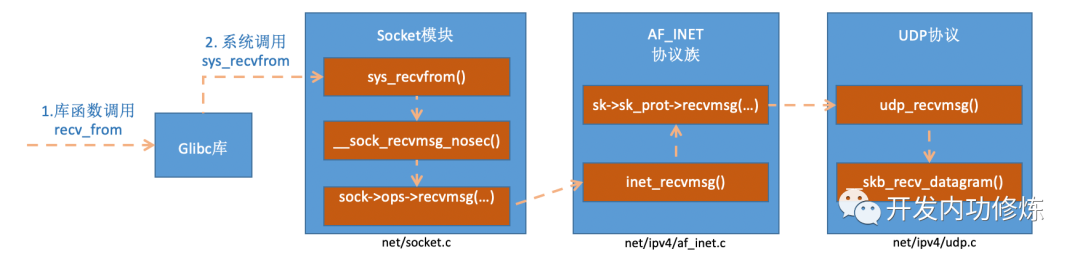
1、Topics交换机的介绍
Topics交换机能让消息只发送往绑定了指定routingkey的队列中去,不同于Direct交换机的是,Topics能把一个消息往多个不同的队列发送;Topics交换机的routingkey不能随意写,必须是一个单词列表,并以点号分隔开,例如“one.two.three”,除此外还有两个替换符,*(星号)能代替一个单词,#(井号)可以代替零个或多个单词,例如“*.one.*”是中间是one的3个单词,“*.*.one”是最后一个是one的3个单词,“one.#”是第一个单词是one的多个单词,若队列绑定键是#,这个队列将接收所有数据,这时候类似fanout交换机,若队列绑定键中没有#和*出现,这时候就类似direct交换机
2、Topics交换机的实现
(1)新建一个名为topics的包,用于装发布确认的代码
效果图:
(2)新建一个名为Receive01的类用于编写消费者的代码

代码如下:
注:RabbitMqUtils工具类的实现在我的另一篇文章里,有需要的同学可以查看参考
RabbitMQ系列(6)--RabbitMQ模式之工作队列(Work queues)的简介及实现_Ken_1115的博客-CSDN博客
package com.ken.topics;import com.ken.utils.RabbitMqUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import com.rabbitmq.client.Delivery;/*** 消息接收*/
public class Receive01 {//声明交换机的名称public static final String EXCHANGE_NAME = "topic_exchange";//接收消息public static void main(String[] args) throws Exception{Channel channel = RabbitMqUtils.getChannel();//声明交换机channel.exchangeDeclare(EXCHANGE_NAME,"topic");//声明队列String queueName = "Q1";/*** 创建队列* 第一个参数:队列名称* 第二个参数:服务器重启后队列是否还存在,即队列是否持久化,true为是,false为否,默认false,即消息存储在内存中而不是硬盘中* 第三个参数:该队列是否只供一个消费者进行消费,是否进行消息共享,true为只允许一个消费者进行消费,false为允许多个消费者对队列进行消费,默认false* 第四个参数:是否自动删除,最后一个消费者断开连接后该队列是否自动删除,true自动删除,false不自动删除* 第五个参数:其他参数*/channel.queueDeclare(queueName,false,false,false,null);//队列与交换机通过routingkey进行捆绑channel.queueBind(queueName,EXCHANGE_NAME,"*.one.*");/*** 声明消费者接收消息后的回调方法(由于回调方法DeliverCallback是函数式接口,所以需要给DeliverCallback赋值一个函数,为了方便我们这里使用Lambda表达式进行赋值)* 为什么要这样写呢,是因为basicConsume方法里的参数deliverCallback的类型DeliverCallback用 @FunctionalInterface注解规定DeliverCallback是一个函数式接口,所以要往deliverCallback参数传的值要是一个函数** 以下是DeliverCallback接口的源代码* @FunctionalInterface* public interface DeliverCallback {* void handle (String consumerTag, Delivery message) throws IOException;* }*/DeliverCallback deliverCallback = (consumerTag, message) -> {System.out.println(new String(message.getBody(),"UTF-8"));System.out.println("接收队列:" + queueName + " 绑定键:" + message.getEnvelope().getRoutingKey());};/*** 用信道对消息进行接收* 第一个参数:消费的是哪一个队列的消息* 第二个参数:消费成功后是否要自动应答,true代表自动应当,false代表手动应答* 第三个参数:消费者接收消息后的回调方法* 第四个参数:消费者取消接收消息后的回调方法(正常接收不调用)*/channel.basicConsume(queueName,true,deliverCallback,consumerTag ->{});}}(3)复制Receive01类并粘贴重命名为Receive02
代码如下:
package com.ken.topics;import com.ken.utils.RabbitMqUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;/*** 消息接收*/
public class Receive02 {//声明交换机的名称public static final String EXCHANGE_NAME = "topic_exchange";//接收消息public static void main(String[] args) throws Exception{Channel channel = RabbitMqUtils.getChannel();//声明交换机channel.exchangeDeclare(EXCHANGE_NAME,"topic");//声明队列String queueName = "Q1";/*** 创建队列* 第一个参数:队列名称* 第二个参数:服务器重启后队列是否还存在,即队列是否持久化,true为是,false为否,默认false,即消息存储在内存中而不是硬盘中* 第三个参数:该队列是否只供一个消费者进行消费,是否进行消息共享,true为只允许一个消费者进行消费,false为允许多个消费者对队列进行消费,默认false* 第四个参数:是否自动删除,最后一个消费者断开连接后该队列是否自动删除,true自动删除,false不自动删除* 第五个参数:其他参数*/channel.queueDeclare(queueName,false,false,false,null);//队列与交换机通过routingkey进行捆绑channel.queueBind(queueName,EXCHANGE_NAME,"*.*.two");//队列与交换机通过routingkey进行捆绑channel.queueBind(queueName,EXCHANGE_NAME,"three.#");/*** 声明消费者接收消息后的回调方法(由于回调方法DeliverCallback是函数式接口,所以需要给DeliverCallback赋值一个函数,为了方便我们这里使用Lambda表达式进行赋值)* 为什么要这样写呢,是因为basicConsume方法里的参数deliverCallback的类型DeliverCallback用 @FunctionalInterface注解规定DeliverCallback是一个函数式接口,所以要往deliverCallback参数传的值要是一个函数** 以下是DeliverCallback接口的源代码* @FunctionalInterface* public interface DeliverCallback {* void handle (String consumerTag, Delivery message) throws IOException;* }*/DeliverCallback deliverCallback = (consumerTag, message) -> {System.out.println(new String(message.getBody(),"UTF-8"));System.out.println("接收队列:" + queueName + " 绑定键:" + message.getEnvelope().getRoutingKey());};/*** 用信道对消息进行接收* 第一个参数:消费的是哪一个队列的消息* 第二个参数:消费成功后是否要自动应答,true代表自动应当,false代表手动应答* 第三个参数:消费者接收消息后的回调方法* 第四个参数:消费者取消接收消息后的回调方法(正常接收不调用)*/channel.basicConsume(queueName,true,deliverCallback,consumerTag ->{});}}
(4)新建一个名为Emit的类用于编写生产者的代码
代码如下:
package com.ken.topics;import com.ken.utils.RabbitMqUtils;
import com.rabbitmq.client.Channel;import java.util.HashMap;
import java.util.Map;/*** 发消息*/
public class Emit {//声明交换机的名称public static final String EXCHANGE_NAME = "topic_exchange";public static void main(String[] args) throws Exception {Channel channel = RabbitMqUtils.getChannel();Map<String,String> bindingKeyMap = new HashMap<>();bindingKeyMap.put("four.one.two","被队列Q1Q2接收");bindingKeyMap.put("three.one.five","被队列Q1Q2接收");bindingKeyMap.put("four.one.six","被队列Q1接收");bindingKeyMap.put("three.seven.six","被队列Q2接收");bindingKeyMap.put("three.eight.two","虽然满足两个绑定,但只被队列Q2接收一次");bindingKeyMap.put("three.seven.six","不匹配任何绑定,不会被任何队列接收到,会被丢弃");bindingKeyMap.put("four.one.nine.two","四个单词,不匹配任何绑定,会被丢弃");bindingKeyMap.put("three.one.nine.two","四个单词,但匹配Q2");for (Map.Entry<String, String> bindingKeyEntry : bindingKeyMap.entrySet()) {String routingKey = bindingKeyEntry.getKey();String message = bindingKeyEntry.getValue();channel.basicPublish(EXCHANGE_NAME,routingKey,null,message.getBytes("UTF-8"));System.out.println("生产者发出消息:" + message);}}}
(5)分别先运行Receive01、Receive02、Emit



(6)查看Receive01和Receive02接收消息的情况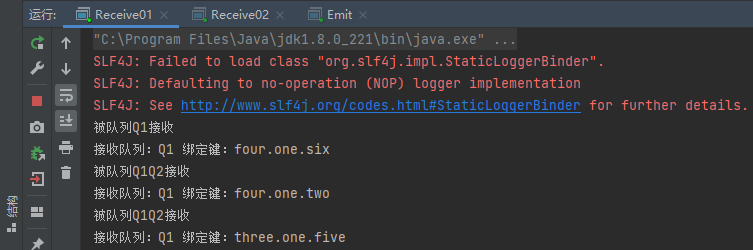
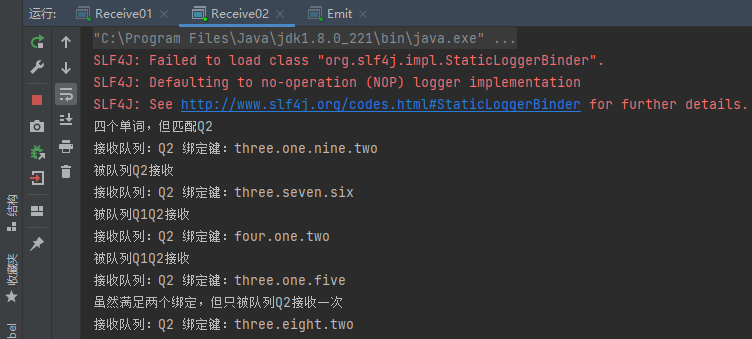
从上述结果可看出topic交换机实现成功