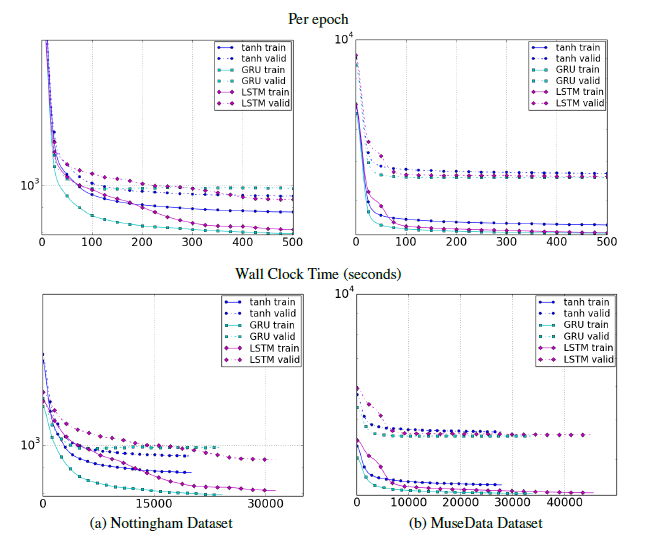
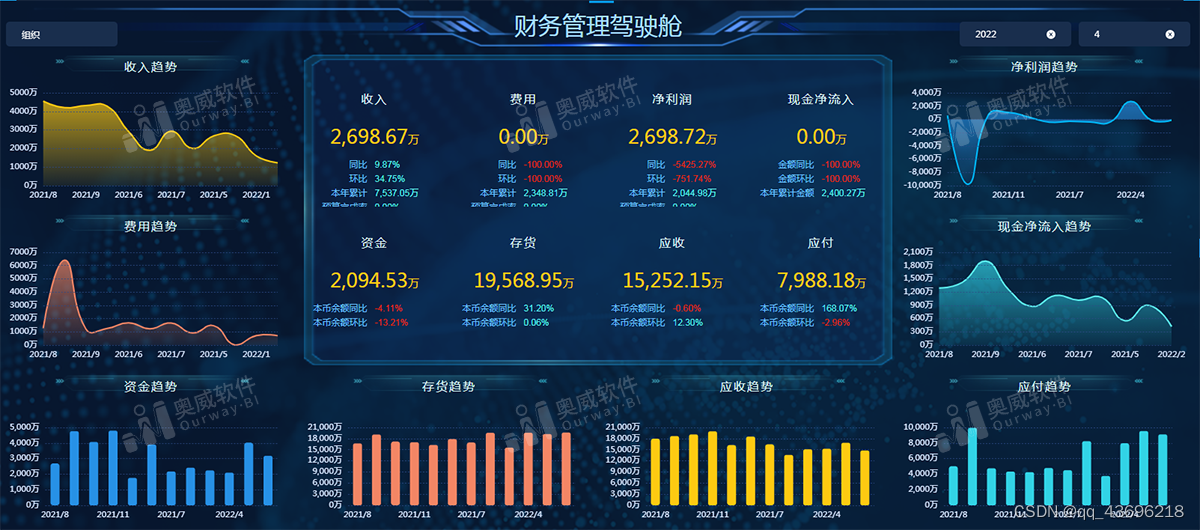
Kafka request.log中RequestQueueTimeMs、LocalTimeMs、RemoteTimeMs、ThrottleTimeMs、含义
要理解各个延时项的含义,必须从Kafka收到TCP请求、处理请求到返回TCP包整个流程开始梳理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ns0shcE7-1688922891392)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709232406001.png)]](https://img-blog.csdnimg.cn/78e95bfe0ce74b7aabd3172dc7504a53.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y8LKfDFV-1688922891393)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709232659184.png)]](https://img-blog.csdnimg.cn/96f5a9518c7042738b0edbf5f6c6b467.png)
RequestQueueTimeMs
Processor 执行processNewResponses() 方法,不断 poll队列 得到socketchannel 拿到对应的client信息拼接connectionId 执行register(String id, SocketChannel socketChannel),注册Selector上,用于真正的请求获取和响应发送I/O操作
Processor 执行processCompletedReceives 从Selector中提取已接收到的所有请求数据, 如果有对应的socketchannel ,创建Requestnew RequestChannel.Request(processor = id, context = context,... 对象,添加到requestChannel的requestQueue中
override def run(): Unit = {startupComplete()try {while (isRunning) {try {//建立新链接configureNewConnections()//注册response写事件processNewResponses()poll()//简单理解成op_read事件processCompletedReceives()processCompletedSends()processDisconnected()closeExcessConnections()} catch {case e: Throwable => processException("Processor got uncaught exception.", e)}}} finally {debug(s"Closing selector - processor $id")CoreUtils.swallow(closeAll(), this, Level.ERROR)shutdownComplete()}
}
我们可以看到,在selector中当channel有数据可读时,会调用processCompletedReceives()方法,这个时候 startTimeNanos记录了当前时间![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3px0jfuG-1688922891393)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709233757030.png)]](https://img-blog.csdnimg.cn/9cc123d5b08845029431ab5f9effe801.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-38U0SZHB-1688922891394)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709233854063.png)]](https://img-blog.csdnimg.cn/c61bc34ef4414b679153a4bdd5e5d94a.png)
此时请求已经被封装为req,但是并没有真正的被处理,此时这个请求是被放入了requestQueue中,等待I/O线程进行处理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3m311ufZ-1688922891394)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709234112670.png)]](https://img-blog.csdnimg.cn/46b9501630674650b37d9032a14e00ca.png)
KafkaRequestHandler时请求处理线程类,也是我们之前说的IO线程。每个请求处理线程实例,负责从 SocketServer 的 RequestChannel 的请求队列中获取请求对象,并进行处理。
所以如果RequestQueueTimeMs过高,说明请求进入requestQueue后由I/O线程取出时间过长,可以考虑增加IO线程数量。
LocalTimeMs
请求被取出后,会由KafkaApis中对应的方法进行处理
apis.handle(request)
在最后的finally方法中,记录了apiLocalCompleteTimeNanos
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AtbnKncX-1688922891395)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709235239490.png)]](https://img-blog.csdnimg.cn/cd6e7304545d4f96b3db200bdb2b8d7e.png)
LocalTimeMs正是记录了request真正在broker中处理的时间,也就时本地的处理时间。如果这一步延时较长,需要根据请求类型(Fetch/Produce/OffsetCommit)请求的处理逻辑来分析究竟是哪一部分的具体逻辑导致处理超时了
RemoteTimeMs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ph7GrQhM-1688922891395)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230709235710496.png)]](https://img-blog.csdnimg.cn/4e09588e39f64a48a3684a107603b043.png)
val apiRemoteTimeMs = nanosToMs(responseCompleteTimeNanos - apiLocalCompleteTimeNanos)
在RequestTime的sendResponse方法中,我们看好了responseCompleteTime被记录了。
在生产环境中,我们经常会看到对于Fetch以及Produce请求,Remote Time可能会达到500ms左右,这是什么原因呢?
当Request被后面的I/O线程处理完成后,还要依靠Processor线程发送Response给请求方。但是要注意,有一些请求不是立即可以回复的,例如Produce请求(ack=-1)以及Fetch请求(设置了min.fetch.bytes/fetch.max.wait.ms)。当要求不被满足时,kafka通过时间轮来处理一些延时操作(例如DelayFetch等)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4mwBWn4i-1688922891395)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710001008208.png)]](https://img-blog.csdnimg.cn/3a187cc4352740189461963d007b1dc8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mM8J10jD-1688922891396)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710001411243.png)]](https://img-blog.csdnimg.cn/a442ebe8612745c59d29732d44ba1ed6.png)
我们可以看到,当延时操作真正执行时时,sendResponse方法才会被调用。也就是说对于ack=-1的produce请求以及设置了min.fetch.bytes/fetch.max.wait.ms的Fetch请求(延时操作请求),RemoteTimeMs高的原因往往是可以返回相应的条件没有被满足;对于produce请求(ack=-1),我们可以排查副本间同步的时延是不是比较高(broker间网络带宽);对于Fetch请求,可能是消息不够多满足不了最小的拉取量,等待500ms返回
ThrottleTimeMs
这个指标项记录了请求被流控的时间,往往出现在做分区副本迁移时设置了流控或设置了client/user级别流控时。Kafka内置了一套软流控机制对请求的回包速度进行了限制。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KPzLQJi7-1688922891396)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710002456500.png)]](https://img-blog.csdnimg.cn/cffff9ce8c5c43aea5a4c38d492eb78d.png)
如果这个指标较高,那么我们需要看看我们是否配置了相关的流控配置项
ResponseQueueTimeMs
当请求经过一系列处理后真正完成,会被封装为response。此时与request请求一样不会真正被发送,而是被放入到response队列中等待I/O线程取出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9g4m9q6k-1688922891396)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710003105716.png)]](https://img-blog.csdnimg.cn/bc77ead7671f405f9dbd010cbc47122c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w26mGi5D-1688922891396)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710003141692.png)]](https://img-blog.csdnimg.cn/9bb481a22e27494cbe1fdc0e0da60175.png)
所以这里与RequestQueueTimeMs的意义类似,如果发现这个值比较高,可以可以考虑增加IO线程数量
ResponseSendTimeMs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yfNq26Km-1688922891396)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710003313698.png)]](https://img-blog.csdnimg.cn/f654d2cea1824a5b9b6e81f9f9d85b14.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cU4oCliU-1688922891397)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710003501504.png)]](https://img-blog.csdnimg.cn/bbdec64ce5424099a660fb8d06cbc429.png)
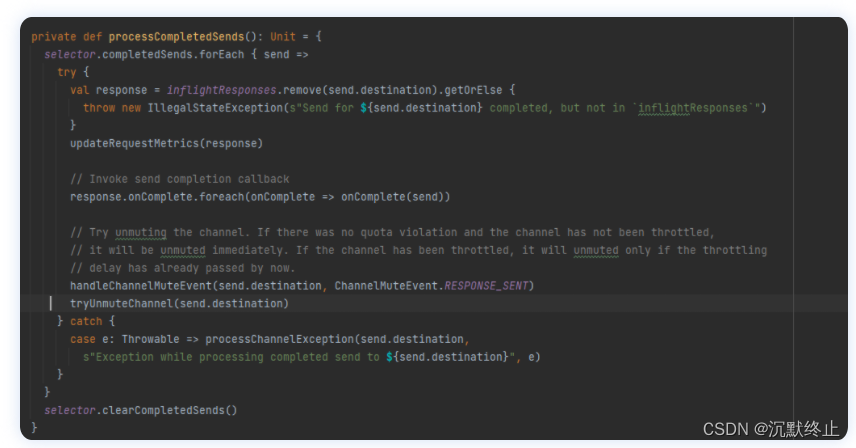
当Processor将Response返回给Request发送方后,对于有些请求需要将其放入inflightResponses,也就是一个临时的Response队列中。这个队列存在的原因是Fetch/Produce请求的回调逻辑要在 Response 被发送回发送方之后,才能执行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MrOlmEYA-1688922891397)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710005058479.png)]](https://img-blog.csdnimg.cn/2831c349c9c74347b0fe7206e4a9aa76.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HKgzpgyU-1688922891397)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710003912114.png)]](https://img-blog.csdnimg.cn/f972ea0685c147a9a431b86507146cf1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aJAHFBNh-1688922891397)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710003844837.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v1F7ACkN-1688922891397)(C:\Users\jimmy\AppData\Roaming\Typora\typora-user-images\image-20230710010545426.png)]](https://img-blog.csdnimg.cn/5f3d8c5e271243c9b2d48b7b4fcc7243.png)
用一个图来表示
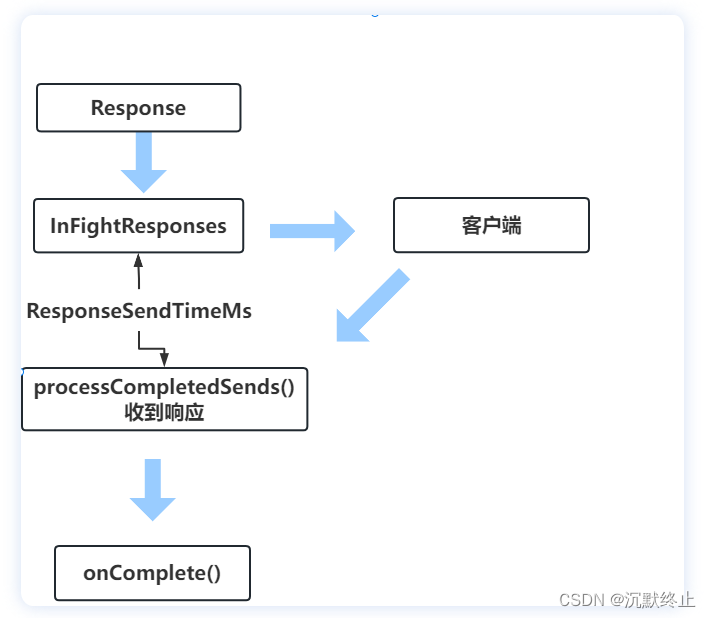
如果ResponseSendTime较高,表示端到端的时延比较高,要对从broker->客户端以及客户端 ->broker整个链路上的网络问题进行排查(是不是网卡队列阻塞了,broker网络带宽达到瓶颈等)