文章目录
- 第一节、数据库调优的步骤
- 1.1、选择合适的DBMS
- 1.2、优化表设计
- 1.3、优化逻辑查询
- 1.4、优化物理查询
- 1.5、使用 Redis 或 Memcached 作为缓存
- 1.6、库级优化
- 第二节、优化MySQL服务器
- 第三节、优化数据库结构
第一节、数据库调优的步骤
1.1、选择合适的DBMS
- 如果对事务性处理以及安全性要求高的话,可以选择商业的数据库产品。这些数据库在事务处理和查询性能上都比较强,比如采用
SQL Server、Oracle,那么单表存储上亿条数据是没有问题的。如果数据表设计得好,即使不采用分库分表的方式,查询效率也不差。 - 除此以外,你也可以采用开源的
MySQL进行存储,它有很多存储引擎可以选择,如果进行事务处理的话可以选择lnnoDB,非事务处理可以选择MylSAM。 NoSQL阵营包括键值型数据库、文档型数据库、搜索引擎、列式存储和图形数据库。这些数据库的优缺点和使用场景各有不同,比如列式存储数据库可以大幅度降低系统的IO,适合于分布式文件系统,但如果数据需要频繁地增删改,那么列式存储就不太适用了。
1.2、优化表设计
1.3、优化逻辑查询
SQL查询优化,可以分为逻辑查询优化和物理查询优化。逻辑查询优化就是通过改变SQL语句的内容让SQL执行效率更高效,采用的方式是对SQL语句进行等价变换,对查询进行重写。
1.4、优化物理查询
物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等), 通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。在这个部分中,我们需要掌握的重点是对索弓|的创建和使用。
1.5、使用 Redis 或 Memcached 作为缓存
常用的键值存储数据库有 Redis 和 Memcached,它们都可以将数据存放到内存中。
1.6、库级优化
库级优化是站在数据库的维度上进行的优化策略,比如控制一个库中的数据表数量。另外,单一的数据库总会遇到各种限制,不如取长补短,利用"外援"的方式。通过主从架构优化我们的读写策略,通过对数据库进行垂直或者水平切分,突破单一数据库或数据表的访问限制, 提升查询的性能。
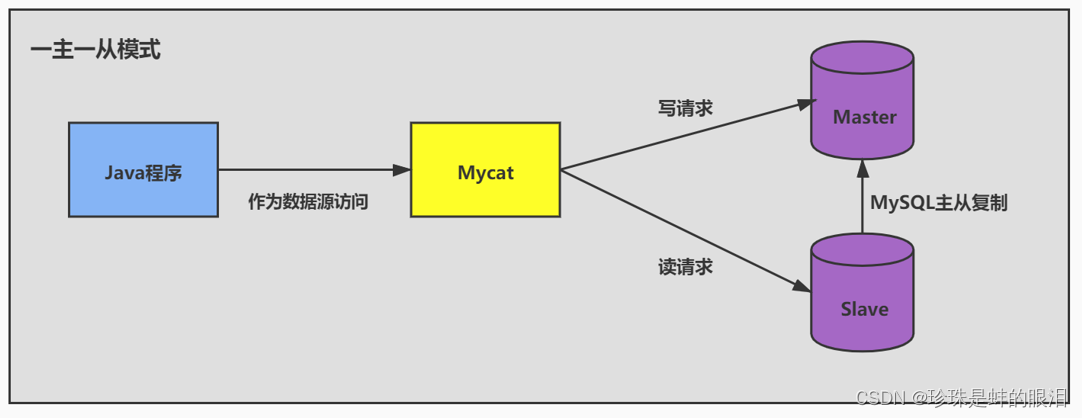
- 读写分离
如果读和写的业务量都很大,并且它们都在同一个数据库服务器中进行操作,那么数据库的性能就会出现瓶颈,这时为了提升系统的性能,优化用户体验,我们可以采用读写分离的方式降低主数据库的负载,比如用主数据库(master)完成写操作,用从数据库(slave) 完成读操作。
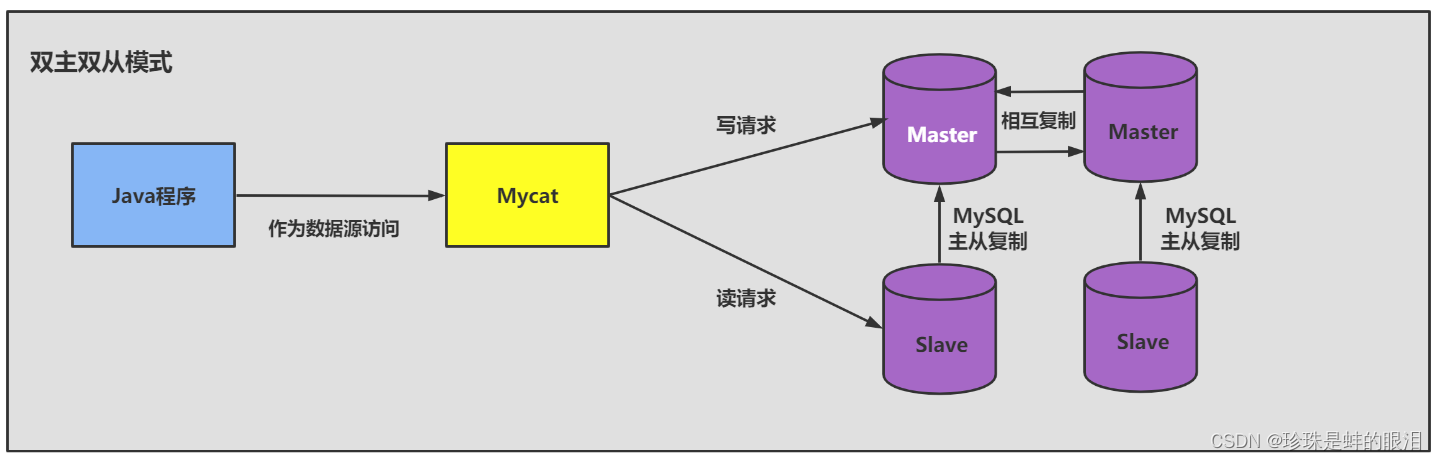
- 数据分片
对数据库分库分表。当数据量级达到千万级以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力。如果你使用的是MySQL,就可以使用MySQL自带的分区表功能,当然你也可以考虑自己做垂直拆分(分库)、水平拆分 (分表)、垂直+水平拆分 (分库分表)。
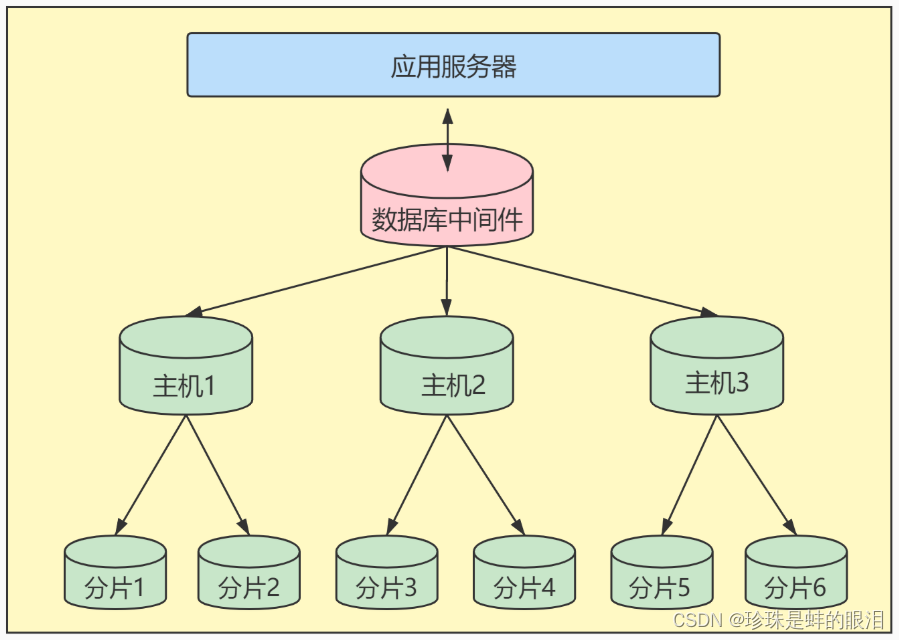
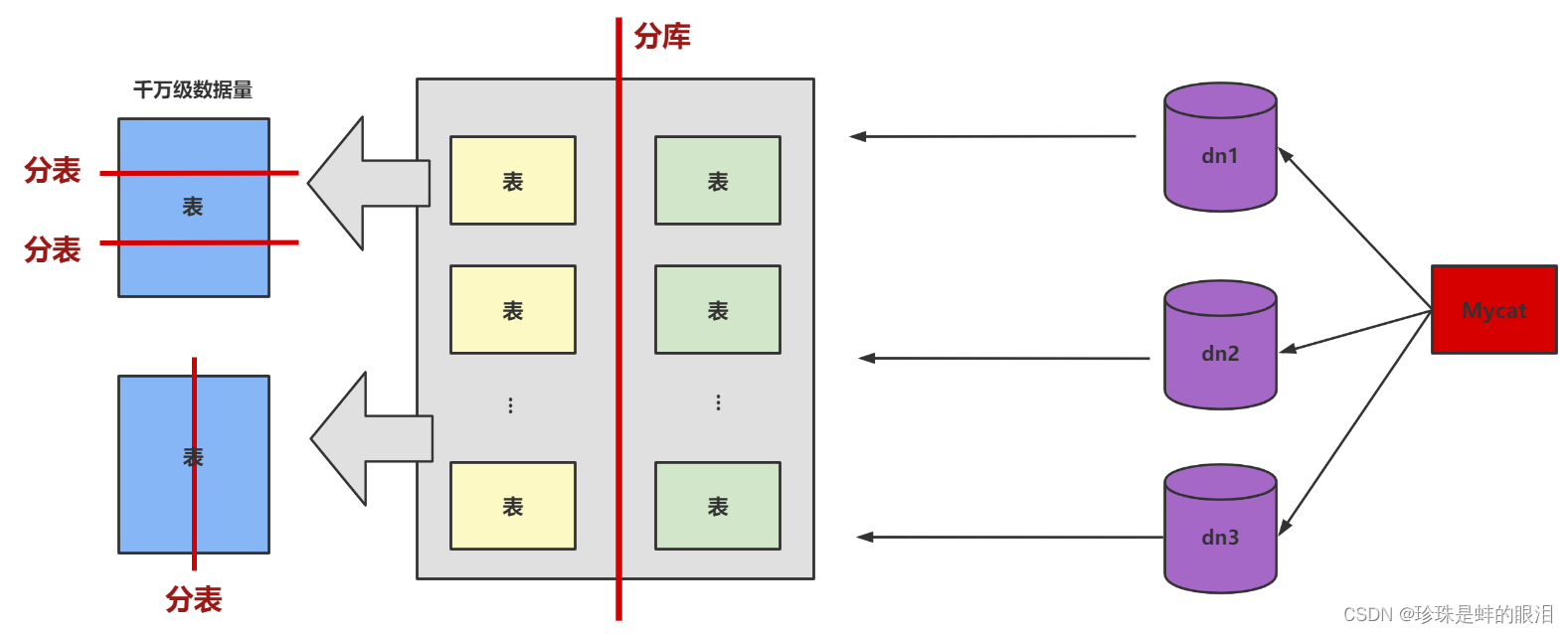
但需要注意的是,分拆在提升数据库性能的同时,也会增加维护和使用成本。
第二节、优化MySQL服务器
优化MySQL服务器主要从两个方面来优化,一方面是对 硬件进行优化;另一方面是对MySQL 服务的参数进行优化。这部分的内容需要较全面的知识,一般只有专业的数据库管理员才能进行这一类的优化。 对于可以定制参数的操作系统,也可以针对MySQL进行操作系统优化。
- 优化MySQL参数这里,需要在配置文件中设置参数值,目前在公司里不需要开发人员做,所以以后用到再来学习。