一、Mask R-CNN是什么,可以做哪些任务?
Mask R-CNN是一个实例分割(Instance segmentation)算法,可以用来做“目标检测”、“目标实例分割”、“目标关键点检测”。
1. 实例分割(Instance segmentation)和语义分割(Semantic segmentation)的区别与联系
联系:语义分割和实例分割都是目标分割中的两个小的领域,都是用来对输入的图片做分割处理;
区别:

1. 通常意义上的目标分割指的是语义分割,语义分割已经有很长的发展历史,已经取得了很好地进展,目前有很多的学者在做这方面的研究;然而实例分割是一个从目标分割领域独立出来的一个小领域,是最近几年才发展起来的,与前者相比,后者更加复杂,当前研究的学者也比较少,是一个有研究空间的热门领域,如图1所示,这是一个正在探索中的领域;
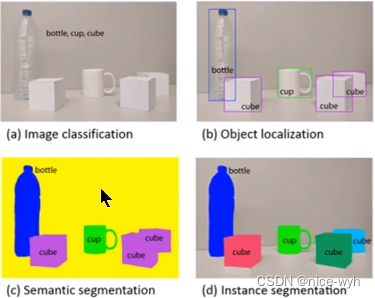
2. 观察图3中的c和d图,c图是对a图进行语义分割的结果,d图是对a图进行实例分割的结果。两者最大的区别就是图中的"cube对象",在语义分割中给了它们相同的颜色,而在实例分割中却给了不同的颜色。即实例分割需要在语义分割的基础上对同类物体进行更精细的分割。
注:很多博客中都没有完全理解清楚这个问题,很多人将这个算法看做语义分割,其实它是一个实例分割算法。
2. Mask R-CNN可以完成的任务

图4 Mask R-CNN进行目标检测与实例分割

图5 Mask R-CNN进行人体姿态识别
总之,Mask R-CNN是一个非常灵活的框架,可以增加不同的分支完成不同的任务,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务,真不愧是一个好算法!
3. Mask R-CNN预期达到的目标
高速
高准确率(高的分类准确率、高的检测准确率、高的实例分割准确率等)
简单直观
易于使用
4. 如何实现这些目标
高速和高准确率:为了实现这个目的,作者选用了经典的目标检测算法Faster-rcnn和经典的语义分割算法FCN。Faster-rcnn可以既快又准的完成目标检测的功能;FCN可以精准的完成语义分割的功能,这两个算法都是对应领域中的经典之作。Mask R-CNN比Faster-rcnn复杂,但是最终仍然可以达到5fps的速度,这和原始的Faster-rcnn的速度相当。由于发现了ROI Pooling中所存在的像素偏差问题,提出了对应的ROIAlign策略,加上FCN精准的像素MASK,使得其可以获得高准确率。
简单直观:整个Mask R-CNN算法的思路很简单,就是在原始Faster-rcnn算法的基础上面增加了FCN来产生对应的MASK分支。即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN。
易于使用:整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务,这将其易于使用的特点展现的淋漓尽致。我很少见到有哪个算法有这么好的扩展性和易用性,值得我们学习和借鉴。除此之外,我们可以更换不同的backbone architecture和Head Architecture来获得不同性能的结果。
二、Mask R-CNN框架解析
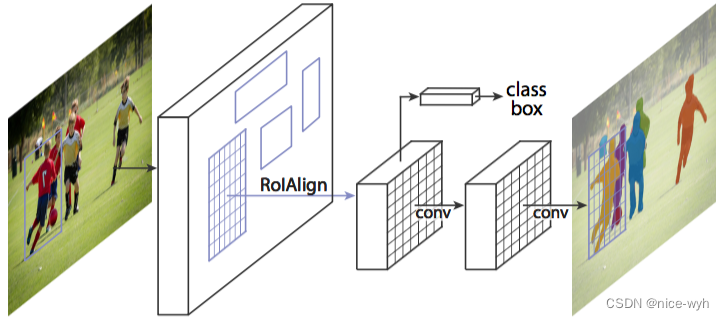
1. Mask R-CNN算法步骤
首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
2. Mask R-CNN架构分解
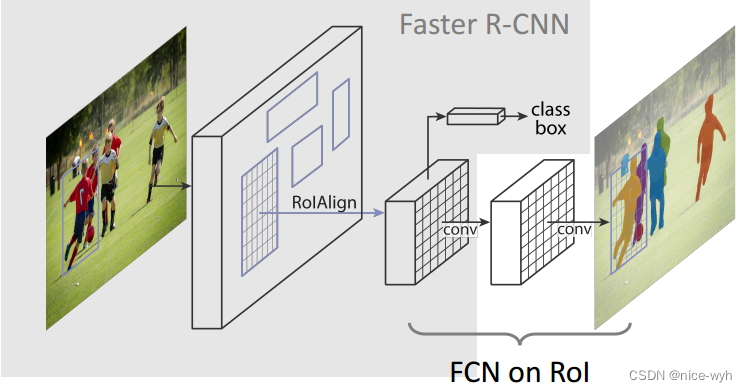
在这里,我将Mask R-CNN分解为如下的3个模块,Faster-rcnn、ROIAlign和FCN。然后分别对这3个模块进行讲解,这也是该算法的核心。
3. Faster-rcnn(该算法请参考该链接,我进行了详细的分析)
4. FCN

FCN算法是一个经典的语义分割算法,可以对图片中的目标进行准确的分割。其总体架构如上图所示,它是一个端到端的网络,主要的模快包括卷积和去卷积,即先对图像进行卷积和池化,使其feature map的大小不断减小;然后进行反卷积操作,即进行插值操作,不断的增大其feature map,最后对每一个像素值进行分类。从而实现对输入图像的准确分割。具体的细节请参考该链接。
5. ROIPooling和ROIAlign的分析与比较
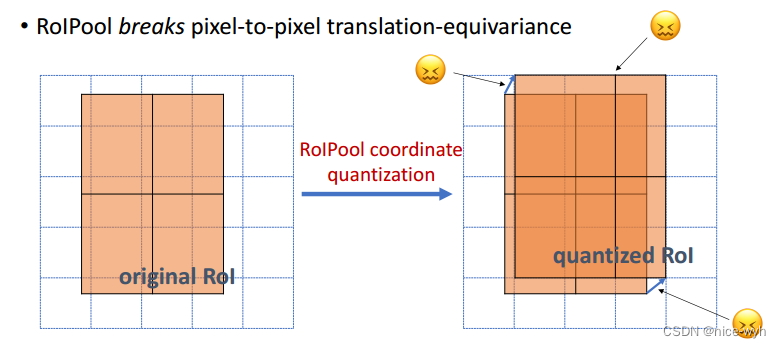
如图所示,ROI Pooling和ROIAlign最大的区别是:前者使用了两次量化操作,而后者并没有采用量化操作,使用了线性插值算法,具体的解释如下所示。
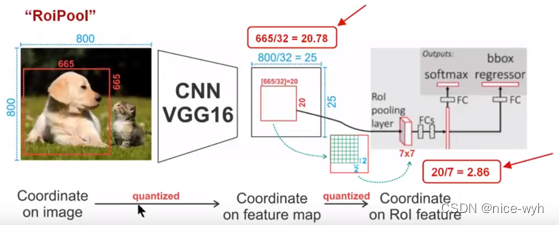
如上图所示,为了得到固定大小(7X7)的feature map,我们需要做两次量化操作:1)图像坐标 — feature map坐标,2)feature map坐标 — ROI feature坐标。我们来说一下具体的细节,如图我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,经过VGG16网络后,我们可以获得对应的feature map,如果我们对卷积层进行Padding操作,我们的图片经过卷积层后保持原来的大小,但是由于池化层的存在,我们最终获得feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关。在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,但是我们的像素值可没有小数,那么作者就对其进行了量化操作(即取整操作),即其结果变为20 x 20,在这里引入了第一次的量化误差;然而我们的feature map中有不同大小的ROI,但是我们后面的网络却要求我们有固定的输入,因此,我们需要将不同大小的ROI转化为固定的ROI feature,在这里使用的是7x7的ROI feature,那么我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,我们采取同样的操作对其进行取整吧,在这里引入了第二次量化误差。其实,这里引入的误差会导致图像中的像素和特征中的像素的偏差,即将feature空间的ROI对应到原图上面会出现很大的偏差。原因如下:比如用我们第二次引入的误差来分析,本来是2,86,我们将其量化为2,这期间引入了0.86的误差,看起来是一个很小的误差呀,但是你要记得这是在feature空间,我们的feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52。这个差距不小吧,这还是仅仅考虑了第二次的量化误差。这会大大影响整个检测算法的性能,因此是一个严重的问题。好的,应该解释清楚了吧,好累!
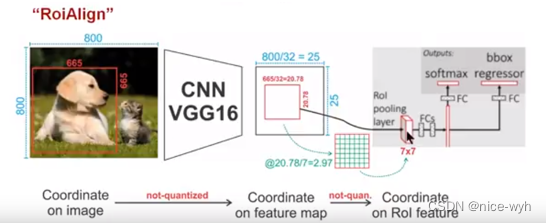
如上图所示,为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,即我们不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。这就是ROIAlign的初衷。那么我们如何处理这些浮点数呢,我们的解决思路是使用“双线性插值”算法。双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。厉害哈。如图11所示,蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些蓝点是2x2Cell中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。这么细心,做科研就应该关注细节,细节决定成败。

6. LOSS计算与分析
由于增加了mask分支,每个ROI的Loss函数如下所示:
![]()
其中Lcls和Lbox和Faster r-cnn中定义的相同。对于每一个ROI,mask分支有Km*m维度的输出,其对K个大小为m*m的mask进行编码,每一个mask有K个类别。我们使用了per-pixel sigmoid,并且将Lmask定义为the average binary cross-entropy loss 。对应一个属于GT中的第k类的ROI,Lmask仅仅在第k个mask上面有定义(其它的k-1个mask输出对整个Loss没有贡献)。我们定义的Lmask允许网络为每一类生成一个mask,而不用和其它类进行竞争;我们依赖于分类分支所预测的类别标签来选择输出的mask。这样将分类和mask生成分解开来。这与利用FCN进行语义分割的有所不同,它通常使用一个per-pixel sigmoid和一个multinomial cross-entropy loss ,在这种情况下mask之间存在竞争关系;而由于我们使用了一个per-pixel sigmoid 和一个binary loss ,不同的mask之间不存在竞争关系。经验表明,这可以提高实例分割的效果。
一个mask对一个目标的输入空间布局进行编码,与类别标签和BB偏置不同,它们通常需要通过FC层而导致其以短向量的形式输出。我们可以通过由卷积提供的像素和像素的对应关系来获得mask的空间结构信息。具体的来说,我们使用FCN从每一个ROI中预测出一个m*m大小的mask,这使得mask分支中的每个层能够明确的保持m×m空间布局,而不将其折叠成缺少空间维度的向量表示。和以前用fc层做mask预测的方法不同的是,我们的实验表明我们的mask表示需要更少的参数,而且更加准确。这些像素到像素的行为需要我们的ROI特征,而我们的ROI特征通常是比较小的feature map,其已经进行了对其操作,为了一致的较好的保持明确的单像素空间对应关系,我们提出了ROIAlign操作。
三、Mask R-CNN细节分析
1. Head Architecture
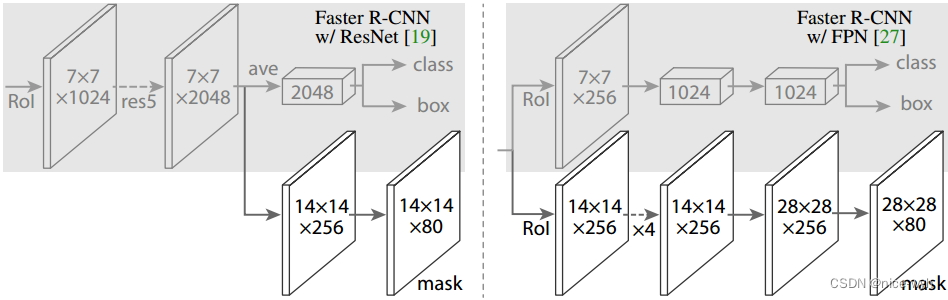
如上图所示,为了产生对应的Mask,文中提出了两种架构,即左边的Faster R-CNN/ResNet和右边的Faster R-CNN/FPN。对于左边的架构,我们的backbone使用的是预训练好的ResNet,使用了ResNet倒数第4层的网络。输入的ROI首先获得7x7x1024的ROI feature,然后将其升维到2048个通道(这里修改了原始的ResNet网络架构),然后有两个分支,上面的分支负责分类和回归,下面的分支负责生成对应的mask。由于前面进行了多次卷积和池化,减小了对应的分辨率,mask分支开始利用反卷积进行分辨率的提升,同时减少通道的个数,变为14x14x256,最后输出了14x14x80的mask模板。而右边使用到的backbone是FPN网络,这是一个新的网络,通过输入单一尺度的图片,最后可以对应的特征金字塔,如果想要了解它的细节,请参考该链接。得到证实的是,该网络可以在一定程度上面提高检测的精度,当前很多的方法都用到了它。由于FPN网络已经包含了res5,可以更加高效的使用特征,因此这里使用了较少的filters。该架构也分为两个分支,作用于前者相同,但是分类分支和mask分支和前者相比有很大的区别。可能是因为FPN网络可以在不同尺度的特征上面获得许多有用信息,因此分类时使用了更少的滤波器。而mask分支中进行了多次卷积操作,首先将ROI变化为14x14x256的feature,然后进行了5次相同的操作(不清楚这里的原理,期待着你的解释),然后进行反卷积操作,最后输出28x28x80的mask。即输出了更大的mask,与前者相比可以获得更细致的mask。

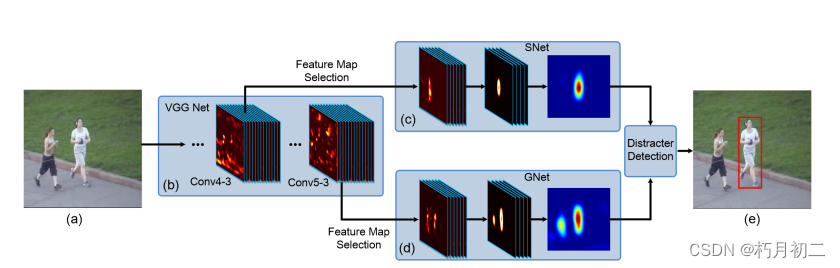
如上图所示,图像中红色的BB表示检测到的目标,我们可以用肉眼可以观察到检测结果并不是很好,即整个BB稍微偏右,左边的一部分像素并没有包括在BB之内,但是右边显示的最终结果却很完美。
2. Equivariance in Mask R-CNN
Equivariance 指随着输入的变化输出也会发生变化。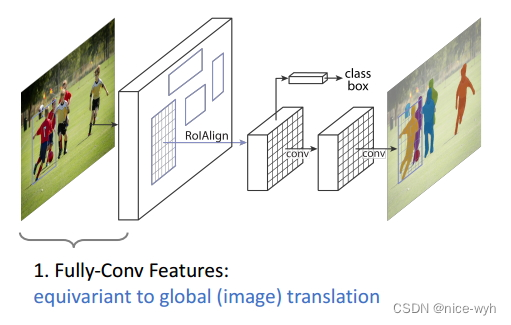
图 Equivariance 1
即全卷积特征(Faster R-CNN网络)和图像的变换具有同变形,即随着图像的变换,全卷积的特征也会发生对应的变化;

图 Equivariance2
在ROI上面的全卷积操作(FCN网络)和在ROI中的变换具有同变性;
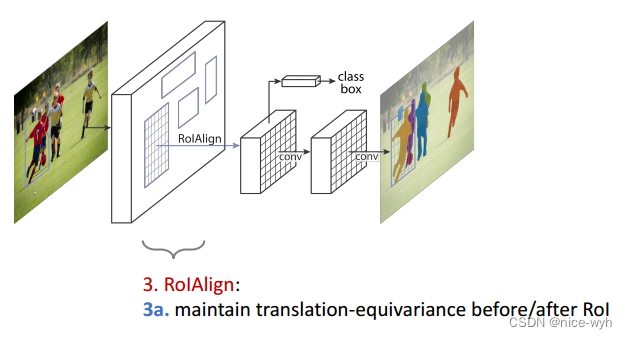
图 Equivariance3
ROIAlign操作保持了ROI变换前后的同变性;

图 ROI中的全卷积
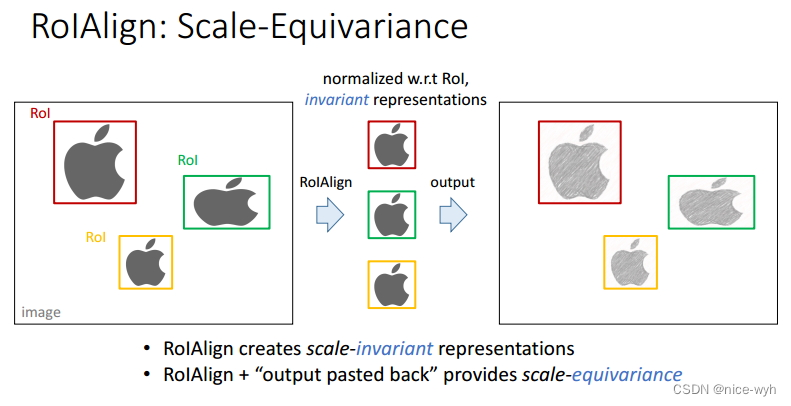
图 ROIAlign的尺度同变性

图 Mask R-CNN中的同变性总结
3. 算法实现细节

图 算法实现细节
观察上图,我们可以得到以下的信息:
Mask R-CNN中的超参数都是用了Faster r-cnn中的值,机智,省时省力,效果还好,别人已经替你调节过啦,哈哈哈;
使用到的预训练网络包括ResNet50、ResNet101、FPN,都是一些性能很好地网络,尤其是FPN,后面会有分析;
对于过大的图片,它会将其裁剪成800x800大小,图像太大的话会大大的增加计算量的;
利用8个GPU同时训练,开始的学习率是0.01,经过18k次将其衰减为0.001,ResNet50-FPN网络训练了32小时,ResNet101-FPN训练了44小时;
在Nvidia Tesla M40 GPU上面的测试时间是195ms/张;
使用了MS COCO数据集,将120k的数据集划分为80k的训练集、35k的验证集和5k的测试集;
四、性能比较
1. 定量结果分析

表 ROI Pool和ROIAlign性能比较
由前面的分析,我们就可以定性的得到一个结论,ROIAlign会使得目标检测的效果有很大的性能提升。根据上表,我们进行定量的分析,结果表明,ROIAlign使得mask的AP值提升了10.5个百分点,使得box的AP值提升了9.5个百分点。
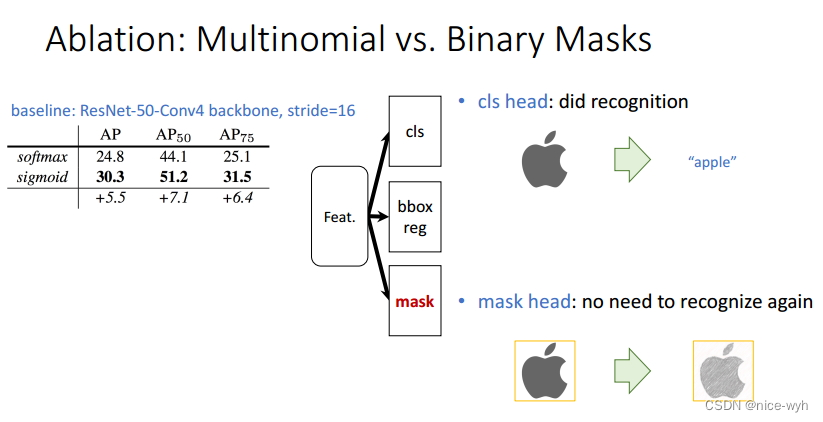
表 Multinomial和Binary loss比较
根据上表的分析,我们知道Mask R-CNN利用两个分支将分类和mask生成解耦出来,然后利用Binary Loss代替Multinomial Loss,使得不同类别的mask之间消除了竞争。依赖于分类分支所预测的类别标签来选择输出对应的mask。使得mask分支不需要进行重新的分类工作,使得性能得到了提升。

表 MLP与FCN mask性能比较
如上表所示,MLP即利用FC来生成对应的mask,而FCN利用Conv来生成对应的mask,仅仅从参数量上来讲,后者比前者少了很多,这样不仅会节约大量的内存空间,同时会加速整个训练过程(因此需要进行推理、更新的参数更少啦)。除此之外,由于MLP获得的特征比较抽象,使得最终的mask中丢失了一部分有用信息,我们可以直观的从右边看到差别。从定性角度来讲,FCN使得mask AP值提升了2.1个百分点。
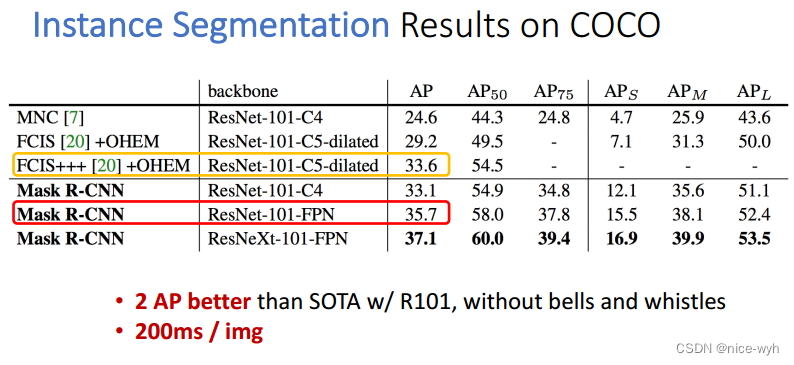
表 实例分割的结果

表 目标检测的结果
观察目标检测的表格,我们可以发现使用了ROIAlign操作的Faster R-CNN算法性能得到了0.9个百分点,Mask R-CNN比最好的Faster R-CNN高出了2.6个百分点。
2. 定性结果分析

图 实例分割结果1

图 实例分割结果2

图 人体姿势识别结果

图 失败检测案例1
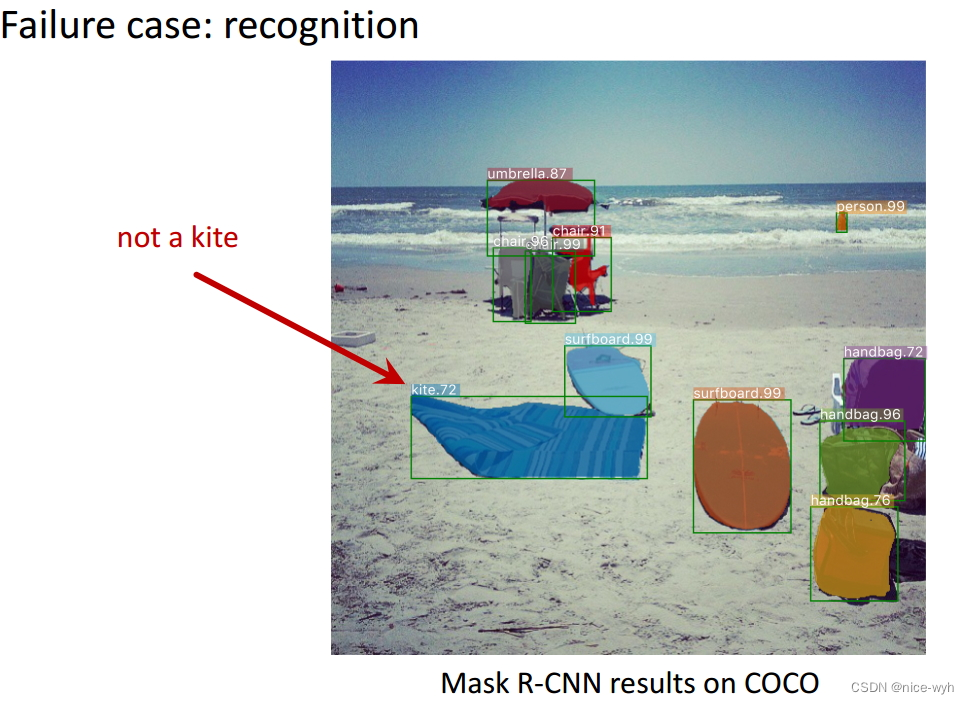
图 失败检测案例2
五、总结
Mask R-CNN论文的主要贡献包括以下几点:
分析了ROI Pool的不足,提升了ROIAlign,提升了检测和实例分割的效果;
将实例分割分解为分类和mask生成两个分支,依赖于分类分支所预测的类别标签来选择输出对应的mask。同时利用Binary Loss代替Multinomial Loss,消除了不同类别的mask之间的竞争,生成了准确的二值mask;
并行进行分类和mask生成任务,对模型进行了加速。
六、代码解析
根据pytorch官方提供的源码链接,进行适当修改和精简后,可以得到一份简易好用的代码,现在对他进行简单的解析。
1.train.py
首先定义了MaskRCNN网络模型,他使用resnet50+fpn作为backbone,并且调用了resnet50的预训练模型进行迁移学习,并在训练时冻结了BN层,同时只训练后三层(即layer4,layer3,layer2)。
def create_model(num_classes, load_pretrain_weights=True):# 如果GPU显存很小,batch_size不能设置很大,建议将norm_layer设置成FrozenBatchNorm2d(默认是nn.BatchNorm2d)# FrozenBatchNorm2d的功能与BatchNorm2d类似,但参数无法更新# trainable_layers包括['layer4', 'layer3', 'layer2', 'layer1', 'conv1'], 5代表全部训练# backbone = resnet50_fpn_backbone(norm_layer=FrozenBatchNorm2d,# trainable_layers=3)# resnet50 imagenet weights url: https://download.pytorch.org/models/resnet50-0676ba61.pthbackbone = resnet50_fpn_backbone(pretrain_path="resnet50.pth", trainable_layers=3)model = MaskRCNN(backbone, num_classes=num_classes)if load_pretrain_weights:# coco weights url: "https://download.pytorch.org/models/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth"weights_dict = torch.load("./maskrcnn_resnet50_fpn_coco.pth", map_location="cpu")for k in list(weights_dict.keys()):if ("box_predictor" in k) or ("mask_fcn_logits" in k):del weights_dict[k]print(model.load_state_dict(weights_dict, strict=False))return model在main函数下, 会先指定设备,然后加载数据集,将图片相似高宽比采样图片组成batch,减小训练时所需GPU显存,通过这样的方式来读取图片。接下来设置学习率、参数更新、和学习率更新方法等;同时如果传入了resume参数接着上次训练的进度继续训练,这里也给出了方法;这些都设置好后,就会开始迭代epoch,开始训练,并把每轮的训练相关参数信息保存到两个txt文件里,以便后续复查,最后保存权重文件,绘制loss、lr、和map的变化图像。
def main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")print("Using {} device training.".format(device.type))# 用来保存coco_info的文件now = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")det_results_file = f"det_results{now}.txt"seg_results_file = f"seg_results{now}.txt"data_transform = {"train": transforms.Compose([transforms.ToTensor(),transforms.RandomHorizontalFlip(0.5)]),"val": transforms.Compose([transforms.ToTensor()])}data_root = args.data_path# load train data set# coco2017 -> annotations -> instances_train2017.jsontrain_dataset = CocoDetection(data_root, "train", data_transform["train"])# VOCdevkit -> VOC2012 -> ImageSets -> Main -> train.txt# train_dataset = VOCInstances(data_root, year="2012", txt_name="train.txt", transforms=data_transform["train"])train_sampler = None# 是否按图片相似高宽比采样图片组成batch# 使用的话能够减小训练时所需GPU显存,默认使用if args.aspect_ratio_group_factor >= 0:train_sampler = torch.utils.data.RandomSampler(train_dataset)# 统计所有图像高宽比例在bins区间中的位置索引group_ids = create_aspect_ratio_groups(train_dataset, k=args.aspect_ratio_group_factor)# 每个batch图片从同一高宽比例区间中取train_batch_sampler = GroupedBatchSampler(train_sampler, group_ids, args.batch_size)# 注意这里的collate_fn是自定义的,因为读取的数据包括image和targets,不能直接使用默认的方法合成batchbatch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using %g dataloader workers' % nw)if train_sampler:# 如果按照图片高宽比采样图片,dataloader中需要使用batch_samplertrain_data_loader = torch.utils.data.DataLoader(train_dataset,batch_sampler=train_batch_sampler,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)else:train_data_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)# load validation data set# coco2017 -> annotations -> instances_val2017.jsonval_dataset = CocoDetection(data_root, "val", data_transform["val"])# VOCdevkit -> VOC2012 -> ImageSets -> Main -> val.txt# val_dataset = VOCInstances(data_root, year="2012", txt_name="val.txt", transforms=data_transform["val"])val_data_loader = torch.utils.data.DataLoader(val_dataset,batch_size=1,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)# create model num_classes equal background + classesmodel = create_model(num_classes=args.num_classes + 1, load_pretrain_weights=args.pretrain)model.to(device)train_loss = []learning_rate = []val_map = []# define optimizerparams = [p for p in model.parameters() if p.requires_grad]optimizer = torch.optim.SGD(params, lr=args.lr,momentum=args.momentum,weight_decay=args.weight_decay)scaler = torch.cuda.amp.GradScaler() if args.amp else None# learning rate schedulerlr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=args.lr_steps,gamma=args.lr_gamma)# 如果传入resume参数,即上次训练的权重地址,则接着上次的参数训练if args.resume:# If map_location is missing, torch.load will first load the module to CPU# and then copy each parameter to where it was saved,# which would result in all processes on the same machine using the same set of devices.checkpoint = torch.load(args.resume, map_location='cpu') # 读取之前保存的权重文件(包括优化器以及学习率策略)model.load_state_dict(checkpoint['model'])optimizer.load_state_dict(checkpoint['optimizer'])lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])args.start_epoch = checkpoint['epoch'] + 1if args.amp and "scaler" in checkpoint:scaler.load_state_dict(checkpoint["scaler"])for epoch in range(args.start_epoch, args.epochs):# train for one epoch, printing every 50 iterationsmean_loss, lr = utils.train_one_epoch(model, optimizer, train_data_loader,device, epoch, print_freq=50,warmup=True, scaler=scaler)train_loss.append(mean_loss.item())learning_rate.append(lr)# update the learning ratelr_scheduler.step()# evaluate on the test datasetdet_info, seg_info = utils.evaluate(model, val_data_loader, device=device)# write detection into txtwith open(det_results_file, "a") as f:# 写入的数据包括coco指标还有loss和learning rateresult_info = [f"{i:.4f}" for i in det_info + [mean_loss.item()]] + [f"{lr:.6f}"]txt = "epoch:{} {}".format(epoch, ' '.join(result_info))f.write(txt + "\n")# write seg into txtwith open(seg_results_file, "a") as f:# 写入的数据包括coco指标还有loss和learning rateresult_info = [f"{i:.4f}" for i in seg_info + [mean_loss.item()]] + [f"{lr:.6f}"]txt = "epoch:{} {}".format(epoch, ' '.join(result_info))f.write(txt + "\n")val_map.append(det_info[1]) # pascal mAP# save weightssave_files = {'model': model.state_dict(),'optimizer': optimizer.state_dict(),'lr_scheduler': lr_scheduler.state_dict(),'epoch': epoch}if args.amp:save_files["scaler"] = scaler.state_dict()torch.save(save_files, "./save_weights/model_{}.pth".format(epoch))# plot loss and lr curveif len(train_loss) != 0 and len(learning_rate) != 0:from plot_curve import plot_loss_and_lrplot_loss_and_lr(train_loss, learning_rate)# plot mAP curveif len(val_map) != 0:from plot_curve import plot_mapplot_map(val_map)if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description=__doc__)# 训练设备类型parser.add_argument('--device', default='cuda:0', help='device')# 训练数据集的根目录parser.add_argument('--data-path', default='/data/coco2017', help='dataset')# 检测目标类别数(不包含背景)parser.add_argument('--num-classes', default=90, type=int, help='num_classes')# 文件保存地址parser.add_argument('--output-dir', default='./save_weights', help='path where to save')# 若需要接着上次训练,则指定上次训练保存权重文件地址parser.add_argument('--resume', default='', type=str, help='resume from checkpoint')# 指定接着从哪个epoch数开始训练parser.add_argument('--start_epoch', default=0, type=int, help='start epoch')# 训练的总epoch数parser.add_argument('--epochs', default=26, type=int, metavar='N',help='number of total epochs to run')# 学习率parser.add_argument('--lr', default=0.004, type=float,help='initial learning rate, 0.02 is the default value for training ''on 8 gpus and 2 images_per_gpu')# SGD的momentum参数parser.add_argument('--momentum', default=0.9, type=float, metavar='M',help='momentum')# SGD的weight_decay参数parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,metavar='W', help='weight decay (default: 1e-4)',dest='weight_decay')# 针对torch.optim.lr_scheduler.MultiStepLR的参数parser.add_argument('--lr-steps', default=[16, 22], nargs='+', type=int,help='decrease lr every step-size epochs')# 针对torch.optim.lr_scheduler.MultiStepLR的参数parser.add_argument('--lr-gamma', default=0.1, type=float, help='decrease lr by a factor of lr-gamma')# 训练的batch size(如果内存/GPU显存充裕,建议设置更大)parser.add_argument('--batch_size', default=2, type=int, metavar='N',help='batch size when training.')parser.add_argument('--aspect-ratio-group-factor', default=3, type=int)parser.add_argument("--pretrain", type=bool, default=True, help="load COCO pretrain weights.")# 是否使用混合精度训练(需要GPU支持混合精度)parser.add_argument("--amp", default=False, help="Use torch.cuda.amp for mixed precision training")args = parser.parse_args()print(args)# 检查保存权重文件夹是否存在,不存在则创建if not os.path.exists(args.output_dir):os.makedirs(args.output_dir)main(args)2.predict.py
对一张图片进行实例分割
import os
import time
import jsonimport numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transformsfrom network_files import MaskRCNN
from backbone import resnet50_fpn_backbone
from draw_box_utils import draw_objsdef create_model(num_classes, box_thresh=0.5):backbone = resnet50_fpn_backbone()model = MaskRCNN(backbone,num_classes=num_classes,rpn_score_thresh=box_thresh,box_score_thresh=box_thresh)return modeldef time_synchronized():torch.cuda.synchronize() if torch.cuda.is_available() else Nonereturn time.time()def main():num_classes = 90 # 不包含背景box_thresh = 0.5weights_path = "./save_weights/mask_rcnn_weights.pth"img_path = "./1.jpg"label_json_path = './coco91_indices.json'# get devicesdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))# create modelmodel = create_model(num_classes=num_classes + 1, box_thresh=box_thresh)# load train weightsassert os.path.exists(weights_path), "{} file dose not exist.".format(weights_path)weights_dict = torch.load(weights_path, map_location='cpu')weights_dict = weights_dict["model"] if "model" in weights_dict else weights_dictmodel.load_state_dict(weights_dict)model.to(device)# read class_indictassert os.path.exists(label_json_path), "json file {} dose not exist.".format(label_json_path)with open(label_json_path, 'r') as json_file:category_index = json.load(json_file)# load imageassert os.path.exists(img_path), f"{img_path} does not exits."original_img = Image.open(img_path).convert('RGB')# from pil image to tensor, do not normalize imagedata_transform = transforms.Compose([transforms.ToTensor()])img = data_transform(original_img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)model.eval() # 进入验证模式with torch.no_grad():# initimg_height, img_width = img.shape[-2:]init_img = torch.zeros((1, 3, img_height, img_width), device=device)model(init_img)t_start = time_synchronized()predictions = model(img.to(device))[0]t_end = time_synchronized()print("inference+NMS time: {}".format(t_end - t_start))predict_boxes = predictions["boxes"].to("cpu").numpy()predict_classes = predictions["labels"].to("cpu").numpy()predict_scores = predictions["scores"].to("cpu").numpy()predict_mask = predictions["masks"].to("cpu").numpy()predict_mask = np.squeeze(predict_mask, axis=1) # [batch, 1, h, w] -> [batch, h, w]if len(predict_boxes) == 0:print("没有检测到任何目标!")returnplot_img = draw_objs(original_img,boxes=predict_boxes,classes=predict_classes,scores=predict_scores,masks=predict_mask,category_index=category_index,line_thickness=3,font='arial.ttf',font_size=20)plt.imshow(plot_img)plt.show()# 保存预测的图片结果plot_img.save("test_result.jpg")if __name__ == '__main__':main()代码首先加载已训练权重文件、预测图片、和存有类别信息的、json文件,对图像进行简单处理后开始预测,并最终把结果绘制在图片上

3.predict2.py
为了实现对多张图片实现预测,我对代码进行了改进,实现了对文件夹下多张图片预测的功能
import os
import time
import jsonimport numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transformsfrom network_files import MaskRCNN
from backbone import resnet50_fpn_backbone
from draw_box_utils import draw_objsdef create_model(num_classes, box_thresh=0.5):backbone = resnet50_fpn_backbone()model = MaskRCNN(backbone,num_classes=num_classes,rpn_score_thresh=box_thresh,box_score_thresh=box_thresh)return modeldef time_synchronized():torch.cuda.synchronize() if torch.cuda.is_available() else Nonereturn time.time()# 预测多张图片
def main():num_classes = 90 # 不包含背景box_thresh = 0.5weights_path = "./save_weights/mask_rcnn_weights.pth"# get devicesdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))files = os.listdir('./images/')for file in files:img_name = file.split('.')img_path = './images/' + img_name[0] + ".jpg"print(img_path)label_json_path = './coco91_indices.json'# create modelmodel = create_model(num_classes=num_classes + 1, box_thresh=box_thresh)# load train weightsassert os.path.exists(weights_path), "{} file dose not exist.".format(weights_path)weights_dict = torch.load(weights_path, map_location='cpu')weights_dict = weights_dict["model"] if "model" in weights_dict else weights_dictmodel.load_state_dict(weights_dict)model.to(device)# read class_indictassert os.path.exists(label_json_path), "json file {} dose not exist.".format(label_json_path)with open(label_json_path, 'r') as json_file:category_index = json.load(json_file)# load imageassert os.path.exists(img_path), f"{img_path} does not exits."original_img = Image.open(img_path).convert('RGB')# from pil image to tensor, do not normalize imagedata_transform = transforms.Compose([transforms.ToTensor()])img = data_transform(original_img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)model.eval() # 进入验证模式with torch.no_grad():# initimg_height, img_width = img.shape[-2:]init_img = torch.zeros((1, 3, img_height, img_width), device=device)model(init_img)t_start = time_synchronized()predictions = model(img.to(device))[0]t_end = time_synchronized()print("inference+NMS time: {}".format(t_end - t_start))predict_boxes = predictions["boxes"].to("cpu").numpy()predict_classes = predictions["labels"].to("cpu").numpy()predict_scores = predictions["scores"].to("cpu").numpy()predict_mask = predictions["masks"].to("cpu").numpy()predict_mask = np.squeeze(predict_mask, axis=1) # [batch, 1, h, w] -> [batch, h, w]if len(predict_boxes) == 0:print("没有检测到任何目标!")returnplot_img = draw_objs(original_img,boxes=predict_boxes,classes=predict_classes,scores=predict_scores,masks=predict_mask,category_index=category_index,line_thickness=3,font='arial.ttf',font_size=20)# plt.imshow(plot_img)# plt.show()# 保存预测的图片结果plot_img.save("./result/" + img_name[0] + ".jpg")if __name__ == '__main__':main()代码会读取images文件夹下的所有图片,并对他们逐一预测,最终将输出的结果保存在result文件夹下
参考链接:https://blog.csdn.net/WZZ18191171661/article/details/79453780




![[LeetCode]-622. 设计循环队列](https://img-blog.csdnimg.cn/4d11edafde924437baed73f24bada59a.gif)