哈希函数
hashmap是开发中常用的一个集合,除了一些基本的属性、put、get等流程,本篇文章主要介绍下哈希函数、扩容、树化的一些细节。
而hash函数就是hashmap的重中之重。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}int index = hash(key) & (n - 1)
从上述的code中,可以看出hash的整体流程,就是获取key的hashcode值给h,然后h 进行右移 16位,在进行异或操作(相同为0,不同为1),因为计算的hashcode值比较大,所以需要在对 数组(n-1) 进行取对应的下表,取模操作比较耗时,所以才使用位运算。

为什么不直接使用 hashcode直接返回?
那么既然key的hashcode是一个随机数,为什么不直接返回呢,而是要进行 异或操作 h ^ (h >>> 16) ,因为一般来说hashmap的长度不会很长,如果直接返回,高位其实没有参与到运算中,会导致计算出的不够均匀。
**为什么 h& (n - 1) **
hashmap中table数组的大小是2的幂次方。比如 2^4 减1之后 其实就是 1111 跟h& 相当于求模运算。
扩容机制
当我们存储数据的使用,一般除非特别指定会设置一定的容量,否则,当添加的元素超过一定的阈值就会进行扩容,有扩容就对应有缩容。
装载因子
具体扩容是根据table数组的大小和 装载因子决定的, 当元素个数超过 n * loadFactor 就会触发扩容。
lodFactory 默认是0.75 ,table数组默认大小是16。当元素超过12之后就会触发扩容。
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
/*** Returns a power of two size for the given target capacity.*/static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
从上述的源码中,可以看到其实在设置指定长度的时候,其实就按照2的次幂进行分配。如果不是的化,那么tableSizeFor就会转换比initialCapacity大的第一个2的幂次方数。
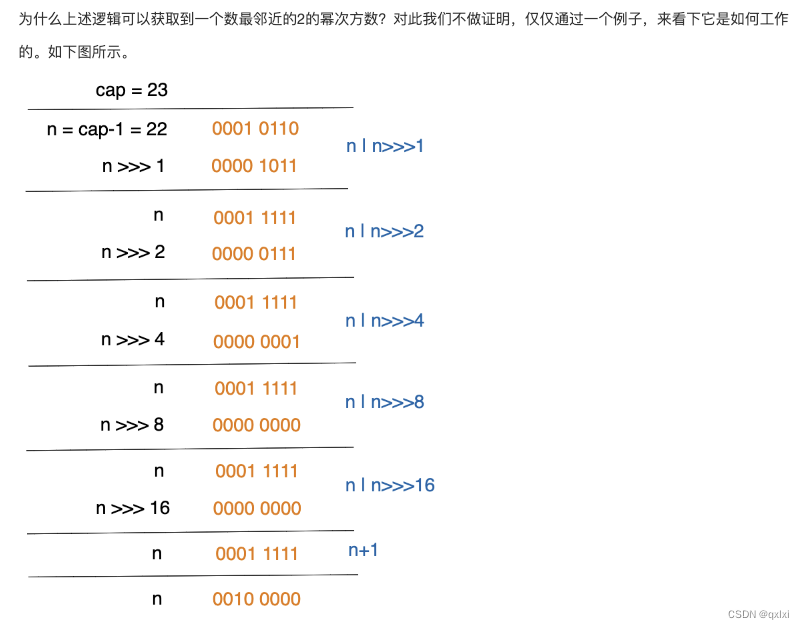
this.threshold = tableSizeFor(initialCapacity);
细心的同学可能发现了,这个计算之后的容量是直接赋值给了threshold。而这个tableSizeFor(initialCapacity); 是数组的大小,threshold是触发扩容的阈值。
那是因为new hashMap的时候,并没有开始创建table数组,而是在put元素的时候,才会进行初始化。

默认装载因子
对于装载因子 为什么设置为0.75,可能有的面试官就纠结于此,询问这个问题,但是我们最好还是了解一下。
结论就是 0.75是结合时间和空间综合考虑的结果。过大,执行效率低。过小。浪费空间。
链表树化阈值
链表树化的阈值为什么是8,其实是根据泊松分布来计算的概率问题。