- 硅基流动官网的模型分类
- 类型(应用场景)
- 标签(功能特性)
- DeepSeek各版本介绍
- 1. DeepSeek 系列模型的定位与核心架构
- (1)DeepSeek-MoE
- (2)DeepSeek-V3
- (3)DeepSeek-R1
- 2. 蒸馏模型(Distilled Models)
- (1)DeepSeek-R1-Distill-Qwen 系列
- (2)DeepSeek-R1-Distill-Llama 系列
- 蒸馏技术的局限性
- ollama上的版本
- 开源与商业化
- 1. DeepSeek 系列模型的定位与核心架构
- 大模型的1.5B 7B 8B 大小是什么意思?
- 参数量的意义
- 1. 模型能力与参数量的关系
- 2. 资源消耗
- 3. 性能边际效应
- 为什么用 7B、8B 等具体数字?
- 如何选择模型大小?
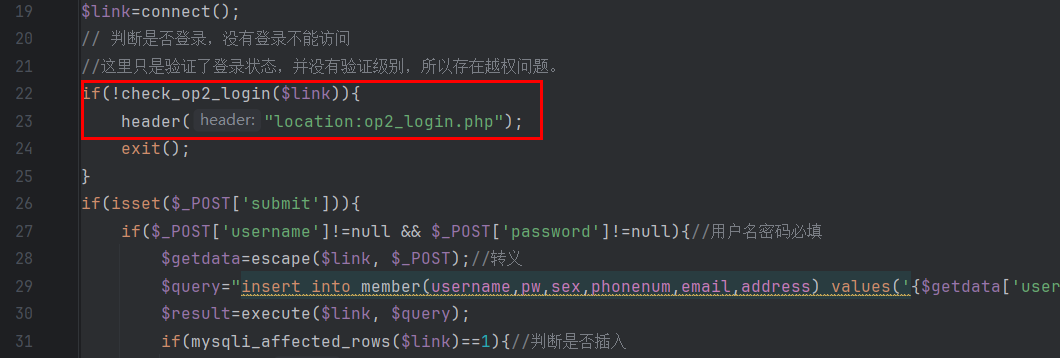
- 需要注意的误区
- 参数量的意义
- 大模型所涉及的软件
- 下载并部署大模型的软件
- AI 客户端
- 客户端的作用
- 一些客户端软件
- vscode 集成大模型的插件
- 大模型安装流程
硅基流动官网的模型分类
类型
对话 生图 嵌入 重排序 语音 视频
标签
视觉 Tools FIM Math Coder 图生图 可微调
- 类型描述模型的主要应用场景,如对话、生图等。
- 标签强调模型的附加功能或专长,如数学能力、支持工具调用等。
- 选择时可根据需求组合类型和标签(例如:选择“对话+可微调”模型来定制客服机器人)。
类型(应用场景)
-
对话
- 指专为自然语言交互设计的模型,能理解和生成连贯的对话(如聊天机器人、客服助手)。
- 例子:类似 ChatGPT 的模型,适用于问答、情感交流、任务指导等场景。
-
生图(Text-to-Image)
- 根据文本描述生成图像的模型,将文字转化为视觉内容。
- 例子:类似 Stable Diffusion、DALL-E,适用于艺术创作、广告设计等。
-
嵌入(Embedding)
- 将文本、图像等数据转化为高维向量,用于语义理解或相似性计算。
- 应用:搜索优化、推荐系统、聚类分析(如文档检索)。
-
语音
- 处理语音相关的任务,如语音识别(ASR)、语音合成(TTS)或语音对话。
- 例子:智能音箱、语音助手背后的模型。
-
视频
- 生成或分析视频内容,可能包括视频生成、剪辑、内容理解等。
- 应用:视频自动剪辑、动态内容生成(如广告视频)。
-
重排序(Reranking)
- 对搜索结果或推荐列表进行优化排序,提升结果相关性。
- 场景:搜索引擎、电商推荐中调整排序优先级。
标签(功能特性)
前六个都是对话模型的标签,或者叫 子类型
-
视觉(Vision)
- 模型具备图像或视频处理能力,如分类、分割、生成、理解。
- 例子:图像描述生成、视频内容分析。
-
Tools
- 支持调用外部工具或 API,增强模型功能(如联网搜索、计算器、数据库查询)。
- 场景:自动化工作流中结合外部工具完成任务。
-
FIM(Fill-in-Middle)
- 专为代码补全设计的模型,能填充代码段中间的缺失部分(而不仅是续写末尾)。
- 用途:提升开发者效率,适用于 IDE 的智能补全。
-
Math
- 擅长解决数学问题,包括符号计算、方程求解、定理证明等。
- 例子:解数学题、工程计算辅助。
-
Coder
- 面向代码生成、理解或调试的模型,支持多种编程语言。
- 应用:自动生成代码、代码注释、Bug 修复。
-
可微调(Fine-tunable)
- 允许用户用自有数据对模型进行微调,适配特定任务或领域。
- 场景:定制化需求(如医疗术语理解、垂直行业对话)。
-
图生图(Image-to-Image)
- 基于输入图像生成新图像,如风格迁移、图像修复、超分辨率等。
- 例子:将草图转化为渲染图,老照片修复。
DeepSeek各版本介绍
以下是关于 DeepSeek 系列模型及其相关术语的详细解释:
1. DeepSeek 系列模型的定位与核心架构
(1)DeepSeek-MoE
- 定义:混合专家模型(Mixture of Experts, MoE)是一种通过动态分配任务给不同“专家子网络”提升模型效率的架构。虽然搜索结果未直接提及 DeepSeek-MoE,但结合行业惯例推测,它可能是 DeepSeek 团队基于 MoE 架构优化的模型,旨在平衡计算资源与性能。
- 特点:MoE 架构通常通过稀疏激活减少计算量,适合处理多任务场景,但需要复杂的路由算法支持。
(2)DeepSeek-V3
- 定位:DeepSeek-V3 是 DeepSeek 团队在 2024 年 12 月发布的预训练基础模型,参数规模达 671B,专注于通用语言理解与生成任务。
- 应用场景:文本生成、问答、摘要等基础 NLP 任务,但未针对复杂推理进行优化。
- 重要性:为后续的 DeepSeek-R1 系列提供了基座模型支持。
(3)DeepSeek-R1
- 定位:DeepSeek-R1 是专门针对复杂推理任务设计的模型,擅长数学、编程、逻辑谜题等多步骤推理,性能对标 OpenAI 的 o1 系列。
- 技术路线:
- DeepSeek-R1-Zero:完全依赖强化学习(RL)训练,未使用监督微调(SFT),直接从基座模型(DeepSeek-V3)进化而来,展现了“自我反思”能力。
- DeepSeek-R1:在 R1-Zero 基础上引入少量高质量人工数据,通过两阶段强化学习和监督微调优化,提升可读性与多任务通用性。
- 优势:在数学竞赛(如 AIME 2024)和代码生成任务中表现接近人类专家水平。
2. 蒸馏模型(Distilled Models)
DeepSeek-R1-Distill-Qwen-7B 指的是运用知识蒸馏技术将DeepSeek-R1的推理能力迁移到Qwen-7B模型上所得到的新模型。
-
DeepSeek:表示开发这个模型的组织或团队。
-
R1:表示这是DeepSeek系列模型中使用强化学习(RL)来提升推理能力的第一个版本。
-
Distill:代表蒸馏,表明该模型是通过知识蒸馏技术得到的。蒸馏 就是 选择一个大型的教师模型(如DeepSeek-R1 671B)和一个较小的学生模型(Qwen-7B),然后通过特定的技术和算法,将教师模型的知识和推理能力转移到学生模型上所得到的新模型。
-
Qwen:这里就是以通义千问Qwen系列模型作为基础模型,利用它的架构和一些基础能力等。
-
7B:表示该模型具有70亿个参数。
DeepSeek-R1具有6710亿参数,有着强大的推理能力和广泛的知识覆盖,能够为蒸馏提供丰富的知识基础。而Qwen-7B作为学生模型,参数量相对小很多,在计算效率和内存占用上具有优势。通过知识蒸馏技术,将DeepSeek-R1的知识和推理能力迁移到Qwen-7B中,使Qwen-7B在保持较小规模的同时,尽可能学习到教师模型的能力,以实现更好的性能。
DeepSeek-R1的蒸馏模型,主要分为两类:
(1)DeepSeek-R1-Distill-Qwen 系列
- 基座模型:基于 Qwen 架构(如 Qwen-2.5 系列),通过微调 DeepSeek-R1 生成的推理数据实现能力迁移。
- 参数版本:1.5B、7B、14B、32B,适用于不同规模的推理任务:
- 1.5B:轻量级任务(文本分类、简单问答),适合移动端或低显存设备。
- 7B/14B:中等复杂度任务(对话系统、代码生成),性能接近部分中大规模闭源模型。
(2)DeepSeek-R1-Distill-Llama 系列
- 基座模型:基于 Llama 架构(如 Llama3.1-8B-Base),通过类似蒸馏方法优化推理能力。
- 参数版本:8B、70B,适用于高性能推理场景:
- 8B:适合单卡 GPU 部署,性能优于同规模通用模型。
- 70B:接近 R1-671B 的部分能力,但未经过强化学习训练,成本远低于原版。
蒸馏技术的局限性
- 蒸馏模型依赖大模型生成的数据,推理能力弱于原版 R1-671B,尤其在需要“涌现式思考”的任务中差距显著。
- 部分商家可能混淆蒸馏模型与满血版 R1,需通过复杂问题测试响应时间和答案质量辨别。
- 技术差异化:R1 依赖纯强化学习实现推理能力突破,蒸馏模型通过知识迁移降低成本,但需警惕性能差距。
ollama上的版本
ollama 上的 DeepSeek-R1 的 1.5B、7B、8B、14B、32B、70B 版本都是蒸馏版本
1.5B版本的模型 其实就是 DeepSeek-R1-Distill-Qwen-1.5B模型
开源与商业化
- DeepSeek-R1 及蒸馏模型均以 MIT 协议开源,允许商业使用和二次开发,与 OpenAI 的闭源策略形成对比。
大模型的1.5B 7B 8B 大小是什么意思?
在大模型领域,1.5B、7B、8B 等数字表示模型的参数量(Parameters),即模型中可学习的参数(权重)总数,通常用 B(Billion,十亿) 作为单位,所以1.5B是15亿参数,7B是70亿,8B是80亿。
参数量的意义
参数是模型从数据中学习的“知识”载体,参数越多,模型理论上能捕捉更复杂的模式,但同时也需要更多的计算资源和数据。以下是关键点:
1. 模型能力与参数量的关系
- 小参数量(1B~10B):
适合轻量级任务(如文本生成、简单问答),推理速度快,可在消费级 GPU 甚至 CPU 上运行。
例子:Meta 的 LLaMA-1(7B)、ChatGLM-6B(60 亿参数)。 - 中等参数量(10B~100B):
能力更强,可处理复杂逻辑(如数学推理、长文本生成),但需要专业 GPU(如 A100)支持。
例子:LLaMA-2(13B)、Falcon(40B)。 - 大参数量(100B+):
接近人类水平的泛化能力(如 GPT-4),但训练和推理成本极高,通常仅限企业级应用。
2. 资源消耗
- 训练成本:参数量越大,训练所需算力(GPU/TPU)和数据量呈指数级增长。
例如:训练 7B 模型需要数千 GPU 小时,而 175B 的 GPT-3 需数万小时。 - 推理成本:
- 7B 模型可在 16GB 显存的 GPU(如 RTX 3090)上运行。
- 70B 模型需要多卡或高端服务器级 GPU(如 A100 80GB)。
3. 性能边际效应
- 参数量增加会提升模型能力,但达到一定规模后边际收益递减。
例如:7B → 13B 提升显著,但 70B → 130B 的增益可能不如预期。
为什么用 7B、8B 等具体数字?
- 工程权衡:模型参数量通常通过调整层数(Layers)、注意力头数(Heads)、隐藏维度(Hidden Size)等设计得出。例如:
- LLaMA-7B:32 层,32 头,4096 隐藏维度 → 约 70 亿参数。
- 硬件适配:参数规模需匹配显存容量。例如:
- 7B 模型量化后可在手机端运行,8B 可能针对特定硬件优化。
如何选择模型大小?
| 参数量 | 适用场景 | 硬件需求 | 典型用途 |
|---|---|---|---|
| 1B~3B | 移动端、边缘设备 | 手机/嵌入式设备 | 轻量问答、本地翻译 |
| 7B~13B | 个人开发者、中小型服务器 | 单卡 GPU(如 RTX 3090) | 复杂对话、代码生成 |
| 20B~70B | 企业级服务器、云计算 | 多卡 GPU/A100 | 专业领域推理(法律、医疗) |
| 100B+ | 超大规模商业应用 | 分布式计算集群 | 通用人工智能(如 GPT-4) |
-
选择建议:
- 资源有限 → 小模型(1B~7B) + 量化技术
- 追求性能 → 中等模型(7B~70B) + 专业 GPU
- 企业级需求 → 百亿级模型 + 云计算支持
-
1.5B 模型的适用场景:
- 轻量级任务:适合移动端或低配置设备运行(如简单问答、文本生成)。
- 快速推理:参数量小,响应速度更快,适合实时性要求高的场景。
- 资源受限环境:显存不足 8GB 的显卡可优先选择小参数模型。
需要注意的误区
- 参数量 ≠ 绝对性能:
模型架构(如 Transformer 优化)、训练数据质量、对齐方法(如 RLHF)同样重要。- 例如:7B 的 Mistral 模型可能优于某些 13B 的老旧架构模型。
- 量化与压缩:
通过量化(如 4-bit 压缩),大模型可降低显存占用,但会轻微损失精度。
大模型所涉及的软件
下载并部署大模型的软件
-
Ollama:一个本地化部署框架,专注于简化大模型的安装与运行(如 Llama、DeepSeek - R1、Mistral 等),支持通过命令行直接调用模型。
-
LM Studio:自带 UI 界面。
-
大模型与部署工具的关系
- DeepSeek:独立的大模型产品(如 DeepSeek - R1),由国内团队开发,以高性能和算法优化著称。
- 协作关系:Ollama 是部署工具,DeepSeek 是模型提供方。用户通过 Ollama 安装 DeepSeek - R1 后,可通过 ChatBox 或其他前端工具与其交互。Ollama 专注于模型部署,而 DeepSeek 是可通过 Ollama 安装的模型之一。
AI 客户端
客户端的作用
- 用户体验优化:Ollama 依赖命令行操作,而 ChatBox 提供图形化界面,简化交互流程,提升操作效率。
- 多模型集成:支持连接多种大语言模型(如 OpenAI GPT、Claude、DeepSeek、本地部署的 Llama2/Mistral 等),用户可灵活切换模型以适应不同任务需求。
- 功能增强:提供 Prompt 调试、历史记录管理、数据安全等 Ollama 不具备的特性。
- 高级功能扩展:支持图像生成(如 DALL - E - 3)、文档交互、联网搜索等,覆盖办公、开发、创意等场景。
一些客户端软件
- 桌面客户端
- ChatBox 桌面客户端:免费开源项目,功能相对单一,简单易用,适合快速上手。
- Cherry Studio 桌面客户端:免费开源项目,功能丰富,支持多模型。
- Web 部署客户端
- OpenWebUI:一般需要 docker 部署。
- 浏览器插件
- page assist 浏览器插件:可以提供大模型的 webUI 界面。
- 收费客户端
- CloseChat 和 LobeChat:部分功能需收费,但有丰富的插件市场,而且可以进行联网查询。
vscode 集成大模型的插件
- Continue 插件
- cline 插件 或者 Roo Code 插件
大模型安装流程
- 通过 Ollama 安装模型(如
ollama run deepseek - r1:7b)。 - 在 ChatBox 中配置 Ollama 的本地 API 地址,选择已安装的模型。
- 通过 ChatBox 的界面与模型交互,利用其高级功能(如 Prompt 优化、多模型切换)。


![【洛谷P1955】程序自动分析[NOI2015]](https://cdn.luogu.com.cn/upload/image_hosting/aq6f4ym8.png)