一、说明
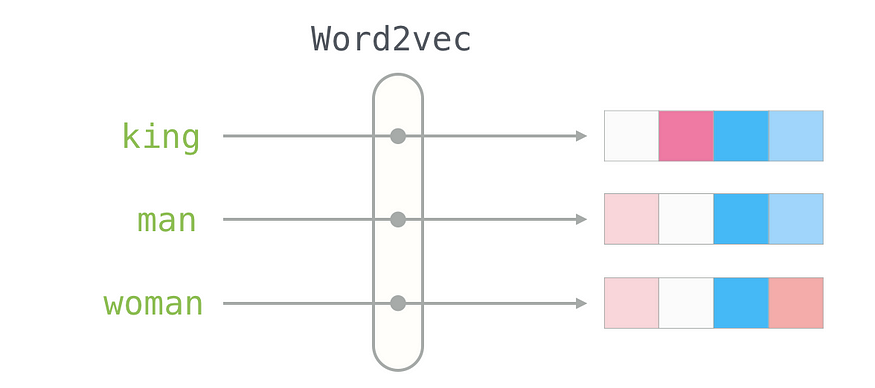
词嵌入是高维向量空间中单词或短语的数字表示,其中向量之间的几何关系捕获相应单词之间的语义和句法相似性。这些表示使机器学习模型能够以更有意义的方式理解和处理自然语言。
在传统的 NLP 方法中,单词是使用稀疏的 one-hot 编码向量来表示的,其中每个单词在大词汇量中都有一个唯一的索引。然而,这种表示缺乏捕捉单词之间的关系和上下文含义的能力。词嵌入通过为单词分配密集、连续的向量表示来解决这一限制,从而允许更细致和上下文相关的单词表示。
词嵌入通常是通过使用 Word2Vec、GloVe 或 fastText 等技术在大型文本语料库上训练模型来学习的。这些模型捕获文本数据中的统计模式,并生成捕获语义和句法关系的词嵌入。由此产生的嵌入可以反映各种语言属性,例如单词相似性、类比,甚至某些语言规律。
虽然预训练的词嵌入(例如 Word2Vec 或 GloVe)可以在线获取,并且可以轻松用于各种 NLP 任务,但它们通常是在通用文本数据上进行训练的,可能无法捕获特定于领域或特定于任务的细微差别。在这种情况下,在专门的数据集上训练特定的词嵌入可能是有益的。在特定领域或用例上训练的定制嵌入可以更好地捕获目标数据的复杂性和上下文,从而提高下游 NLP 任务的性能。
拥有特定的嵌入可以让模型更好地理解数据中存在的特定领域语言、语义关系和上下文线索。这使得自然语言处理、情感分析、文本分类、机器翻译和其他 NLP 任务变得更加准确和有效。