几种流行的 Python 性能加速方案对比:https://zhuanlan.zhihu.com/p/604519817
对于一般通用场景用户,对性能没有那么强烈的诉求,紧跟官方步伐,升级到最新版本的 Python 既可,或者使用 PyPy。Numba、Codon、Taichi 等这一类,原理上基本相同,也都是从某个场景发展过来的较为通用的方案,但是也都有各自的一些限制,按照场景选择自己顺手的即可。
Cython、Pybind11、PyO3 可以看做一类,都是需要学习新语言,相对 Cython 在语言学习成本上最低,但是也更小众,Pybind11、PyO3 比较适合的场景是为现有的 C++、Rust 代码,提供 Python API,如果不想写 C++、Rust,又对性能有很高的诉求,Cython 是个不错的选择,如果是新开项目,可以尝试下逐渐受关注的 Rust。
推荐直接使用 C、C++开发,然后使用 ctypes 粘起来
1、高性能 Python 编译器 Codon
:https://github.com/exaloop/codon
文档:https://docs.exaloop.io/codon/general/intro
众所周知,Python 是一门简单易学、具有强大功能的编程语言,在各种用户使用统计榜单中总是名列前茅。相应地,围绕 Python,研究者开发了各种便捷工具,以更好的服务于这门语言。
编译器充当着高级语言与机器之间的翻译官,不同版本的 Python 编译器已被开发出来,其中Codon 就是一个高性能的 Python 编译器。
作为高性能 Python 编译器,Codon 可将 Python 代码编译为本机机器代码,而无需任何运行时开销。在单线程上,Python 的典型加速大约为 10-100 倍或更多。Codon 的性能通常与 C/C++ 的性能相当。与 Python 不同,Codon 支持本机多线程,这可以使速度提高很多倍。Codon 可通过插件基础结构进行扩展,它允许用户合并新的库、编译器优化甚至关键字。
Codon 框架是完全模块化和可扩展的,允许无缝集成新模块、编译器优化、领域特定语言等,并积极为生物信息学和量化金融等多个领域开发新的 Codon 扩展。
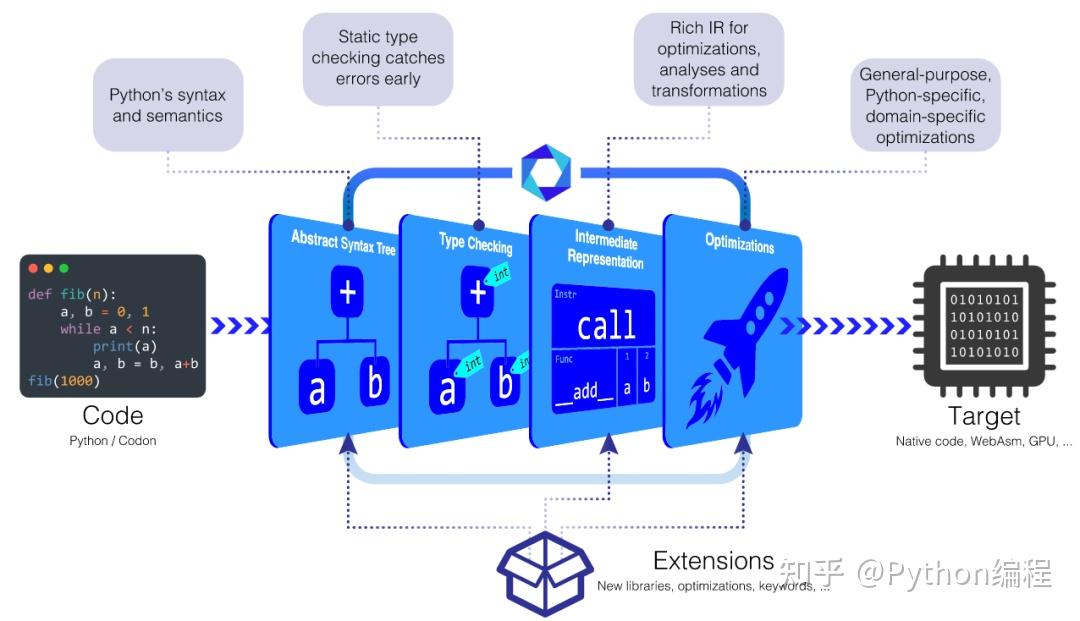
Codon Pipeline
一些基准测试结果。
基准测试
以下是来自 Codon 基准测试套件的结果,比较了 Python、PyPy、C++ 和 Codon 在一系列任务和应用程序上的表现。
基准测试在以下设置上运行:


Python、PyPy、Codon 的对比
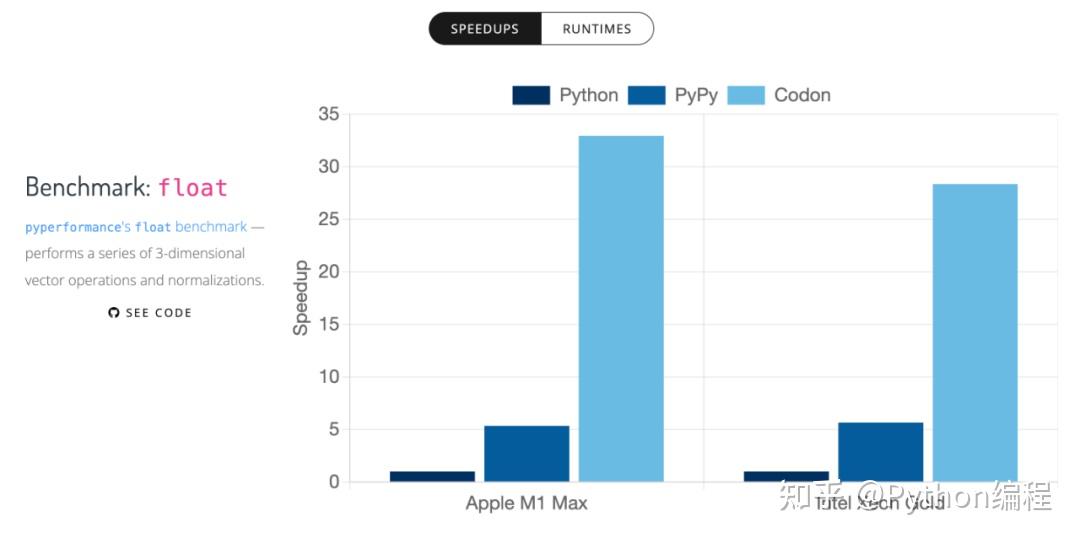



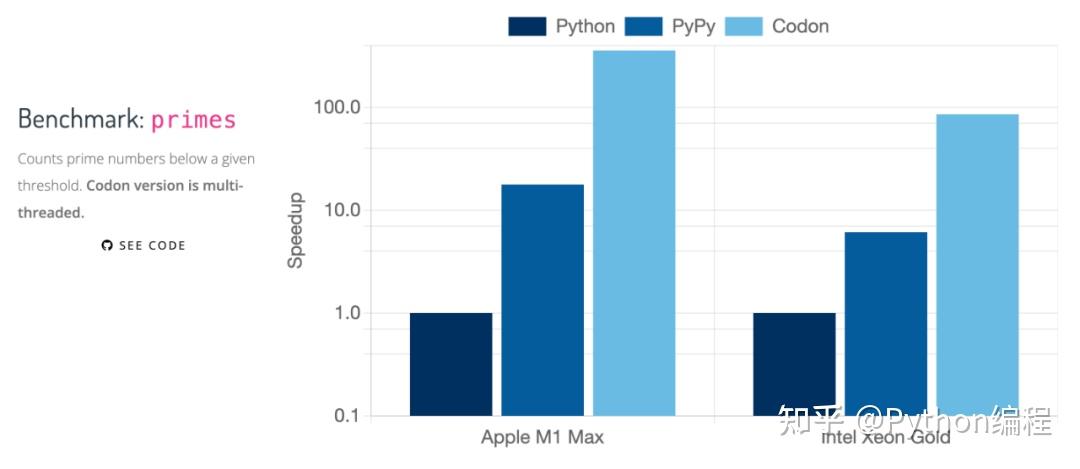
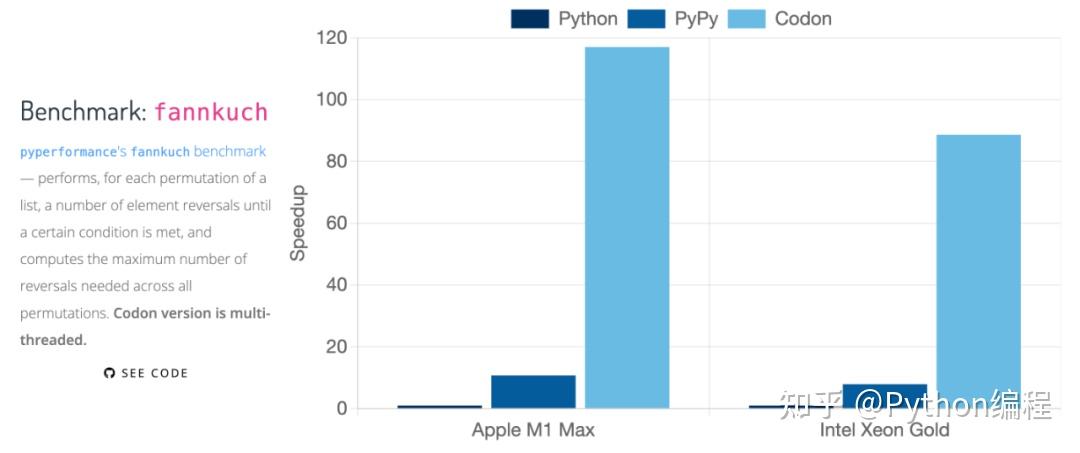

Python、PyPy、C++ 、Codon 的对比
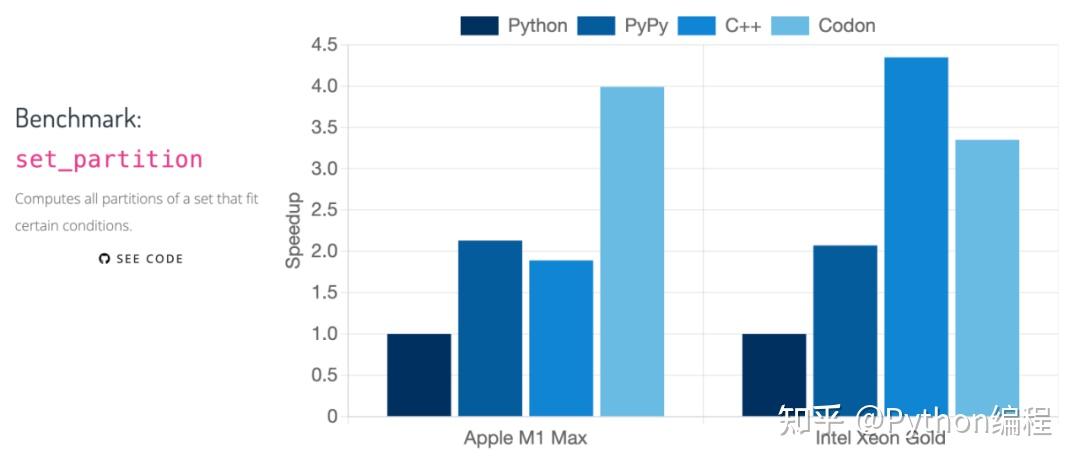

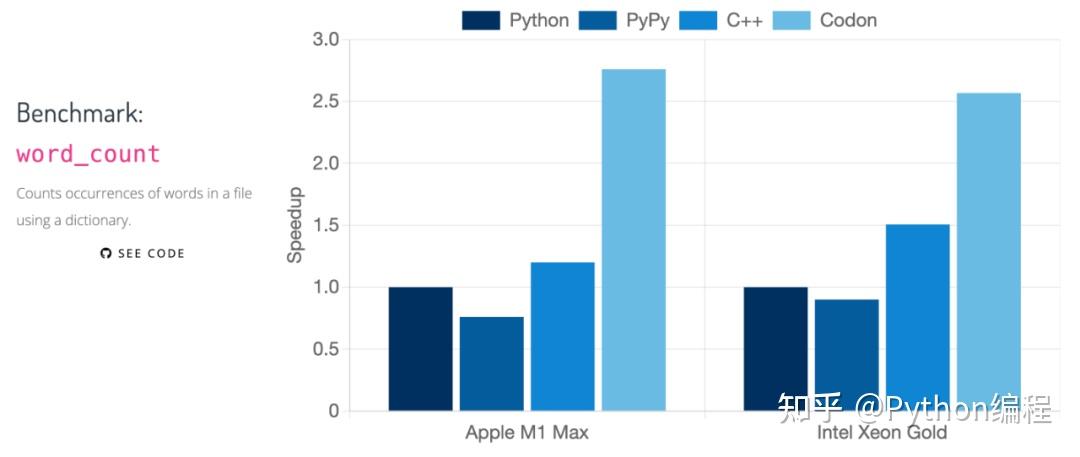

几种语言的具体对比如下:
Codon 尽可能地遵循 CPython 语法、语义和 API,但在一些特殊情况下,考虑性能原因,Codon 与 CPython 会有些不同,例如 Codon 为 64 位 int,CPython 是任意宽度 int。在性能方面,CPython 的加速通常是 10-100 倍的加速。
虽然 Codon 确实提供了一个类似于 Numba 的 JIT 装饰器,但 Codon 通常是一个提前(ahead-of-time)编译器,可以将端到端程序编译为本机代码。它还支持编译更广泛的 Python 构造和库集。
PyPy 的目标是成为 CPython 的简易替代品,而 Codon 在一些地方有所不同,这些不同主要体现在消除动态运行时或虚拟机上,从而获得更好的性能。
Codon 通常生成与等效的 C 或 C++ 程序相同的代码,有时可以生成比 C/C++ 编译器更好的代码。原因有很多,例如更好的容器实现,Codon 不使用目标文件和内联所有库代码,或者不使用 C 执行的特定于 Codon 的编译器优化或 C++。
Codon 的编译过程实际上更接近 C++ 而不是 Julia。Julia 是一种动态类型语言,它执行类型推断作为优化,而 Codon 类型是提前检查整个程序。Codon 还试图通过采用 Python 的语法和语义来规避新语言的学习曲线。
常见问题解答
虽然 Codon 几乎支持 Python 的所有语法,但它并不是一个简单的替代品,大型代码库可能需要修改才能通过 Codon 编译器运行。例如,一些 Python 的模块还没有在 Codon 中实现,一些 Python 的动态特性是不允许的。Codon 编译器会生成详细的错误消息,以帮助识别和解决任何不兼容问题。Codon 支持无缝的 Python 互操作性,以处理需要特定 Python 库或动态性的情况。
我想使用 Codon,但我有一个大型 Python 代码库且不想移植,怎么办?
你可以通过 @codon.jit 装饰器来使用 Codon,这将只编译带注释的函数,并自动处理与 Codon 之间的数据转换。它还允许使用任何特定于 Codon 的模块或扩展,例如多线程。
与其他语言和框架的互通性如何?
互通性是 Codon 的优先事项。我们不希望使用 Codon 使用户无法使用现有的其他优秀框架和库。Codon 支持与 Python 和 C/C++ 的完全互通。
Codon 是否使用垃圾收集?
是的,Codon 使用了 Boehm 垃圾收集器。
Codon 不支持 Python 模块 X 或函数 Y?
虽然 Codon 涵盖了 Python 标准库的一个相当大的子集,但它还没有涵盖每个模块的每个函数。请注意,仍然可以通过 Python 调用缺少的函数 from python import。许多缺少 Codon 本地实现的函数(例如 I/O 或 OS 相关功能)通常不会实现 Codon 的实质性加速。
对于我的应用程序,Codon 并不比 Python 快?
大部分时间用在 C 语言实现的库代码中的应用程序通常不会在 Codon 中看到实质性的性能提升。同样地,受 I/O 或网络限制的应用程序在 Codon 中也会遇到相同的瓶颈。
对于我的应用程序,Codon 比 Python 慢?
如果是这样,请将 Codon 明显比 Python 慢的情况报告给问题跟踪器。
Codon 是免费的吗?
对于非生产用途,Codon 始终是免费的。用户可以免费将 Codon 用于个人、学术或其他非商业应用。
Codon 是开源的吗?
Codon 是根据商业源代码许可证 (BSL) 获得许可的,它的源代码是公开可用的,并且可以免费用于非生产用途。BSL 在技术上不是「开源」许可证,尽管在许多情况下你仍然可以像对待任何其他开源项目一样对待 Codon。重要的是,根据 BSL,每个版本的 Codon 都会在 3 年后转换到实际的开源许可证(特别是 Apache)。
2、Python 调用其他语言的实现
使用 C/C++ 实现
当 Python 面临运算密集型任务时,其速度总是显得力不从心。要提升 Python 代码运行速度有多种方法,如 ctypes、cython、CFFI 等,本篇文章主要从 ctypes 方面介绍如何提升 Python 的运行速度 。ctypes 是 Python 的内置库,利用 ctypes 可以调用 C/C++ 编译成的 so 或 dll 文件 (so 存在 linux/MacOS 中,dll 存在于 windows) ,简单而言,就是将计算压力较大的逻辑利用 C/C++ 来实现,然后编译成 so 或 dll 文件,再利用 ctypes 加载进 Python,从而将计算压力大、耗时较长的逻辑交于 C/C++ 去执行。如 Numpy、Pandas 这些库其底层其实都是 C/C++ 来实现的 。
纯 Python 实现
为了对比出使用 ctypes 后程序运行速度的变化,先使用纯 Python 代码实现一段逻辑,然后再利用 C 语言去实现相同的逻辑 。这里为了模仿运算密集任务,实现一段逻辑用于计算一个集合中点与点之间的距离以及实现一个操作字符串的逻辑,具体代码如下:
import time
import random
import timeit# 点
class Point(object):def __init__(self, x, y):self.x = xself.y = yclass Test(object):def __init__(self, string, nb):self.string = stringself.points = []# 初始化点集合for i in range(nb):self.points.append(Point(random.random(), random.random()))self.distances = []# 增量字符串def increment_string(self, n):tmp = ""# 每个字符做一次偏移for c in self.string:tmp += chr(ord(c) + n)self.string = tmp# 这个函数计算列表中每个点之间的距离def distance_between_points(self):for i, a in enumerate(self.points):for b in self.points:# 距离公式self.distances.append(((b.x - a.x) ** 2 + (b.y - b.x) ** 2) ** 0.5)def main():test = Test("A nice sentence to test.", 10000)test.increment_string(-5) # 偏移字符串中的每个字符test.distance_between_points() # 计算集合中点与点之间的距离if __name__ == '__main__':cost_time = timeit.timeit(main, number=1)print(f'纯Python执行耗时: {cost_time}')
上述代码中,定义了 Point 类型,其中有两个属性,分别是 x 与 y,用于表示点在坐标系中的位置 ,然后定义了 Test 类,其中的 increment_string () 方法用于操作字符串,主要逻辑就是循环处理字符串中的每个字符,首先通过 ord () 方法将字符转为 unicode 数值,然后加上对应的偏移 n,接着在通过 chr () 方法将数值转换会对应的字符 。此外还实现了 distance_between_points () 方法,该方法的主要逻辑就是利用双层 for 循环,计算集合中每个点与其他点的距离。使用时,创建了 10000 个点进行程序运行时长的测试 。多次执行这份代码,其运行时间大约在 39.4 左右
使用 ctypes 提速度
要使用 ctypes,首先就要将耗时部分的逻辑通过 C 语言实现,并将其编译成 so 或 dll 文件,因为我使用的是 MacOS,所以这里会将其编译成 so 文件 ,先来看一下上述逻辑通过 C 语言实现的具体代码,如下:
#include<stdlib.h>
#include<math.h>// 点结构
typedef struct s_point
{double x;double y;
} t_point;typedef struct s_test
{char*sentence;// 句子int nb_points;t_point *points;// 点double*distances;// 两点距离,指针
} t_test;
// 增量字符串
char* increment_string(char* str, int n)
{for(int i =0; str[i]; i++)// 每个字符做一次偏移str[i]= str[i]+ n;return(str);
}
// 随机生成点集合
void generate_points(t_test *test,int nb)
{// calloc () 函数用来动态地分配内存空间并初始化为 0// 其实就是初始化变量,为其分配内存空间t_point *points = calloc(nb +1,sizeof(t_point));for(int i =0; i < nb; i++){points[i].x = rand();points[i].y = rand();}// 将结构地址赋值给指针test->points = points;test->nb_points = nb;
}
// 计算集合中点的距离
void distance_between_points(t_test *test)
{int nb = test->nb_points;// 创建变量空间double* distances = calloc(nb * nb +1,sizeof(double));for(int i =0; i < nb; i++)for(int j =0; j < nb; j++)// sqrt 计算平方根distances[i * nb + j]= sqrt((test->points[j].x - test->points[i].x)*(test->points[j].x - test->points[i].x)+(test->points[j].y - test->points[i].y)*(test->points[j].y - test->points[i].y));test->distances = distances;
}
其中具体的逻辑不再解释,可以看注释理解其中的细节,通过 C 语言实现后,接着就可以通过 gcc 来编译 C 语言源文件,将其编译成 so 文件 ,命令如下:
// 生成 .o 文件
gcc -c fastc.c
// 利用 .o 文件生成so文件
gcc -shared -fPIC -o fastc.so fastc.o
获得了 fastc.so 文件后,接着就可以利用 ctypes 将其调用并直接使用其中的方法了,需要注意的是「Windows 系统体系与 Linux/MacOS 不同,ctypes 使用方式会有差异」 ,至于 ctypes 的具体用法,后面会通过单独的文章进行讨论。ctypes 使用 fastc.so 的代码如下:
import ctypes
from ctypes import *
from ctypes.util import find_library
import time# 定义结构,继承自ctypes.Structure,与C语言中定义的结构对应
class Point(ctypes.Structure):_fields_ = [('x', ctypes.c_double),('y', ctypes.c_double)]class Test(ctypes.Structure):_fields_ = [('sentence', ctypes.c_char_p),('nb_points', ctypes.c_int),('points', ctypes.POINTER(Point)),('distances', ctypes.POINTER(c_double)),]# Lib C functions
_libc = ctypes.CDLL(find_library('c'))
_libc.free.argtypes = [ctypes.c_void_p]
_libc.free.restype = ctypes.c_void_p
# Lib shared functions
_libblog = ctypes.CDLL("./fastc.so")
_libblog.increment_string.argtypes = [ctypes.c_char_p, ctypes.c_int]
_libblog.increment_string.restype = ctypes.c_char_p
_libblog.generate_points.argtypes = [ctypes.POINTER(Test), ctypes.c_int]
_libblog.distance_between_points.argtypes = [ctypes.POINTER(Test)]if __name__ == '__main__':start_time = time.time()# 创建test = {}test['sentence'] = "A nice sentence to test.".encode('utf-8')test['nb_points'] = 0test['points'] = Nonetest['distances'] = Nonec_test = Test(**test)ptr_test = ctypes.pointer(c_test)# 调用so文件中的c语言方法_libblog.generate_points(ptr_test, 10000)ptr_test.contents.sentence = _libblog.increment_string(ptr_test.contents.sentence, -5)_libblog.distance_between_points(ptr_test)_libc.free(ptr_test.contents.points)_libc.free(ptr_test.contents.distances)print('ctypes run time: %s' % str(time.time() - start_time))
多次执行这份代码,其运行时间大约在 1.2 左右
python 2.py
ctypes run time:1.2614238262176514
相比于纯 Python 实现的代码快了 30 倍有余
有人可能会提及使用 asyncio 异步的方式来提升 Python 运行速度,但这种方式只能提高 Python 在 IO 密集型任务中的运行速度,对于运算密集型的任务效果并不理想。
Pybind11
Pybind11 是一个轻量级的仅头文件库,它在 Python 中暴露 C++ 类型,反之亦然,主要用于创建现有 C++ 代码的 Python 绑定,它的目标和语法类似于 Boost.Python,相对大而全的 Boost 更加轻量。可是使用 C++ 来编写 Python 包。
构建上可以参考官方的样例:https://github.com/pybind/python_example
#include <pybind11/pybind11.h>#define STRINGIFY(x) #x
#define MACRO_STRINGIFY(x) STRINGIFY(x)int add(int i, int j) {return i + j;
}namespace py = pybind11;PYBIND11_MODULE(python_example, m) {m.doc() = R"pbdoc(Pybind11 example plugin-----------------------.. currentmodule:: python_example.. autosummary:::toctree: _generateaddsubtract)pbdoc";m.def("add", &add, R"pbdoc(Add two numbersSome other explanation about the add function.)pbdoc");m.def("subtract", [](int i, int j) { return i - j; }, R"pbdoc(Subtract two numbersSome other explanation about the subtract function.)pbdoc");#ifdef VERSION_INFOm.attr("__version__") = MACRO_STRINGIFY(VERSION_INFO);
#elsem.attr("__version__") = "dev";
#endif
}使用 Rust 实现
PyO3
PyO3 是 Python 的 Rust 绑定,包括用于创建本地 Python 扩展模块的工具。还支持从 Rust 二进制文件运行 Python 代码并与之交互。相比 pybind11,受限于 C++,Rust 工具链相对更完善一点,打包上有 maturin 方案,体验更好。
使用 Java 实现
3、Numba
官网:https://numba.pydata.org/
官网文档:https://numba.readthedocs.io/en/stable/user/installing.html
一行代码让你的python运行速度提高100倍:https://zhuanlan.zhihu.com/p/45309190
JIT 是什么
jit 的全称是 Just-in-time,在 numba 里面则特指 Just-in-time compilation(即时编译),它是一种编译技术,下面的对比即可对 jit 进行清晰的定位
编译方式
- 动态编译(dynamic compilation):指的是“在运行时进行编译”;与之相对的是事前编译(ahead-of-time compilation,简称AOT),也叫静态编译(static compilation)
- JIT编译(just-in-time compilation)狭义来说是当某段代码即将第一次被执行时进行编译,因而叫“即时编译”。JIT编译是动态编译的一种特例。JIT编译一词后来被泛化,时常与动态编译等价;但要注意广义与狭义的JIT编译所指的区别
- 自适应动态编译(adaptive dynamic compilation)也是一种动态编译,但它通常执行的时机比JIT编译迟,先让程序“以某种式”先运行起来,收集一些信息之后再做动态编译。这样的编译可以更加优化。
注意事项
- 但是jit技术并不总是能够如预期的加速代码,甚至有可能降低代码效率,这于代码的结构有关,不过绝大多数情况还是能够有明显的效果的
- JIT 之于 Python:Python 啥都好,就是太“动态”了,导致去运行效率不高,jit之于python那简直是如虎添翼
Numba 是一个开源的 JIT 编译器,通过 装饰器,Numba 可以将带注释的 Python 和 NumPy 代码的子集转换为高效的机器码。( numba 它只能加速数值计算函数,只能在numpy 包基础上进行加速。否则就绕开吧。可以看看 ctypes 和 cython。推荐直接使用 C、C++开发,然后使用 ctypes 粘起来 ) 。numba 使用 LLVM 编译器架构将纯Python代码生成优化过的机器码,将面向数组和使用大量数学的python代码优化到与c,c++和Fortran类似的性能,而无需改变Python的解释器。
numba 所完成的工作就是:解析Python函数的ast语法树并加以改造,添加类型信息;
将带类型信息的ast语法树通过llvmpy动态地转换为机器码函数,然后再通过和ctypes类似的技术为机器码函数创建包装函数供Python调用。
安装 numba、快速入门
pypi ( 目前版本 0.58.1 ):https://pypi.org/project/numba/
安装:pip install numba
中文文档:https://www.kancloud.cn/apachecn/numba-doc-zh/1947346
5 分钟快速入门:https://numba.readthedocs.io/en/stable/user/5minguide.html
Numba 装饰器
Numba有很多装饰器,我们已经看到了@jit,但是还有:

如果希望 JIT 能针对所有类型的参数进行运算,可以使用 autojit
autoit 虽然可以根据参数类型动态地产生机器码函数,但是由于它需要每次检查参数类型,因此计算速度也有所降低。numba的用法很简单,基本上就是用jit和autojit这两个修饰器,和一些类型对象。下面的程序列出 numba 所支持的所有类型:
print(list(map(lambda x=None: print(x), dir(numba))))
print(list(map(lambda x=None: print(x), numba.__dict__.values())))
一些装饰器中可用的其他选项:

ctypes/cffi/cython 互操作性:

Numba 的使用
import timeit
import numba
from numba import jitdef func_1(x, y):s = 0for i in range(x, y):s += ireturn s@jit(nopython=True)
def func_2(x, y):s = 0for i in range(x, y):s += ireturn sdef main():# print(list(map(lambda x=None: print(x), dir(numba))))# print(list(map(lambda x=None: print(x), numba.__dict__.values())))cost_time = timeit.timeit(lambda x=None: func_1(1, 100000000), number=1)print(f'cost_time ---> {cost_time}')cost_time = timeit.timeit(lambda x=None: func_2(1, 100000000), number=1)print(f'cost_time ---> {cost_time}')if __name__ == '__main__':main()pass
执行结果:
cost_time ---> 2.8881187999941176
cost_time ---> 0.12966140000207815
4、Taichi
Taichi 是一种嵌在 Python 中的并行编程语言,使用 Python 语言作为 DSL,所以我们可以在正常的 Python 代码中使用它。它可以帮助我们轻松编写可移植的高性能并行程序,专注于高性能计算和图形领域。安装使用上和 Numba 类似。
安装:pip install taichi
import taichi as ti
import taichi.math as tmti.init(arch=ti.gpu)n = 320
pixels = ti.field(dtype=float, shape=(n * 2, n))@ti.func
def complex_sqr(z): # complex square of a 2D vectorreturn tm.vec2(z[0] * z[0] - z[1] * z[1], 2 * z[0] * z[1])@ti.kernel
def paint(t: float):for i, j in pixels: # Parallelized over all pixelsc = tm.vec2(-0.8, tm.cos(t) * 0.2)z = tm.vec2(i / n - 1, j / n - 0.5) * 2iterations = 0while z.norm() < 20 and iterations < 50:z = complex_sqr(z) + citerations += 1pixels[i, j] = 1 - iterations * 0.02gui = ti.GUI("Julia Set", res=(n * 2, n))for i in range(1000000):paint(i * 0.03)gui.set_image(pixels)gui.show()5、Nuitka
6、MatxScript
:https://github.com/bytedance/matxscript
字节开源的 MatxScript,是一个高性能可扩展的 Python 编译器,可以自动化把 Python 类或函数翻译成 C++,运行时完全没有 Python 开销。目前 Matx 主要支持机器学习相关的应用