连续稳定调节。磁通计的积分器零漂和霍尔探头的非线性误差影响小。系统配置连续可调双极性磁化电源,方便样品的磁化与退磁。测量B或J:采用B或J线…