🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~
⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战 欢迎订阅!本专栏针对机器学习基础专栏的理论知识,利用python代码进行实际展示,真正做到从基础到实战!
💡往期推荐:
【机器学习基础】机器学习入门(1)
【机器学习基础】机器学习入门(2)
【机器学习基础】机器学习的基本术语
【机器学习基础】机器学习的模型评估(评估方法及性能度量原理及主要公式)
【机器学习基础】一元线性回归(适合初学者的保姆级文章)
【机器学习基础】多元线性回归(适合初学者的保姆级文章)
【机器学习基础】对数几率回归(logistic回归)
【机器学习基础】正则化
💡本期内容:前面讲了三个最基本的模型,包括了分类和回归,这里再来介绍另外一种很常用的分类方法:决策树。
文章目录
- 1 什么是决策树
- 1.1 决策树的应用场景
- 1.2 决策树的组成
- 1.3 决策树的递归策略
- 2 划分选择
- 2.1 信息熵
- 2.2 信息增益
- 2.3 增益率
- 2.4 基尼指数
- 3 剪枝处理
- 3.1 预剪枝
- 3.2 后剪枝
1 什么是决策树
决策树是一种树形结构,用于描述从一组数据中提取出一些特征,并通过这些特征来进行分类或预测的过程。决策树的每个节点表示一个特征,每个分支表示这个特征的一个取值,叶子节点表示最终的分类结果。
1.1 决策树的应用场景
决策树可以用于解决分类和回归问题,常见的应用场景包括:
- 贷款风险评估:决策树可以用于预测贷款申请人的信用风险,帮助银行更准确地评估申请人的偿债能力。
- 疾病诊断:决策树可以用于辅助医生进行疾病诊断,通过分析病人的症状、体征和实验室检查结果等信息,帮助医生确定最可能的疾病诊断。
- 客户流失预测:决策树可以用于预测客户流失的可能性,帮助企业制定相应的客户保持策略,以降低客户流失率。
- 股票价格预测:决策树可以用于预测股票价格的变动,帮助投资者制定更准确的投资策略。
恶意入侵行为检测:决策树可以用于检测网络中的恶意入侵行为,保护企业的网络安全。
在线广告点击预测:决策树可以用于预测互联网用户对在线广告点击的概率,帮助广告商更好地定位广告投放。
1.2 决策树的组成
决策树由以下几部分组成:
- 决策节点:决策树的起点,代表了整个决策过程的开始。
- 机会节点:机会节点代表一个事件发生的可能性,也就是一个随机事件。
- 决策枝:从决策节点或机会节点出发,代表决策者可以作出的选择或决策。
- 概率枝:从机会节点出发,代表该事件发生的概率。
- 损益值:在决策过程中,每个决策或事件的发生都伴随着一定的成本或收益,这些成本或收益被称为损益值。
- 终点:代表了决策过程的结束,通常以一个方框表示。
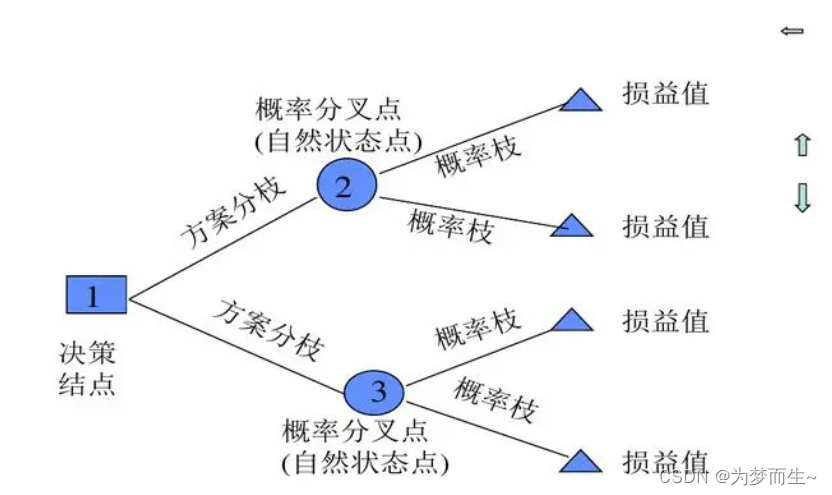
在构建决策树时,需要从决策树的末端开始,从后向前逐步推进到决策树的始端。在推进的过程中,需要计算每个阶段事件发生的期望值,并考虑资金的时间价值。最后,通过对决策树进行剪枝,删去除了最高期望值以外的其他所有分枝,找到问题的最佳方案。
1.3 决策树的递归策略
显然,决策树的生成是一个递归过程。在决策树基本算法中,有三种情形会导致递归返回:
- 当前结点包含的样本全属于同一类别,无需划分
- 当前属性集为空或是所有样本在所有属性上取值相同,无法划分
- 当前结点包含的样本集合为空不能划分
在第(2)种情形下,我们把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别; 在第(3)种情形下,同样把当前结点标记为叶结点,但将其类别设定为其父结点所含样本最多的类别.注意这两种情形的处理实质不同: 情形(2)是在利用当前结点的后验分布而情形(3)则是把结点的样本分布作为当前结点的先验分布.
2 划分选择
决策树的关键是如何选择最优划分属性,一般而言,随着划分过程的不断进行,我们希望决策树的分支节点包含的样本尽可能的属于同一类别,即结点的“纯度”越来越高
2.1 信息熵
在决策树中,信息熵是一个重要的概念,用于度量样本集合的不纯度。对于样本集合而言,如果样本集合中只有一个类别,则其确定性最高,熵为0;反之,如果样本集合中包含多个类别,则熵越大,表示样本集合中的分类越多样。

在决策树的构建过程中,信息熵被用来选择最佳的划分属性。对于每个属性,计算其划分后的信息熵,选择使得信息熵最小的属性作为当前节点的划分属性。这样能够使得划分后的子树更加纯,即类别更加明显,从而降低样本集合的不确定性。
信息熵的公式如下:

假定离散属性 α \alpha α有 V V V个可能的取值,若使用 α \alpha α来对样本集 D D D进行划分,则会产生 V V V个分支结点,其中 v v v第个分支结点包含了 D D D中所有在属性 a a a上取值为 a v a^v av的样本,记为 D v D^v Dv.我们可根据信息熵计算公式计算出 D v D^v Dv的信息嫡,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 ∣ D v ∣ ∣ D ∣ \frac{|D^v|}{|D|} ∣D∣∣Dv∣,即样本数越多的分支结点的影响越大,于是可计算出用属性 α \alpha α对样本集 D D D进行划分所获得的“信息增益”(information gain)
2.2 信息增益
为了衡量不同划分方式降低信息熵的效果,还需要计算分类后信息熵的减少值(原系统的信息熵与分类后系统的信息熵之差),该减少值称为熵增益或信息增益,其值越大,说明分类后的系统混乱程度越低,即分类越准确。
信息增益的计算公式如下:

一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。

对于信息增益,举一个西瓜书上面的例子:

2.3 增益率
在上面的介绍中,我们有意忽略了"编号"这一列.若把"编号"也作为一个候选划分属性,可计算出它的信息增益为0.998远大于其他候选划分属性.这很容易理解"编号"将产生 17 个分支,每个分支结点仅包含一个样本,这些分支结点的纯度己达最大.然而,这样的决策树显然不具有泛化能力,无法对新样本进行有效预测.
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法不直接使用信息增益,而是使用“增益率”(gain ratio)来选择最优划分属性.采用信息增益相同的符号表示,增益率定义为

其中,

优点:属性a的可能取值数目越多 (即 V 越大),则 IV(a) 的值通常就越大。
缺点:对取值数目少的属性有偏好
C4.5 算法中使用启发式: 先从候选划分属性中找出信息增益高于平均水平的,再从中选取增益率最高的。
2.4 基尼指数
决策树模型的建树依据主要用到的是基尼系数的概念。反映了从 D 中随机抽取两个样例,其类别标记不一致的概率。
采用基尼系数进行运算的决策树也称为CART决策树。
基尼系数(gini)用于计算一个系统中的失序现象,即系统的混乱程度(纯度)。基尼系数越高,系统的混乱程度就越高(不纯),建立决策树模型的目的就是降低系统的混乱程度(体高纯度),从而得到合适的数据分类效果。
基尼系数的计算公式如下

基尼系数越低表示系统的混乱程度越低(纯度越高),区分度越高,越适合用于分类预测。
在候选属性集合中,选取那个使划分后基尼指数最小的属性。即:

3 剪枝处理
划分选择的各种准则虽然对决策树的尺寸有较大影响,但对泛化性能的影响很有限。是决策树预防“过拟合”的主要手段!
剪枝方法和程度对决策树泛化性能的影响更为显著(在数据带噪时甚至可能将泛化性能提升 25%)
3.1 预剪枝
从上往下剪枝,通常利用超参数进行剪枝。例如,通过限制树的最大深度(max_depth)便能剪去该最大深度下面的节点。
没有剪枝前:

剪枝后:

3.2 后剪枝
从下往上剪枝,大多是根据业务需求剪枝。例如,在违约预测模型中,认为违约概率为45%和50%的两个叶子节点都是高危人群,那么就把这两个叶子节点合并成一个节点。