基于WIN10的64位系统演示
一、写在前面
本期,我们继续学习深度学习图像分割系列的另一个模型,PSPNet。
二、PSPNet简介
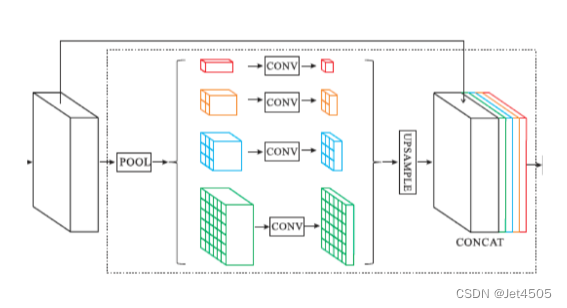
(1)金字塔池化模块 (Pyramid Pooling Module)
PSPNet的核心是其金字塔池化模块,该模块能够捕捉图像的不同区域上下文。这是通过在多个不同的尺度上对特征进行池化并使用1x1卷积来实现的。然后,这些不同尺度的特征图被上采样到原始尺度并与原始特征图一起串联。
(2)使用深层骨干网络
为了获取丰富的特征表示,PSPNet使用深层网络(如ResNet)作为其骨干网络。这为模型提供了强大的特征提取能力。
(3)辅助损失
为了在深网络中稳定训练,PSPNet引入了辅助损失。这通常在网络的中间层添加,帮助梯度更好地流经网络。
三、数据源
来源于公共数据,主要目的是使用PSPNet分割出电子显微镜下的细胞边缘:
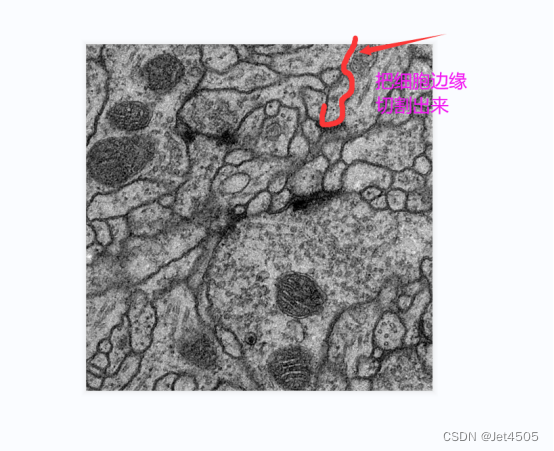
数据分为训练集(train)、训练集的细胞边缘数据(label)以及验证集(test),注意哈,没有提供验证集的细胞边缘数据。因此,后面是算不出验证集的性能参数的。




四、PSPNet实战:
这里,由于Pytorch并没有PSPNet预训练模型,因此只能从头搭建咯。
上代码:
(a)数据读取和数据增强
import os
import numpy as np
from skimage.io import imread
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_score# 设置文件路径
data_folder = 'U-net-master\data_set'
train_images_folder = os.path.join(data_folder, 'train')
label_images_folder = os.path.join(data_folder, 'label')
test_images_folder = os.path.join(data_folder, 'test')train_images = sorted(os.listdir(train_images_folder))
label_images = sorted(os.listdir(label_images_folder))
test_images = sorted(os.listdir(test_images_folder))# 定义数据集类
class CustomDataset(Dataset):def __init__(self, image_paths, mask_paths, transform=None):self.image_paths = image_pathsself.mask_paths = mask_pathsself.transform = transformdef __len__(self):return len(self.image_paths)def __getitem__(self, idx):image = imread(self.image_paths[idx])mask = imread(self.mask_paths[idx])mask[mask == 255] = 1# Ensure the image has 3 channelsif len(image.shape) == 2:image = np.stack((image,) * 3, axis=-1) sample = {'image': image, 'mask': mask}if self.transform:sample = self.transform(sample)return sampleclass ToTensorAndNormalize(object):def __init__(self, mean, std):self.mean = meanself.std = stddef __call__(self, sample):image, mask = sample['image'], sample['mask']# Swap color axis# numpy image: H x W x C# torch image: C x H x Wimage = image.transpose((2, 0, 1))image = torch.from_numpy(image).float()mask = torch.from_numpy(mask).float()# Normalize the imagefor t, m, s in zip(image, self.mean, self.std):t.sub_(m).div_(s)return {'image': image, 'mask': mask}# Use the new transform for normalization
transform = ToTensorAndNormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])# 获取数据集
train_dataset = CustomDataset(image_paths=[os.path.join(train_images_folder, img) for img in train_images],mask_paths=[os.path.join(label_images_folder, img) for img in label_images],transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)解读:
其他没什么好说的,就是要注意:上述代码的数据需要人工的安排训练集和测试集。严格按照下面格式放置好各个文件,包括文件夹的命名也不要变动:

(b)PSPNet建模
# 获取PSPNet模型
class PSPNet(nn.Module):def __init__(self, input_channels, output_channels):super(PSPNet, self).__init__()# Encoder (Feature extraction)self.enc = nn.Sequential(nn.Conv2d(input_channels, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(2))# Pyramid Pooling Moduleself.ppm = nn.ModuleList([nn.AdaptiveAvgPool2d(output_size=(1, 1)),nn.AdaptiveAvgPool2d(output_size=(2, 2)),nn.AdaptiveAvgPool2d(output_size=(3, 3)),nn.AdaptiveAvgPool2d(output_size=(6, 6))])self.ppm_conv = nn.ModuleList([nn.Conv2d(64, 64, kernel_size=1),nn.Conv2d(64, 64, kernel_size=1),nn.Conv2d(64, 64, kernel_size=1),nn.Conv2d(64, 64, kernel_size=1)])# Decoderself.decoder = nn.Sequential(nn.Conv2d(320, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.ConvTranspose2d(128, output_channels, kernel_size=3, stride=2, padding=1, output_padding=1))def forward(self, x):x = self.enc(x)ppm_out = [x]for pool, conv in zip(self.ppm, self.ppm_conv):ppm_out.append(F.interpolate(conv(pool(x)), size=x.size()[2:], mode='bilinear', align_corners=True))x = torch.cat(ppm_out, dim=1)return self.decoder(x)# 获取SegNet模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = PSPNet(input_channels=3, output_channels=2).to(device)optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = torch.nn.CrossEntropyLoss()def calc_iou(pred, target):# Convert prediction to boolean values and flattenpred = (pred > 0.5).view(-1)target = target.view(-1)# Calculate intersection and unionintersection = torch.sum(pred & target)union = torch.sum(pred | target)# Avoid division by zeroiou = (intersection + 1e-8) / (union + 1e-8)return iou.item()# 初始化损失和IoU的历史记录列表
losses_history = []
ious_history = []# 训练模型
epochs = 100
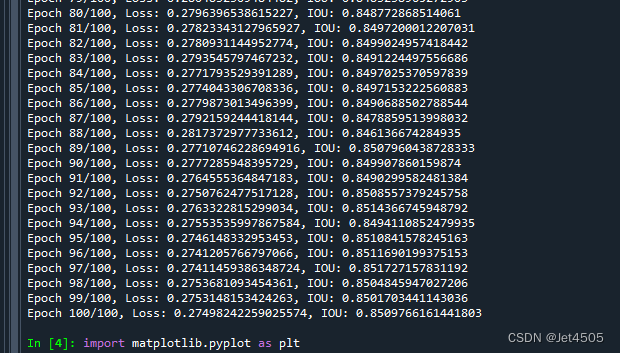
for epoch in range(epochs):model.train()running_loss = 0.0total_iou = 0.0for samples in train_loader:images = samples['image'].to(device)masks = samples['mask'].long().to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, masks)loss.backward()optimizer.step()running_loss += loss.item()# Calculate IOUpred_masks = F.softmax(outputs, dim=1)[:, 1]total_iou += calc_iou(pred_masks, masks)avg_loss = running_loss / len(train_loader)avg_iou = total_iou / len(train_loader)print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss}, IOU: {avg_iou}")# Append to historylosses_history.append(avg_loss)ious_history.append(avg_iou)迭代的深度比之前的模型要慢:
(c)各种性能指标打印和可视化
###################################误差曲线#######################################import matplotlib.pyplot as plt# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制训练损失和IoU
plt.figure(figsize=(12, 5))# 绘制损失
plt.subplot(1, 2, 1)
plt.plot(losses_history, label='训练损失')
plt.title('损失随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.legend()# 绘制IoU
plt.subplot(1, 2, 2)
plt.plot(ious_history, label='训练IoU')
plt.title('IoU随迭代次数的变化')
plt.xlabel('迭代次数')
plt.ylabel('IoU')
plt.legend()plt.tight_layout()
plt.show()直接看结果:
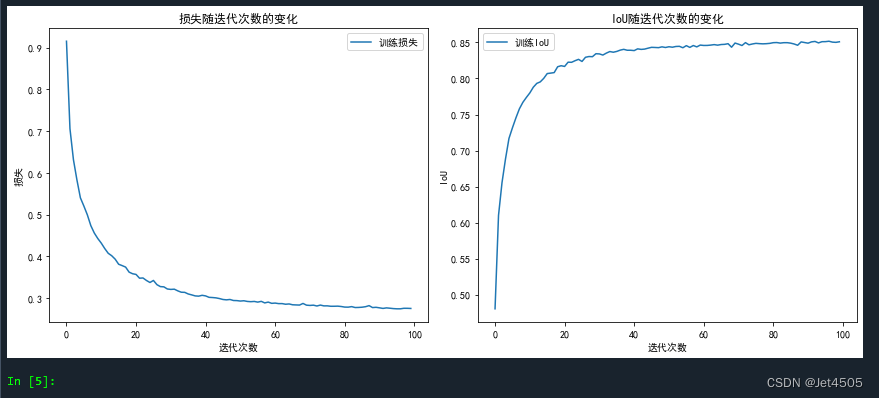
误差和IOU曲线,看起来模型收敛不如之前的模型,100次迭代没有达到90%。
##############################评价指标,对于某一个样本#######################################
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_scoredef calc_iou(y_true, y_pred):intersection = np.logical_and(y_true, y_pred)union = np.logical_or(y_true, y_pred)return np.sum(intersection) / np.sum(union)# 从数据集中获取一个样本
sample = train_dataset[0]
sample_img = sample['image'].unsqueeze(0).to(device)
sample_mask = sample['mask'].cpu().numpy()# 使用模型进行预测
with torch.no_grad():model.eval()prediction = model(sample_img)['out']# 取前景类并转为CPU
predicted_mask = prediction[0, 1].cpu().numpy()
predicted_mask = (predicted_mask > 0.5).astype(np.uint8)# 计算ROC曲线
fpr_train, tpr_train, _ = roc_curve(sample_mask.ravel(), predicted_mask.ravel())# 计算AUC
auc_train = auc(fpr_train, tpr_train)# 计算其他评估指标
pixel_accuracy_train = accuracy_score(sample_mask.ravel(), predicted_mask.ravel())
iou_train = calc_iou(sample_mask, predicted_mask)
accuracy_train = accuracy_score(sample_mask.ravel(), predicted_mask.ravel())
recall_train = recall_score(sample_mask.ravel(), predicted_mask.ravel())
precision_train = precision_score(sample_mask.ravel(), predicted_mask.ravel())
f1_train = f1_score(sample_mask.ravel(), predicted_mask.ravel())# 绘制ROC曲线
plt.figure()
plt.plot(fpr_train, tpr_train, color='blue', lw=2, label='Train ROC curve (area = %0.2f)' % auc_train)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()# 定义指标列表
metrics = [("Pixel Accuracy", pixel_accuracy_train),("IoU", iou_train),("Accuracy", accuracy_train),("Recall", recall_train),("Precision", precision_train),("F1 Score", f1_train)
]# 打印表格的头部
print("+-----------------+------------+")
print("| Metric | Value |")
print("+-----------------+------------+")# 打印每个指标的值
for metric_name, metric_value in metrics:print(f"| {metric_name:15} | {metric_value:.6f} |")
print("+-----------------+------------+")注意哈,这个代码只是针对某一个样本的结果:
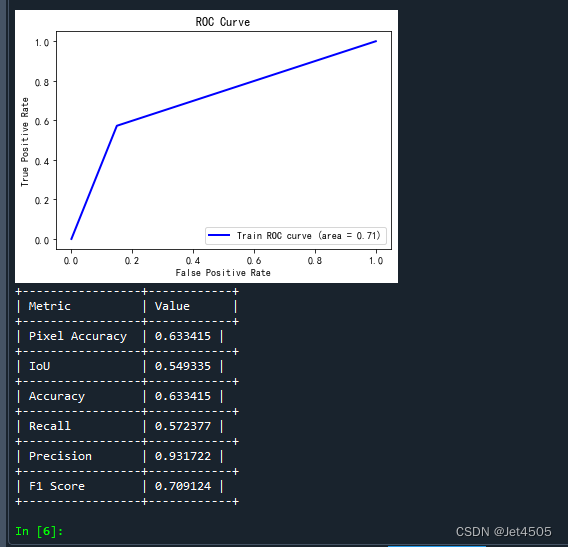
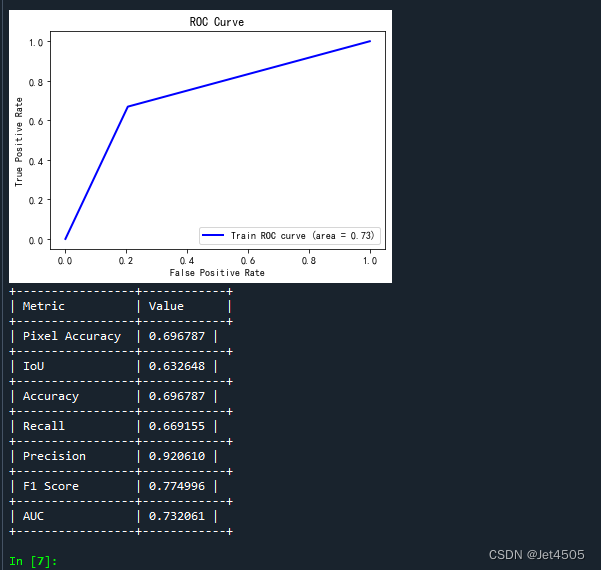
ROC曲线:这里存疑,感觉没啥意义,而且这个曲线看起来有问题,是一个三点折线。
一些性能指标,稍微解释,主要是前两个:
A)Pixel Accuracy:
定义:它是所有正确分类的像素总数与图像中所有像素的总数的比率。
计算:(正确预测的像素数量) / (所有像素数量)。
说明:这个指标评估了模型在每个像素级别上的准确性。但在某些场景中(尤其是当类别非常不平衡时),这个指标可能并不完全反映模型的表现。
B)IoU (Intersection over Union):
定义:对于每个类别,IoU 是该类别的预测结果(预测为该类别的像素)与真实标签之间的交集与并集的比率。
计算:(预测与真实标签的交集) / (预测与真实标签的并集)。
说明:它是一个很好的指标,因为它同时考虑了假阳性和假阴性,尤其在类别不平衡的情况下。
C)Accuracy:
定义:是所有正确分类的像素与所有像素的比例,通常与 Pixel Accuracy 相似。
计算:(正确预测的像素数量) / (所有像素数量)。
D)Recall (or Sensitivity or True Positive Rate):
定义:是真实正样本被正确预测的比例。
计算:(真阳性) / (真阳性 + 假阴性)。
说明:高召回率表示少数阳性样本不容易被漏掉。
E)Precision:
定义:是被预测为正的样本中实际为正的比例。
计算:(真阳性) / (真阳性 + 假阳性)。
说明:高精度表示假阳性的数量很少。
F)F1 Score:
定义:是精度和召回率的调和平均值。它考虑了假阳性和假阴性,并试图找到两者之间的平衡。
计算:2 × (精度 × 召回率) / (精度 + 召回率)。
说明:在不平衡类别的场景中,F1 Score 通常比单一的精度或召回率更有用。
##############################评价指标,对于全部训练集的样本#######################################
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, accuracy_score, recall_score, precision_score, f1_score# 初始化变量来存储评估指标的累积值和真实标签与预测值
total_pixel_accuracy = 0
total_iou = 0
total_accuracy = 0
total_recall = 0
total_precision = 0
total_f1 = 0
total_auc = 0
all_true_masks = []
all_predicted_masks = []# 遍历整个训练集
for sample in train_dataset:sample_img = sample['image'].unsqueeze(0).to(device)sample_mask = sample['mask'].cpu().numpy()# 使用模型进行预测with torch.no_grad():model.eval()prediction = model(sample_img)['out']# 取前景类并转为CPUpredicted_mask = prediction[0, 1].cpu().numpy()predicted_mask = (predicted_mask > 0.5).astype(np.uint8)# 收集真实标签和预测值all_true_masks.extend(sample_mask.ravel())all_predicted_masks.extend(predicted_mask.ravel())# 计算ROC曲线和AUC
fpr_train, tpr_train, _ = roc_curve(all_true_masks, all_predicted_masks)
avg_auc = auc(fpr_train, tpr_train)# 计算其他评估指标
avg_pixel_accuracy = accuracy_score(all_true_masks, all_predicted_masks)
avg_iou = calc_iou(np.array(all_true_masks), np.array(all_predicted_masks))
avg_accuracy = accuracy_score(all_true_masks, all_predicted_masks)
avg_recall = recall_score(all_true_masks, all_predicted_masks)
avg_precision = precision_score(all_true_masks, all_predicted_masks)
avg_f1 = f1_score(all_true_masks, all_predicted_masks)# 绘制ROC曲线
plt.figure()
plt.plot(fpr_train, tpr_train, color='blue', lw=2, label='Train ROC curve (area = %0.2f)' % avg_auc)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc='lower right')
plt.show()# 打印评估指标的平均值
metrics = [("Pixel Accuracy", avg_pixel_accuracy),("IoU", avg_iou),("Accuracy", avg_accuracy),("Recall", avg_recall),("Precision", avg_precision),("F1 Score", avg_f1),("AUC", avg_auc)
]print("+-----------------+------------+")
print("| Metric | Value |")
print("+-----------------+------------+")
for metric_name, metric_value in metrics:print(f"| {metric_name:15} | {metric_value:.6f} |")print("+-----------------+------------+")这个结果是针对有所训练集的:
(d)查看验证集和验证集的具体分割情况
#######################看训练集图片的具体分割效果###########################################
import matplotlib.pyplot as plt
import numpy as np# 选择一张训练集图片
img_index = 20
sample = train_dataset[img_index]
train_img = sample['image'].unsqueeze(0).to(device) # 为batch_size添加一个维度with torch.no_grad():model.eval()prediction = model(train_img)['out']# 使用阈值处理预测掩码
mask_threshold = 0.5
pred_mask = prediction[0, 1].cpu().numpy() # 选择前景类
pred_mask = (pred_mask > mask_threshold).astype(np.uint8)# 使用matplotlib来展示原始图像、真实掩码和预测的分割图像
plt.figure(figsize=(15, 5))plt.subplot(1, 3, 1)
plt.title("Original Image")
# Normalize the image to [0,1] range
denorm_img = train_img[0].permute(1, 2, 0).cpu().numpy()
denorm_img = denorm_img - denorm_img.min()
denorm_img = denorm_img / denorm_img.max()
plt.imshow(denorm_img.clip(0, 1))plt.subplot(1, 3, 2)
plt.title("True Segmentation")
true_mask = sample['mask'].cpu().numpy()
if len(true_mask.shape) == 1: # Ensure mask is 2Dtrue_mask = true_mask.reshape(int(np.sqrt(true_mask.shape[0])), -1)
plt.imshow(true_mask, cmap='gray')plt.subplot(1, 3, 3)
plt.title("Predicted Segmentation")
plt.imshow(pred_mask, cmap='gray')plt.show()#######################看测试集图片的具体分割效果###########################################
#看具体分割的效果
import matplotlib.pyplot as plttest_dataset = CustomDataset(image_paths=[os.path.join(test_images_folder, img) for img in test_images],mask_paths=[os.path.join(label_images_folder, img) for img in label_images], # 这里我假设您的测试集的标签也在label_images_folder中transform=transform
)# 选择一张测试图片
img_index = 20
sample = test_dataset[img_index]
test_img = sample['image'].unsqueeze(0).to(device)with torch.no_grad():model.eval()prediction = model(test_img)['out']# 使用阈值处理预测掩码
mask_threshold = 0.5
pred_mask = prediction[0, 1].cpu().numpy()
pred_mask = (pred_mask > mask_threshold).astype(np.uint8)# 使用matplotlib来展示原始图像、真实掩码和预测的分割图像
plt.figure(figsize=(15, 5))plt.subplot(1, 3, 1)
plt.title("Original Image")
# Normalize the image to [0,1] range
denorm_img = test_img[0].permute(1, 2, 0).cpu().numpy()
denorm_img = denorm_img - denorm_img.min()
denorm_img = denorm_img / denorm_img.max()
plt.imshow(denorm_img.clip(0, 1))plt.subplot(1, 3, 3)
plt.title("Predicted Segmentation")
plt.imshow(pred_mask, cmap='gray')plt.show()查看训练集分割效果:

查看验证集分割效果(验证集没有label,所以中间是空的):

总体来看,都不行哦!我就不调参了。
五、写在后面
略~
六、数据
链接:https://pan.baidu.com/s/1Cb78MwfSBfLwlpIT0X3q9Q?pwd=u1q1
提取码:u1q1