文章目录
- 一、链表
- 1.1 链表的概念
- 1.2 链表的结构
- 二、LinkedList的简介
- 三、LinkedList的使用
- 3.1 构造方法
- 3.2 常见操作
- 3.3 遍历方法
- 四、LinkedList的模拟实现
- 五、LinkedList 和 ArrayList 的区别
一、链表
1.1 链表的概念
链表(Linked List)是一种常见的数据结构,用于存储和组织数据。它由一系列节点(Node)组成,每个节点包含两个主要部分:数据域(Data)和指针域(Pointer)。
数据域存储节点所需的数据或信息,可以是任意类型的数据,如整数、字符、对象等。指针域则指向链表中的下一个节点,将节点连接起来形成链表结构。
链表中的节点并不一定按照物理上的连续位置存储,而是通过指针域相互连接。这使得链表能够灵活地插入、删除和修改节点,而无需像数组那样进行元素的移动。
链表的优点是可以高效地插入和删除节点,而无需移动其他节点。然而,由于链表中的节点不是连续存储的,访问特定位置的节点需要从头部开始遍历,因此随机访问的效率较低。
1.2 链表的结构
在实际的应用场景中,链表的结构非常多样,以下是常见的链表结构:
- 单项链表
单向链表(Singly Linked List)是一种基本的链表结构,每个节点包含两个主要部分:数据域和指针域。以下是单向链表的结构示意图:

-
在单向链表中,每个节点包含一个数据域,用于存储节点所需的数据,以及一个指针域,指向链表中的下一个节点。最后一个节点的指针域通常指向空值(NULL),表示链表的结束。
-
通过这种方式,节点之间通过指针链接在一起,形成一个链表结构。链表的头部节点通过外部引用进行访问,然后可以依次遍历访问链表中的每个节点。
-
由于单向链表只有一个方向的指针,所以只能从头部节点开始顺序遍历访问,无法直接访问后续节点,也无法在常量时间内进行反向遍历。
-
单向链表在插入和删除节点时具有较好的性能,因为只需要修改节点的指针,而不需要移动其他节点。然而,在访问特定位置的节点时,需要从头部节点开始遍历整个链表,导致访问效率较低。
- 双向链表
双向链表(Doubly Linked List)的每个节点包含两个指针,分别指向前一个节点和后一个节点。这使得节点可以在两个方向上进行遍历和访问,提供了更多的灵活性和功能。
以下是双向链表的结构示意图:

-
在双向链表中,每个节点包含一个数据域和两个指针域。除了指向下一个节点的指针域(Next Pointer),还有一个指向前一个节点的指针域(Prev Pointer)。头部节点的 Prev Pointer 通常指向空值(NULL),尾部节点的 Next Pointer 也指向空值。
-
通过 Prev Pointer 和 Next Pointer,双向链表允许在链表的两个方向上遍历和访问节点。这使得在某些情况下,例如在链表末尾插入或删除节点,可以更高效地操作链表。
-
与单向链表相比,双向链表的操作稍微复杂一些,因为每个节点需要维护两个指针。但双向链表提供了更多的功能和灵活性,如可以从头部或尾部快速插入或删除节点,以及可以在两个方向上进行遍历和搜索。
- 带头节点的链表
带头结点的链表在头部添加了一个额外的节点作为头结点(Header Node)或哑节点(Dummy Node),这个头结点不存储任何实际的数据。
以下是带头结点的链表的结构示意图:

-
头结点位于链表的起始位置,其主要作用是方便链表的操作和管理。它不存储实际的数据,只包含一个指针域,指向链表中的第一个实际节点。
-
带头结点的链表的优点在于简化了链表的操作。它确保链表中始终存在一个非空节点,简化了插入、删除和遍历等操作的实现。此外,头结点可以用于存储链表的一些统计信息或提供其他便利的功能。
-
在带头结点的链表中,链表的第一个实际节点为头结点的下一个节点。通过头结点,可以轻松地访问链表中的实际数据节点,并进行相应的操作。
-
当遍历带头结点的链表时,通常从头结点的下一个节点开始,直到遇到指针域为 NULL 的节点,表示链表结束。
- 循环链表
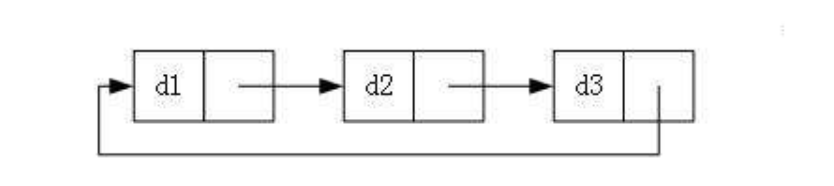
循环链表(Circular Linked List)是一种特殊的链表结构,其中最后一个节点的指针指向链表的头部节点,形成一个闭环。
以下是循环链表的结构示意图:
-
在循环链表中,每个节点仍然包含数据域和指针域,但最后一个节点的指针域不再指向空值(NULL),而是指向链表的头部节点。
-
这样的设计使得链表形成一个循环结构,可以通过任何节点开始遍历整个链表。从任何节点出发,通过指针的循环跳转,可以访问链表中的所有节点。
-
循环链表的优点在于在遍历和操作链表时,不需要考虑链表的结束位置。无论从哪个节点开始遍历,总能回到起始位置,避免了在常规链表中遇到的空指针异常。
二、LinkedList的简介
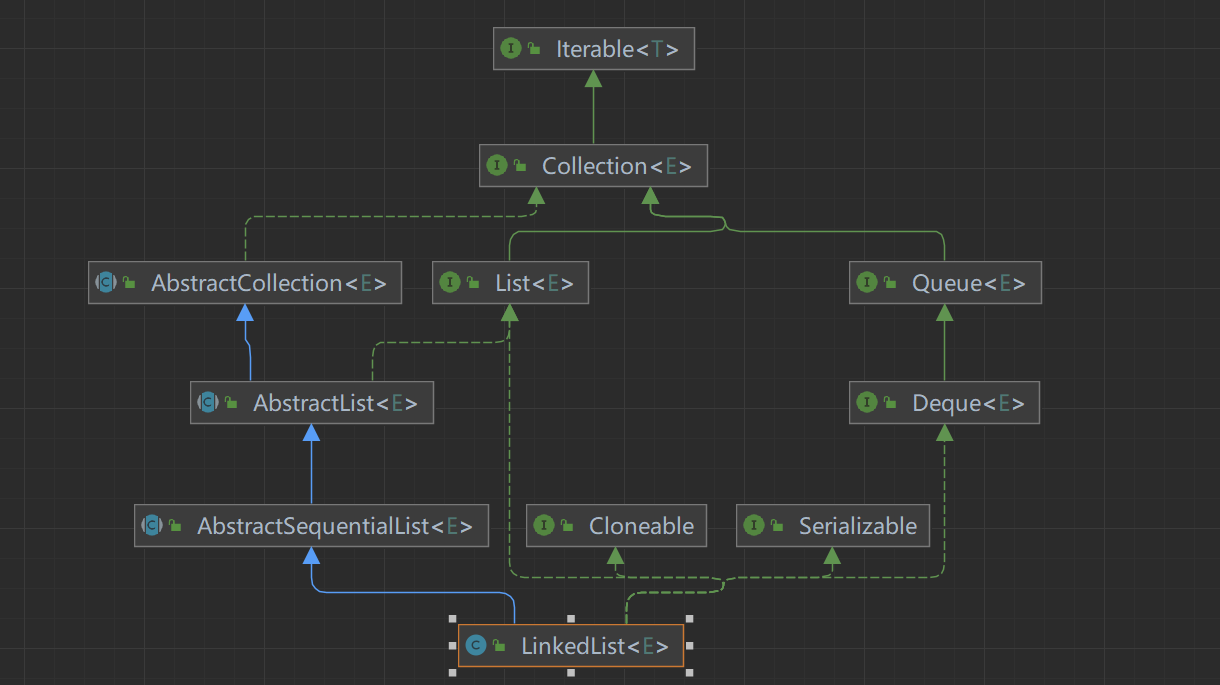
在Java中,LinkedList(链表)是Java集合框架提供的一个实现了List接口的类。它是基于双向链表结构实现的,可以用于存储和操作元素的有序集合。
继承体系结构如下:
三、LinkedList的使用
3.1 构造方法
LinkedList类提供了以下几种构造方法:
- LinkedList():创建一个空的LinkedList对象。
LinkedList<String> list = new LinkedList<>();
- LinkedList(Collection<? extends E> c):创建一个包含指定集合中的元素的LinkedList对象。集合中的元素将按照迭代器返回的顺序添加到LinkedList中。
List<String> collection = new ArrayList<>();
collection.add("Element 1");
collection.add("Element 2");
LinkedList<String> list = new LinkedList<>(collection);
- LinkedList(LinkedList<? extends E> c):创建一个包含指定LinkedList中的元素的LinkedList对象。指定LinkedList中的元素将按照迭代器返回的顺序添加到新的LinkedList中。
LinkedList<String> originalList = new LinkedList<>();
originalList.add("Element 1");
originalList.add("Element 2");
LinkedList<String> newList = new LinkedList<>(originalList);
3.2 常见操作
LinkedList类提供了许多用于操作链表的方法。以下是一些常见的操作方法:
- 添加元素:
add(E element):在链表末尾添加一个元素。addFirst(E element):在链表开头添加一个元素。addLast(E element):在链表末尾添加一个元素。
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.addFirst("Element 0");
list.addLast("Element 2");
- 获取元素:
get(int index):获取指定位置的元素。getFirst():获取链表的第一个元素。getLast():获取链表的最后一个元素。
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");
String element = list.get(0);
String firstElement = list.getFirst();
String lastElement = list.getLast();
- 删除元素:
remove(int index):删除指定位置的元素。removeFirst():删除链表的第一个元素。removeLast():删除链表的最后一个元素。
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");
list.remove(0);
list.removeFirst();
list.removeLast();
- 判断元素是否存在:
contains(Object element):检查链表是否包含指定元素。
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");
boolean containsElement = list.contains("Element 1");
- 获取链表大小和清空链表:
size():获取链表中元素的个数。isEmpty():检查链表是否为空。clear():清空链表中的所有元素。
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");
int size = list.size();
boolean isEmpty = list.isEmpty();
list.clear();
3.3 遍历方法
在LinkedList中,可以使用不同的方式进行遍历操作。下面是几种常见的遍历方法:
- 使用for循环和get方法遍历:
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");for (int i = 0; i < list.size(); i++) {String element = list.get(i);// 处理当前元素System.out.println(element);
}
- 使用增强型for循环遍历:
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");for (String element : list) {// 处理当前元素System.out.println(element);
}
- 使用迭代器(Iterator)遍历:
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {String element = iterator.next();// 处理当前元素System.out.println(element);
}
- 使用Java 8+的Stream API进行遍历:
LinkedList<String> list = new LinkedList<>();
list.add("Element 1");
list.add("Element 2");list.stream().forEach(element -> {// 处理当前元素System.out.println(element);
});
四、LinkedList的模拟实现
import java.util.Stack;public class MyLinkList {static class ListNode {public int val;public ListNode prev;public ListNode next;public ListNode(int val) {this.val = val;}}private ListNode head; // 标记双向链表的头部private ListNode tail; // 标记双向链表的尾部// 头插public void addFirst(int data) {if (this.head == null) {this.head = new ListNode(data);this.tail = this.head;} else {ListNode node = new ListNode(data);node.next = this.head;this.head.prev = node;this.head = node;}}//尾插public void addLast(int data) {if (this.tail == null) {this.tail = new ListNode(data);this.head = this.tail;} else {ListNode node = new ListNode(data);this.tail.next = node;node.prev = this.tail;this.tail = node;}}//任意位置插入,第一个数据节点为0号下标public boolean addIndex(int index, int data) {if (index < 0 || index > size()) {System.out.println("index位置不合法!");return false;}if (index == 0) {addFirst(data);} else if (index == size()) {addLast(data);} else {ListNode cur = head;while (index != 0) {cur = cur.next;index--;}ListNode node = new ListNode(data);ListNode prev = cur.prev;cur.prev = node;node.next = cur;prev.next = node;node.prev = prev;}return true;}//查找是否包含关键字key是否在单链表当中public boolean contains(int key) {ListNode cur = head;while (cur != null) {if (cur.val == key) {return true;}cur = cur.next;}return false;}//删除第一次出现关键字为key的节点public void remove(int key) {// 链表为空if (head == null) {return;} else if (head.val == key) {// 要删除的元素在头head = head.next;if (head == null)return;head.prev = null;} else if (tail.val == key) {// 要删除的元素在尾tail = tail.prev;tail.next = null;} else {// 正常情况ListNode cur = head;// 注意考虑只有一个元素的情况while (cur.next != null && cur != tail) {if (cur.val == key) {cur.prev.next = cur.next;cur.next.prev = cur.prev;return;}cur = cur.next;}}}//删除所有值为key的节点public void removeAllKey(int key) {// 空链表if (null == head) {return;}// 从头开始,出现连续的keywhile (head.val == key) {head = head.next;if (head == null) {return;}head.prev = null;}// 从尾开始出现连续的keywhile (tail.val == key) {tail = tail.prev;if (tail == null)return;tail.next = null;}// 其他情况,注意只有一个元素的情况ListNode cur = head;while (cur.next != null && cur != tail) {if (cur.val == key) {cur.prev.next = cur.next;cur.next.prev = cur.prev;}cur = cur.next;}}//得到单链表的长度public int size() {int cnt = 0;ListNode cur = head;while (cur != null) {cnt++;cur = cur.next;}return cnt;}public void display() {ListNode cur = head;while (cur != null) {System.out.print(cur.val + " ");cur = cur.next;}System.out.println();}private void _display2(ListNode node) {if (node == null) {return;}if (node.next == null) {System.out.print(node.val + " ");return;}_display2(node.next);System.out.print(node.val + " ");}// 递归逆序打印链表public void display2() {ListNode node = this.head;_display2(node);System.out.println();}public void _display3(ListNode node) {if (node == null)return;Stack<ListNode> stack = new Stack<>();while (node != null) {stack.push(node);node = node.next;}while (!stack.isEmpty()) {System.out.print(stack.pop().val + " ");}System.out.println();}// 利用栈逆序打印链表public void display3() {ListNode node = this.head;_display3(node);}public void clear() {ListNode cur = head;while (cur != null) {ListNode curNext = cur.next;cur.val = 0;cur.prev = null;cur.next = null;cur = curNext;}this.head = this.tail = null;}
}五、LinkedList 和 ArrayList 的区别
LinkedList和ArrayList是Java集合框架中的两种不同的List实现,它们有以下几个区别:
-
底层数据结构:LinkedList底层基于链表实现,而ArrayList底层基于动态数组实现。
-
插入和删除操作:由于LinkedList是基于链表的数据结构,插入和删除元素的操作比较高效,时间复杂度为O(1),因为只需要调整节点的指针。而ArrayList的底层是动态数组,插入和删除操作需要移动其他元素,时间复杂度为O(n),其中n是元素的数量。
-
随机访问:ArrayList支持高效的随机访问,可以通过索引快速获取元素,时间复杂度为O(1)。而LinkedList需要从头开始遍历链表才能找到指定位置的元素,时间复杂度为O(n),其中n是索引位置。
-
内存消耗:由于LinkedList需要额外的指针来维护节点之间的连接关系,因此在存储相同数量的元素时,LinkedList通常会占用更多的内存空间。而ArrayList只需要连续的内存空间来存储元素。
-
迭代器性能:对于迭代器遍历操作,LinkedList的性能较好,因为只需要遍历链表中的节点即可。而ArrayList在使用迭代器遍历时,由于底层是数组,可能会导致性能稍差。
总而言之,当需要频繁进行插入和删除操作,而对于随机访问的需求较少时,LinkedList可能是更好的选择。而当需要频繁进行随机访问,而插入和删除操作较少时,ArrayList更为适合。