卷友们好,我是rumor。
众所周知,RLHF十分玄学且令人望而却步。我听过有的小道消息说提升很大,也有小道消息说效果不明显,究其根本还是系统链路太长自由度太高,不像SFT一样可以通过数据配比、prompt、有限的超参数来可控地调整效果。
但也正是因为它的自由度、以目标为导向的学习范式和性价比更高的标注成本,业内往往认为它会有更高的效果天花板。同时我最近看OpenAI的SuperAlignment计划感受颇深,非常坚定地认为scalable的RLHF(不局限于PPO)就是下一步的大突破所在。
所以我秉着不抛弃不放弃的决心,带大家梳理一下最近的RLHF平替工作,探索如何更稳定地拿到效果。
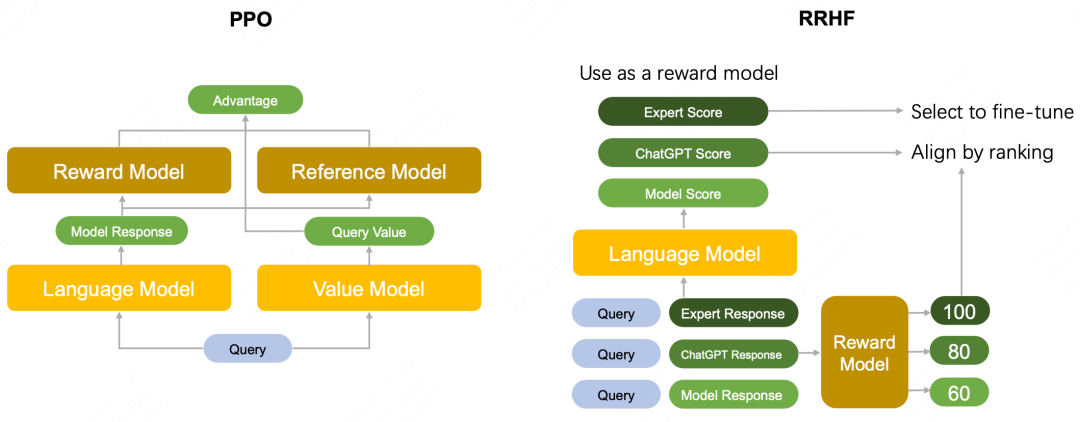
RLHF链路可以分为两个模块,RM和RL,这两个模块各有各的问题:
RM:对准确率和泛化性的要求都很高,不然很容易就被hack到(比如输出某个pattern就给高分)。但业内普遍标注数据的一致率只有70%左右,数据决定效果天花板,如何让RM代表大部分人的判断、且能区分出模型结果的细微差异,难难难。这也是RLHF方法没法规模化起来的主要瓶颈
RL:奖励太稀疏(最后一步才拿到句子分数,不像SFT一样有真实的token-level监督信号)、PPO超参数非常多,导致效果很不稳定
针对上述两个模块的问题,学术界大佬们各显神通,大概有以下几种解决方案:
没得商量,不做RL了,选择性保留RM:比如RRHF、DPO,这类方法可以直接在RM数据上优化语言模型,但如果想提升效果,需要用自身模型采样,得再引入一个RM,比如RSO、SCiL、PRO等。又或者直接用RM采样的数据做精调,比如RAFT、Llama2等
用其他RL算法:比如ReMax、Decision Transformer
下面我们就逐一盘盘这些方法以及他们给出的有用结论。
不做RL了
RRHF
RRHF: Rank Responses to Align Language Models with Human Feedback without tears
RRHF是阿里在今年年初(2023.04)发布的工作,它的做法是直接在RM数据山优化LM,让chosen回答的概率大于rejected回答的概率。
在具体实现上,就是计算句子的条件概率后加一个ranking loss:
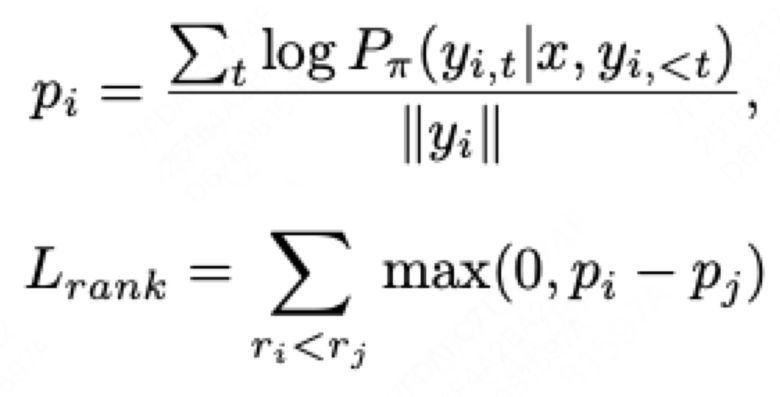
但在实践中,作者发现只用ranking loss会把模型训崩溃,所以又加了SFT loss。从消融实验可以看到加了rank loss确实对模型效果有一些提升:
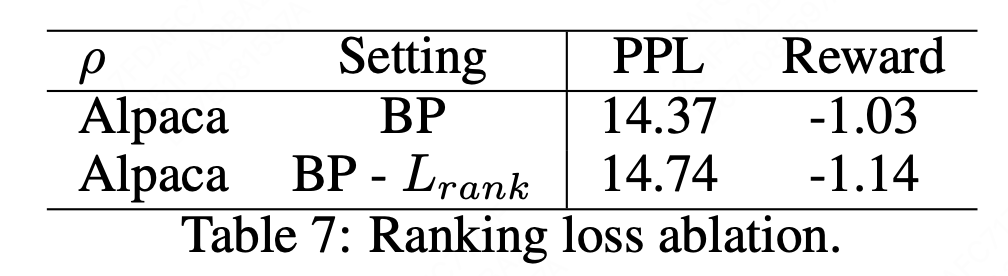
最终在HH数据集上,作者提出的RRHF平均得分略好于PPO(-1.02 vs -1.03),效果差距不是太大,但该方法主打一个便捷稳定。
同时作者也在实验中尝试了不同的数据采样策略:
直接用开源RM的数据
用自己的模型生成response,用开源RM进行排序,做出新的RM数据
循环执行2,类似强化的思维不断靠自身采样到更好的答案
最后的结论也比较符合直接,是3>2>1。
Preference Ranking Optimization for Human Alignment
后续阿里(非同作者)在2023.06又提出了一个PRO方法,核心思想跟RRHF接近,但有两个不同:
选用了更多负例,不止停留在pair-wise
给不同负例不同的惩罚项(比如分数差的多就拉大一些)
同时也加上了SFT loss,最终效果比RLHF和RRHF都有些提升。
DPO
Direct Preference Optimization:Your Language Model is Secretly a Reward Model
DPO是斯坦福在2023.05底提出的工作,主打一个硬核,直接从PPO公式推出了一个平替方案,虽然最终loss呈现的思想跟RRHF接近(chosen句子概率>rejected句子概率),但同时带有一个SFT模型的约束,可以保证在不加SFT loss的情况下训练不崩溃(个人猜测)。
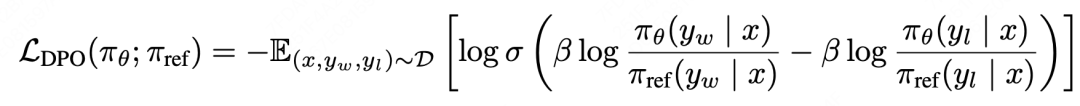
作者在公开的几个RM数据集上都做了实验,可以发现DPO对超参数的敏感度更低,效果更稳定,且奖励得分优于RLHF。
同时,微软在2023.10月的一篇工作[1]上也对DPO做了进一步的探索。考虑到排序数据成本,他们直接默认GPT4 > ChatGPT > InstructGPT,实验后得到以下结论:
用DPO在 GPT4 vs InstructGPT 上训练的效果 > 直接在GPT-4数据精调的效果
先在简单的pair上训练后,再在困难的pair上训练会有更好的效果
RSO
Statistical rejection sampling improves preference optimization
上面介绍了两种ranking思想的loss,具体哪种更好一些呢?DeepMind在2023.09月份的一篇RSO[2]工作中进行了更系统的对比,得到了以下结论:
DPO(sigmoid-norm) loss效果略好,但更重要的是增加SFT约束,可以看表中没加约束的hinge loss效果很差,但加了约束后则能接近DPO
另外重要的还有采样策略,比如要优化模型A,最好用模型A生产的结果,去做pair标注,再训练A,比用模型B生产的数据训练A更好。这跟RRHF的结论也比较一致,更接近「强化」的思想
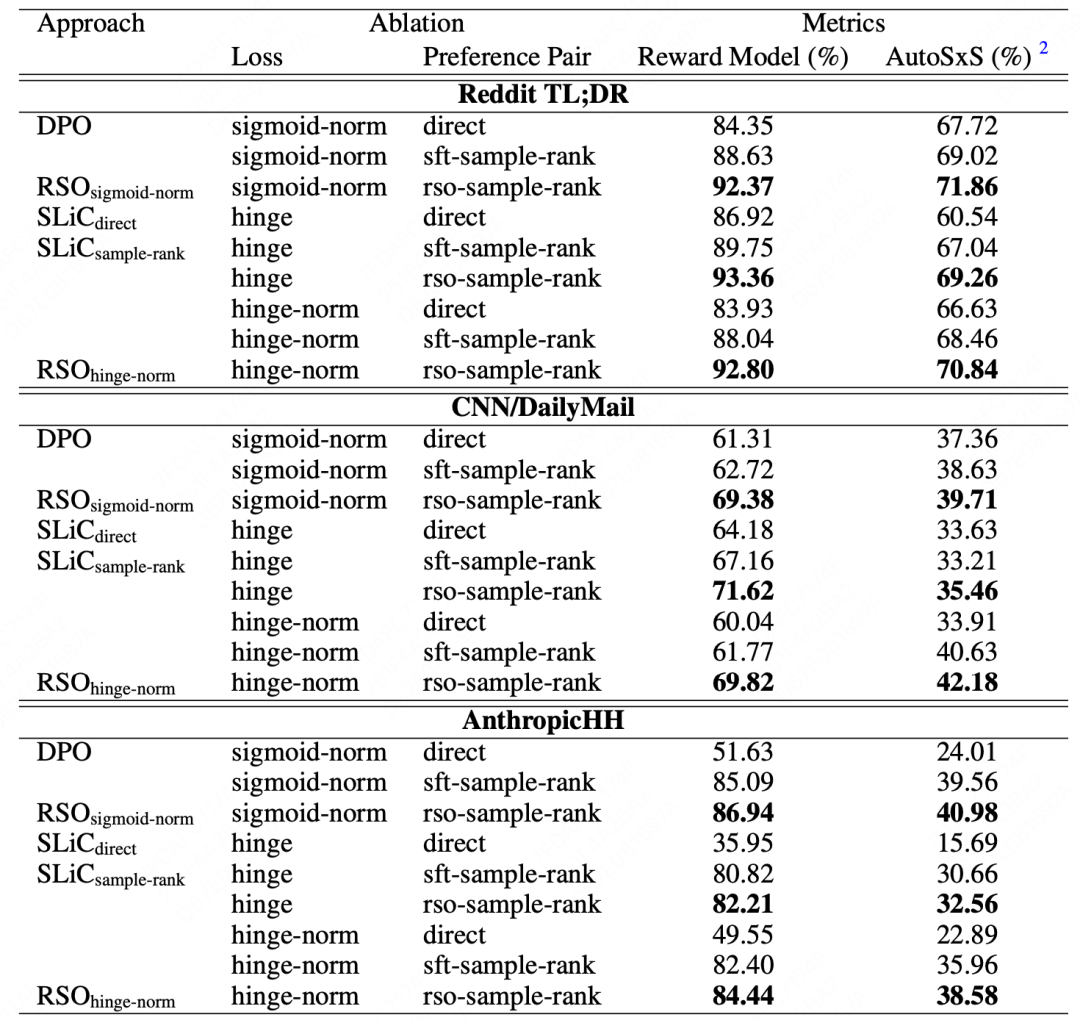
同时作者提出了另外一种RSO(Rejection Sampling Optimization)的采样方法,实验发现有2个点左右的提升。
Rejection Sampling + SFT
拒绝采样是一种针对复杂问题的采样策略[3],可以更高效地采样到合适的样本,进行复杂分布的估计。最近也有很多方法,利用RM进行拒绝采样,直接用采样出的数据对模型做SFT。
Llama 2: Open Foundation and Fine-Tuned Chat Models
LLama2就很好地使用了拒绝采样,先问问地训RM,再用RM筛选出当前模型最好的结果进行SFT。论文发出时他们一共把llama2-chat迭代了5轮,前4轮都是用的拒绝采样,只有最后一轮用了PPO,可以看到相比ChatGPT的胜率一直在提升:
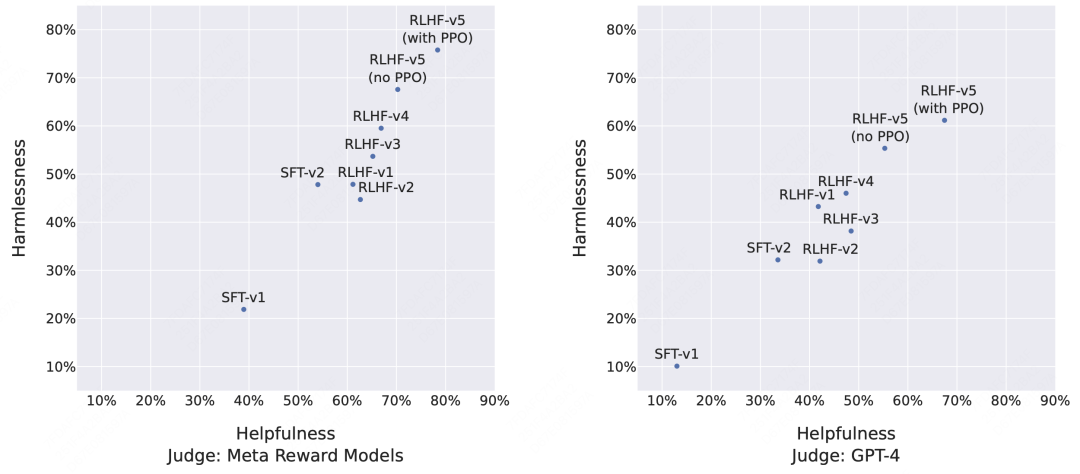
不过从RLHF v5(no PPO)和RLHF v5(with PPO)来看,RL还是能有很大的效果收益。
这种方法还有很多变体可以探索,比如港大在2023.04提出的RAFT[4],就是选取多个样本进行后续精调。同时采样策略也可以进行一些优化,比如上面提到的RSO。
用其他RL算法
ReMax
ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
ReMax是港中文在2023.10提出的工作,核心是对RLHF中RL阶段的PPO算法进行了简化。
强化的难点是怎么把多步之后的最终目标转化成模型loss,针对这个问题有不同解决方案,目前OpenAI所使用的RL策略叫PPO[5],是他们自己在2017年提出的一个经典RL算法(OpenAI早期真的做了很多强化的工作)。
但ReMax的作者认为,PPO并不适用于语言模型的场景:
可以快速拿到句子奖励:传统RL的长期奖励获取可能会比较昂贵,比如必须玩完一局游戏、拿起一个杯子,而RLHF在有了RM后可以快速拿到奖励
确定性的环境:传统RL中,环境也是变化的,同一个场景+动作可能拿到不同奖励,而在语言模型中,给定上下文和当前结果,下一步的状态也是确定的,RM打分也是确定的
上面两点在传统RL中会造成学习不稳定的问题,因此PPO使用了Actor-Critic网络,即引入一个「助教」来给模型的每一步打分,而作者认为在语言模型上可以省去。
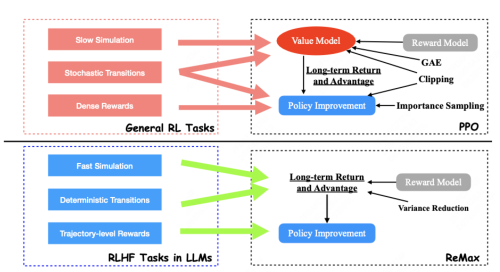
因此,作者提出用强化中的REINFORCE算法来代替PPO,去掉了Critic模型,但作者在实验中同样发现了梯度方差较大优化不稳定的问题,于是增加了一项bias来降低方差,命名为ReMax算法。
由于资源受限,作者没跑通7B的PPO实验,只对比了1.3B的ReMax和PPO,效果显示ReMax更好一些:
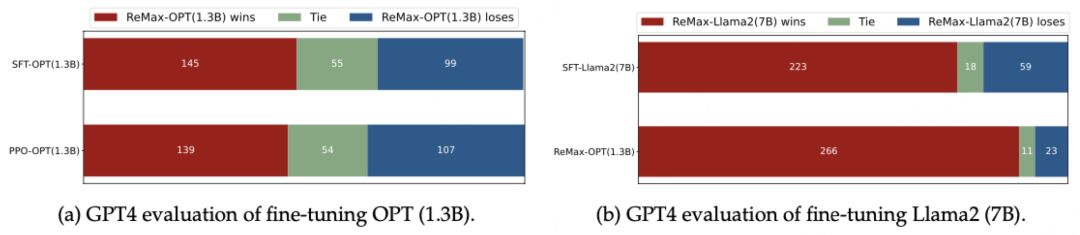
除了效果提升之外,由于去掉了一个要训练的模型,在显存占用和训练速度上都有提升。
Offline RL: Decision Transformer
上面我们说的PPO、REINFORCE都是Online RL,需要一个虚拟环境,通过互动拿到奖励,再进行学习。相对的,Offline RL是指直接拿之前和环境互动的数据来学习。
Aligning Language Models with Offline Reinforcement Learning from Human Feedback
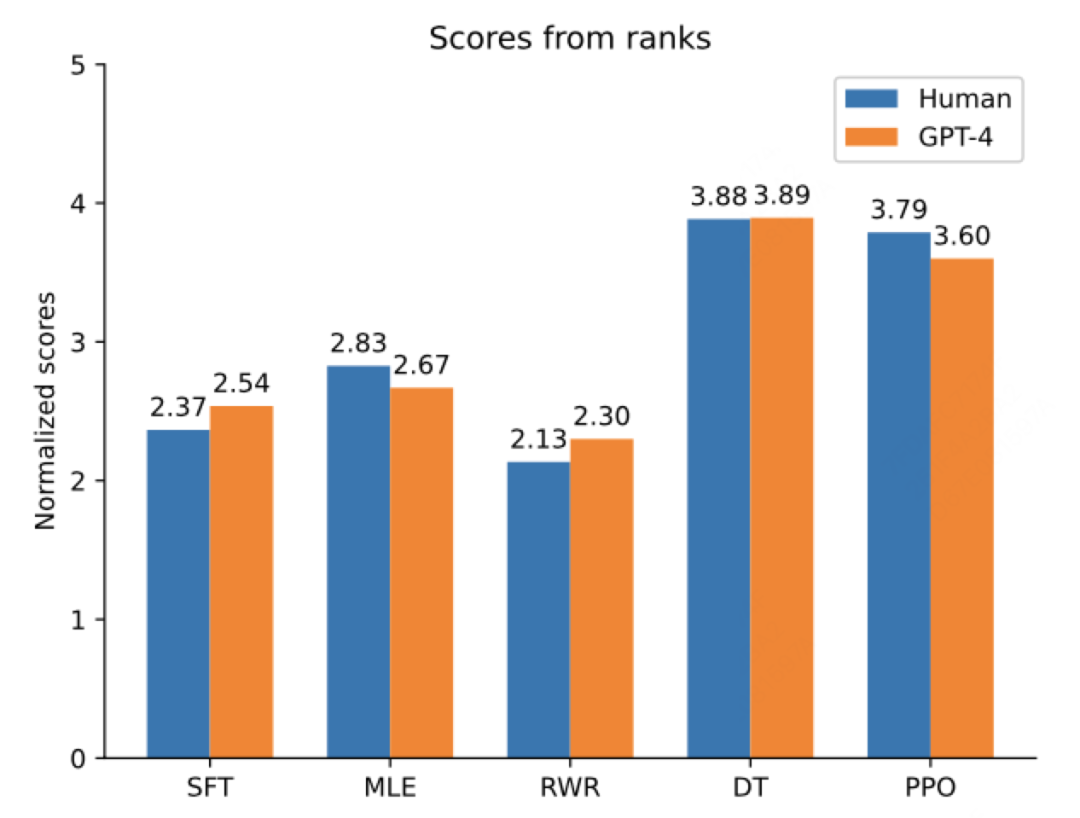
这篇是英伟达在2023.08提出的工作,探索了MLE、用reward做回归、DT(Decision Transformer)三种离线强化算法,最终发现DT的效果更好。
Decision Transformer是一个2021 RL Transformer的开山之作,但NLPer一看就懂:
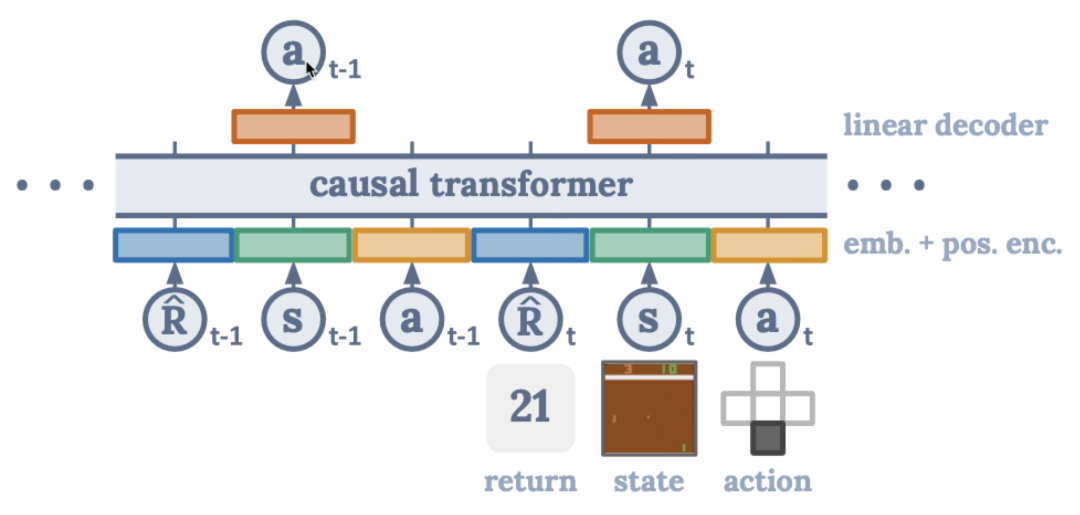
它的核心思想是把奖励、状态作为输入,让模型预测动作,从而建模三者之间的关系。比如模型训练时见过1分的答案,也见过5分的,那预测时直接输入<reward>5.0让它给出最好的结果。
这样训下来效果居然还不错,也超过了PPO:
SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF
没想到的是,英伟达不同团队在2023.10月又推出了一篇SteerLM的工作,与DT的思想类似,但会把奖励分为不同维度,比如质量、帮助性等等。
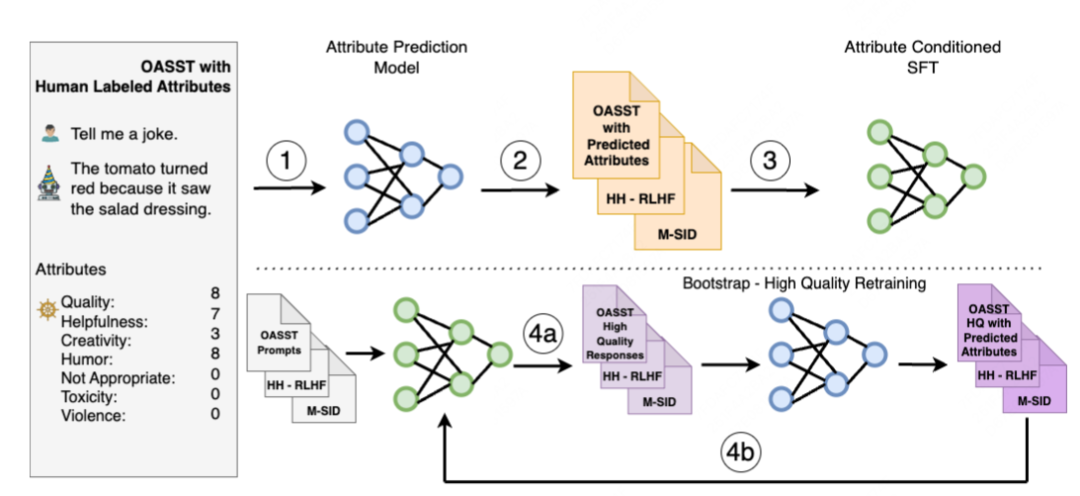
具体做法:
通过人工标注的各个维度打分,训练一个打分模型
用打分模型对更多数据打分
精调一个SFT模型,可以做到输入prompt、目标分数,输出符合分数的结果
用第三步的模型生产更多答案,再打分,如此循环
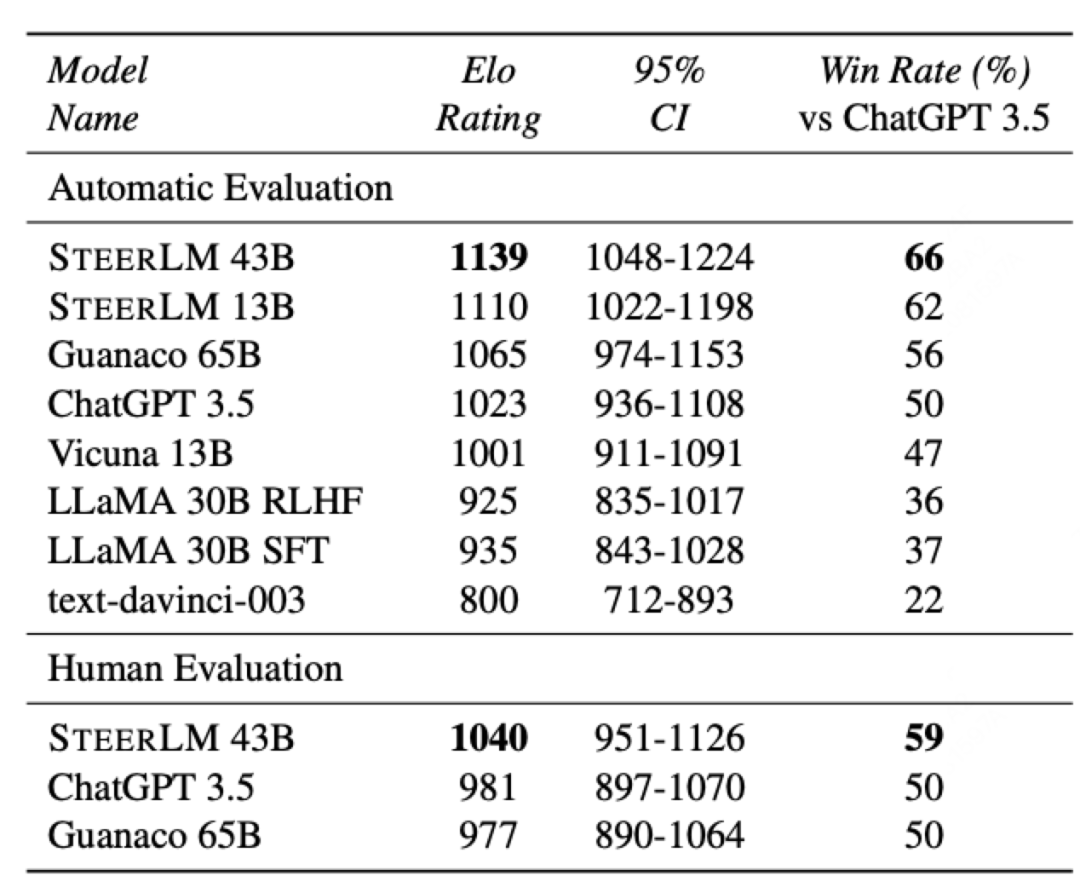
最终的效果也是好于RLHF(PPO哭晕在厕所):
总结
以上就是我最近关注的RLHF平替方法,虽然可走的路很多,但很难有一个可靠且全面的效果对比,毕竟RLHF本身就难训不稳定,几百条数据下波动几个点很正常,而且无论是自动测评还是人工测评都会带有bias。
但对于资源有限的团队来说,平替方案不失为一种选择。
参考资料
[1]
Contrastive Post-training Large Language Models on Data Curriculum: https://arxiv.org/abs/2310.02263
[2]Statistical rejection sampling improves preference optimization: https://arxiv.org/pdf/2309.06657.pdf
[3]理解Rejection Sampling: https://gaolei786.github.io/statistics/reject.html
[4]RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment: https://arxiv.org/abs/2304.06767
[5]PPO: https://arxiv.org/pdf/1707.06347.pdf

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「彩蛋:你能找到几个同厂不同组的相近工作 」
」