文章目录
- 一、循环神经网络
- 1. 无隐状态的神经网络
- 2. 有隐状态的循环神经网络
- 3. 基于循环神经网络的字符级语言模型
- 4. 困惑度
- 5. 小结
- 二、循环神经网络的从零开始实现
- 1. 独热编码
- 2. 初始化模型参数
- 3. 循环神经网络模型
- 4. 预测
- 5. 梯度裁剪
- 6. 训练
一、循环神经网络
n元语法模型,单词 xt 在时间步 t 的条件概率仅取决于前 n-1个单词

如果想要引入时间步 t-(n-1) 之前单词的影响到 xt 上,则需要增加 n,但会造成模型参数数量呈指数级增长。这时引入隐变量模型:

ht-1是隐状态,也称为隐藏变量,它储存了时间步 t-1 的序列信息。可以基于当前输入 xt 和 先前隐状态 ht-1来计算时间步 t 处的任何时间的隐状态:

函数 f 表示了隐变量模型不是近似值。
隐状态与之前具有隐藏单元的隐藏层不同:
-
隐藏层:从输入到输出的路径上隐藏的层。如下图 h1,h2等等
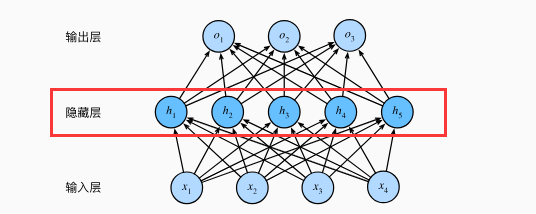
-
隐状态:给定步骤所做的任何事情的输入,这些状态只能通过时间步的数据来计算。如下图的 Ht-1,Ht,Ht+1
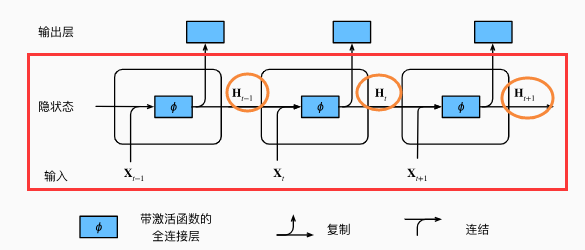
循环神经网络则是具有隐状态的神经网络。
1. 无隐状态的神经网络
下面是只有但隐藏层的多层感知机。设隐藏层的激活函数为Ф,给定一个小批量样本X∈nxd,其中批量大小为n,输入维度为d,则隐藏层的输出H∈Rnxh为:
隐藏层参数为Wxh∈Rdxh,偏置参数bh∈R1xh,以及隐藏单元数目h。
可以看出这是一个线性神经网络通过一个激活函数,使得网络变为非线性神经网络。将隐藏变量H用作输出层的输入,输出层为:
O∈Rnxq是输出变量,Whq∈Rhxq是权重参数,bq∈R1xq是输出层的偏置参数。如果是分类问题,可以接softmax(O)来计算输出类别的概率分布。
2. 有隐状态的循环神经网络
有了隐状态后,假设在时间步t有小批量输入Xt∈Rnxd,Xt的每一行对应于来自该序列时间步t处的一个样本。
Ht∈Rnxh表示时间步t的隐藏变量,与多层感知机不同的是,这里保存了前一个时间步的隐藏变量Ht-1,并引入了一个新的权重系数Whh∈Rhxh来描述当前时间步中使用前一个时间步的隐藏变量。
当前时间步隐藏变量由当前时间步的输入与前一个时间步的隐藏变量一起计算得出:
从相邻时间步的隐藏变量Ht和Ht-1可知,这些变量捕获保留了序列直到当前步的历史信息,可以理解为当前时间步下的状态或记忆,因此这样的隐藏变量被称为隐状态。
由于当前时间步中,隐状态使用的定义与前一个时间步中使用的定义相同,因此计算是循环的。于是基于循环计算的隐状态神经网络被命名为循环神经网络。在循环神经网络计算的层称为循环层。
将完整的输入序列展开得到下图所展示的结构:

对于时间步t,输出层的输出类似于多层感知机的计算:

在任意时间步t,隐状态的计算可以被视为:
- 拼接当前时间步 t 的输入Xt和前一时间步 t-1 的隐状态Ht-1;
- 将拼接的结果送入带有激活函数Ф的全连接层。 全连接层的输出是当前时间步 t 的隐状态Ht。
下面是具有隐状态的循环神经网络

隐状态XtWxh + Ht-1Whh的计算,相当于Xt和Ht-1的拼接与Wxh和Whh的拼接的矩阵乘法。
使用简单的代码来说明一下,定义矩阵X、W_xh、H和W_hh,它们的形状分别为(3, 1)、(1, 4)、(3, 4)和(4, 4)。分别将X乘以W_xh,将H乘以W_hh,然后将两个乘法相加,得到一个(3, 4)的矩阵。
import torch
from d2l import torch as d2l# 形状分别为(3, 1)、(1, 4)、(3, 4)、(4, 4)
# torch.normal生成均值为0方差为1的正态分布
X, W_xh = torch.normal(0, 1, (3, 1)), torch.normal(0, 1, (1, 4))
H, W_hh = torch.normal(0, 1, (3, 4)), torch.normal(0, 1, (4, 4))
torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
tensor([[ 0.8949, -0.3242, -0.7219, 0.8379],[-1.2085, 1.3454, -1.2772, -2.4002],[-0.1999, -2.9783, 3.5500, 2.6767]])
沿列(轴1)进行拼接X和H,沿行(轴0)拼接矩阵W_xh和W_hh,两个拼接分别产生形状(3,5)、(5,4)的矩阵,相乘为(3,4)的矩阵。
# 沿列(轴1)拼接矩阵X和H,沿行(轴0)拼接矩阵W_xh和W_hh
# 两个拼接分别产生形状(3,5)、(5,4)的矩阵
# 相乘为(3,4)的矩阵
torch.matmul(torch.cat((X, H), 1), torch.cat((W_xh, W_hh), 0))
tensor([[ 0.8949, -0.3242, -0.7219, 0.8379],[-1.2085, 1.3454, -1.2772, -2.4002],[-0.1999, -2.9783, 3.5500, 2.6767]])
3. 基于循环神经网络的字符级语言模型
根据过去和当前词元预测下一词元

训练过程中:
- 对每个时间步的输出层的输出进行softmax操作
- 利用交叉熵损失计算模型输出和标签之间的误差
- 隐藏层中隐状态的循环计算,第3个时间步的输出O3由文本序列"m","a"和"c"确定
- 训练数据文本序列下一个字符为"h",第3个时间步的损失将取决于下一个字符的概率分布,下一个字符是基于特征序列"m","a"和"c"和时间步的标签"h"确定
4. 困惑度
困惑度:下一个词元的实际选择数的调和平均数,用来评估模型
一个序列中所有的n个词元的交叉熵损失的平均值来衡量:
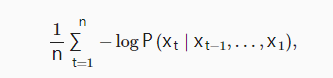
对上式求求指数,可得困惑度
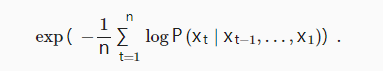
- 在最好的情况下,模型总是完美地估计标签词元的概率为1。 在这种情况下,模型的困惑度为1。
- 在最坏的情况下,模型总是预测标签词元的概率为0。 在这种情况下,困惑度是正无穷大。
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布。 在这种情况下,困惑度等于词表中唯一词元的数量。
5. 小结
- 对隐状态使用循环计算的神经网络称为循环神经网络(RNN)。
- 循环神经网络的隐状态可以捕获直到当前时间步序列的历史信息。
- 循环神经网络模型的参数数量不会随着时间步的增加而增加。
- 我们可以使用困惑度来评价语言模型的质量。
二、循环神经网络的从零开始实现
从头开始基于循环神经网络实现字符级语言模型。
# 读取数据集
%matplotlib inline
import math
import torchfrom torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
1. 独热编码
每个词元都有一个对应的索引,表示为特征向量,即每个索引映射为相互不同的单位向量。
词元表不同词元个数为N,词元索引范围为0到N-1。词元的索引为整数,那么将创建一个长度为N的全0向量,并将第i处元素设置为1。则此向量是原始词元的一个独热编码。
假如有2个词元"cat"和"dog"
- "cat"对应:[1, 0]
- "dog"对应:[0, 1]
索引为0和2的独热向量
# 索引为0和2的独热向量
F.one_hot(torch.tensor([0, 2]), len(vocab))
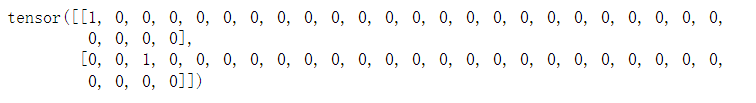
采样的小批量数据形状为二维张量:(批量大小,时间步数),one_hot函数将其转换为三维张量:(时间步数,批量大小,词表大小)
# 采样的小批量数据形状为二维张量:(批量大小,时间步数)
# one_hot函数将其转换为三维张量:(时间步数,批量大小,词表大小)
# 方便我们通过最外层维度,一步一步更新小批量数据的隐状态
X = torch.arange(10).reshape((2, 5))
print(F.one_hot(X.T, 28).shape)
# 显示第一行
F.one_hot(X.T, 28)[0,:,:]

2. 初始化模型参数
隐藏单元数num_hiddens是一个可调的超参数
训练语言模型时,输入和输出来自相同的词表,具有相同的维度即词表大小
"""
初始化模型参数:1、隐藏层参数2、输出层参数3、附加梯度
"""
# (词表大小,隐藏层数,设备)
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_size# 定义函数normal(),初始化模型的参数def normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params
3. 循环神经网络模型
定义init_rnn_state函数在初始化时返回隐状态,该函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)。
# 定义init_rnn_state函数在初始化时返回隐状态
# 该函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)
def init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )
循环神经网络通过最外层的维度实现循环,以便时间步更新小批量数据的隐状态H
# 循环神经网络通过最外层的维度实现循环,以便时间步更新小批量数据的隐状态H
def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []# X的形状:(批量大小,词表大小)for X in inputs:# 激活函数tanh,更新隐状态HH = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)
创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数
"""
从零开始实现的循环神经网络模型:
1、定义网络模型的参数
2、对词表进行独热编码
3、初始化模型参数并返回隐状态
"""
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""# 定义类的初始化,将传入的参数赋值给对象的属性,以便后续使用def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):# 对输入进行独热编码,返回状态及参数X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):# 初始化参数return self.init_state(batch_size, self.num_hiddens, device)
检查输出是否具有正确的形状。 例如,隐状态的维数是否保持不变。
num_hiddens = 512
# 网络模型
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
# 获得网络初始状态
state = net.begin_state(X.shape[0], d2l.try_gpu())
# 将X移到GPU上,并且返回输出Y和状态
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
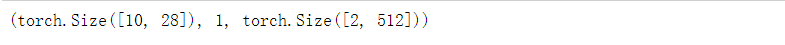
可以看到输出形状是(时间步数x批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)。
4. 预测
定义预测函数
"""
定义预测函数:
1、prefix是用户提供的字符串;
2、循环遍历prefix的开始字符时不输出,不断将隐状态传递给下一个时间步;
3、在此期间模型进行自我更新(隐状态),不进行预测;
4、2和3步骤称为预热期,预热期过后隐状态的值更适合预测,从而预测字符并输出。
"""
# prefix:前缀字符串
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]# 匿名函数:改变输出的形状get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))# 预热期:不进行输出for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])# 预热期过了之后,进行预测for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])
测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符
# 测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符。
# 未训练模型,输出预测结果没有联系
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())

5. 梯度裁剪
为什么要梯度裁剪:
1、对于长度为T的序列,我们在迭代中计算T个时间步上的梯度,在反向传播过程中产生长度为T的矩阵乘法链;
2、T较大时,会导致数值不稳定,例如梯度消失或者梯度爆炸。
一个流行的替代方案是通过将梯度g投影回给定半径 (例如θ)的球来裁剪梯度g。

def grad_clipping(net, theta): #@save"""裁剪梯度"""if isinstance(net, nn.Module):# 附加梯度的参数params = [p for p in net.parameters() if p.requires_grad]else:# 梯度的范数:对应图里作为分母的"||g||"params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))# 如果梯度过大,将其限制到θif norm > theta:for param in params:param.grad[:] *= theta / norm
6. 训练
在一个迭代周期内训练模型:
1、序列数据的不同采样方法(随机采样和顺序分区)将导致状态初始化的差异;
2、在更新模型参数之前裁剪梯度,这样可以保证训练过程中如果某点发生梯度爆炸,模型也不会发散;
3、用困惑度评价模型,使得不同长度的序列也有了可比性。
- 顺序分区:只在每个迭代周期的开始位置初始化隐状态。
- 随机抽样:每个样本都是在一个随机位置抽样的,因此需要在每个迭代周期重新初始化隐状态。
#@save
"""
训练网络一个迭代周期:
1、初始化状态,将数据传到GPU上
2、计算损失,进行梯度裁剪并更新模型参数
"""
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期(定义见第8章)"""# 状态,时间state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量# detach_()将张量从计算图中分离出来,不会影响到原始张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()# 将Y 进行转置并展平成一维向量y = Y.T.reshape(-1)# 将X,y移动到设备上,并且输入到模型中X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()# 如果更新器 updater 是 torch.optim.Optimizer 类型,则调用 updater.step() 方法进行参数更新;# 否则调用 updater(batch_size=1) 进行参数更新。if isinstance(updater, torch.optim.Optimizer):updater.zero_grad() # 梯度置零l.backward() # 反向传播,知道如何调整参数以最小化损失函数grad_clipping(net, 1) # 梯度裁剪updater.step() # 使用优化器来更新参数else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)# y.numel()计算y中元素数量metric.add(l * y.numel(), y.numel())# 使用指数损失函数计算累积平均困惑度 math.exp(metric[0] / metric[1]) 和训练速度 metric[1] / timer.stop()。return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
- updater.zero_grad(): 这一行代码将模型参数的梯度置零,以便在每次迭代中计算新的梯度。
- l.backward(): 这一行代码使用反向传播算法计算损失函数对模型参数的梯度。通过计算梯度,我们可以知道如何调整模型参数以最小化损失函数。
- grad_clipping(net, 1): 这一行代码对模型的梯度进行裁剪,以防止梯度爆炸的问题。梯度爆炸可能会导致训练不稳定,裁剪梯度可以限制梯度的范围。
- updater.step(): 这一行代码使用优化器(如SGD、Adam等)来更新模型的参数。优化器根据计算得到的梯度和预定义的学习率来更新模型参数,以使模型更好地拟合训练数据。
循环神经网络的训练函数也支持高级API实现
# 循环神经网络的训练函数也支持高级API实现
#@save
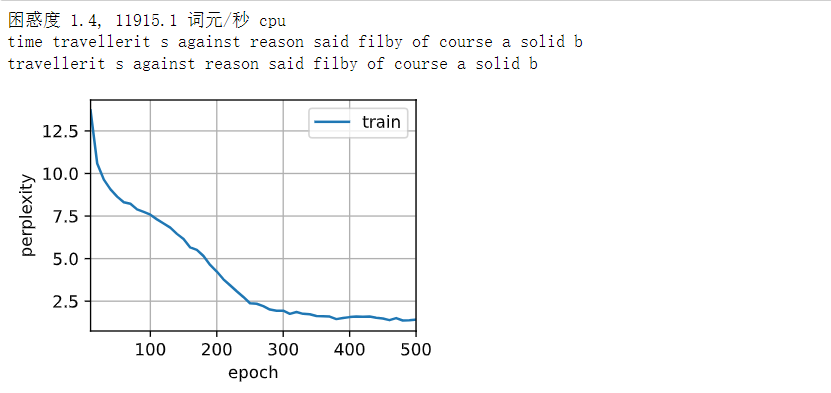
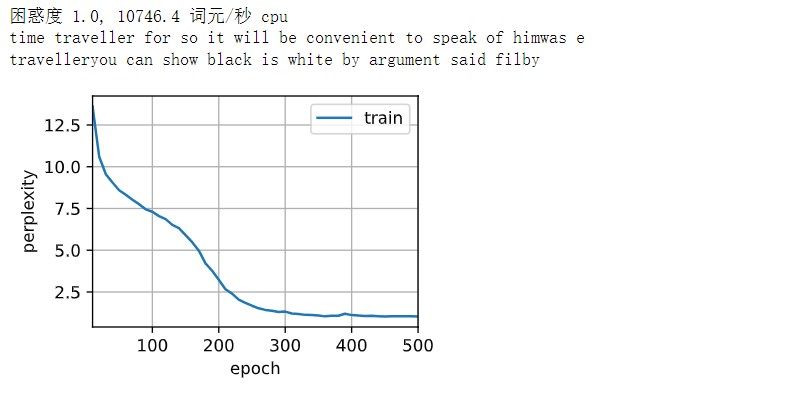
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""训练模型(定义见第8章)"""loss = nn.CrossEntropyLoss()# 动画窗口:窗口显示一个图例,图例名称为 "train",x 轴的范围从 10 到 num_epochsanimator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)# 每10个epoch,对输入字符串进行预测,并将预测结果添加到动画中if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛
# 在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
检查一下随机抽样方法的结果
# 检查一下随机抽样方法的结果
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True)